? ? ? ? 训练是什么样的? ? ? ??
????????看源码,了解darknet训练需要的命令行参数及训练所需的数据怎么放
????????git clone, make 之后可以看到大致情况:
????????????????src/ 是libdarknet的源码
????????????????examples/darknet.c是darknet main代码
????????需要运行yolo,则 CMDLINE darknet yolo,执行run_yolo,在examples/yolo.c中
看usage :?%s %s [train/test/valid] [cfg] [weights (optional)]
????????需要CMDLINE ?darknet yolo train cfg/yolov1.cfg [可选预训练权重],执行train_yolo
? ? ? ? 看到一些点
????????????????char *voc_names[] = {"aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"};
????????????????????????都说20个class,现在才具体看到是哪20个物体
?????????????????char *train_images = "/data/voc/train.txt";
????????????????????????train_images 说明了训练需要的图片,但只有一个/data/voc/train.txt,说明train.txt包含图片列表
? ? ? ? 所以训练前准备,需要一些图片及包含这些图片名字的train.txt
? ? ? ? 在scripts/下,有一些脚本文件,voc_label.py,"voc",这个应该要运行的
? ? ? ? 打开看下,
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "po
ttedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
? ? dw = 1./(size[0])
? ? dh = 1./(size[1])
? ? x = (box[0] + box[1])/2.0 - 1
? ? y = (box[2] + box[3])/2.0 - 1
? ? w = box[1] - box[0]
? ? h = box[3] - box[2]
? ? x = x*dw
? ? w = w*dw
? ? y = y*dh
? ? h = h*dh
? ? return (x,y,w,h)
def convert_annotation(year, image_id):
? ? in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
? ? out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
? ? tree=ET.parse(in_file)
? ? root = tree.getroot()
? ? size = root.find('size')
? ? w = int(size.find('width').text)
? ? h = int(size.find('height').text)
? ? for obj in root.iter('object'):
? ? ? ? difficult = obj.find('difficult').text
? ? ? ? cls = obj.find('name').text
? ? ? ? if cls not in classes or int(difficult)==1:
? ? ? ? ? ? continue
? ? ? ? cls_id = classes.index(cls)
? ? ? ? xmlbox = obj.find('bndbox')
? ? ? ? b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
? ? ? ? bb = convert((w,h), b)
? ? ? ? out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
? ? if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
? ? ? ? os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
? ? image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
? ? list_file = open('%s_%s.txt'%(year, image_set), 'w')
? ? for image_id in image_ids:
? ? ? ? list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
? ? ? ? convert_annotation(year, image_id)
? ? list_file.close()
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
? ? ? ? OK,看到train.txt了
? ? ? ? 没学过python,但本质和C/C++都是一样的,
????????classes 和?voc_names是一致的,
????????sets数据集,上下文联系,[year, image_id],
? ? ? ? 再看几个需要的地方
????????????????'VOCdevkit/VOC%s/labels/'%(year)
????????????????'VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)
????????????????'VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)
????????????????'VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id)
? ? ? ? 可以看到需要?VOCdevkit/VOC2007? ?VOCdevkit/VOC2012, 这和论文里提到的是一致的
? ? ? ?
????????数据集下载,作者博客有mirror镜像,
????????pjreddie.com 下 分类中点击"projects",下面列表中有 “Pascal VOC Dataset Mirror”,点进去

????????说大也大,说不大也不大
? ? ? ? ?下载 这两个年份的?Train/Validation Data?和 Test Data?
? ? ? ? edge自行下载太慢了,还是上老古董迅雷下载(非会员,不用登录),可以满速下载
? ? ? ? 先放到scripts/,直接解压,
????????????????tar xvf ?VOCtrainval_06-Nov-2007.tar
????????????????tar xvf VOCtest_06-Nov-2007.tar
????????????????tar xvf VOCtrainval_11-May-2012.tar
? ? ? ? 试着运行一下python voc_label.py 没有任何提示,ls看下scripts多了
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
? ? ? ? 有了train.txt,来试着train一下看看
? ? ? ? 修改char *train_images = "/data/voc/train.txt"; 为?char *train_images = "scripts/train.txt";
????????char *backup_directory = "backup/";
? ? ? ? make
? ? ? ? ./darknet yolo train cfg/yolov1.cfg
? ? ? ? 没有nvidia显卡,cpu模式运行
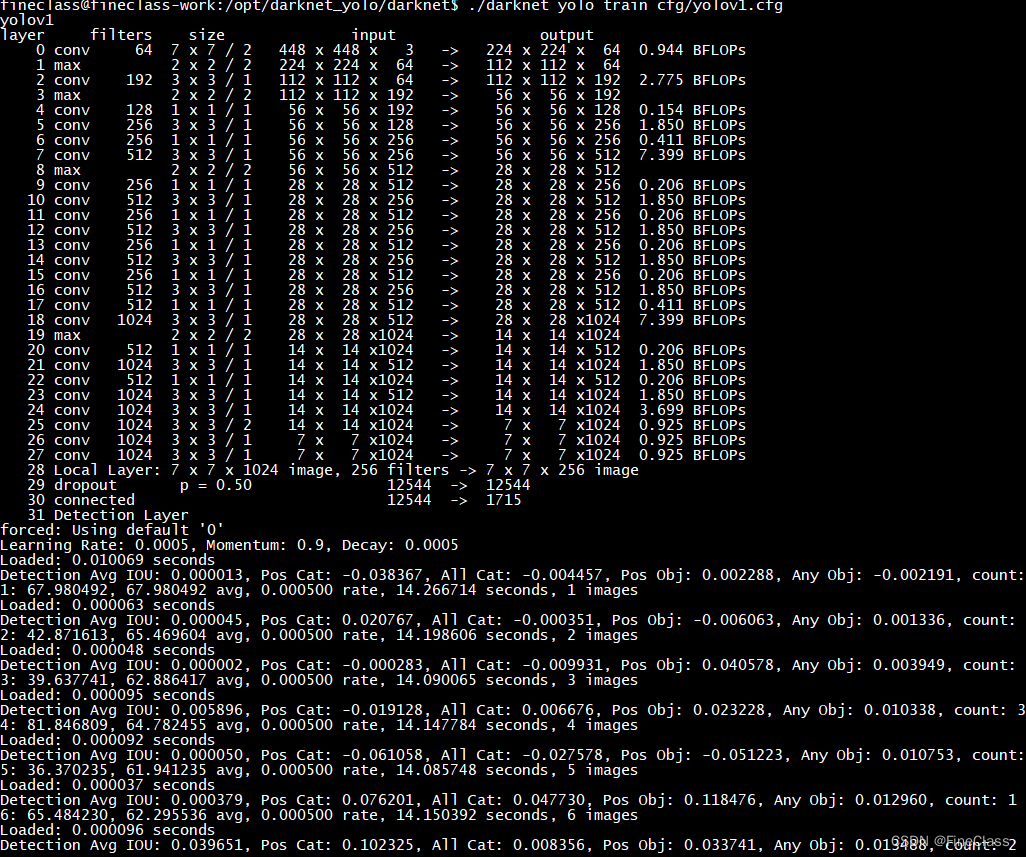
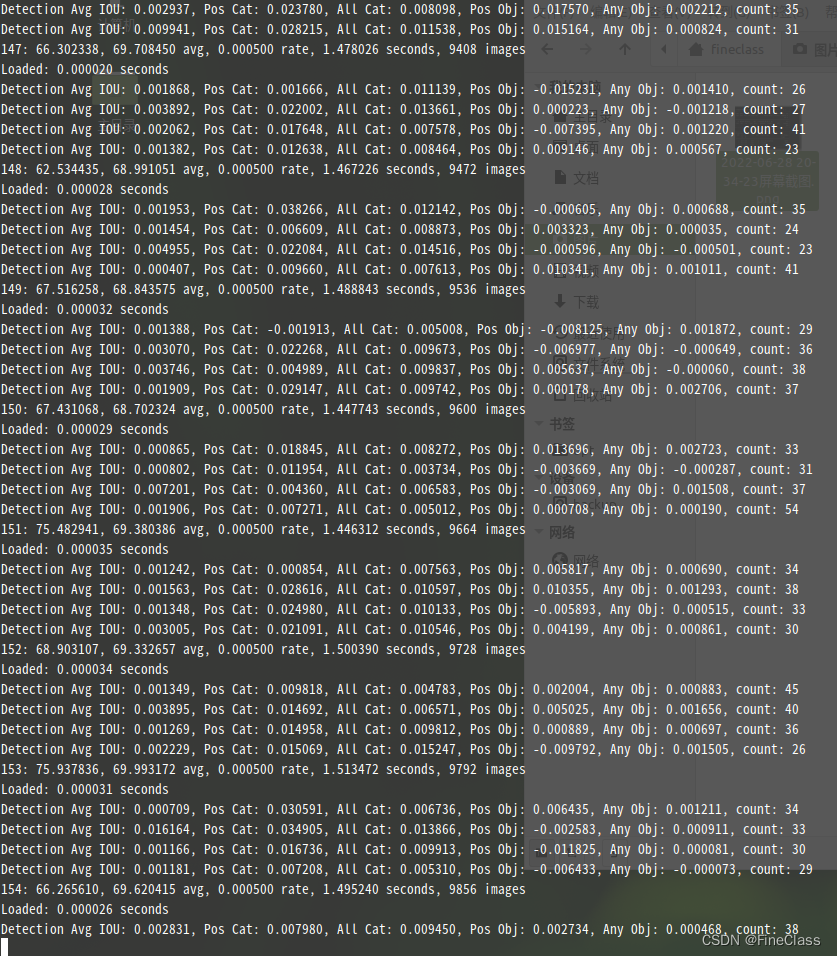
? ? ? ? ?需要14秒一张图,train.txt有16551行,就是有16551张图片,那么
? ? ? ? 14s / 1pic *?16551 pics = 231714s = 64.365小时 = 2.681875天,
? ? ? ? 我这么训练需要3天时间,还不知道训练得对不对。
? ? ? ? 本身只是为了了解训练,所以修改train.txt,保留个300张,训练一个小时,看看会怎么样
??????? 哦,忘了,还得修改cfg/yolov1.cfg
??????????????? 开头
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=8
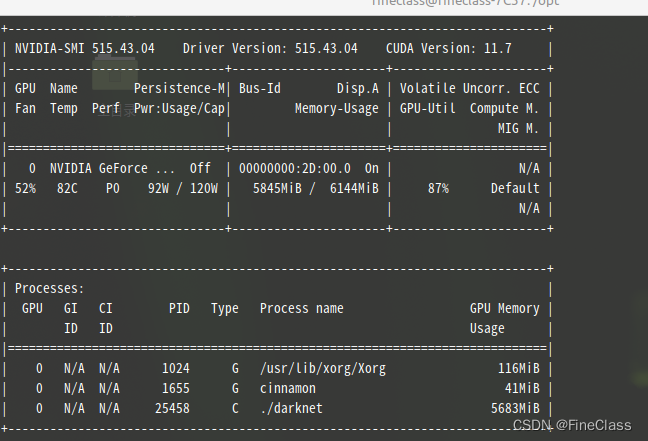
??????? 训练的时候batch=N,可以多张图一起,网上说需要考虑内存(GPU时是显存?)大小来设置batch,
????????batch=64还行,总7.5GiB,用到 5.2GiB(69.2%),减去运行前系统占用,使用了2.4GiB左右
????????CPU训练,处理速度是一样的,还是14秒一张图
??????? 中午吃饭,让它跑着
??????? 。。。一个小时之后,还在跑,i=4, backup下也没有任何东西,看了下代码,
??????? if(i%1000==0 || (i < 1000 && i%100 == 0)){
??????????? char buff[256];
??????????? sprintf(buff, "%s/%s_%d.weights", backup_directory, base, i);
??????????? save_weights(net, buff);
??????? }
??????? 小于1000的时候,每100保存一次,然后每1000保存一次。
??????? 由于设置了batch=64,所以批处理64张图片算一次,然而300/64 ~= 4.6,i到5结束
??????? 再等等,看5之后会不会结束
??????? 不会,再看代码,examples/yolo.c
?while(get_current_batch(net) < net->max_batches){
}
搜索max_batches,啊!啊!啊!
./cfg/yolov1.cfg:21:max_batches = 40000
疯了,白跑了,无奈,
??????? 改吧,
????????if(1/*i%1000==0 || (i < 1000 && i%100 == 0)*/)
??????? 每次都保存
??????? while(/*get_current_batch(net) < net->max_batches*/i < 6)
??????? 把300张训练完
?????? ? 编译,继续一小时训练。。。
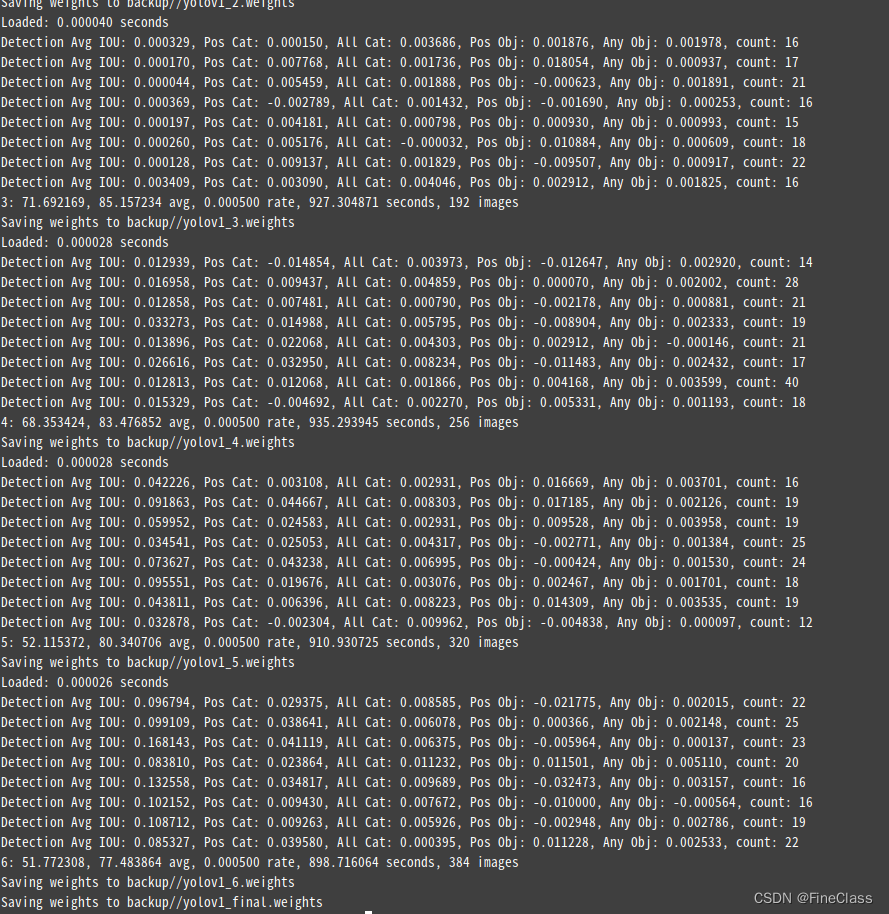
????????batch=64,subdivisions=8, 每次64张,分割8次,所以while() {} 内循环一次,会打印8次Detection,1次结果
??????? 好了,来试下吧,从随机初始化开始训练的,效果可能很差
??????? 接下来是valid验证?面对未知,先tar打个包保存下前面漫长等待的结果
??????? 修改 list *plist = get_paths("scripts/2007_test.txt");,重新编译
??????? 根据train.txt数据量缩减,scripts/2007_test.txt保留前100个(随便点,只是为了了解过程)
./darknet yolo valid cfg/yolov1.cfg backup/yolov1_final.weights
forced: Using default '0'
Learning Rate: 0.0005, Momentum: 0.9, Decay: 0.0005
8
16
24
32
40
48
56
64
72
80
88
96
104
Total Detection Time: 435.000000 Seconds
结果在results下
??????? 看打印好像只学习了cat猫,找两张猫的,在找几张狗马之类的(相似的),再找人车等(差异很大的),测试下
????????./darknet yolo test cfg/yolov1.cfg backup/yolov1_final.weights
输入scripts/VOCdevkit/VOC2007/JPEGImages/000028.jpg
...
boat: 8731119616%
cat: 46369484800%
diningtable: 327312343040%
dog: 46521561088%
horse: 44593692672%
aeroplane: 1450414848%
motorbike: 7307784192%
Not compiled with OpenCV, saving to predictions.png instead
结果为predictions.png

??????? 啥都是
或是?./darknet detect cfg/yolov1.cfg backup/yolov1_final.weights data/dog.jpg
??????? 也啥都是
????????
? ? ? ? 想要看正确结果,下载作者预训练好的权重文件
想要看正常结果,那下载作者训练好的权重
https://pjreddie.com/media/files/yolov1.weights
752.75MB
https://pjreddie.com/media/files/yolov3.weights
236MB
可见两个全连接层参数有约500MB大小
还是老古董下载,这次慢了,只有1~2MB下载速度
./darknet detect cfg/yolov1.cfg ..//yolov1.weights data/dog.jpg
forced: Using default '0'
Loading weights from ..//yolov1.weights...Done!
data/dog.jpg: Predicted in 4.471884 seconds.
train: 55%
好吧,还是不对
? ? ? ? 算了,反正知道训练过程了
使用作者的YOLOv3是没问题的
./darknet detect cfg/yolov3.cfg ..//yolov3.weights data/dog.jpg
Loading weights from ..//yolov3.weights...Done!
data/dog.jpg: Predicted in 16.387323 seconds.
dog: 100%
truck: 92%
bicycle: 99%

-------------------------------------------
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpgdetect是缩减参数命令
具体是
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg? ? ? ? -----------------------------------------------------------
之前没注意,看的是YOLOv3,原来有yolov2、yolov1介绍,
pjreddie.com/darknet/yolov1
pjreddie.com/darknet/yolov2
pjreddie.com/darknet/yolo? ?【yolov3】
------------------------------------------------------------------

这些前面做了,所以代码阅读的地方是正确的
后面就不对了,原来应该这样做

重来:
????????git clone https://github.com/pjreddie/darknet.git
????????cd darknet && git checkout yolov3
? ? ? ? 修改Makefile,没有cudnn cuda gpu,所以,都改为0
? ? ? ? make
????????./darknet yolo test cfg/yolov1/yolo.cfg ../yolov1.weights data/dog.jpg
forced: Using default '0'
Loading weights from ../yolov1.weights...Done!
data/dog.jpg: Predicted in 4.579839 seconds.
dog: 26%
car: 74%
bicycle: 39%
Not compiled with OpenCV, saving to predictions.png instead
训练,把openmp多线程设置为1,不然只有一个线程,很慢
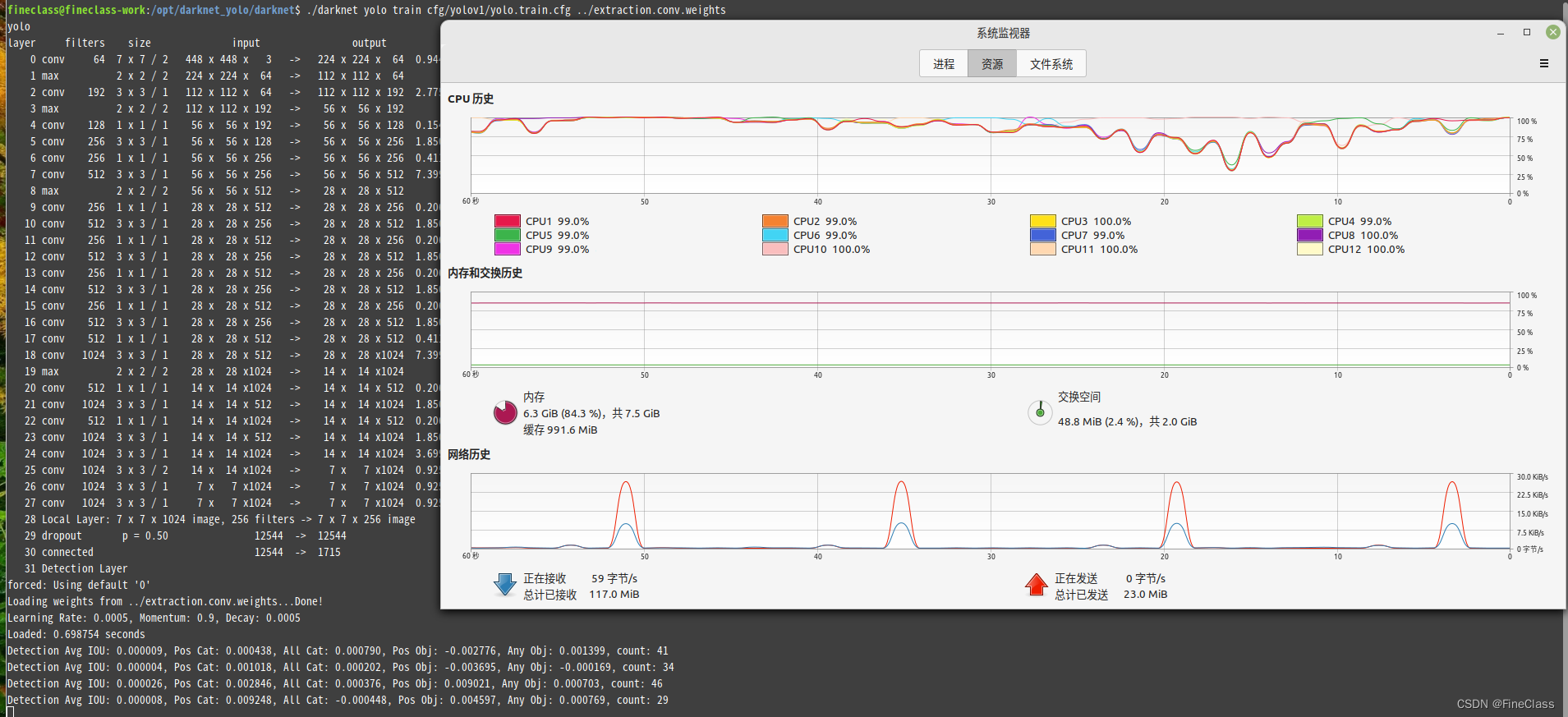
????????具体图像、数据是怎么被处理的?
????????慢慢看吧
---------------------------------------------------------------------
有GPU就是不一样