ЧАбд
ЪВУДЪЧШЫЙЄжЧФм?ЕББЛЮЪЕНетИіЮЪЬтЪБ,ЮвУЧКмШнвзСЊЯыЕНвЛИіР§зг:ИјМЦЫуЛњЗЂвЛеХЭМЦЌ,МЦЫуЛњИљОнЭМЦЌжаЕФвЛаЉЬиеї,ХаЖЯЭМЦЌжаетИіЖЏЮяЪЧУЈЛЙЪЧЙЗЁЃЫЕЕНAIphaGo,ЮвЯыФувВВЛЛсФАЩњ,ЁА17Фъ3:0ЭъЪЄЪРНчЙкОќПТНрЁБШУДѓМвецЧаИаЪмЕНAIЕФЭўСІЁЃетСНИіПДЫЦЬьВюЕиБ№ЕФР§зг,ЦфЪЕПЩвдгУвЛжжФЃаЭРДБэЪі,ФЧОЭЪЧЗжРрЁЃВЛЭЌЕФЪЧЧАУцЕФНсЙћЖгСажЛгаСНИіВЮЪ§:УЈ/ЙЗ,вЊУДЪЧ[1,0],вЊУДЪЧ[0,1],ЖјAIphaGoЕФНсЙћЖгСа,ПЩвдга19*19ИіВЮЪ§жЎЖрЁЃ2017ФъШЫЙЄжЧФмЪзДЮБЛЬсЩ§ЕНЙњМвеНТдВуУц,ЫцКѓМИФъИїЕиИќЪЧЮЇШЦШЫЙЄжЧФмПЊеЙСЫжюЖрММЪѕЛЏЁЂВњвЕЛЏВМОжЁЃ
дкЛЅСЊЭјаавЕ,ШЫЙЄжЧФмИќЪЧЩцМАЗНЗНУцУц:ШЫСГЪЖБ№ЁЂгябдДІРэЁЂздЖЏМнЪЛЁЂжЧФмЭЦМіЁГадиAIМЏШКЕФЛљДЁЩшЪЉЮвУЧГЦжЎЮЊЁАжЧЫужааФЁБ,БОЮФЮвНЋЮЊДѓМвНщЩмЛЅСЊЭјжЧЫуМмЙЙЕФвЛаЉжЊЪЖЁЃ
ДѓФЃаЭ
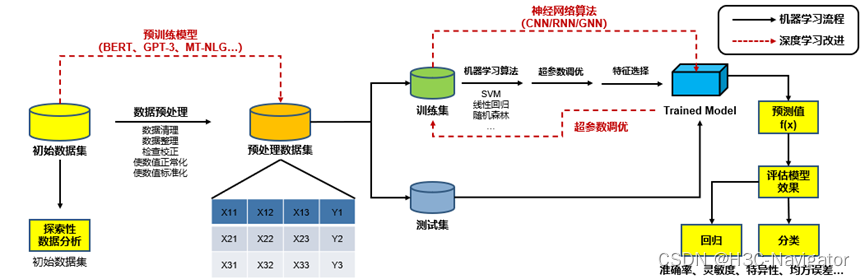
ЛњЦїбЇЯА(ML)ЪЧШЫЙЄжЧФмжаКмживЊвЛВПЗж,ЖјЩюЖШбЇЯА(DL)дђЪЧЛњЦїбЇЯАжаКмживЊЕФзщГЩЁЃЕЋЪЧдк2020ФъвдКѓ,дНРДдНЖрЕФвЕЮёПЊЪМгІгУFoundation Models,вВБЛГЦЮЊЁАДѓФЃаЭЁБЁЃ
ЯТЭМЪЧML/DLЕФДІРэСїГЬЪОР§:
ЖдБШML,DLНЋжюЖрЫуЗЈЭГвЛГЩЩёОЭјТчЫуЗЈ,АќРЈCNN(ОэЛ§ЩёОЭјТч)ЁЂRNN(бЛЗЩёОЭјТч)вдМАGNN(ЭМаЮЩёОЭјТч)ЕШ,ВЛЭЌЕФЩёОЭјТчФЃаЭдкВЛЭЌЕФбЕСЗГЁОАФмДјРДВЛвЛбљЕФаЇЙћЁЃ
DLЕФСэЭтвЛИіЩ§МЖЕуОЭдкгкЪ§ОндЄДІРэНзЖЮ:вЕЮёВњЩњЕФДјБъЧЉЕФЪ§ОнЪЧМЋЦфШБЗІЕФ,ИќЖрЕФЪ§ОнЪЧРДздЛЅСЊЭјЩЯЕФЮоБъЧЉЪ§Он,ДЫЪБЮвУЧашвЊвЛИіФЃаЭНјааЪ§ОнЕФдЄДІРэЛђепЮоБъЧЉбЕСЗ,ЮвУЧЪьжЊЕФBERTЁЂGPT-3ЁЂMT-NLGЁОЭЪЧетжждЄбЕСЗФЃаЭЁЃ
ДѓФЃаЭЭљЭљвдФЃаЭВЮЪ§ЖрЁЂЩёОдЊЪ§СПЖрЁЂЩёОЭјТчВуЪ§ЖрЖјжјУћ,дкетаЉвђЫиЕФМгГжЯТ,ЁАДѓЙцФЃЪ§Он+ДѓФЃаЭЁБЕФФЃЪНдНРДдНЖрЕУБЛгІгУЕНжюЖрЛЅСЊЭјЙЋЫОЕФжЧЫуМмЙЙжаЁЃ
ЗжВМЪНВПЪ№
ЁАДѓФЃаЭЁБОПОЙгаЖрДѓ?ЮвУЧЭЈЙ§вЛИіР§згРДИаЪмвЛЯТ:
OpenAIЗЂВМЕФGPT-3,вЛОУцЪРе№ОЊAIНч,ЫќАќКЌ1750вкИіВЮЪ§,етШУЩёОЭјТчжЎИИGeoffrey HintonВЛНћИаЬОЁАМјгк GPT-3 дкЮДРДЕФОЊШЫЧАОА,ПЩвдЕУГіНсТл,ЩњУќЁЂгюжцКЭЭђЮяЕФД№АИ,ОЭжЛЪЧ 4.398 ЭђвкИіВЮЪ§ЖјвбЁБЁЃШЛЖјЭъећбЕСЗвЛДЮGPT-3ЫљКФЗбЕФЫуСІвВЪЧОЊШЫЕФ,АДееNVIDIAЕФЪ§Он:бЕСЗвЛДЮДѓаЭGPT-3,ЪЙгУ2wПХA100ашвЊЯћКФ5ЬьЪБМф,ЪЙгУ2wПХH100вВашвЊЯћКФ19ИіаЁЪБ,ећЬхЯћКФЫуСІПЩДя10EFlops-Days!етЯдШЛВЛЪЧвЛПХGPUЛђепвЛЬЈGPUНкЕуЫљФмГадиЕФ,вђДЫЗжВМЪНГЩЮЊAIМЏШКЕФжїСїВПЪ№ФЃЪНЁЃ
ЬнЖШЯТНЕЪЧAIбЕСЗжаНјааВЮЪ§ЕќДњЕФзюГЃгУЪжЖЮ,е§ГЃРДНВЮвУЧЛсАбЫљгазЪСЯМЏNМЦЫувЛДЮЫуГівЛИіLoss,ЕЋЪЧетбљЕФзіЗЈКФЪБКФСІЧвНсЙћвЛАуЁЃвђДЫЪЕМЪбЕСЗжа,ЮвУЧЛсАбNЛЎЗжГЩШєИЩЕФзгМЏ,ЮвУЧГЦжЎЮЊBatchЁЃЭЈЙ§вЛДЮBatchдЫЫуМЦЫуГівЛИіLoss,ИљОнетИіLossЭъГЩвЛДЮВЮЪ§ЕќДњ,ШЛКѓНјааЯТвЛИіBatchдЫЫу,вРДЮНјааЁжБЕНЫљгаBatchдЫЫуЭъГЩЁЃетбљЫљгаЕФBatchЖМЙ§ЭъвЛДЮ,ЮвУЧГЦжЎЮЊ1 epochЁЃећИіЙ§ГЬШчЯТЭМЫљЪО:
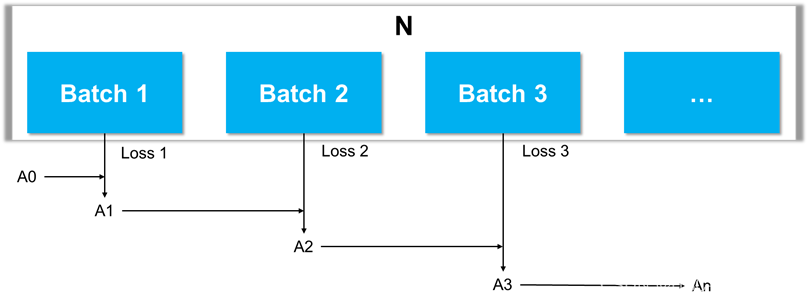
вдЩЯЪЧФЃаЭбЕСЗЕФвЛИіТпМЫМТЗ,ШЛЖјЪЕМЪЕФМЏШКжаашвЊГфЗжРћгУКУGPUзЪдД,вдИпаЇТЪЁЂИпРћгУТЪвдМАИпзМШЗТЪЕФзМдђЭъГЩAIбЕСЗЁЃ
ФЧУДецЪЕЕФAIЗжВМЪНМЏШКЪЧдѕбљЕФФи,ЧыПДЯТЭМ:
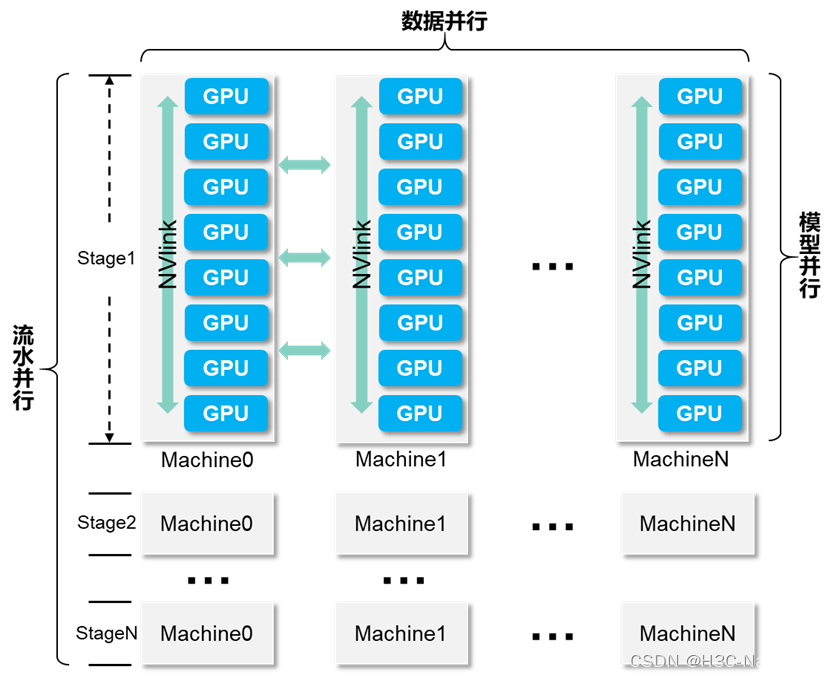
етРяБпЩцМАШ§ИіИХФю:ФЃаЭВЂааЁЂЪ§ОнВЂаавдМАСїЫЎВЂааЁЃИљОнЫуЗЈЕФДѓаЁ,ПЩвдбЁдёадЕУВЩгУЦфжавЛжжЛђСНжжВЂааЗНЪН,ЕЋЪЧЁАДѓФЃаЭЁБбЕСЗЭљЭљЖМЛсгІгУЕНШ§жжВЂааЗНЪНЁЃЮвУЧЛсНЋетИіAIМЏШКЛЎЗжЮЊШєИЩStage,УПИіStageЖдгІвЛИіТпМЩЯЕФBatch,УПИіStageгЩШєИЩЬЈGPUНкЕузщГЩЁЃ
Ъ§ОнВЂаа:ЯрЭЌЕФФЃаЭЗжВМдкЭЌвЛИіStageЕФВЛЭЌGPUНкЕуЩЯ,дкВЛЭЌЕФНкЕуЩЯЪЙгУВЛЭЌЕФЪ§ОнНјаабЕСЗЁЃФЃаЭВЂаа:дкФГGPUНкЕуНЋФЃаЭЧаЗжЕНВЛЭЌЕФGPUПЈЩЯ,МѕЩйЕЅПЈВЮЪ§СПЁЃСїЫЎВЂаа:ЛљгкФЃаЭВЂаа,вЛИіbatchНсЪјЧАПЊЪМЯТвЛИіbatch,вдГфЗжРћгУМЦЫузЪдД,МѕЩйЪБМфПеЯЖЁЃ
Ъ§ОнЭЈаХ
дквЛИіGPUНкЕуФкВП,ВЛЭЌGPUПЈЩЯЕФеХСПЧаЦЌашвЊЛузм,етВПЗжЪ§ОнЭЈаХвРППNvlinkНјаа;дквЛИіStageМЏШКжа,ВЛЭЌGPUНкЕужЎМфЕФФЃаЭВЮЪ§ашвЊЭЌВН,етВПЗжЪ§ОнЭЈаХашвЊвРППЭтВПЭјТч;ВЛЭЌStageжЎМфашвЊНјааForward passКЭBackward passЕФЬнЖШДЋЕн,вВашвЊвРППЭтВПЭјТчЁЃНгЯТРДЮвУЧвРДЮНщЩмвЛЯТВЛЭЌНзЖЮЕФЪ§ОнЭЈаХЧщПіЁЃ
1. GPUНкЕуФкВПЭЈаХ
GPUНкЕуФкВПЕФЭЈаХЗжЮЊСНжжЧщПі,вЛжжЪЧGPUПЈжЎМфЕФЭЈаХ,етВПЗжЪ§ОнЭЈаХЕБЧАжївЊЪЧЭЈЙ§NVlinkЪЕЯжЁЃ

ЩЯЭМеЙЪОЕФЪЧHGX A100 8-GPU ЕФGPU Baseboard,8ПщA100 GPUЭЈЙ§NVlinkЪЕЯжИпЫйЛЅЭЈЁЃ
GPUНкЕуФкВПЭЈаХСэЭтвЛжжЧщПіЪЧGPUгыCPUЁЂФкДцЁЂгВХЬЁЂЭјПЈжЎМфЕФЭЈаХ,ДЫЪБОЭашвЊЖдећИіGPUНкЕуМмЙЙНјааЖрЗНЮЌЖШЕФПМТЧКЭЩшМЦЁЃЮвУЧвдH3C R5500 G5ЮЊР§НјааНщЩм:

H3C UniServer R5500 G5ЪЧH3CЭЦГіЕФЛљгкHGX A100 8-GPUФЃПщЭъШЋзджїбаЗЂЕФ6UЁЂ2ТЗGPUЗўЮёЦї,ИУЗўЮёЦїЪЪгУгкащФтЛЏЁЂИпадФмМЦЫу(HPC)ЁЂФкДцМЦЫуЁЂЪ§ОнПтЁЂЩюЖШбЇЯАКЭГЌДѓЙцИёВЂаабЕСЗЕШМЦЫуУмМЏаЭГЁОА,ОпгаМЦЫуадФмИпЁЂЙІКФЕЭЁЂРЉеЙадЧПКЭПЩППадИпЕШЬиЕу,взгкЙмРэКЭВПЪ№,ПЩТњзуИпадФмГЌДѓЙцФЃВЂаабЕСЗгІгУЁЃ
ЮвУЧвЛЦ№ПДвЛЯТИУGPUЗўЮёЦїЕФЭиЦЫЩшМЦ:
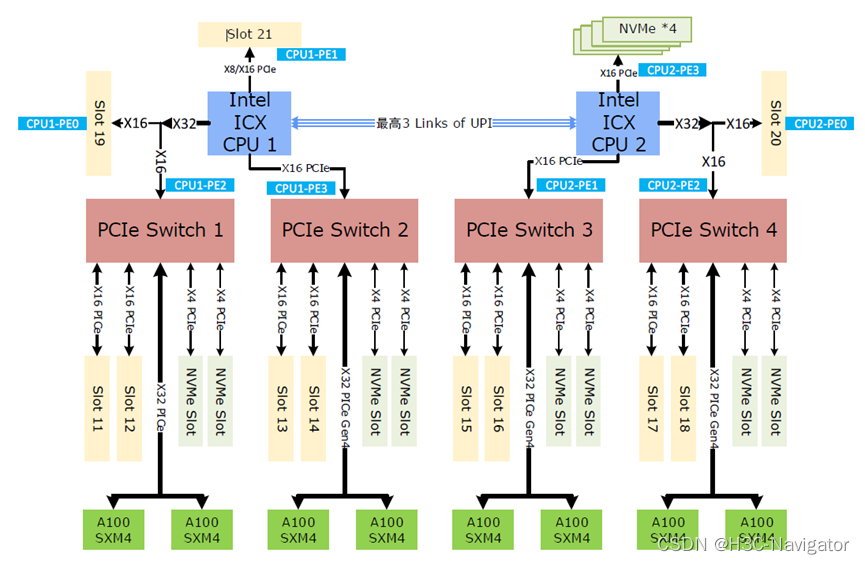
ЗўЮёЦїНкЕужаФкЧЖЖрзщPCIe Switch,ПЩвдЪЕЯжGPUПЈгыЦфЫћзщМўЕФИпЫйЛЅСЊ:гыSlot 11-18ЕФЭјПЈЛЅСЊЁЂгыNVMe SlotЕФгВХЬЕФИпЫйЛЅСЊ,GPUПЈФмЙЛПьЫйЗУЮЪЕНЗХжУдкNVMeгВХЬжаЕФBatchаХЯЂЁЃШчДЫвЛЬзМмЙЙЩшМЦ,ЪЕЯжСЫGPUНкЕуФкИїзщМўЕФИпЫйЛЅСЊ,вВе§вђШчДЫ,ИУВњЦЗдкЛЅСЊЭјжїСїAIГЁОАжаЕФЫуСІБэЯжМЋЮЊгХау:
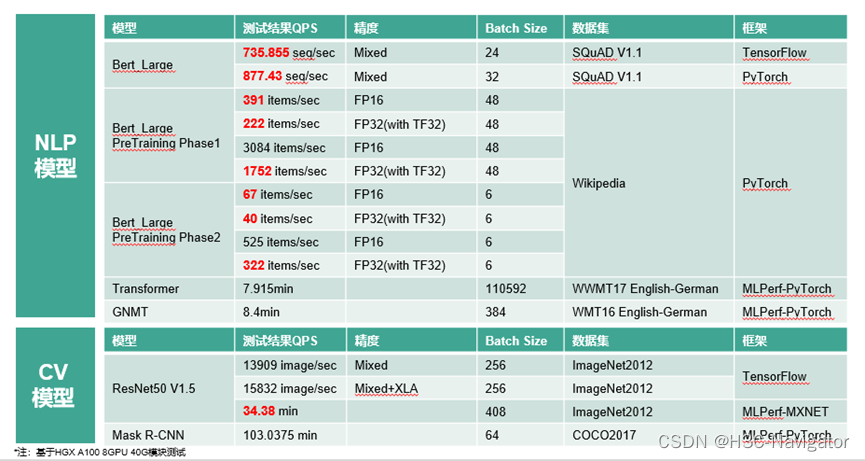
H3CПЩвдЮЊЛЅСЊЭјЙЋЫОЬсЙЉЖрбљЛЏЁЂЖЈжЦЛЏЕФAIНтОіЗНАИ:

2. GPUНкЕуЭтВПЭЈаХ
ЩЯБпЮвУЧЬИЕНЕФAIЗжВМЪНВПЪ№МЏШКРя,Ъ§ОнВЂаавдМАСїЫЎВЂааЖМашвЊВЛЭЌGPUНкЕужЎМфЪ§ОнЕФИпЫйЛЅЗУЁЃЪ§ОнВЂаажївЊНтОіЕФЪЧЬнЖШЛузмЕФЮЪЬт,СїЫЎВЂаадђНтОіЕФЪЧЬнЖШДЋВЅЕФЮЪЬтЁЃ
ЬнЖШЛузмБШНЯКУРэНт,дкStageФкВПЪЧВЩгУВЛЭЌЕФЪ§ОнЖдЭЌвЛИіФЃаЭЗжЖЮНјаабЕСЗ,бЕСЗЭъГЩКѓИУStageЪфГіЕФЪЧЫљгаGPUНкЕуЛузмЕФВЮЪ§аХЯЂЁЃ
ЫЕЕНЬнЖШДЋВЅ,ОЭБиаывЊЫЕвЛЯТФЃаЭбЕСЗжаГЃгУЕФЗДЯђДЋВЅ:
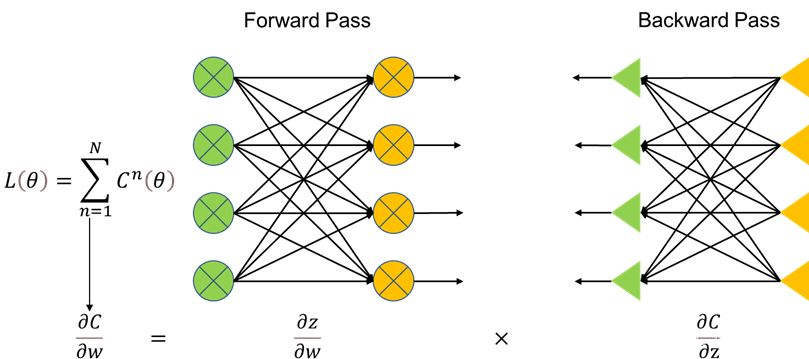
ШчЭМЫљЪО,дкФЃаЭбЕСЗжаЮвУЧЛсЪзЯШЖЈвхLossКЏЪ§,ІШдђЪЧЫљгаВЮЪ§ЕФКЯМЏ,вђДЫФЃаЭЕФбЕСЗОЭЯрЕБгкЮвУЧевЕНвЛИіІШМЏ,ПЩвдШУLossКЏЪ§жЕзюаЁЁЃЮвУЧНЋФЃаЭЧаЗжШєИЩИіC,вђДЫевЕНЫљгаCЕФзюаЁжЕЧѓКЭБуЪЧLЕФзюаЁжЕЁЃЧѓзюаЁжЕЕФЙ§ГЬвВПЩвдПДГЩЮЂЗжМЦЫуЕФЙ§ГЬ:вдІШжаЕФwВЮЪ§ЮЊР§,?C/?wБуЪЧЮЂЗжМЦЫу,ЮвУЧНЋ?C/?wВ№ЗжГЩ?z/?w*?z/?w,ДЫЪБ?z/?wОЭЪЧвЛИіе§ЯђЬнЖШЕФЙ§ГЬ,Жј?z/?wдђЪЧвЛИіЗДЯђЬнЖШЕФЙ§ГЬЁЃжЎЫљвдетбљзі,ЪЧвђЮЊе§ГЃМЦЫуСїГЬашвЊАбЖрВуЩёОЭјТчМЦЫуЭъГЩКѓВХФмНјаавЛДЮе§ЯђЧѓЕМ,етбљЛсМЋДѓНЕЕЭаЇТЪ,ЖјЗДЯђЬнЖШЕФгІгУ,ЛсЪЙЕУЮвУЧЧѓНтLossКЏЪ§БфЕУИќЮЊИпаЇЁЃ
вдЩЯОЭЪЧЗДЯђЬнЖШЕФвЛИіМђНщ,ЮвУЧПЩвдПДЕН,ећИіЙ§ГЬжаЭЌВуЩёОЭјТчЛђепВЛЭЌВуЩёОЭјТчжЎМфвЛжБЖМдкНјааЪ§ОнДЋЪфЛђепВЮЪ§ДЋЪф,етаЉЪ§ОнЭЈаХДѓВПЗжЖМЪЧПчМЦЫуНкЕуНјааЕФЁЃвђДЫ,ЮЊСЫБЃеЯФЃаЭбЕСЗаЇТЪ,ашвЊИјAIМЏШКЙЙНЈвЛИіЕЭбгЪБЕФИпадФмЭјТчЁЃдквдЬЋЭјСьгђ,етИіИпадФмЭјТчОЭЪЧRoCEЭјТч,гЩгкЦЊЗљдвђ,ОЭВЛдкетеЙПЊRoCEЕФНщЩмСЫЁЃ
НсКЯдкЭјТчСьгђЕФЬНЫї,ЮвУЧЩшМЦСЫвЛЬзжЧЫужааФЮоЫ№ЭјТчећЬхЭиЦЫ:
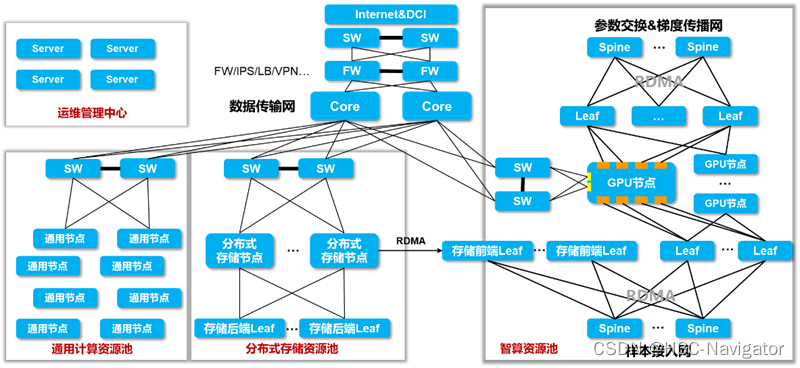
ИУМмЙЙећЬхПЩЗжЮЊвдЯТМИИіЧјгђ:жЧЫузЪдДГиЁЂЗжВМЪНДцДЂзЪдДГиЁЂЭЈгУМЦЫузЪдДГиЁЂЪ§ОнДЋЪфЭјвдМАдЫЮЌЙмРэжааФЁЃЦфжажЧЫузЪдДГигжЗжЮЊВЮЪ§НЛЛЛ&ЬнЖШДЋВЅЭјЁЂбљБОНгШыЭј,етСНВПЗжЖМашвЊЪЙФмRoCE,ДђдьЕЭбгЪБЮоЖЊАќИпадФмЭјТч,ДгЖјБЃеЯAIМЏШКЕФИпаЇТЪЁЃ
дкЛЅСЊЭјаавЕжа,ДѓЙцФЃЁЂИпЭЬЭТЪЧжїСї,вђДЫдкжЧЫузЪдДГиЕФЭјТчЩшМЦжа,ЛЅСЊЭјгаЦфЖРЕНЕФЩшМЦ:
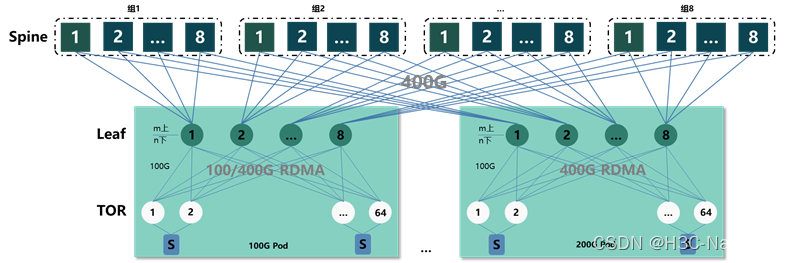
ећЬхзщЭјЗжЮЊSpine/Leaf/TORШ§Ву:дк100G Podжа,SpineВЩгУS9825-64DЩшБИ,TORВЩгУS9820-8C/S9820-8M/S9855-48CD8DЩшБИ,LeafВЩгУS9825-64D/S9820-8C/S9820-8MЩшБИ;дк200G Podжа,SpineКЭLeafВЩгУS9825-64DЩшБИ,TORВЩгУS9820-8C/S9820-8M/S9855-24B8DЩшБИ,S9820ПюаЭВЩгУ400GвЛЗжЖўЕФаЮЪНЁЃ
гыДЫЭЌЪБ,ВПЪ№вЛИіRoCEЭјТчвВОјЗЧвзЪТ,ашвЊНсКЯВЛЭЌЕФвЕЮёСїЬиеїСщЛюЕїећBufferЫЎЯп,ЗёдђФбвдДяЕНзюМбаЇЙћ,ЮЊДЫH3CЭЦГіСЫSeerFabricжЧФмЮоЫ№НтОіЗНАИ,Г§СЫНтОіЛљБОЕФRoCEздЖЏЛЏЁЂRoCEПЩЪгЁЂRoCEЗжЮівдМАRoCEЕїгХЮЪЬт,ЛЙЬсЙЉAI ECNжЧФмЕїгХФЃПщ:
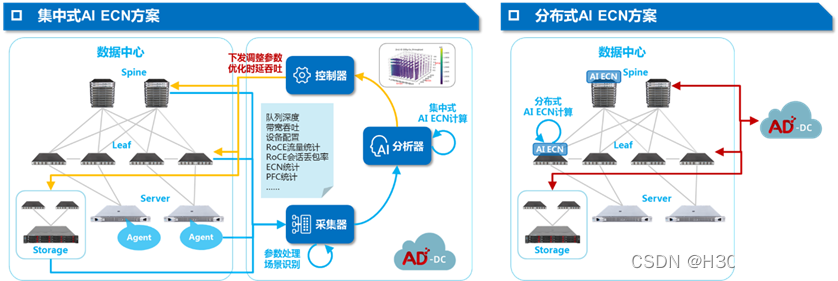
ЭЈЙ§SeerFabricПЩвдНЕЕЭВПЪ№RoCEЭјТчЕФУХМї,ЬсИпВПЪ№аЇТЪ,ХфКЯH3CЗсИЛЖрбљЕФ400G/200G/100GЭјТчВњЦЗ,ПЩвдзюДѓЕФЪЭЗХЭјТчЕФЧБСІ,ЬсИпAIМЏШКЕФдЫаааЇТЪЁЃ
3. AIПђМм
ЧАБпЮвУЧСФЭъСЫећИіAIМЏШКЕФДѓжТМмЙЙ,ШЛЖјвЊжЊЕР,ГфЗжЕїЖЏШчДЫХгДѓЙцФЃЕФAIМЏШКОјЗЧвзЪТЁЃећИіЯЕЭГЕФИпаЇдЫааШчЙћЖМашвЊЮвУЧздМКШЅПМТЧ,етЛсеМгУПЊЗЂШЫдБЬЋЖрОЋСІ,ШчЭЌдЦМЦЫуЪБДњГіЯжOpenStackЁЂШнЦїЪБДњГіЯжkubernetesвЛбљ,AIЪБДњвВгЕгаЫќзЈЪєЕФВйзїЯЕЭГ:AIПђМмЁЃ
AIПђМмЪЧ AIЫуЗЈФЃаЭЩшМЦЁЂбЕСЗКЭбщжЄЕФвЛЬзБъзМНгПкЁЂЬиадПтКЭЙЄОпАќ,МЏГЩСЫЫуЗЈЕФЗтзАЁЂЪ§ОнЕФЕїгУвдМАМЦЫузЪдДЕФЪЙгУ,ЭЌЪБУцЯђПЊЗЂепЬсЙЉСЫПЊЗЂНчУцКЭИпаЇЕФжДааЦНЬЈ,ЪЧЯжНзЖЮAIЫуЗЈПЊЗЂЕФБиБИЙЄОпЁЃаХЭЈдКИјГіСЫвЛИіБъзМЕФAIПђМмгІИУОпБИЕФФмСІ:
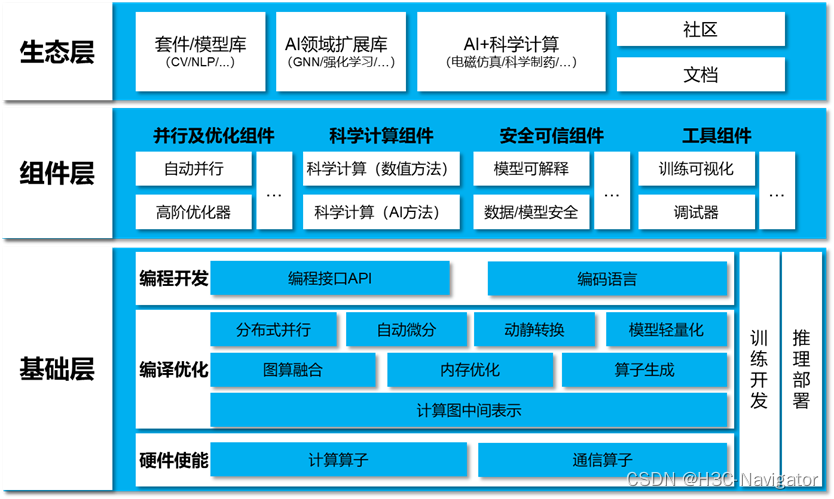
вЕФкБШНЯжЊУћЕФAIПђМмгаTensorFlowКЭPyTorch,ВњвЕНчЧуЯђгкTensorFlow,бЇЪѕНчдђЧуЯђгкPyTorchЁЃетСНИіПђМмВЂЗЧЭъУРЕФ,вЕНчЮЊСЫВЙГфФГаЉСьгђЕФШБЯнЛЙдкВЛЖЯЭЦГіИїжжИїбљЕФAIПђМм,ЮвУЧЦкД§зюжеФмЙЛгаетбљвЛИіAIПђМмПЩвдвЛЭГНКў,ПЩвдНЋИїжжФмСІГЁОАЖММЏКЯдкФкЁЃетВПЗжЕФжЊЪЖДѓМвИааЫШЄвВПЩвдздМКШЅЬНЫї,ФмЙЛИќШнвзШУЮвУЧРэНтAIЕФдЫааЙ§ГЬЁЃ
еЙЭћ
ШЫЙЄжЧФмЗЂеЙжСНё,ЫфШЛдкЫуЗЈЁЂЫуСІЁЂЪ§ОнетШ§ДѓТэГЕЗНУцЕФЗЂеЙЧїЪЦУЭНј,ШЛЖјAIеце§вЊИГФмВњвЕЁЂИГФмЩчЛсЛЙгааэЖрТЗвЊзпЁЃБШШчдкЙЄГЬВуУц:ашвЊПМТЧИїЦѓвЕПђМмЕФЪЪгУадЁЂашвЊПМТЧШЋЩњУќжмЦкЕФЮЌЛЄЁЂашвЊПМТЧAIЕФздЖЏЛЏдЫЮЌЁЃдйБШШчдкАВШЋВуУц:ашвЊПМТЧAIСьгђЕФПЩаХМЦЫуЁЂашвЊПМТЧАВШЋгыадФмЕФЦНКтЁ