🤓?YOLOv6 ORT/MNN/TNN/NCNN C++ЭЦРэВПЪ№
0. ЧАбд
зђЬьУРЭХПЊдДСЫYOLOv6,гжЪЧвЛИіYOLOЯЕСаЕФаТзїЁЃДЫЪБОрРыYOLOXПЊдДВюВЛЖрИеКУвЛФъЕФЪБМфЁЃжЎЧАФѓЙ§КмЖрYOLOЯЕСаЕФЭЦРэР§зг,БШШчYOLOv3ЁЂYOLOv4ЁЂYOLOv5ЁЂYOLOXЁЂYOLORКЭYOLOPЕШЕШЁЃЫфШЛзюНќвбОУЛгадкзіdetectionЗНЯђСЫ,ЕЋзїЮЊYOLOЯЕСаЕФРЯЗлСЫ,ГіРДДеИіШШФжгІИУзмЪЧПЩвдЕФЁЃЫљвд,етДЮвВРДДеДеYOLOЯЕСаЕФШШФж,ИјГіМИИіВЛЭЌЕФЭЦРэв§ЧцЕФР§зг,АќРЈONNXRuntimeЁЂMNNЁЂNCNNКЭTNN,вдМАМђЕЅМЧТМЯТФЃаЭЕФзЊЛЛЙ§ГЬЁЃзмЕФРДЫЕ,YOLOv6 ЕФ C++ЭЦРэ,ЖМЪЧаЉжиИДадЕФЙЄзї,УЛЪВУДЬЋДѓЕФФбЖШ,ИеКУГУзХжмФЉ,ЫГЪжФѓвЛФѓЁЃетЦЊЮФеТВЛЛсМЧТМЕиКмЯъЯИ,жЛНВМИИівЊЕуЁЃ
1. ONNX КЭ TNN ФЃаЭзЊЛЛ
ОЙ§ГЂЪд,жБНгзЊЛЛГіРДЕФONNXКЭTNNФЃаЭЮФМўдкЭЦРэЪБ,НсЙћвЛЧае§ГЃ,ВЛашвЊаоИФ YOLOv6 ЕФ Detect дДТы,ЪЙгУЙйЗНЬсЙЉЕФ deploy/ONNX/export_onnx.py жБНгзЊЛЛМДПЩЁЃЕЋЪЧ NCNN КЭ MNN ЖМашвЊаоИФ Detect ЕФдДТыНјааЬиЪтДІРэВХПЩе§ГЃЭЦРэЁЃЫљвд ONNX КЭ TNN ЗХдкетвЛНкНВ,MNN КЭ NCNN ЕФФЃаЭзЊЛЛЗХдкЯТвЛаЁНкНВЁЃ
ЪзЯШЯТдидДТы:
git clone --depth=1 https://github.com/meituan/YOLOv6.gitШЛКѓЩдЮЂаоИФЯТ export_onnx.py,дДТыЪЧУЛгаЬэМг onnxsimЕФ,зїЮЊЛљВй,ЮвУЧАбЫќЬэМгЩЯ,аоИФКѓШчЯТ:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import argparse
import time
import sys
import os
import torch
import torch.nn as nn
import onnx
import onnxsim
import onnxruntime as ort
ROOT = os.getcwd()
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT))
from yolov6.models.yolo import *
from yolov6.models.effidehead import Detect
from yolov6.layers.common import *
from yolov6.utils.events import LOGGER
from yolov6.utils.checkpoint import load_checkpoint
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolov6s.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set Detect() inplace=True')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0, 1, 2, 3 or cpu')
args = parser.parse_args()
args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
print(args)
t = time.time()
apply_simplify = True # діМгonnxsim
# Check device
cuda = args.device != 'cpu' and torch.cuda.is_available()
device = torch.device('cuda:0' if cuda else 'cpu')
assert not (device.type == 'cpu' and args.half), '--half only compatible with GPU export, i.e. use --device 0'
# Load PyTorch model
model = load_checkpoint(args.weights, map_location=device, inplace=True, fuse=True) # load FP32 model
for layer in model.modules():
if isinstance(layer, RepVGGBlock):
layer.switch_to_deploy()
# Input
img = torch.zeros(args.batch_size, 3, *args.img_size).to(device) # image size(1,3,320,192) iDetection
# Update model
if args.half:
img, model = img.half(), model.half() # to FP16
model.eval()
for k, m in model.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, Detect):
m.inplace = args.inplace
y = model(img) # dry run
# ONNX export
h, w = args.img_size
export_file = args.weights.replace('.pt', f'-{h}x{w}.onnx') # filename діМгsizeБъМЧ
try:
LOGGER.info('\nStarting to export ONNX...')
torch.onnx.export(model, img, export_file, verbose=False, opset_version=12,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['image_arrays'],
output_names=["outputs"],
)
# Checks
onnx_model = onnx.load(export_file) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
LOGGER.info(f'ONNX export success, saved as {export_file}')
except Exception as e:
LOGGER.info(f'ONNX export failure: {e}')
if apply_simplify: # діМгЕФonnxsimВПЗж
print(f'{export_file} simplifying with onnx-simplifier {onnxsim.__version__}...')
try:
onnx_model = onnx.load(export_file) # load onnx model
onnx_model, check = onnxsim.simplify(onnx_model, check_n=3)
assert check, 'simplifying check failed'
onnx.save(onnx_model, export_file)
except Exception as e:
print(f'{export_file} simplifier failure: {e}')
# Running ORT check діМгORTбщжЄ
sess = ort.InferenceSession(export_file)
print(f"ORT Loaded {export_file} !")
for _ in sess.get_inputs(): print(f"Input: {_}")
for _ in sess.get_outputs(): print(f"Output: {_}")
print("ORT Check Done !")
# Finish
LOGGER.info('\nExport complete (%.2fs)' % (time.time() - t))дЄбЕСЗКУЕФptФЃаЭЮФМўПЩвдДгЙйЗНЬсЙЉЕФСДНгЯТди,ЗХдк YOLOv6 ЕФИљФПТМЯТ,жБНгзЊЛЛОЭаа:
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6n.pt --img 640 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6n.pt --img 320 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6s.pt --img 640 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6s.pt --img 320 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6t.pt --img 640 --batch 1етИіЙ§ГЬБШНЯЫГРћ,днЪБУЛЗЂЯжЪВУДПгЁЃНгЯТРДзЊЛЛЮЊ TNN ФЃаЭЮФМў,УќСюШчЯТ:
convert2tnn# python3 ./converter.py onnx2tnn ./tnn_models/yolov6/yolov6t-640x640.onnx -o ./tnn_models/yolov6/ -v v1.0 -optimize -align
convert2tnn# python3 ./converter.py onnx2tnn ./tnn_models/yolov6/yolov6s-640x640.onnx -o ./tnn_models/yolov6/ -v v1.0 -optimize -align
convert2tnn# python3 ./converter.py onnx2tnn ./tnn_models/yolov6/yolov6n-640x640.onnx -o ./tnn_models/yolov6/ -v v1.0 -optimize -align
convert2tnn# python3 ./converter.py onnx2tnn ./tnn_models/yolov6/yolov6s-320x320.onnx -o ./tnn_models/yolov6/ -v v1.0 -optimize -align
convert2tnn# python3 ./converter.py onnx2tnn ./tnn_models/yolov6/yolov6n-320x320.onnx -o ./tnn_models/yolov6/ -v v1.0 -optimize -alignTNNФЃаЭЕФзЊЛЛашвЊгУЕН tnn-convert,ШчКЮЪЙгУtnn-convertОЭВЛеЙПЊСЫ,ИааЫШЄЕФЭЌбЇПЩвдПДЮвжЎЧАаДЕФвЛЦЊЮФеТ,ДЋЫЭУХ:
tnn-convertДюНЈМђМЧ-YOLOPзЊTNN - жЊКѕtnn-convertДюНЈМЧТМгаЖЮЪБМфУЛИќСЫ,зюНќзМБИећРэвЛЯТЪЙгУTNNЁЂMNNКЭNCNNЕФЯЕСаБЪМЧ,КУМЧадВЛШчРУБЪЭЗ(МЧадвВВЛКУ),ЗНБуздМКвдКѓВШПгЕФЪБКђХРЕФРћЫїЕу~( ПДет ,ФПЧА 80ЖрC++ЭЦРэР§зг,ФмБрИіlibРДгУ,ИааЫЁ https://zhuanlan.zhihu.com/p/431418709
https://zhuanlan.zhihu.com/p/431418709
2. MNN КЭ NCNN ФЃаЭзЊЛЛ
NCNN КЭ MNN ЖМашвЊаоИФ Detect ЕФдДТыНјааЬиЪтДІРэВХПЩе§ГЃЭЦРэЁЃMNNЦфЪЕвВПЩвджБНгзЊ,ЕЋЪЧзЊГіРДЕФФЃаЭЮФМўЫфШЛФмЭЦРэ,ЕЋЪЧдкdecodeЭъжЎКѓ,НсЙћКмЦцЙж,ЫљвдЮвзюКѓОіЖЈНЋMNNЕФФЃаЭЮФМўзЊЛЛВЩгУКЭNCNNЭЌбљЕФДІРэЗНЪНЁЃЦфЪЕКмЖраДЕФЙигкYOLOЯЕСаЕФВПЪ№ЮФеТЖМгаЬсЕНЙ§,ИУЯЕСадкВПЪ№ЪБжївЊЕФвЛИіЮЪЬтОЭЪЧШчКЮДІРэ Detect Head жаЙигк decode ВПЗжЕФТпМЁЃетВПЗжДњТыдк YOLOv6жаГЄетбљ:
def forward(self, x):
z = []
for i in range(self.nl):
# ...
if self.training:
# ...
else:
y = torch.cat([reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1)
bs, _, ny, nx = y.shape
y = y.view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if self.grid[i].shape[2:4] != y.shape[2:4]:
d = self.stride.device
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
self.grid[i] = torch.stack((xv, yv), 2).view(1, self.na, ny, nx, 2).float()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = torch.exp(y[..., 2:4]) * self.stride[i] # wh
else:
xy = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy
wh = torch.exp(y[..., 2:4]) * self.stride[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else torch.cat(z, 1)етВПЗжЫфШЛгааЉПђМмПЩвджБНгжЇГжЕМГі,ЕЋЛсВњЩњДѓСПЕФНКЫЎop,ЫљвдвЛИіПЩбЁЕФзіЗЈЪЧ,жЛЕМГіdecodeжЎЧАЕФRawВПЗжЕФФкШн,дкC++ВрзіdecodeЁЃСэЭт,ЮвУЧПЩвдПДЕН,decodeВПЗжДцдквЛИі5ЮЌЖШЕФВйзї:
y = y.view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()етВПЗждкNCNNжагІИУЪЧВЛжЇГжЕФ(АДееЮвЖдncnn::MatЕФРэНт,Ыќгаc,h,wШ§ИіЮЌЖШ,ВЂМйЩшb=1,ЫљвдПЩвдДІРэ<=4ЮЌЕФеХСП),вВВЛФмжБНгЕМГіЁЃЫљвд,етИі5ЮЌЕФДІРэ,ЮвУЧвВвЊзіЯргІЕФаоИФЁЃжСгкMNN,ЦфЪЕПЩвджБНгзЊЛЛетВПЗжdecodeЕФТпМ,ЕЋЪЧЮвдкЭЦРэЪБ,ЗЂЯжГіРДЕФНсЙћВЛЬЋЖд,гкЪЧОіЖЈВЩгУNCNNЭЌбљЕФДІРэЗНЪН,ОЭЪЧжЛЕМГіdecodeЧАЕФВПЗж,АбdecodeЗХдкc++ВрДІРэ,КѓРДбщжЄСЫетбљзіПЩвдЕУЕНе§ГЃЕФЭЦРэНсЙћЁЃ
ФЧУД,етЖЮ Detect Head ЕФТпМЕНЕзвЊдѕУДИФФи?ГЄЛАЖЬЫЕ,ЮвжБНгЗХвЛИіЮваоИФКѓЕФДњТыАЩ:
-
models/effidehead.pyаоИФжЎКѓ
class Detect(nn.Module):
# ...
def forward(self, x):
z = []
for i in range(self.nl):
# ...
if self.training:
# ...
else: # аоИФжЎКѓГЄетбљ
x[i] = torch.cat([reg_output, obj_output, cls_output], 1)
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,1,20,20,85=80+5) (bs,na,ny,nx,no=nc+5=4+1+nc)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = x[i].view(bs, self.na, 85, -1).permute(0, 1, 3, 2).contiguous() # (b,self.na,20x20,85) for NCNN
x[i] = x[i].view(bs, -1, 85)
return torch.cat(x, dim=1) # (b,?,85)етРя,ЮвУЧАбдРДЕФ5ЮЌВйзїаоИФГЩ4ЮЌВйзї,вђЮЊЕМГіЪБ,ЪЕМЪЕФno(num_outputs=85)ЁЂna(num_anchors=1)ЕФжЕЖМЪЧПЩвдЪТЯШМЦЫуГіРДЕФ,ЭЈЙ§ПД YOLOv6 жаЕФ configs ЮФМўМажаЕФХфжУЮФМў,ЮвУЧвВПЩвдШЗЖЈЪЕМЪЩЯ naвЛжБЮЊ1,Жј ny,nxЪЧУПИіЬиеїЭМЕФДѓаЁ,ЖдгкЙЬЖЈЕФЪфШыshape,ИїИіЬиеїЭМЕФny,nxвВЪЧЙЬЖЈЕФЁЃЮЊСЫБфГЩ4ЮЌВйзї,ЮвУЧПЩвдАбдРДдкзюКѓЕФСНИіЮЌЖШ(ny,nx)жБНгРЦН,АДееаажїађЕФЯпадФкДцРДРэНт,етбљЪЧПЩааЕФЁЃгкЪЧга:
x[i] = x[i].view(bs, self.na, 85, -1).permute(0, 1, 3, 2).contiguous() # (b,self.na,20x20,85) for NCNN
x[i] = x[i].view(bs, -1, 85)зюКѓ,дкЗЕЛиНсЙћжЕжЎЧА,ЮвУЧдйзівЛИіКЯВЂДІРэ,етбљОЭВЛашвЊдкc++НтТыЕФЪБКђЕЅЖРЖдУПИіЬиеїЭМЖМзівЛБщ,КЯВЂКѓ,жЛвЊЖдвЛИіДѓЕФЪфГізіdecodeОЭПЩвдСЫЁЃ
return torch.cat(x, dim=1) # (b,?,85)етбљаоИФжЎКѓ,export_onnx.pyЕФДњТыВЛгУБф,ЛЙЪЧгУдРДЕФУќСюаажБНгЕМГіОЭПЩвдСЫ(ЮвдкЮФМўУћдіМгСЫ-for-ncnnзїЮЊКѓзКЗНБуЧјЗж)ЁЃ
ЛЙЪЧЯШЕМГіЮЊ ONNX:
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6n.pt --img 640 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6n.pt --img 320 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6s.pt --img 640 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6s.pt --img 320 --batch 1
PYTHONPATH=. python3 ./deploy/ONNX/export_onnx.py --weights yolov6t.pt --img 640 --batch 1ФЃаЭЮФМўЮЊ:
yolov6 ls -lh | grep yolov6 | grep for-ncnn | grep onnx
-rw-r--r-- 1 yanjunqiu staff 16M Jun 25 12:52 yolov6n-320x320-for-ncnn.onnx
-rw-r--r-- 1 yanjunqiu staff 16M Jun 25 12:51 yolov6n-640x640-for-ncnn.onnx
-rw-r--r-- 1 yanjunqiu staff 66M Jun 25 12:53 yolov6s-320x320-for-ncnn.onnx
-rw-r--r-- 1 yanjunqiu staff 66M Jun 25 12:52 yolov6s-640x640-for-ncnn.onnx
-rw-r--r-- 1 yanjunqiu staff 57M Jun 25 12:53 yolov6t-640x640-for-ncnn.onnxгУnetronДђПЊРДПД,ЗЂЯжdecodeФЧВПЗжвбОУЛгаСЫ:
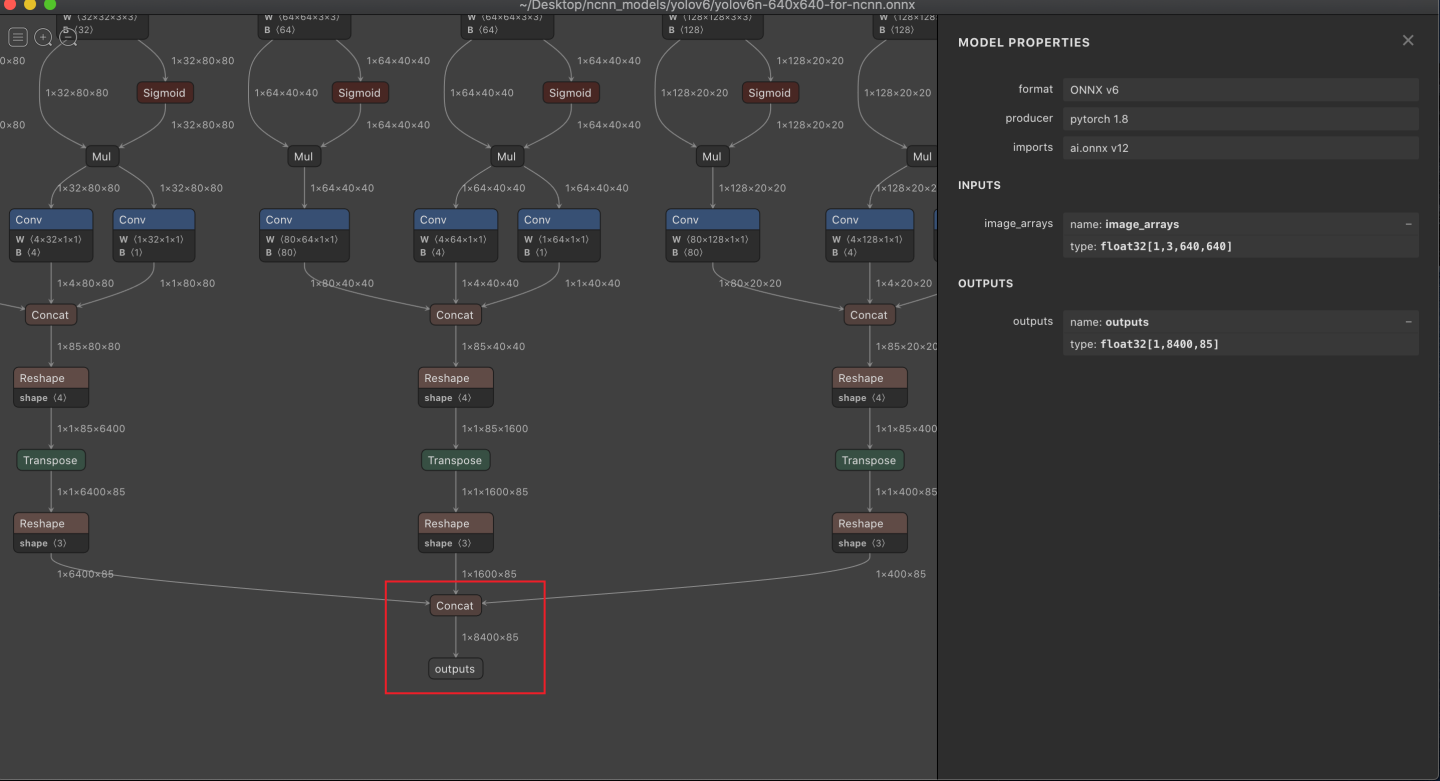
?
БрМЧаЛЛЮЊОгжа
ЬэМгЭМЦЌзЂЪЭ,ВЛГЌЙ§ 140 зж(ПЩбЁ)
ДјdecodeЕФonnx,гУnetronДђПЊЪЧГЄетбљЕФ:
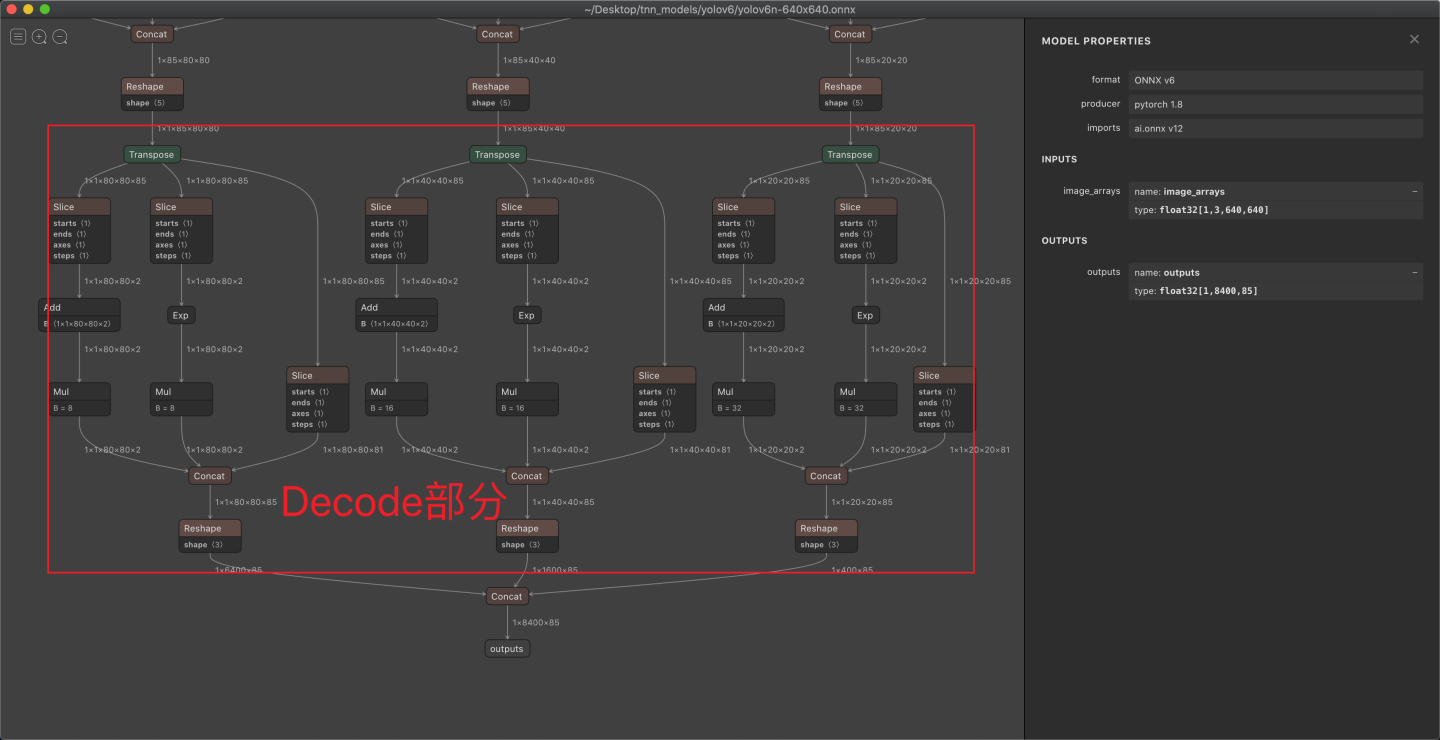
?
БрМЧаЛЛЮЊОгжа
ЬэМгЭМЦЌзЂЪЭ,ВЛГЌЙ§ 140 зж(ПЩбЁ)
ПЩвдЗЂЯжСНепгаКмУїЯдЕФЧјБ№,ВЛДјdecodeЕФЭМ,дкЪфГіВПЗжвЊМђЕЅКмЖрЁЃ
НгЯТРД,ОЭЪЧАДГЃЙцСїГЬНЋONNXзЊЛЛГЩNCNNКЭMNNФЃаЭ,УќСюааШчЯТ:
onnx2ncnn yolov6/yolov6s-320x320-for-ncnn.onnx yolov6/yolov6s-320x320-for-ncnn.param yolov6/yolov6s-320x320-for-ncnn.bin
ncnnoptimize yolov6/yolov6s-320x320-for-ncnn.param yolov6/yolov6s-320x320-for-ncnn.bin yolov6/yolov6s-320x320-for-ncnn.opt.param yolov6/yolov6s-320x320-for-ncnn.opt.bin 0вЛЧае§ГЃЁЃзЊЛЛЮЊMNNФЃаЭЕФУќСюЮЊ:
YOLOv6 MNNConvert -f ONNX --modelFile yolov6n-640x640-for-ncnn.onnx --MNNModel yolov6n-640x640.mnn --bizCode MNN
Start to Convert Other Model Format To MNN Model...
[15:19:09] /Users/yanjunqiu/Desktop/third_party/library/MNN/tools/converter/source/onnx/onnxConverter.cpp:30: ONNX Model ir version: 6
Start to Optimize the MNN Net...
inputTensors : [ image_arrays, ]
outputTensors: [ outputs, ]
Converted Success!вВЪЧвЛЧае§ГЃЁЃ
3. ONNX КЭ TNN ФЃаЭ C++ ЭЦРэ
ONNXКЭTNNЕФФЃаЭЖМЪЧДјdecodeЕФ,вђДЫдкКѓДІРэЪБМђЕЅаЉ,ВЛгУЩњГЩanchorСЫЁЃФЃаЭЭЦРэжБНгЪфГіЕФЮЌЖШЪЧ(1,n,85),етИіnБэЪОзмЙВЪфГіЕФanchorsИіЪ§,85ЕФКЌвхЪЧ:
85=5+80=cxcy(2)+cwch(2)+obj_conf(1)+cls_conf(80)гЩгкЪфГіЕФзјБъОЭвбОЪЧЙщвЛЛЏКѓЕФcx,cyКЭcw,ch,ЫљвдКѓДІРэОЭКмМђЕЅСЫ,жБНгзЊЛЛГЩx1,y1,x2,y2ИёЪНОЭааЁЃТпМДѓИХШчЯТ:
float cx = offset_obj_cls_ptr[0];
float cy = offset_obj_cls_ptr[1];
float w = offset_obj_cls_ptr[2];
float h = offset_obj_cls_ptr[3];
float x1 = ((cx - w / 2.f) - (float) dw_) / r_;
float y1 = ((cy - h / 2.f) - (float) dh_) / r_;
float x2 = ((cx + w / 2.f) - (float) dw_) / r_;
float y2 = ((cy + h / 2.f) - (float) dh_) / r_;ЯъЯИЕФЭЦРэДњТыОЭВЛеЙПЊСЫ,ЛсдкЮФеТзюКѓЗХГіЁЃ
4. NCNN КЭ MNN ФЃаЭ C++ ЭЦРэ
NCNNКЭMNNЕФФЃаЭЮФМўУЛгаЕМГіdecodeВПЗж,вђДЫКѓДІРэИДдгвЛЕуЁЃКѓДІРэжївЊАќРЈ2ВПЗж,вЛЪЧЩњГЩanchors,ЖўЪЧИљОнЩњГЩЕФanchorsКЭЪфГіЕФдЪМаХЯЂНтТызјБъЁЃYOLOv6 ЕФanchorsЩњГЩТпМЦфЪЕКЭYOLOXЛљБОЪЧвЛжТЕФ,ОЭЪЧУПИіfeature mapЩЯУПИіУЊЕуЩњГЩвЛИіanchorПђ,зіЙ§detectionЫуЗЈЕФЭЌбЇгІИУКмЖрРэНтетОфЛАЕФвтЫМ,ЮввВОЭВЛЊрТСЫЁЃжБНгЗХДњТыАЩЁЃ
-
generate_anchorsКЏЪ§жївЊТпМ
oid NCNNYOLOv6::generate_anchors(const int target_height,
const int target_width,
std::vector<int> &strides,
std::vector<YOLOv6Anchor> &anchors)
{
for (auto stride: strides)
{
int num_grid_w = target_width / stride;
int num_grid_h = target_height / stride;
for (int g1 = 0; g1 < num_grid_h; ++g1)
{
for (int g0 = 0; g0 < num_grid_w; ++g0)
{
YOLOv6Anchor anchor;
anchor.grid0 = g0;
anchor.grid1 = g1;
anchor.stride = stride;
anchors.push_back(anchor);
}
}
}
}-
зјБъНтТыЕФжївЊТпМ
const int grid0 = anchors.at(i).grid0;
const int grid1 = anchors.at(i).grid1;
const int stride = anchors.at(i).stride;
float dx = offset_obj_cls_ptr[0];
float dy = offset_obj_cls_ptr[1];
float dw = offset_obj_cls_ptr[2];
float dh = offset_obj_cls_ptr[3];
float cx = (dx + (float) grid0) * (float) stride;
float cy = (dy + (float) grid1) * (float) stride;
float w = std::exp(dw) * (float) stride;
float h = std::exp(dh) * (float) stride;
float x1 = ((cx - w / 2.f) - (float) dw_) / r_;
float y1 = ((cy - h / 2.f) - (float) dh_) / r_;
float x2 = ((cx + w / 2.f) - (float) dw_) / r_;
float y2 = ((cy + h / 2.f) - (float) dh_) / r_;ЯъЯИЕФЭЦРэДњТыОЭВЛеЙПЊСЫ,ЛсдкЮФеТзюКѓЗХГіЁЃ
5. YOLOv6 C++ЭЦРэЕФЪЙгУР§зг
ЪзЯШЪЧЗХГіYOLOv6 ЕФ4ИіЭЦРэв§ЧцЕФC++ дДТы,ЯыБиДѓМвзюЙиаФОЭЪЧФмВЛФмАзцЮСЫЁЃЫљгаЕФДњТыЖММЏГЩНјСЫlite.ai.toolkit ЙЄОпЯфжа,СуГЩБОЮобЙСІАзцЮЁЃ
ЖддДТыИааЫШЄЕФЭЌбЇ,ПЩздаабЁдёЙиаФЕФЭЦРэв§ЧцАцБОНјаадФЖСЁЃНгЯТРД,дкМђЕЅЬљМИИіЪЙгУlite.ai.toolkit ЙЄОпЯфвЛМќЕїгУЕФР§згЁЃ
-
ONNXRuntimeАцБО
#include "lite/lite.h"
static void test_default()
{
std::string onnx_path = "../../../hub/onnx/cv/yolov6s-640x640.onnx";
std::string test_img_path = "../../../examples/lite/resources/test_lite_yolov6_1.jpg";
std::string save_img_path = "../../../logs/test_lite_yolov6_1.jpg";
// 1. Test Default Engine ONNXRuntime
auto *yolov6 = new lite::cv::detection::YOLOv6(onnx_path); // default
std::vector<lite::types::Boxf> detected_boxes;
cv::Mat img_bgr = cv::imread(test_img_path);
yolov6->detect(img_bgr, detected_boxes);
lite::utils::draw_boxes_inplace(img_bgr, detected_boxes);
cv::imwrite(save_img_path, img_bgr);
std::cout << "Default Version Detected Boxes Num: " << detected_boxes.size() << std::endl;
delete yolov6;
}-
MNNАцБО
static void test_mnn()
{
#ifdef ENABLE_MNN
std::string mnn_path = "../../../hub/mnn/cv/yolov6s-640x640.mnn";
std::string test_img_path = "../../../examples/lite/resources/test_lite_yolov6_2.jpg";
std::string save_img_path = "../../../logs/test_lite_yolov6_mnn_2.jpg";
// 3. Test Specific Engine MNN
auto *yolov6 = new lite::mnn::cv::detection::YOLOv6(mnn_path);
std::vector<lite::types::Boxf> detected_boxes;
cv::Mat img_bgr = cv::imread(test_img_path);
yolov6->detect(img_bgr, detected_boxes);
lite::utils::draw_boxes_inplace(img_bgr, detected_boxes);
cv::imwrite(save_img_path, img_bgr);
std::cout << "MNN Version Detected Boxes Num: " << detected_boxes.size() << std::endl;
delete yolov6;
#endif
}
-
NCNNАцБО
static void test_ncnn()
{
#ifdef ENABLE_NCNN
std::string param_path = "../../../hub/ncnn/cv/yolov6s-640x640-for-ncnn.opt.param";
std::string bin_path = "../../../hub/ncnn/cv/yolov6s-640x640-for-ncnn.opt.bin";
std::string test_img_path = "../../../examples/lite/resources/test_lite_yolov6_2.jpg";
std::string save_img_path = "../../../logs/test_lite_yolov6_ncnn_2.jpg";
// 4. Test Specific Engine NCNN
auto *yolov6 = new lite::ncnn::cv::detection::YOLOv6(param_path, bin_path);
std::vector<lite::types::Boxf> detected_boxes;
cv::Mat img_bgr = cv::imread(test_img_path);
yolov6->detect(img_bgr, detected_boxes);
lite::utils::draw_boxes_inplace(img_bgr, detected_boxes);
cv::imwrite(save_img_path, img_bgr);
std::cout << "NCNN Version Detected Boxes Num: " << detected_boxes.size() << std::endl;
delete yolov6;
#endif
}-
TNNАцБО
static void test_tnn()
{
#ifdef ENABLE_TNN
std::string proto_path = "../../../hub/tnn/cv/yolov6s-640x640.opt.tnnproto";
std::string model_path = "../../../hub/tnn/cv/yolov6s-640x640.opt.tnnmodel";
std::string test_img_path = "../../../examples/lite/resources/test_lite_yolov6_2.jpg";
std::string save_img_path = "../../../logs/test_lite_yolov6_tnn_2.jpg";
// 5. Test Specific Engine TNN
auto *yolov6 = new lite::tnn::cv::detection::YOLOv6(proto_path, model_path);
std::vector<lite::types::Boxf> detected_boxes;
cv::Mat img_bgr = cv::imread(test_img_path);
yolov6->detect(img_bgr, detected_boxes);
lite::utils::draw_boxes_inplace(img_bgr, detected_boxes);
cv::imwrite(save_img_path, img_bgr);
std::cout << "TNN Version Detected Boxes Num: " << detected_boxes.size() << std::endl;
delete yolov6;
#endif
}ЪфГіЕФНсЙћШчЯТ:

?
БрМЧаЛЛЮЊОгжа
ЬэМгЭМЦЌзЂЪЭ,ВЛГЌЙ§ 140 зж(ПЩбЁ)

?
БрМЧаЛЛЮЊОгжа
ЬэМгЭМЦЌзЂЪЭ,ВЛГЌЙ§ 140 зж(ПЩбЁ)
6. змНс
БОЮФжївЊНВНтСЫУРЭХ6дТ24ПЊдДЕФYOLOv6дкВЛЭЌЭЦРэв§ЧцЕФC++ЙЄГЬЛЏЙ§ГЬ,АќКЌСЫORTЁЂMNNЁЂNCNNКЭTNNЯТЕФЭЦРэДІРэ,вдМАВЛЭЌЭЦРэПђМмЯТФЃаЭзЊЛЛашвЊзЂвтЕФЮЪЬтЁЃВЂЧв,ЫљгаЕФДњТыЖММЏГЩНјСЫlite.ai.toolkit ЙЄОпЯфжа,СуГЩБОЮобЙСІАзцЮЁЃ
ГУзХжмФЉФѓУРЭХЕФетИіYOLOv6ФЃаЭ,аДЭъетЦЊЮФеТЕФЪБКђ,ВюВЛЖрЪЧАјЭэ6Еу,ЪБжЕжйЯФ,ЮвУўСЫУўМЂГІъЄъЄЕФЖЧзг,ОѕЕУЪЧЪБКђДђПЊЮвЪжЛњЩЯЕФУРЭХЭтТєРДЯТИіЕЅСЫ~ ЮЪЬтРДСЫ,ФЧЕНЕзГдЩЖКУФи ...