本文使用transformer集成时间上下文信息
通过更新输入的动态模板(文中设置200帧),获得时间上下文信息,再利用transformer进行处理
transformer 本身对空间上下文具有更好的建模能力
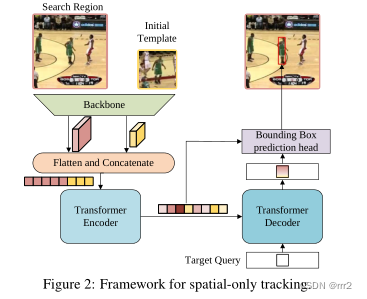
新架构包含三个关键组件:编码器、解码器和预测头。
编码器接受初始目标对象、当前图像和动态更新模板的输入。输入是由一个搜索区域和两个模板组成的三元组。它们来自主干的特征首先被展平并连接,然后发送到编码器。
编码器中的自注意力模块通过其特征依赖性学习输入之间的关系。由于模板图像在整个视频序列中更新,编码器可以捕获目标的空间和时间信息。
解码器学习查询嵌入来预测目标对象的空间位置。
基于角点的预测头用于估计当前帧中目标对象的边界框。同时,学习分数头来控制动态模板图像的更新。
背景
离线Siamese 跟踪器属于纯空间跟踪器,它们将目标跟踪视为初始模板和当前搜索区域之间的模板匹配。
无梯度方法[54,57]利用额外的网络来更新Siamese跟踪器的模板[2,61]。另一个代表性工作LTMU[8]学习元更新程序来预测当前状态是否足够可靠,以便用于长期跟踪中的更新。这些方法虽然有效,但会造成空间和时间的分离(未说明为什么分离,分离带来什么后果)。相反,我们的方法将空间和时间信息作为一个整体进行集成,同时使用transformer进行学习。
STARK-S结构
backbone
搜索区域x(3320320) , 初始化模板z (3128128) 经过resnet(s=16)得到特征fx(
2562020) fz(25688)

送到编码器之前,拼接展平,(256*(400+64))

编码器
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
N=6个encoder layer (多头自注意力和FFN)
并计算了sin位置嵌入,用法:
解码器
只在解码器中输入一个查询来预测目标对象的一个边界框。即只输出一组预测候选框值。
此外,由于只有一个预测,我们删除了DETR中用于预测关联的匈牙利算法[24]。与编码器类似,解码器堆叠M个解码器层,每个层由自注意力、编码器-解码器注意力和前馈网络组成。在编码器-解码器注意力模块中,目标查询可以关注模板上的所有位置和搜索区域特征,从而学习用于最终边界盒预测的鲁棒表示。
head
明确地建模了坐标估计中的不确定性,为目标跟踪生成了更准确和更稳健的预测。通过估计盒角点的概率分布来设计一个新的预测头。
我们首先从编码器的输出序列中提取搜索区域特征(400*256),然后计算搜索区域特征和解码器的输出嵌入(256)之间的相似性。
最后reshape得到特征图f 2562020 送入到FCN
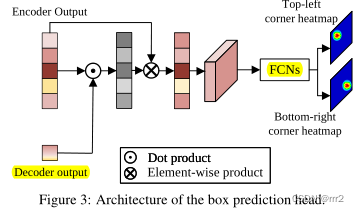
if self.head_type == "CORNER":
# adjust shape
#([1, 400, 256])
enc_opt = memory[-self.feat_len_s:].transpose(0, 1) # encoder output for the search region (B, HW, C)
# .([1, 256, 1])
dec_opt = hs.squeeze(0).transpose(1, 2) # (B, C, N)
# dot product
att = torch.matmul(enc_opt, dec_opt) # (B, HW, N) ([1, 400, 1])
# element-wise mul
opt = (enc_opt.unsqueeze(-1) * att.unsqueeze(-2)).permute((0, 3, 2, 1)).contiguous() # (B, HW, C, N) --> (B, N, C, HW)
bs, Nq, C, HW = opt.size()
opt_feat = opt.view(-1, C, self.feat_sz_s, self.feat_sz_s)
# run the corner head
outputs_coord = box_xyxy_to_cxcywh(self.box_head(opt_feat))
outputs_coord_new = outputs_coord.view(bs, Nq, 4)
out = {'pred_boxes': outputs_coord_new}
return out, outputs_coord_new
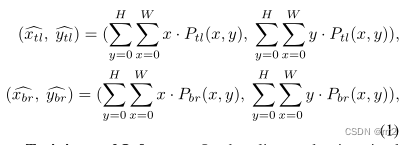
损失函数
不使用分类损失。
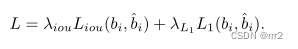
在推理时,固定了第一帧模板的特征,将每一帧获取搜索区域作为输入。
STARK-ST
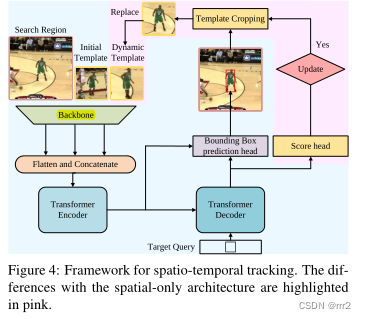
输入增加了 动态模板(3128128)(第一帧的动态模板用什么?)
经过backbone得到动态模板特征(25688)
送到编码器之前,拼接展平,(256*(400+64+64))
分类头
增加分类头,设置阈值,判断是否为目标
训练
区分为主干网络和分类头,分成两个阶段进行训练。
用18和19年的两篇说 分开训练是好的。但是目前有大量论文是将分类和定位联合。
分类损失
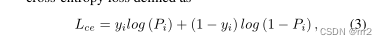
实验
训练设置
训练训练数据包括LaSOT[13]、GOT-10K[18]、COCO2017[30]和TrackingNet[36]
搜索图像和模板的大小分别为320×320像素和128×128像素,分别对应于目标盒面积的52倍和22倍。
STACK-ST的整个训练过程分为两个阶段,分别需要500个阶段进行本地化,50个阶段进行分类。每个epoch 使用6W个训练三元组。损耗权重λL1和λiou分别设置为5和2。AdamW weight decay 10?4.
每个GPU 包含16个三元组,因此每个iteration 的minibatch size =128
主干和其余部分的初始学习率为10?5和10?分别为4。第一阶段400个阶段后,学习率下降了10倍,第二阶段40个阶段后,学习率下降了10倍。
结果和对比
我们在三个短期基准(GOT-10K、TrackingNet和VOT2020)和两个长期基准(LaSOT和VOT2020-LT)测试
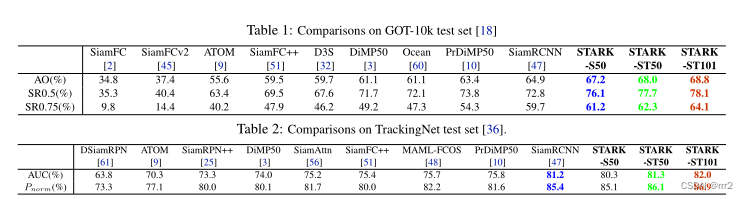
GOT-10K[18]是最近发布的一个大规模和高多样性的用于野外一般目标跟踪的基准测试。它包含了10000多段真实运动物体的视频片段。所有方法使用数据集提供的相同训练和测试数据的协议确保了深度跟踪器的公平比较。训练数据集和测试数据集中的类是零重叠的。上传跟踪结果后,官方网站自动进行分析。所提供的评估指标包括成功图、平均重叠(AO)和成功率(SR)。AO表示所有估计边界框和地面真实框之间的平均重叠。SR0.5表示重叠超过0.5的成功跟踪帧的速率,而SR0.75表示重叠超过0.75的帧。
考虑到Ground Truth框的尺度大小,将Precision 进行归一化,得到Norm. Prec,它的取值在[0, 0.5] 之间。即判断预测框与Ground Truth框中心点的欧氏距离与Ground Truth框斜边的比例。
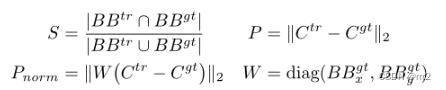
AUC: area under curve 成功率图的曲线下面积
VOT2020
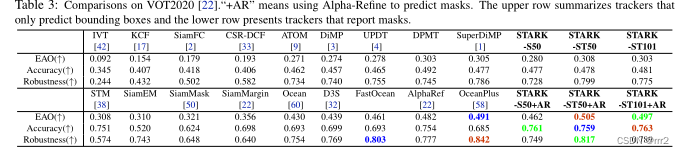
https://blog.csdn.net/Dr_destiny/article/details/80108255
EAO是VOT的对短时跟踪的综合评价指标,它可以反应准确性(A)和鲁棒性(R),但不是由准确性(A)和鲁棒性(R)直接计算得到的。
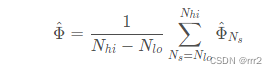
Accuracy用来评价tracker跟踪目标的准确度,数值越大,准确度越高。
Robustness用来评价tracker跟踪目标的稳定性,数值越大,稳定性越差。
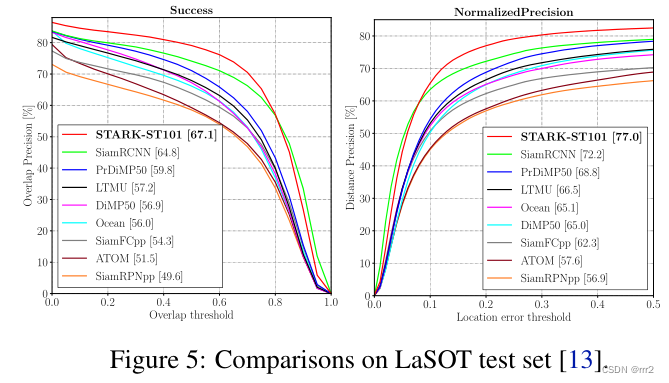
LASOT
LaSOT[13]是一个大规模的长期跟踪基准,在测试集中包含280个视频,平均长度为2448帧
VOT2020-LT
VOT2020-LT由50个长视频组成,其中目标对象经常消失和重新出现。此外,跟踪器需要报告当前目标的置信度分数。在一系列置信阈值下计算精度(Pr)和召回率(Re)。Fscore

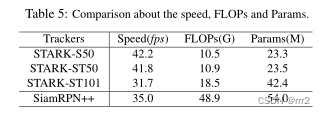
组件对比

分析
当移除分数头时性能降低,这表明时间信息的不当使用可能会损害性能,因此筛选出不可靠的模板非常重要。
Corner更准
encoder 更重要
其他框架对比
共同学习本地化和分类。
如第3.2节所述,本地化被视为首要任务,并在第一阶段进行培训。而分类在第二阶段作为次要任务进行训练。我们还做了一个实验,在一个阶段中共同学习本地化和分类。如选项卡所示。7.该策略导致次优结果,比STARK策略低3.9%。两个潜在的原因是:(1)分数头的优化干扰了盒头的训练,导致盒预测不准确。(2) 这两项任务的训练需要不同的数据。具体来说,本地化任务希望所有搜索区域都包含跟踪目标,以提供强大的监督。相比之下,分类任务期望均衡分布,一半的搜索区域包含目标,而剩下的一半不包含目标。

编码器注意。图6的上半部分显示了来自Cat-20的模板搜索三元组,以及来自最后一个编码器层的注意力地图。可视化注意力是以初始模板的中心像素为查询,以三元组中的所有像素为关键字和值来计算的。可以看出,注意力集中在跟踪的目标上,并已将其与背景大致分离。此外,编码器产生的特征在目标和干扰物之间也具有很强的区分能力。解码器注意。图6的下半部分展示了来自BOWS-13的模板搜索三元组,以及来自最后一个解码器层的注意力映射。可以看出,解码器对模板和搜索区域的注意力是不同的。具体来说,模板上的注意力主要集中在目标的左上角区域,而搜索区域上的注意力往往放在目标的边界上。此外,学习到的注意力对干扰具有鲁棒性。