ЦзОлРрКЭAPОлРрЪЧЛљгкЭМЕФСНжжОлРр,дкетРяЮвНщЩмAPОлРрЁЃ
Affinity Propagation Clustering(МђГЦAPЫуЗЈ)ЪЧ2007ЬсГіЕФ,ЕБЪБЗЂБэдкScienceЩЯЁЖsingle-exemplar-basedЁЗЁЃЬиБ№ЪЪКЯИпЮЌЁЂЖрРрЪ§ОнПьЫйОлРр,ЯрБШДЋЭГЕФОлРрЫуЗЈ,ИУЫуЗЈЫуЪЧБШНЯаТЕФ,ДгОлРрадФмКЭаЇТЪЗНУцЖМгаДѓЗљЖШЕФЬсЩ§ЁЃ
Affinity PropagationПЩвдЗвыЮЊЙиСЊДЋВЅ,ЫќЪЧвЛжжЛљгкЪ§ОнЕужЎМфЁАЯћЯЂДЋЕнЁБИХФюЕФОлРрММЪѕ,ЫљвдЮвУЧГЦЦфЮЊЛљгкЭМЕФОлРрЗНЗЈЁЃ
ИУЫуЗЈЭЈЙ§дкЪ§ОнЕужЎМфЗЂЫЭЯћЯЂжБЕНЪеСВРДДДНЈДиЁЃЫќвдЪ§ОнЕужЎМфЕФЯрЫЦадзїЮЊЪфШы,ВЂИљОнвЛЖЈЕФБъзМШЗЖЈЗЖР§ЁЃдкЪ§ОнЕужЎМфНЛЛЛЯћЯЂ,жБЕНЛёЕУвЛзщИпжЪСПЕФЗЖР§ЁЃгыk-meansЛђk-medoidsЕШОлРрЫуЗЈВЛЭЌ,ДЋВЅдкдЫааЫуЗЈжЎЧАВЛашвЊШЗЖЈЛђЙРМЦДиЕФЪ§СПЁЃ
ЙЋЪНЯъНт
ЮвУЧЪЙгУЯТУцЕФЪ§ОнМЏ,РДНщЩмЫуЗЈЕФЙЄзїдРэЁЃ
ЯрЫЦОиеѓ
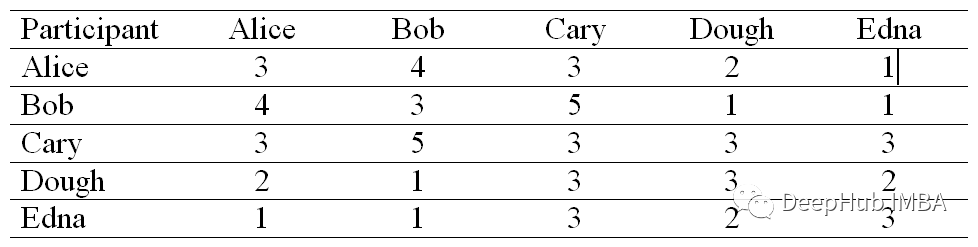
ЯрЫЦЖШОиеѓжаЕФУПвЛИіЕЅдЊИёЖМЪЧЭЈЙ§ЖдВЮгыепжЎМфЕФВюжЕЦНЗНКЭЧѓИКРДМЦЫуЕФЁЃ
БШШч Alice КЭ Bob ЕФЯрЫЦЖШ,ВюЕФЦНЗНКЭЮЊ (3ЈC4)2 + (4ЈC3)2 + (3ЈC5)2 + (2ЈC1)2 + (1ЈC 1)2 = 7ЁЃвђДЫ,Alice КЭ Bob ЕФЯрЫЦЖШжЕЮЊ -(7)ЁЃ

ШчЙћЮЊЖдНЧЯпбЁдёНЯаЁЕФжЕ,дђИУЫуЗЈНЋЮЇШЦЩйСПМЏШКЪеСВ,ЗДжЎврШЛЁЃвђДЫЮвУЧгУ -22 ЬюГфЯрЫЦОиеѓЕФЖдНЧдЊЫи,етЪЧЮвУЧЯрЫЦОиеѓжаЕФзюаЁжЕЁЃ

Юќв§ЖШ(Responsibility)Оиеѓ
ЮвУЧНЋЪзЯШЙЙдьвЛИіЫљгадЊЫиЖМЩшЮЊ0ЕФПЩгУадОиеѓЁЃШЛКѓ,ЮвУЧНЋЪЙгУвдЯТЙЋЪНМЦЫуЮќв§ЖШОиеѓжаЕФУПИіЕЅдЊИё:

етРяiжИЕФЪЧаа,kжИЕФЪЧЯрЙиОиеѓЕФСаЁЃ
Р§Шч,Bob(Са)ЖдAlice(аа)ЕФЮќв§ЖШЪЧ-1,етЪЧЭЈЙ§ДгBobКЭAliceЕФЯрЫЦЖШ(-7)жаМѕШЅAliceЫљдкааЕФзюДѓЯрЫЦЖШ(BobКЭAliceЕФЯрЫЦЖШ(-6)Г§Эт)РДМЦЫуЕФЁЃ

дкМЦЫуСЫЦфЫћВЮгыепЖдЕФЮќв§ЖШжЎКѓ,ЮвУЧЕУЕНСЫЯТУцЕФОиеѓЁЃ
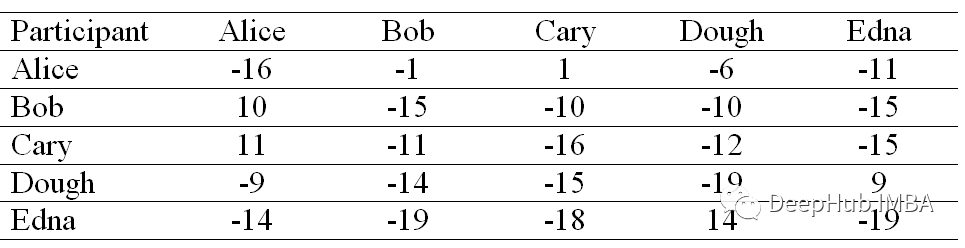
Юќв§ЖШЪЧгУРДУшЪіЕуkЪЪКЯзїЮЊЪ§ОнЕуiЕФОлРржааФЕФГЬЖШЁЃ
ЙщЪєЖШ(Availability)Оиеѓ
ЮЊСЫЙЙдьвЛИіЙщЪєЖШОиеѓ,НЋЪЙгУЖдНЧКЭЗЧЖдНЧдЊЫиЕФСНИіЕЅЖРЕФЗНГЬНјааМЦЫу,ВЂНЋЫќУЧгІгУЕНЮвУЧЕФЮќв§ЖШОиеѓжаЁЃ
ЖдНЧЯпдЊЫиНЋЪЙгУЯТУцЕФЙЋЪНЁЃ
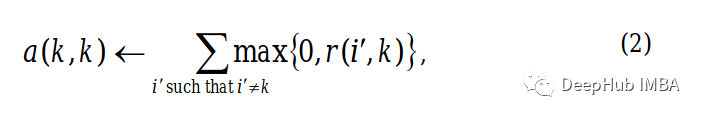
етРя i жИЕФЪЧЙиСЊОиеѓЕФааКЭ k СаЁЃ
ИУЕШЪНИцЫпЮвУЧбиСаМЦЫуЫљгаДѓгк 0 ЕФжЕЕФзмКЭ,ЕЋжЕЕШгкЫљЬжТлСаЕФааГ§ЭтЁЃР§Шч,Alice ЕФЖдНЧЯпЩЯдЊЫижЕНЋЪЧ Alice СаЕФе§жЕжЎКЭ,ЕЋВЛАќРЈ Alice СаЕФжЕ,ЕШгк 21(10 + 11 + 0 + 0)ЁЃ

аоИФКѓ,ЮвУЧЕФЙщЪєЖШОиеѓНЋШчЯТЫљЪО:

ЯждкЖдгкЗЧЖдНЧдЊЫи,ЪЙгУвдЯТЕШЪНИќаТЫќУЧЕФжЕЁЃ

ЭЈЙ§вЛИіР§згРДРэНтЩЯУцЕФЕШЪНЁЃМйЩшЮвУЧашвЊевЕН Bob(Са)Жд Alice(аа)ЕФЙщЪєЖШ,ФЧУДЫќНЋЪЧ Bob ЕФздЮвЙщЪє(дкЖдНЧЯпЩЯ)КЭ Bob СаЕФЪЃгрЛ§МЋЮќв§ЖШЕФзмКЭ,ВЛАќРЈ Bob ЕФAliceаа(-15 + 0 + 0 + 0 = -15)ЁЃ
дкМЦЫуЦфгрВПЗжКѓ,ЕУЕНвдЯТЙщЪєЖШОиеѓЁЃ

ЙщЪєЖШПЩвдРэНтЮЊгУРДУшЪіЕуiбЁдёЕуkзїЮЊЦфОлРржааФЕФЪЪКЯГЬЖШЁЃ
зМОн(Criterion)Оиеѓ
зМОнОиеѓжаЕФУПИіЕЅдЊИёжЛЪЧИУЮЛжУЕФЮќв§ЖШОиеѓКЭЙщЪєЖШОиеѓЯрМгЕФКЭЁЃ


УПаажаОпгазюИпзМОнжЕЕФСаБЛжИЖЈЮЊбљБОЁЃЙВЯэЭЌвЛИіЪЕР§ЕФаадкЭЌвЛИіДижаЁЃдкЮвУЧЕФЪОР§жаЁЃAliceЁЂBobЁЂCary ЁЂDoug КЭ Edna ЖМЪєгкЭЌвЛИіМЏШКЁЃ
ШчЙћЧщПіЪЧетбљ:

ФЧУДAliceЁЂBob КЭ Cary ЙЙГЩвЛИіДи,Жј Doug КЭ Edna ЙЙГЩЕкЖўИіДиЁЃ
CriterionБЛЮвЗвыГЩзМОнвВОЭЪЧЫЕУїетИіОиеѓЪЧЮвУЧОлРрЫуЗЈХаЖЯЕФБъзМКЭвРОнЁЃ
ДњТыЪОР§
дкsklearnжавбОАќКЌСЫИУЫуЗЈ,ЫљвдЮвУЧПЩвдФУРДжБНгЪЙгУ:
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation
Дг Sklearn ЩњГЩОлРрЪ§Он
X, clusters = make_blobs(n_samples=1000, centers=5, cluster_std=0.8, random_state=0)
plt.scatter(X[:,0], X[:,1], alpha=0.7, edgecolors='b')
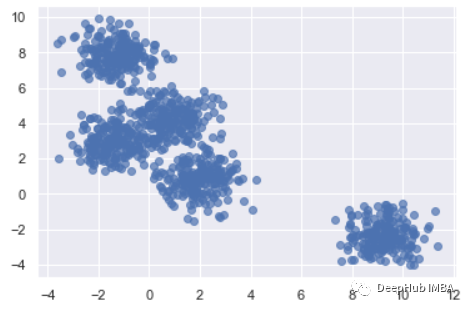
ГѕЪМЛЏКЭФтКЯФЃаЭЁЃ
af = AffinityPropagation(preference=-50)
clustering = af.fit(X)
APОлРргІгУжаашвЊЪжЖЏжИЖЈPreferenceКЭDamping factor,ЫфШЛВЛашвЊЯдЪНжИЖЈДиЕФЪ§СП,ЕЋЪЧетСНИіВЮЪ§ЦфЪЕЪЧдгаЕФОлРрЁАЪ§СПЁБПижЦЕФБфЬх:
Preference:Ъ§ОнЕуiЕФВЮПМЖШГЦЮЊp(i)Лђs(i,i),ЪЧжИЕуiзїЮЊОлРржааФЕФВЮПМЖШ,ОлРрЕФЪ§СПЪмЕНВЮПМЖШpЕФгАЯь,ШчЙћШЯЮЊУПИіЪ§ОнЕуЖМгаПЩФмзїЮЊОлРржааФ,ФЧУДpОЭгІШЁЯрЭЌЕФжЕЁЃШчЙћШЁЪфШыЕФЯрЫЦЖШЕФОљжЕзїЮЊpЕФжЕ,ЕУЕНОлРрЪ§СПЪЧжаЕШЕФЁЃШчЙћШЁзюаЁжЕ,ЕУЕНРрЪ§НЯЩйЕФОлРрЁЃ
Damping factor(зшФсЯЕЪ§):жївЊЪЧЦ№ЪеСВзїгУЕФЁЃ
ЛцжЦОлРрНсЙћЕФЪ§ОнЕу
plt.scatter(X[:,0], X[:,1], c=clustering.labels_, cmap=ЁЎrainbowЁЏ, alpha=0.7, edgecolors=ЁЎbЁЏ)

змНс
Affinity Propagation ЪЧвЛжжЮоМрЖНЛњЦїбЇЯАММЪѕ,ЬиБ№ЪЪгУгкЮвУЧВЛжЊЕРзюМбМЏШКЪ§СПЕФЧщПіЁЃВЂЧвИУЫуЗЈИДдгЖШНЯИп,ЫљвддЫааЪБМфЯрЖдБШK-MeansГЄКмЖр,етЛсЪЙЕУгШЦфдкКЃСПЪ§ОнЯТдЫааЪБКФЗбЕФЪБМфКмЖрЁЃ
https://avoid.overfit.cn/post/70c0efd697ef43a6a43fea8938afff60
зїеп:Sarthak Kedia