��Ԥѵ������ģ�͡�WKLM:Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
??֪ʶ��ǿ��Ԥѵ������ģ��ּ�ڽ����ⲿ֪ʶ��Ľṹ��֪ʶ,�ڶ�����ģ�ͽ���Ԥѵ����ʱ����ʽ����ģ��ѧϰ���ṹ��ʵ֪ʶ�����ķ���һƪ����ICLR 2020��֪ʶ��ǿԤѵ���Ĺ�����
����Ҫ��:
- ͨ��Replacement�IJ��������ⲿ֪ʶ:�����ı��е�ʵ��(entity mention),�����ѡ֪ʶ����ͬ���͵�����ʵ����Ϊ�滻;
- ������ල��Ԥѵ��Ŀ�ꡪ���ж�ʵ���Ƿ��滻;
- ��������:����Ҫ̫���ʵ����Ϣ������Ҫ���ӻ���Ԥѵ������ģ�͵Ľṹ;
��Ҫ��Ϣ:
| ��� | ���� | ֵ |
|---|---|---|
| 1 | ģ������ | WKLM |
| 2 | ����� | ICLR 2020 |
| 3 | �������� | ��Ȼ���Դ�����Ԥѵ������ģ�� |
| 4 | �о����� | ֪ʶ��ǿ������ģ�� |
| 5 | �������� | Knowledge-enhanced PLM |
| 6 | GitHubԴ�� | |
| 7 | https://openreview.net/pdf?id=BJlzm64tDH |
һ������
- Ԥѵ������ģ�Ϳ�����ģ��ѧϰ��һ�����Ե����������Ϣ,������Ǩ�Ƶ����ε���������;Ԥѵ������ģ��Ҳ������һЩ��Ҫ���������������ϴﵽ������Ч��;Ȼ��ԭʼ���ı�ȴ����ȫ������ȷ��ʵ����Ϣ;
These tasks are carefully designed so that the text input alone does not convey the complete information for accurate predictions �C external knowledge is required to fill the gap
- ���е�Ԥѵ��Ŀ����ǻ���token-level,����û����ʽ�Ķ�ʵ����н�ģ;
However, existing pretraining objectives are usually defined at the token level and do not explicitly model entity-centric knowledge.
encyclopedic knowledge about real-world entities
??WKLM�����֮��,�����ϻ�ֻ��ERNIE��������֪ʶ��ǿģ��,�����������������Ҳ��ȫ���ϵ�ǰ��Ԥѵ���������濼��,��,����ܹ���ģ�Ϳ�����Ч��ѧϰ��֪ʶ,�Լ���������������ģ�顣
??���ĵ���Ҫ������:
- ��չ�����е�֪ʶ��ȫ(Knowledge Graph Completion)���Ԥѵ������ģ����,������Ԥѵ������ģ�ͶԳ�ʶ֪ʶ������ͱ�������;
- ���һ���µ����ලԤѵ���������ôӷǽṹ�����ı��в�ʵ����Ϣ;
��������:Entity Replacement Training
??��������ϸ����WKLMģ�������ģ��ѧϰ��֪ʶ��
??����,����һ���ල�ľ���,ʹ��һЩ�ִʹ���ʶ�����Ӧ��entity mention,����Wikipedia���ж��롣
��Ϊ���Ϻ�֪ʶ��ȫ������Ӣ��Wikipedia,���ʵ�ֶ�Wikipedia�����ϻ�ȡ�����ݴ����Լ�֪ʶ�����,�ɲο���������һƪ���:
??������һ�ּ���,��ʹ��ʵ����ָ������Ϊ����ȫ��ȷ��,���,���д�ԭʼ���ı���ʶ���ʵ�嶼��Ϊ����ȷ��(positive statement),Ϊ����ģ�Ϳ���ѵ��,�����Ҫ����negative�������ʵ�ַ������Լ�����Ϊ:��ij��ʶ�����ʵ��(entity mention),ѡ�������ͬentity type������entity�����滻��
����������Ϊ��,��������ǡ��й������DZ�����,���С����������ڳ�������ʵ�塣�ڹ���������ʱ,�����ѡ���Ϻ������滻��������,��Ϊ���Ƕ����ڳ�������ʵ�塣
??�������˸�����,��������Ϊ��ǰ�ľ��Ӵ��ڴ������Ϣ,�����������ģ���ܹ������������������жϾ����е�ÿһ��ʵ���Ƿ��Ѿ����滻��ѵ��Ŀ��Ϊ:
J e , C = I e �� E + log ? P ( e �O C ) + ( 1 ? I e �� E + ) ( 1 ? log ? P ( e �O C ) ) J_{e, \mathcal{C}}=\mathbb{I}_{e\in\mathcal{E}^+}\log P(e|C) + (1 - \mathbb{I}_{e\in\mathcal{E}^+})(1 - \log P(e|C)) Je,C?=Ie��E+?logP(e�OC)+(1?Ie��E+?)(1?logP(e�OC))
���� E + \mathcal{E}^+ E+ ��ʾ������ȷ��ʵ��, I e �� E + \mathbb{I}_{e\in\mathcal{E}^+} Ie��E+?���ʾ�����ǰ�����е�ij��ʵ�� e e e����ȷ��,���Ӧϵ��Ϊ1,����Ϊ0�� C \mathcal{C} C���ʾ��ǰ�ľ��ӡ����,������ѵ��Ŀ��Ҳ������Ϊ�Ƕ�ÿһ��ʵ����ж����ࡣ
??����������������ͼ��ʾ:
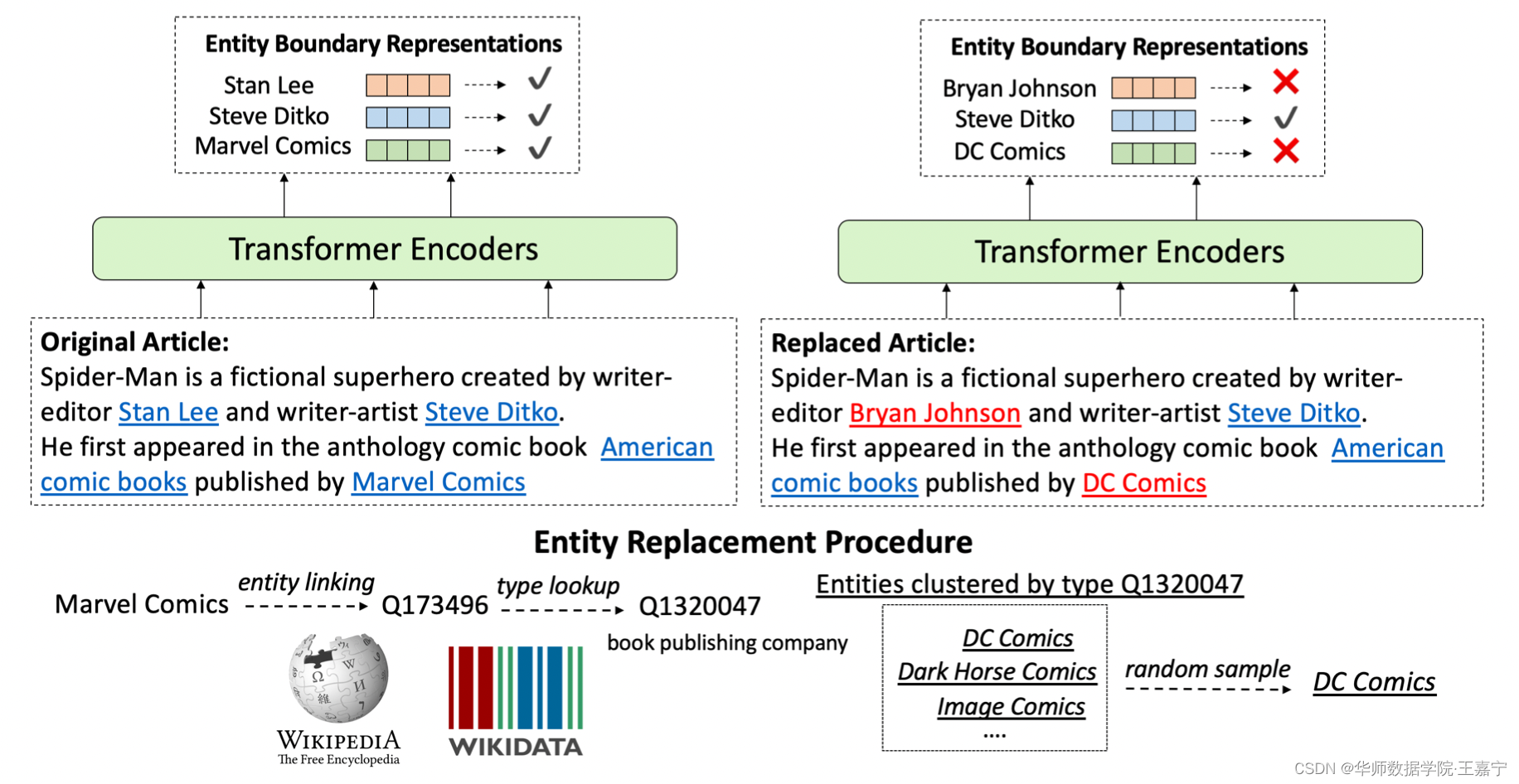
(1)Replacement
??����һ���ı���,���Dz��滻����entity mention�� ���仰˵,�κ��������滻��ʵ��֮�����������һ��δ���滻��ʵ�塣 ������������滻ͬһ�����е�����ʵ�岢�ҽ����������������ȷʵ������
(2)Model
??��ȫѡ��BERT-base�ļܹ�,���Լ��������Ԥѵ������;
Ԥ�ⲿ��:ѡ��entity mention boundary representation(entity before��after���ֵ�representation����ƴ��),��ι��MLP�н��ж�����;
(3)Training Objectives
- ��Ȼʹ��Masked Language Modeling����,��ȷ������entity mention�Ͻ���mask;
When masking tokens, we restrict the masks to be outside the entity spans.
- �����ѡ5%��token����mask;
We use a masking ratio of 5% instead of 15% in the original BERT to avoid mask- ing out too much of the context
- ѵ��ʱ,Ϊ������ѵ��:MLM+entity replacement binary classification,batch_size=128
����ʵ��
??ʵ����������֪ʶͼ�ײ�ȫ���ʴ�Ͷ�����ʵ����ࡣ
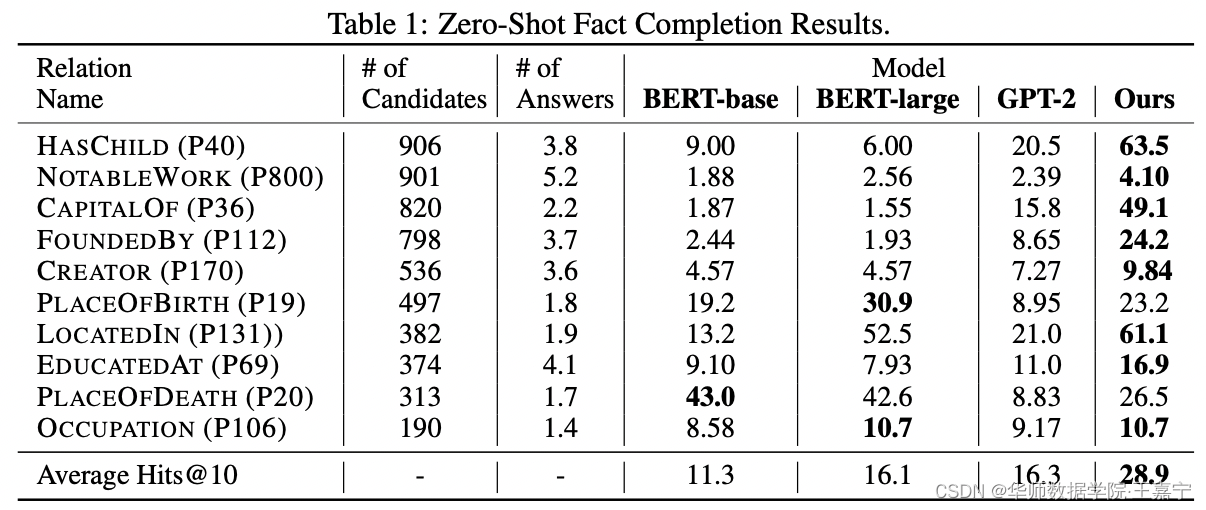
(1)֪ʶ��ȫ(Fact Completion)
??Ϊÿ����Ԫ�鹹��Ϊ�ı�����,���� {Paris, CapitalOf, France} �� the capital of France is Paris�������maskһ��ʵ��,��ģ�ͽ���Ԥ�⡣10��relations�ֱ�1000������������ָ��ѡ��Hits@10��
??����ѡ��Wikidata��Ϊ֪ʶ��(Wikidata�ǽ�Ϊ����Ļ���Ӣ��Wikipedia��֪ʶͼ�ײ�ȫ��������,���ݼ����ص�ַ:https://deepgraphlearning.github.io/project/wikidata5m),ʵ��Ч������ͼ��ʾ:
(2)�ʴ�(Question Answering)
??�ʴ���Ҫ������ȡʽ�Ķ����⡢�����ʴ�(֪ʶͼ���ʴ�)��������ѡ��4����ͬ���ʴ����ݼ�,����WebQuestion��TriviaQA��Quasar-T��SearchQA��ʵ����������ʾ:
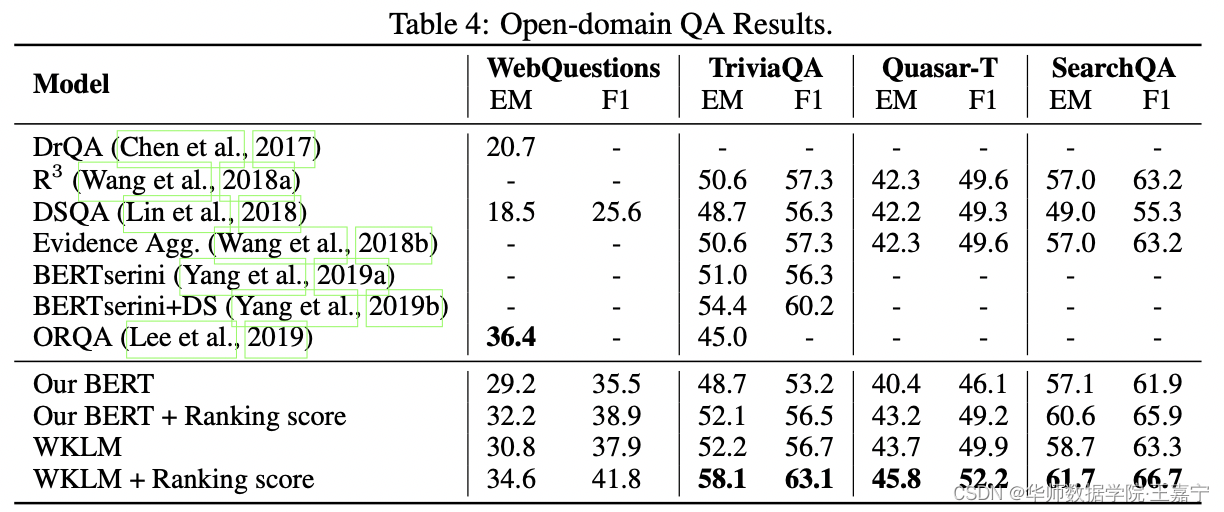
��ʵ����Է���,�����WKLM���ʴ����ݼ������沢������,�ڲ������ݼ��ϲ�������ǰ����������Ҫ��������ȡ������Ƶĺ���ranking score��
??����Ҳ��SQuAD����������,������ʾ:

ͬbase�����ģ�ͶԱ�,��������Լ1�������ҡ�
����Question Answering�����йصĸ���ϸ��,�ɲο���������ؽ��ר��:�ʴ�ϵͳ
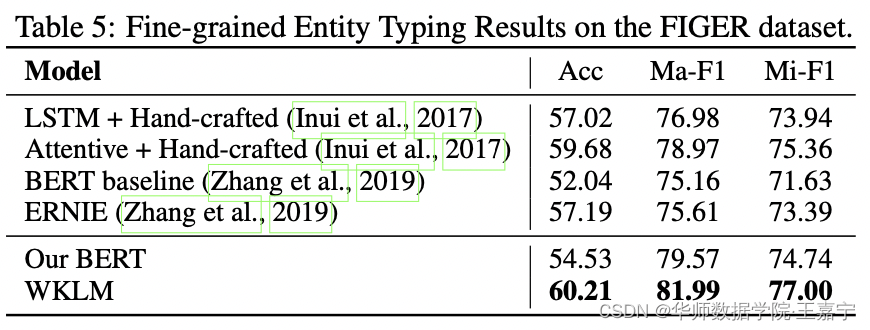
(3)ʵ�����(Entity Typing)
??ʵ�����ּ�ڸ���һ������,�Լ������е�һ��ʵ��mention,�����Ŀ���Ƕ�ָ����ʵ����з��ࡣ����ѡ��FIGER���ݼ���������,ʵ��������ͼ��ʾ:
�ܽ�:
- WKLM������һ��֪ʶ��ǿԤѵ�����Ⱥ�,������ٶ�ERNIEģ�������entity masking��whole word masking,WKLM����entity replacement�IJ���,����ģ��ȥ�ж�ʵ���Ƿ��DZ��滻��(����Ϊʵ���Ƿ���ȷ)�����������MLM����Ӽ�,��Ϊ�����ռ�ֻ��2����Ĵ�С����ʵ��,����replacement��˼��Ҳ������DeBERTa�����,��Ϊ��Ϊ��ȴ��Ч������ģ�����ܵIJ��ԡ�
- ��ȻWKLMҲ�в���֮��,�����������һ�ּ���,�����е���ָ������ʶ���ʵ��һ������ȷ�ġ����Ƕ������ĵ��������ʵ�ֶ��ı��е�ʵ�����ȷ���ھ�(Ŀǰ����������δ��������TagMe�Ŀ�Դ����)������,����ĸ�����Ҳ����֤����������ʵ��һ���Ǵ����,�������ٸ�������,������Ϊδ���Ľ��IJ��֡�