��ʾ:����д���,Ŀ¼�����Զ�����,������ɿɲο��ұߵİ����ĵ�
ǰ��
�ı�ʶ����ͼ�������һ����������,��������ʶ��OCR������,��Ҫ�ȼ���ͼ��������λ��,�ٶԼ��������ֽ���ʶ��,�ı����ܵ�CRNNģ�Ϳ����ں���, �Լ��������ֽ���ʶ��

An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
ԭ���ĵ�ַ:���ĵ�ַ
һ��CRNNģ�ͽ���
1.ģ�ͽṹ
CRNNģ�ͽ����CNNģ����RNNģ��,CNN������ȡͼ������,RNN��CNN��ȡ���������д����õ����,��Ӧ���յı�ǩ��
CRNN��������,������,ѭ�����ת¼��,����ÿ��ͼ����Ӣ�ĵ��ʵij��Ȳ�һ��,���Ǿ���CNN֮����ȡ������������һ����,���Ծ���Ҫһ��ת¼�㴦��,�õ����ս����
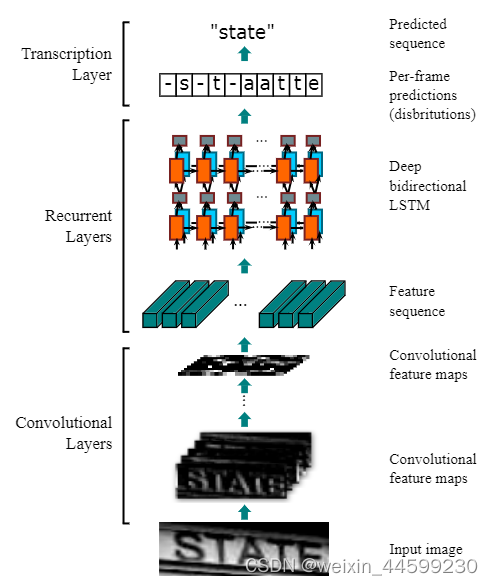
��ͼΪģ�͵Ĵ���ṹ��
����ģ�͵���һ��ͼ��,��shape��(1,32,100) (channel,width,height),
����һ������������֮��,��shape���(512,1,24)(new_channel,new_height,new_width),��channel��height������ά�Ⱥϲ�,�ϲ���shape(512,24),�ٽ�������ά�Ƚ���λ��,(24,512)(new_width,new_height*new_channel),���ں�����Ҫ����ȡ����������ѭ��������,���24���൱����ʱ�䲽��,24��ʱ�䲽���������ͼshape��(24,512)��������Ϊ,��ԭͼ�ֳ�24��,ÿһ����512ά������������ʾ������ͼ��ʾ
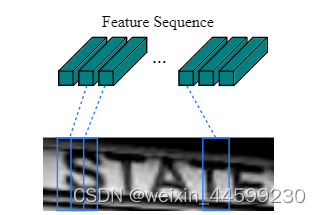
��24���������������ѭ��������,������ѭ���������������LSTM�ѵ����ɵ�,������͵õ�24��ʱ�䲽�����,�پ���ȫ���Ӳ��Լ�softmax��õ�һ�����ʾ���,��״Ϊ(T,num_class),T��ʱ�䲽,num_class��Ҫ����������,��0-9�����Լ�a-z��ĸ���,����һ��blank��ʶ��,�ܹ�37�ࡣʱ�䲽�����24��,����ͼƬ���ַ�����һ������24,���̲�һ,����ת¼�㽫�䴦����
2.CTCLoss
���ʹ�ô�ͳ��loss function,��Ҫ����ѵ������,��24��ʱ�䲽,����Ҫ��24����Ӧ�ı�ǩ,�ڸ���������Ȼ������,���ǿ���ͼƬ�е�ÿһ���ַ�������������,һ���ַ���Ӧһ����ǩ,����Ҫ��ǿ������ּ���㷨,CTCLoss����Ҫ����������
����24��ʱ�䲽�õ�24����ǩ,�ٽ���һ���±任,�ŵõ����ձ�ǩ��24��ʱ�䲽���Կ���ԭͼ�зֳ�24��,ÿһ�����һ����ǩ,��ʱһ����ĸռ�ݺü���,������ĸSռ������,��������������Ӧ����S,�е���û����ĸ,������հ����,������ô���⡣�õ��������ʱ�������ظ����ַ�ȥ��(�հ��������ͬ�ַ���ȥ��,��Ϊ��ʵ��ǩ�п��ܴ��������ظ��ַ�,����green,�е�����������e��Ӧ��ȥ��,�����ɱ�ǩ��ʱ���������e-e����,��ȥ��),����ȥ���հ����ɵõ����ձ�ǩ��
�±任��������
��
:
L
��
T
��
L
<
=
T
\beta :L^{'T} ��L^{<=T}
��:L��T��L<=T
T����ʱ�䲽,����,���ڶ������ظ��ַ�ȥ��,������ij���һ��С��T
�ټ����±任������,�հ���-��ʾ
��
(
?
?
s
s
t
a
a
a
t
?
e
e
)
=
s
t
a
t
e
\beta(--sstaaat-ee)=state
��(??sstaaat?ee)=state
��
(
?
?
s
?
t
t
?
a
?
t
?
e
)
=
s
t
a
t
e
\beta(--s-tt-a-t-e)=state
��(??s?tt?a?t?e)=state
��
(
?
s
?
s
t
?
a
a
t
?
e
)
=
s
s
t
a
t
e
\beta(-s-st-aat-e)=sstate
��(?s?st?aat?e)=sstate
��
(
?
s
?
t
t
a
?
t
t
?
e
e
)
=
s
t
a
t
e
\beta(-s-tta-tt-ee)=state
��(?s?tta?tt?ee)=state
���Կ�������Ҫ���state,��ֹһ��·������ʵ�����state.
����LSTM��Ľ����Ҫ����ת¼�㴦��,��LSTM�������ǩ����Ϊx,�����ǩΪl�ĸ���Ϊ:
p
(
l
�O
x
)
=
��
��
��
��
?
(
l
)
p
(
��
�O
x
)
p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
p(l�Ox)=������?(l)��?p(���Ox)
��
��
��
?
(
l
)
\pi \in \beta ^{-}(l)
������?(l)��ʾ�����±任��Ϊl��·������
��
\pi
��
����ÿһ��·��
��
\pi
����
p
(
��
�O
x
)
=
��
t
=
1
T
y
��
t
t
p(\pi |x)=\prod_{t=1}^{T}y_{\pi ^{t}}^{t }
p(���Ox)=t=1��T?y��tt?
y
��
t
t
y_{\pi ^{t}}^{t }
y��tt?��ʾ��·����t��ʱ�䲽ȡ�øñ�ǩ��һ������,������������ȡ�ø�·���ĸ��ʡ�
CTCLoss���Ż�Ŀ����ʹ��
p
(
l
�O
x
)
=
��
��
��
��
?
(
l
)
p
(
��
�O
x
)
p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
p(l�Ox)=��������?(l)?p(���Ox)���,����
l
o
s
s
=
?
p
(
l
�O
x
)
=
��
��
��
��
?
(
l
)
p
(
��
�O
x
)
loss=-p(l|x)=\sum_{\pi \in \beta ^{-}(l) }p(\pi |x)
loss=?p(l�Ox)=��������?(l)?p(���Ox),ʹ�ø�loss��С��,������ǰ��lstm�Լ�cnn�IJ���,����CTCLoss������Щ����,�ݲ����ۡ�Pytorch���ṩ��CTCLoss�ļ���ӿ�,����ֱ��ʹ�ü��ɡ�
from torch.nn import CTCLoss
beam search
ѵ����ʹ��CTCLoss���²���,���Խ����ʹ�ñ����ⷨ,���ÿ��·����һ������,����ȡ�����ʵ�һ��·��,ʱ�临�Ӷȷdz���,�����37�����,���г�����24,��ô·���ܺ��� 3 7 24 37^{24} 3724,��ֻ��һ��������·���� �����Ծ���Ҫ�õ�beam search���Ż�������̡�
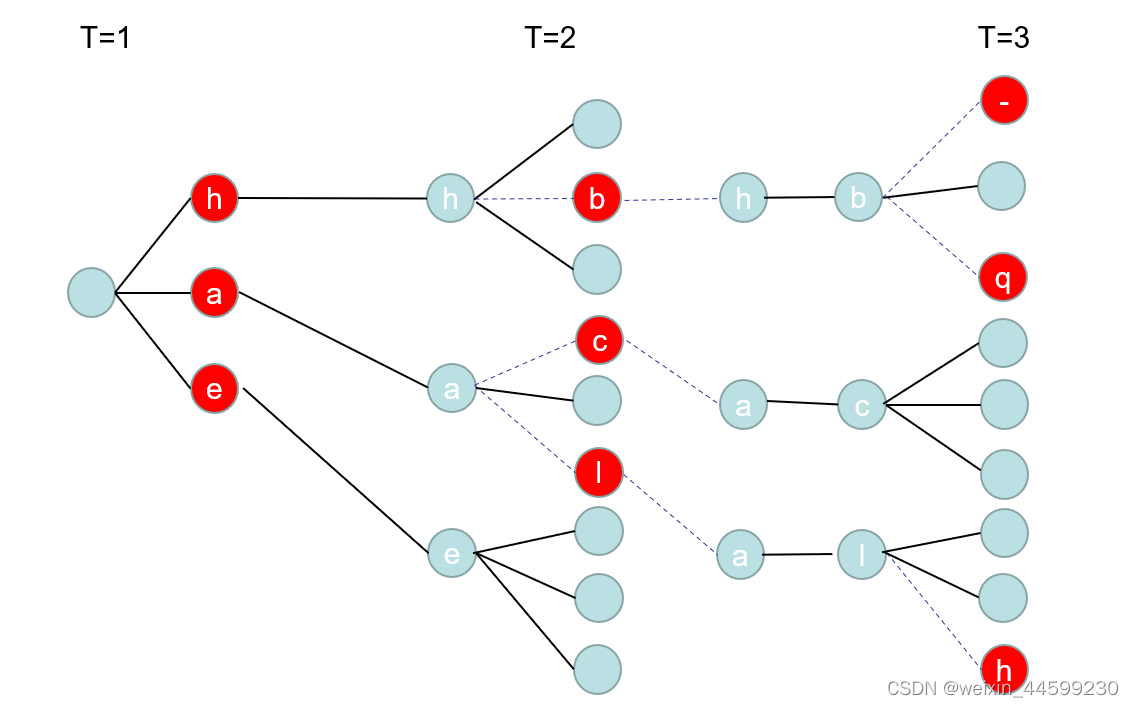
���������ͼ��ʾ,���ڵ�һ��ʱ�䲽���ҵ�����������(������������)����ǩ,�������������ʵı�ǩΪ��������������,�ڵڶ������ڵ�һ���ĸ��ʻ�����(��Ҫ�Ե�һ����������ǩ�ĸ��ʳ��Ժ���ı�ǩ����)�������Ÿ���ǩ,����Ÿ���ǩ��ȡ�������� ,������������,�Դ�����,�ھ������һ��ʱ�䲽���õ�����·��,ȡ������������,�ھ���CTC decode���ɵõ�����label��
����ʹ��pytorchʵ��crnn
���ݼ�
���ü������ݼ��ϲ���������ش���,�õ���ǧ����ͼƬ
ֻ������չʾ�ؼ����ִ���
�����Լ����ݼ���https://gitee.com/yuhailong143/crnn
dataset.py
import os
import torch
from torch.utils.data import Dataset
from PIL import Image
import numpy as np
class Synth90kDataset(Dataset):
CHARS = '0123456789abcdefghijklmnopqrstuvwxyz'
CHAR2LABEL = {char: i + 1 for i, char in enumerate(CHARS)}
LABEL2CHAR = {label: char for char, label in CHAR2LABEL.items()}
def __init__(self, root_dir=None,image_dir = None, mode=None, file_names=None, img_height=32, img_width=100):
if mode == "train":
file_names, texts = self._load_from_raw_files(root_dir, mode)
else:
texts = None
self.root_dir = root_dir
self.image_dir = image_dir
self.file_names = file_names
self.texts = texts
self.img_height = img_height
self.img_width = img_width
def _load_from_raw_files(self, root_dir, mode):
paths_file = None
if mode == 'train':
paths_file = 'train.txt'
elif mode == 'test':
paths_file = 'test.txt'
file_names = []
texts = []
with open(os.path.join(root_dir, paths_file), 'r') as fr:
for line in fr.readlines():
file_name, ext = line.strip().split('.')
text = file_name.split('_')[-1].lower()
file_names.append(file_name + "." + ext)
texts.append(text)
return file_names, texts
def __len__(self):
return len(self.file_names)
def __getitem__(self, index):
file_name = self.file_names[index]
file_path = os.path.join(self.image_dir,file_name)
image = Image.open(file_path).convert('L') # grey-scale
image = image.resize((self.img_width, self.img_height), resample=Image.BILINEAR)
image = np.array(image)
image = image.reshape((1, self.img_height, self.img_width))
image = (image / 127.5) - 1.0
image = torch.FloatTensor(image)
if self.texts:
text = self.texts[index]
target = [self.CHAR2LABEL[c] for c in text]
target_length = [len(target)]
target = torch.LongTensor(target)
target_length = torch.LongTensor(target_length)
# ���DataLoader������collate_fn,��˴�����ֵΪ����DataLoaderʱȡ����ֵ
return image, target, target_length
else:
return image
def synth90k_collate_fn(batch):
# zip(*batch)���
images, targets, target_lengths = zip(*batch)
# stack���������ѵ�����˼��һ��������һ��ά��,Ȼ�������ŵ�ά����,�Ѷ�����������һ���������������������Ƭ,���IJ�������stack,0�ἴ����stack
images = torch.stack(images, 0)
# cat��ָ����ƴ�ӵ���˼��һ��������ά��,�����������������cat��һ��������������
targets = torch.cat(targets, 0)
target_lengths = torch.cat(target_lengths, 0)
# �˴����ص����ݼ�ʹtrain_loaderÿ��ȡ��������,����train_loader,ÿ�ζ���ȡ������ֵ,���˴�����ֵ��
return images, targets, target_lengths
if __name__ == '__main__':
from torch.utils.data import DataLoader
from config import train_config as config
img_width = config['img_width']
img_height = config['img_height']
data_dir = config['data_dir']
train_batch_size = config['train_batch_size']
cpu_workers = config['cpu_workers']
train_dataset = Synth90kDataset(root_dir=data_dir, mode='train',
img_height=img_height, img_width=img_width)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=train_batch_size,
shuffle=True,
num_workers=cpu_workers,
collate_fn=synth90k_collate_fn)
model.py
import torch.nn as nn
class CRNN(nn.Module):
def __init__(self, img_channel, img_height, img_width, num_class,
map_to_seq_hidden=64, rnn_hidden=256, leaky_relu=False):
super(CRNN, self).__init__()
self.cnn, (output_channel, output_height, output_width) = \
self._cnn_backbone(img_channel, img_height, img_width, leaky_relu)
self.map_to_seq = nn.Linear(output_channel * output_height, map_to_seq_hidden)
self.rnn1 = nn.LSTM(map_to_seq_hidden, rnn_hidden, bidirectional=True)
# �����˫��lstm���,��Ҫ *2,�̶��÷�
self.rnn2 = nn.LSTM(2 * rnn_hidden, rnn_hidden, bidirectional=True)
self.dense = nn.Linear(2 * rnn_hidden, num_class)
# CNN��������
def _cnn_backbone(self, img_channel, img_height, img_width, leaky_relu):
assert img_height % 16 == 0
assert img_width % 4 == 0
# ��������
channels = [img_channel, 64, 128, 256, 256, 512, 512, 512]
kernel_sizes = [3, 3, 3, 3, 3, 3, 2]
strides = [1, 1, 1, 1, 1, 1, 1]
paddings = [1, 1, 1, 1, 1, 1, 0]
cnn = nn.Sequential()
def conv_relu(i, batch_norm=False):
# shape of input: (batch, input_channel, height, width)
input_channel = channels[i]
output_channel = channels[i+1]
cnn.add_module(
f'conv{i}',
nn.Conv2d(input_channel, output_channel, kernel_sizes[i], strides[i], paddings[i])
)
if batch_norm:
cnn.add_module(f'batchnorm{i}', nn.BatchNorm2d(output_channel))
relu = nn.LeakyReLU(0.2, inplace=True) if leaky_relu else nn.ReLU(inplace=True)
cnn.add_module(f'relu{i}', relu)
# size of image: (channel, height, width) = (img_channel, img_height, img_width)
conv_relu(0)
cnn.add_module('pooling0', nn.MaxPool2d(kernel_size=2, stride=2))
# (64, img_height // 2, img_width // 2)
conv_relu(1)
cnn.add_module('pooling1', nn.MaxPool2d(kernel_size=2, stride=2))
# (128, img_height // 4, img_width // 4)
conv_relu(2)
conv_relu(3)
cnn.add_module(
'pooling2',
nn.MaxPool2d(kernel_size=(2, 1))
) # (256, img_height // 8, img_width // 4)
conv_relu(4, batch_norm=True)
conv_relu(5, batch_norm=True)
cnn.add_module(
'pooling3',
nn.MaxPool2d(kernel_size=(2, 1))
) # (512, img_height // 16, img_width // 4)
conv_relu(6) # (512, img_height // 16 - 1, img_width // 4 - 1)
output_channel, output_height, output_width = \
channels[-1], img_height // 16 - 1, img_width // 4 - 1
return cnn, (output_channel, output_height, output_width)
# CNN+LSTMǰ�����
def forward(self, images):
# shape of images: (batch, channel, height, width)
conv = self.cnn(images)
batch, channel, height, width = conv.size()
conv = conv.view(batch, channel * height, width)
conv = conv.permute(2, 0, 1) # (width, batch, feature)
# ������ȫ���ӡ�ȫ����������״Ϊ(width, batch, channel*height),
# �����״Ϊ(width, batch, hidden_layer),�ֱ��Ӧʱ��,batch,������,����LSTM����Ҫ��
seq = self.map_to_seq(conv)
recurrent, _ = self.rnn1(seq)
recurrent, _ = self.rnn2(recurrent)
output = self.dense(recurrent)
return output # shape: (seq_len, batch, num_class)
train.py
import os
import cv2
import torch
from torch.utils.data import DataLoader
import torch.optim as optim
from torch.nn import CTCLoss
from dataset import Synth90kDataset, synth90k_collate_fn
from model import CRNN
from evaluate import evaluate
from config import train_config as config
def train_batch(crnn, data, optimizer, criterion, device):
crnn.train()
images, targets, target_lengths = [d.to(device) for d in data]
logits = crnn(images)
log_probs = torch.nn.functional.log_softmax(logits, dim=2)
batch_size = images.size(0)
input_lengths = torch.LongTensor([logits.size(0)] * batch_size)
target_lengths = torch.flatten(target_lengths)
loss = criterion(log_probs, targets, input_lengths, target_lengths)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
def main():
epochs = config['epochs']
train_batch_size = config['train_batch_size']
lr = config['lr']
show_interval = config['show_interval']
valid_interval = config['valid_interval']
save_interval = config['save_interval']
cpu_workers = config['cpu_workers']
reload_checkpoint = config['reload_checkpoint']
img_width = config['img_width']
img_height = config['img_height']
data_dir = config['data_dir']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'device: {device}')
train_dataset = Synth90kDataset(root_dir=data_dir,image_dir='../data/images', mode='train',
img_height=img_height, img_width=img_width)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=train_batch_size,
shuffle=True,
num_workers=cpu_workers,
collate_fn=synth90k_collate_fn)
num_class = len(Synth90kDataset.LABEL2CHAR) + 1
crnn = CRNN(1, img_height, img_width, num_class,
map_to_seq_hidden=config['map_to_seq_hidden'],
rnn_hidden=config['rnn_hidden'],
leaky_relu=config['leaky_relu'])
if reload_checkpoint:
crnn.load_state_dict(torch.load(reload_checkpoint, map_location=device))
crnn.to(device)
optimizer = optim.RMSprop(crnn.parameters(), lr=lr)
criterion = CTCLoss(reduction='sum')
criterion.to(device)
assert save_interval % valid_interval == 0 or valid_interval % save_interval ==0
i = 1
for epoch in range(1, epochs + 1):
print(f'epoch: {epoch}')
tot_train_loss = 0.
tot_train_count = 0
for train_data in train_loader:
loss = train_batch(crnn, train_data, optimizer, criterion, device)
train_size = train_data[0].size(0)
tot_train_loss += loss
tot_train_count += train_size
if i % show_interval == 0:
print('train_batch_loss[', i, ']: ', loss / train_size)
if i % save_interval == 0:
save_model_path = os.path.join(config["checkpoints_dir"],"crnn.pt")
torch.save(crnn.state_dict(), save_model_path)
print('save model at ', save_model_path)
i += 1
print('train_loss: ', tot_train_loss / tot_train_count)
if __name__ == '__main__':
main()
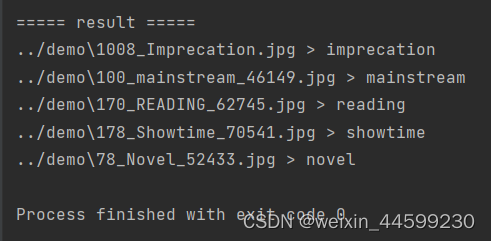
ʶ��Ч���������

������