本系列博客包括6个专栏,分别为:《自动驾驶技术概览》、《自动驾驶汽车平台技术基础》、《自动驾驶汽车定位技术》、《自动驾驶汽车环境感知》、《自动驾驶汽车决策与控制》、《自动驾驶系统设计及应用》,笔者不是自动驾驶领域的专家,只是一个在探索自动驾驶路上的小白,此系列丛书尚未阅读完,也是边阅读边总结边思考,欢迎各位小伙伴,各位大牛们在评论区给出建议,帮笔者这个小白挑出错误,谢谢!
此专栏是关于《自动驾驶汽车环境感知》书籍的笔记.
3.多传感器前融合技术
前融合技术:指在原始数据层面,把所有传感器的数据信息进行直接融合,然后根据融合后的数据信息实现感知功能,输出一个结果层的探测目标。
常见的基于神经网络的融合方法,如:MV3D(Multi-View 3D Object Detection)、AVOD(Aggregate View Object Detection)、F-PointNet(Frustum PointNets for 3D Object Detection)等。
3.1 MV3D
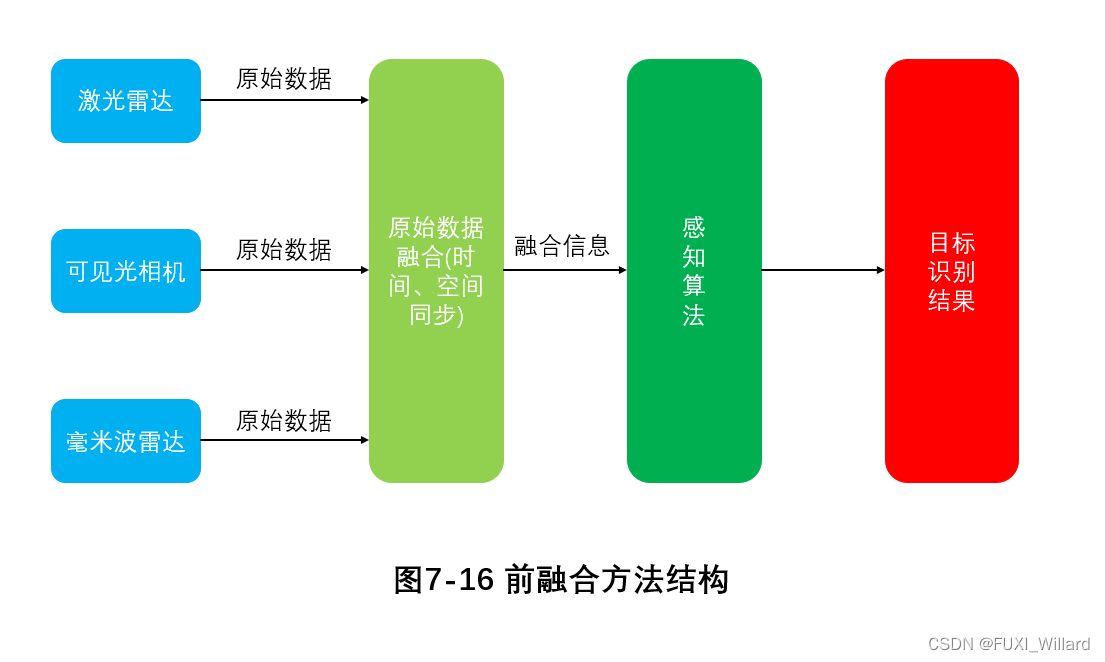
MV3D将激光雷达探测的点云数据和可见光摄像头拍摄的RGB图像进行融合,其输入数据为激光雷达投影的鸟瞰图(LIDAR bird view)、前视图(LIDAR front view)和二维RGB图像,其网络结构主要有三维区域生成网络(3D proposal network)和基于区域的融合网络(region-based fusion network),使用深度融合(deep fusion)方式进行融合,如下图:
激光雷达点云数据是一个无序的数据点构成的集合,在用设计好的神经网络模型处理点云数据前,为了更加有效保留三维点云数据的信息,方便处理,MV3D将点云数据投影到特定的二维平面,得到鸟瞰图和前视图。
3D proposal network,类似于Faster-RCNN检测模型中应用的区域生成网络(Region Proposal Network,RPN),并在三维推广,实现的一个功能就是生成目标的三维候选框;这部分功能在鸟瞰图中完成,鸟瞰图的各个目标遮挡较少,候选框提取的效率最好。
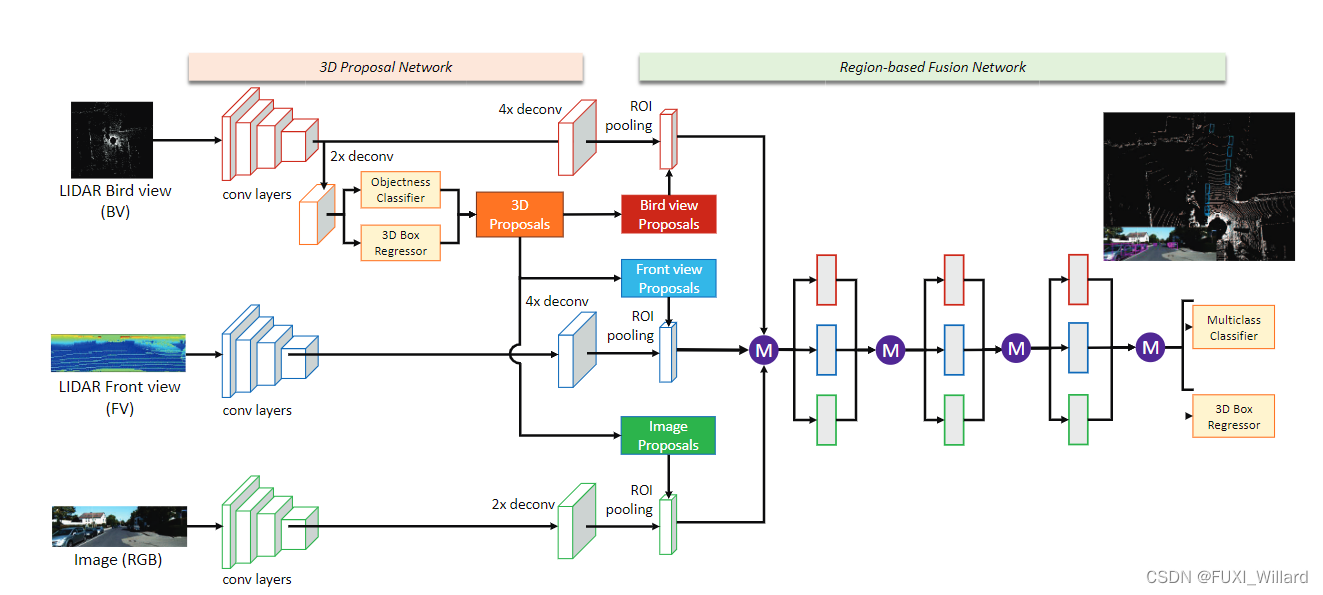
在提取候选框后,分别向三种图中进行映射,得到各自感兴趣区域(Region of Interest,ROI),进入region-based fusion network进行融合;在融合方式选择上,有:早期融合(early fusion)、后期融合(late fusion)、深度融合(deep fusion),三种方式对比如下图:
论文原文链接
3.2 AVOD
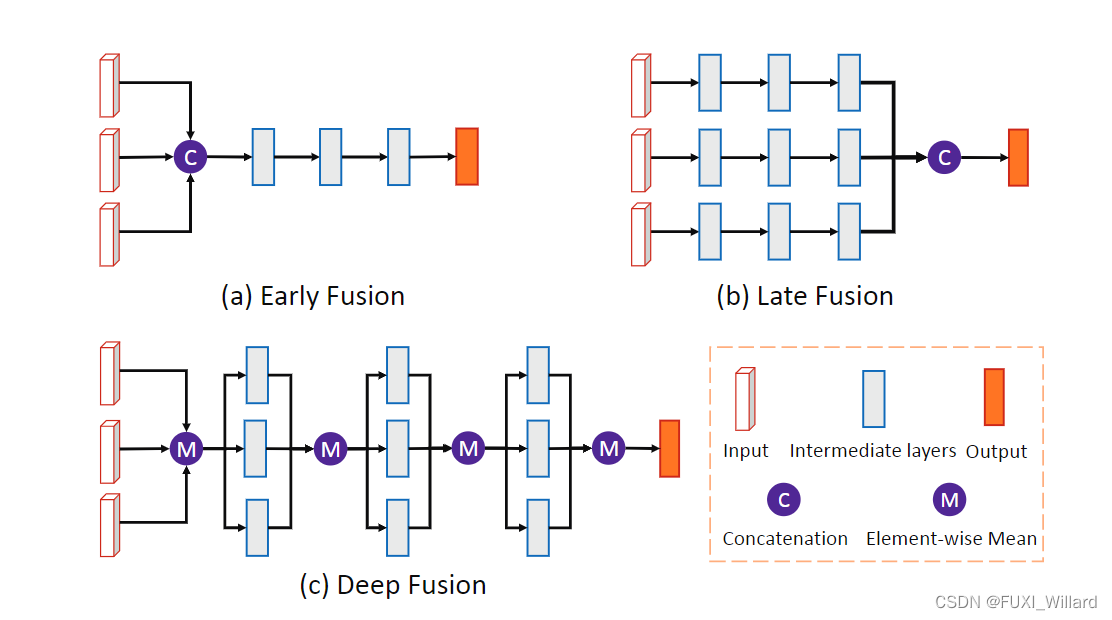
AVOD是一种融合激光雷达点云数据及RGB图像信息的三维目标检测算法,其输入只有激光雷达生成的鸟瞰图(Bird’s Eye View,BEV)Map和摄像头采集的RGB图像,舍弃了激光雷达前向图(Front View,FV)和BEV中的密度特征(intensity feature),如下图所示:

对输入数据,AVOD先进行特征提取,得到两种全分辨率的特征映射,输入到RPN中生成没有朝向的区域建议,最后挑选出合适的提议候选送入到检测网络生成带有朝向的三维界框,完成目标检测任务;AVOD存在两处传感器数据融合:特征融合和区域建议融合。
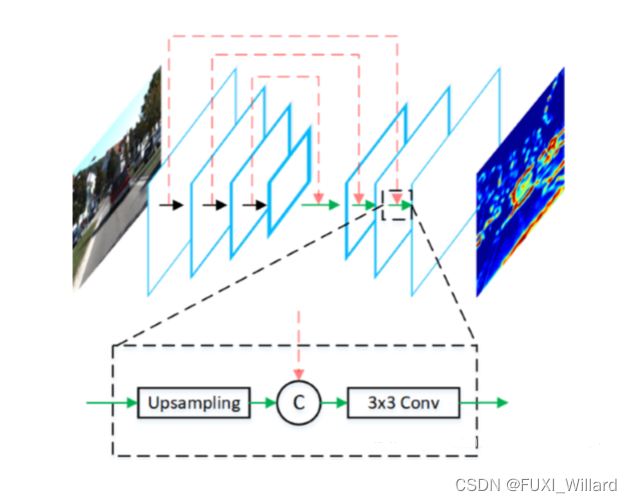
上图说明:上图是AVOD特征提取网络,使用了编码器-解码器(encoder-decoder)结构,每层解码器先对输入进行上采样,然后与对应编码器的输出串联,最终通过一个3×3的卷积进行融合;该结构可以提取到分辨率的特征映射,有效避免了小目标物体因为下采样在输出的特征映射上所占像素不足1的问题,最终输出的特征映射既包含底层细节信息,又融合了高层语义信息,能有效提高小目标物体的检测结果。
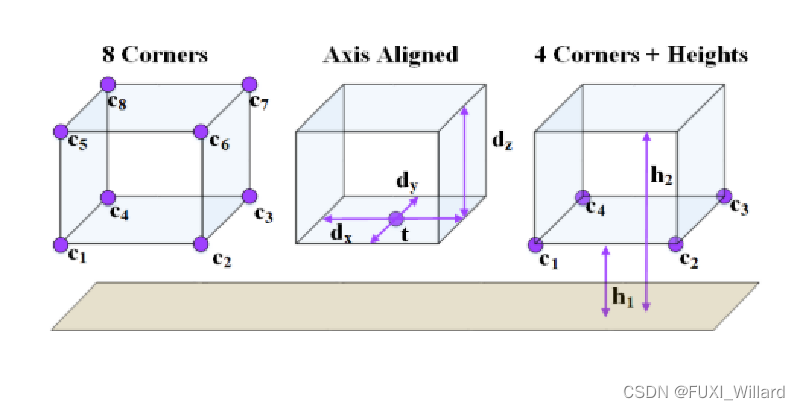
上图说明:上图是三种边界框编码方式,从左到右依次是:MV3D、轴对齐、AVOD的三维边界框编码方式,与MV3D指定八个顶点坐标的编码方式相比,AVOD利用一个底面和高度约束了三维边界框的形状,且只用一个10维的向量表示即可,MV3D需要24维的向量表示。
3.3 F-PointNet
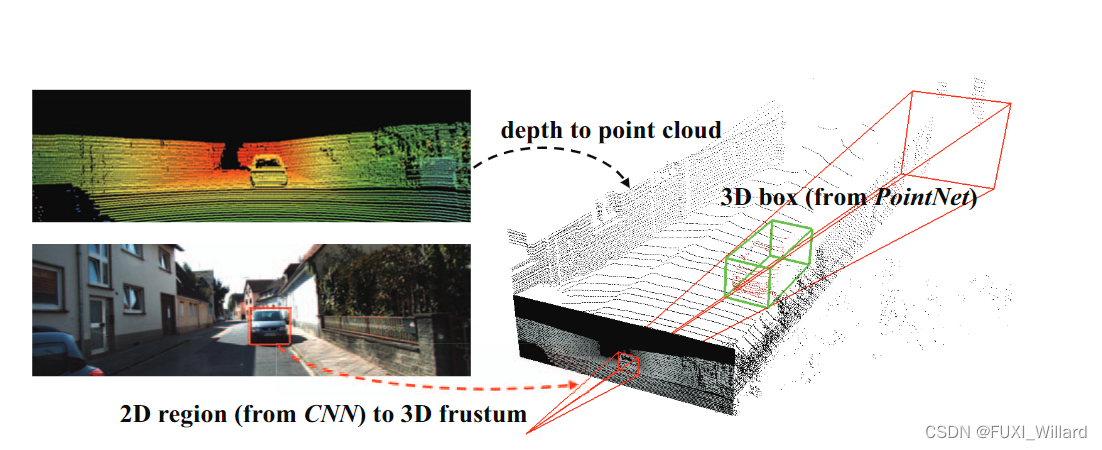
F-PointNet结合成熟的二维图像中的目标检测方法来对目标进行定位,得到对应三维点云数据中的视锥体(frustum),并对其进行边界框回归从而完成检测任务,如下图所示:
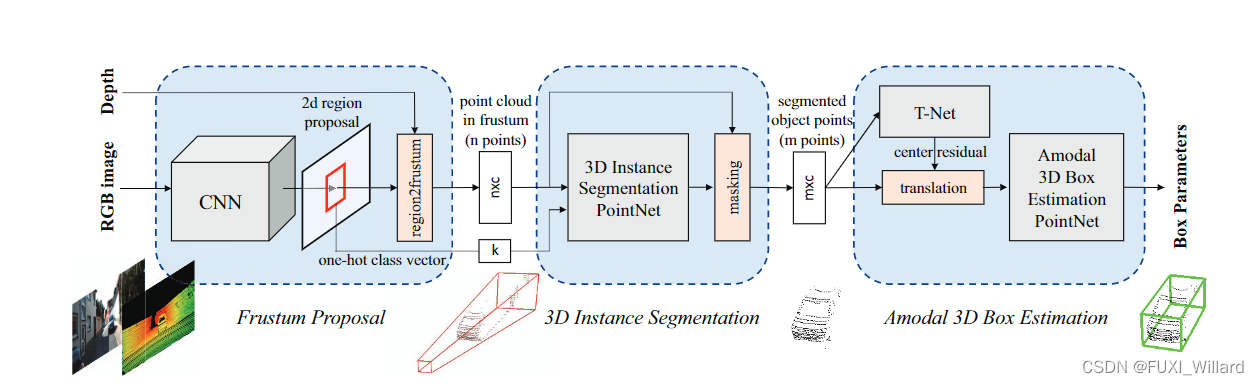
F-PointNet整个网络结构由三部分组成:视锥体(frustum proposal)、三维实例分割(3D instance segmentation)、三维边界框回归(amodal 3D box estimation);网络结构如下图所示:
F-PointNet利用RGB图像分辨率高这一优点,采用基于FPN的检测模型先得到目标在二维图像上的边界框,然后按照已知的摄像头投影矩阵,将二维边界框提升到定义了目标三维搜索空间的视锥体,并收集截体内的所有点构成锥体点云;
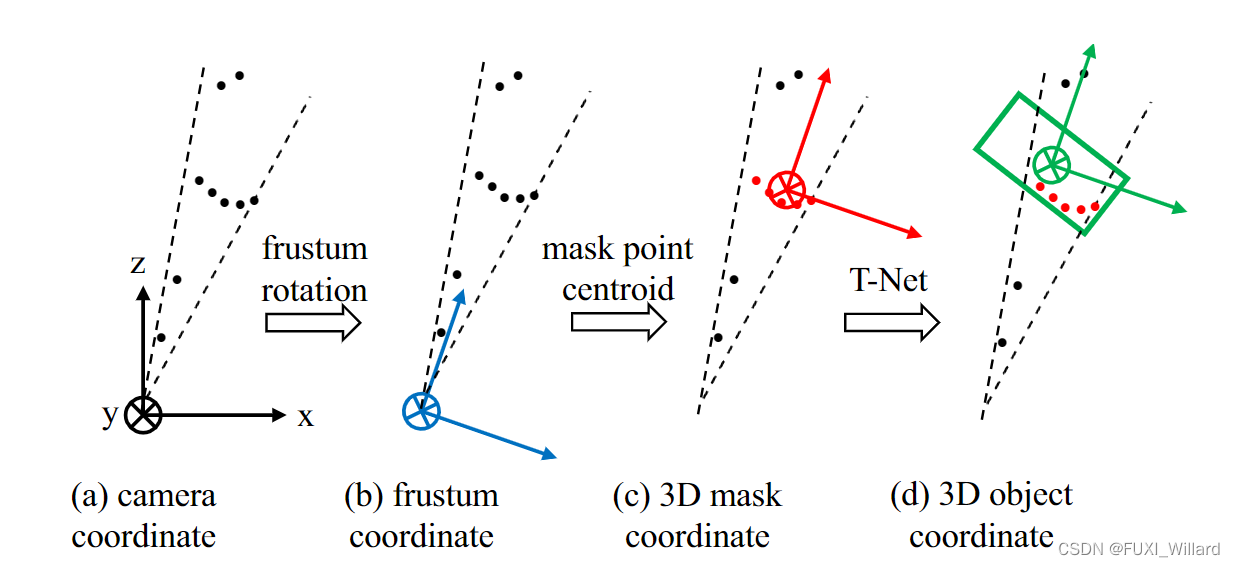
上图说明:图(a)是摄像头坐标系,图(b)是锥体坐标系,图( c )是三维掩膜局部坐标系,图(d)是T-Net预测的3D目标坐标系;为了避免遮挡和模糊问题,对锥体点云数据,F-PointNet使用PointNet(或PointNet++)模型进行实例分割;在三维空间中,物体间大都是分离的,三维分割更可靠;通过实例分割,可以得到目标物体的三维掩膜(即属于该目标的所有点云),并计算其质心作为新的坐标原点,如图( c )所示,转换为局部坐标系,以提高算法的平移不变性;最后,对目标点云数据,F-PointNet通过使用带有T-Net的PointNet(或PointNet++)模型进行回归操作,预测目标三维边界框的中心、尺寸和朝向,如图(d)所示,最终完成检测任务;T-Net的作用是预测目标三维边界框真实中心到目标质心的距离,然后以预测中心为原点,得到目标坐标系。
小结:
F-PointNet为了保证每个步骤点云数据的视角不变性和最终更加准确地回归三维边界框,共需要进行三次坐标系转换,分别是视锥体转换、掩膜质心转换、T-Net预测。
论文原文链接