ЮФеТФПТМ
1. ЩюЖШбЇЯАМђНщ
дкНщЩмЩюЖШбЇЯАжЎЧА,ЮвУЧЯШПДЯТетЗљЭМ:ШЫЙЄжЧФм>ЛњЦїбЇЯА>ЩюЖШбЇЯА

ЩюЖШбЇЯАЪЧЛњЦїбЇЯАЕФвЛИізгМЏ,вВОЭЪЧЫЕЩюЖШбЇЯАЪЧЪЕЯжЛњЦїбЇЯАЕФвЛжжЗНЗЈЁЃгыЛњЦїбЇЯАЫуЗЈЕФжївЊЧјБ№ШчЯТЭМЫљЪО:

ДЋЭГЛњЦїбЇЯАЫуЪѕвРРЕШЫЙЄЩшМЦЬиеї,ВЂНјааЬиеїЬсШЁ,ЖјЩюЖШбЇЯАЗНЗЈВЛашвЊШЫЙЄ,ЖјЪЧвРРЕЫуЗЈздЖЏЬсШЁЬиеї,етвВЪЧЩюЖШбЇЯАБЛПДзіКкКазг,ПЩНтЪЭадВюЕФдвђЁЃ
ЫцзХМЦЫуЛњШэгВМўЕФЗЩЫйЗЂеЙ,ЯжНзЖЮЭЈЙ§гЕгажкЖрВуЪ§ЩёОЭјТч(Neural Network)РДФЃФтШЫФдРДНтЪЭЪ§Он,АќРЈЭМЯё,ЮФБО,вєЦЕЕШФкШнЁЃФПЧАРДПДГЃгУЕФЩёОЭјТчАќРЈ:
- ОэЛ§ЩёОЭјТч(Convolutional Neural Network)
- бЛЗЩёОЭјТч(Recurrent Neural Network)
- ЩњГЩЖдПЙЭјТч(Generative Adversarial Networks)
- ЩюЖШЧПЛЏбЇЯА(Deep Reinforcement Learning)ЕШЁЃ
2. ЪВУДЪЧЩёОЭјТч
ШЫЙЄЩёОЭјТч( Artificial Neural Network, МђаДЮЊANN)вВМђГЦЮЊЩёОЭјТч(NN),ЪЧвЛжжФЃЗТЩњЮяЩёОЭјТчНсЙЙКЭЙІФмЕФ МЦЫуФЃаЭЁЃШЫФдПЩвдПДзіЪЧвЛИіЩњЮяЩёОЭјТч,гЩжкЖрЕФЩёОдЊСЌНгЖјГЩЁЃИїИіЩёОдЊДЋЕнИДдгЕФЕчаХКХ,ЪїЭЛНгЪеЕНЪфШыаХКХ,ШЛКѓЖдаХКХНјааДІРэ,ЭЈЙ§жсЭЛЪфГіаХКХЁЃЯТЭМЪЧЩњЮяЩёОдЊЪОвтЭМ:

ФЧдѕУДЙЙНЈШЫЙЄЩёОЭјТчжаЕФЩёОдЊФи?

ЪмЩњЮяЩёОдЊЕФЦєЗЂ,ШЫЙЄЩёОдЊНгЪеРДздЦфЫћЩёОдЊЛђЭтВПдДЕФЪфШы,УПИіЪфШыЖМгавЛИіЯрЙиЕФШЈжЕ(w),ЫќЪЧИљОнИУЪфШыЖдЕБЧАЩёОдЊЕФживЊадРДШЗЖЈЕФ,ЖдИУЪфШыМгШЈВЂгыЦфЫћЪфШыЧѓКЭКѓ,ОЙ§вЛИіМЄЛюКЏЪ§f,МЦЫуЕУЕНИУЩёОдЊЕФЪфГіЁЃ
ФЧНгЯТРДЮвУЧОЭРћгУЩёОдЊРДЙЙНЈЩёОЭјТч,ЯрСкВужЎМфЕФЩёОдЊЯрЛЅСЌНг,ВЂИјУПвЛИіСЌНгЗжХфвЛИіЧПЖШ,ШчЯТЭМЫљЪО:

ЩёОЭјТчжааХЯЂжЛЯђвЛИіЗНЯђвЦЖЏ,МДДгЪфШыНкЕуЯђЧАвЦЖЏ,ЭЈЙ§вўВиНкЕу,дйЯђЪфГіНкЕувЦЖЏ,ЭјТчжаУЛгабЛЗЛђепЛЗЁЃЦфжаЕФЛљБОЙЙМўЪЧ:
- ЪфШыВу:МДЪфШыxЕФФЧвЛВу
- ЪфГіВу:МДЪфГіyЕФФЧвЛВу
- вўВиВу:ЪфШыВуКЭЪфГіВужЎМфЖМЪЧвўВиВу
ЬиЕуЪЧ:
- ЭЌвЛВуЕФЩёОдЊжЎМфУЛгаСЌНгЁЃ
- ЕкNВуЕФУПИіЩёОдЊКЭЕкN-1ВуЕФЫљгаЩёОдЊЯрСЌ(етОЭЪЧfull connectedЕФКЌвх),ЕкN-1ВуЩёОдЊЕФЪфГіОЭЪЧЕкNВуЩёОдЊЕФЪфШыЁЃ
- УПИіСЌНгЖМгавЛИіШЈжЕЁЃ
3. ЩёОдЊЪЧШчКЮЙЄзїЕФ?
ШЫЙЄЩёОдЊНгЪеЕНвЛИіЛђЖрИіЪфШы,ЖдЫћУЧНјааМгШЈВЂЯрМг,змКЭЭЈЙ§вЛИіЗЧЯпадКЏЪ§ВњЩњЪфГіЁЃ

-
ЫљгаЕФЪфШыxi,гыЯргІЕФШЈжиwiЯрГЫВЂЧѓКЭ:
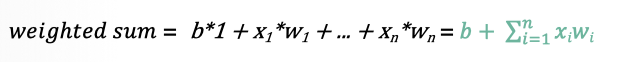
-
НЋЧѓКЭНсЙћЫЭШыЕНМЄЛюКЏЪ§жа,ЕУЕНзюжеЕФЪфГіНсЙћ:
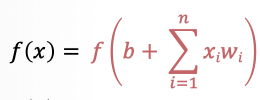
3.1 МЄЛюКЏЪ§
дкЩёОдЊжав§ШыСЫМЄЛюКЏЪ§,ЫќЕФБОжЪЪЧЯђЩёОЭјТчжав§ШыЗЧЯпадвђЫиЕФ,ЭЈЙ§МЄЛюКЏЪ§,ЩёОЭјТчОЭПЩвдФтКЯИїжжЧњЯпЁЃШчЙћВЛгУМЄЛюКЏЪ§,УПвЛВуЪфГіЖМЪЧЩЯВуЪфШыЕФЯпадКЏЪ§,ЮоТлЩёОЭјТчгаЖрЩйВу,ЪфГіЖМЪЧЪфШыЕФЯпадзщКЯ,в§ШыЗЧЯпадКЏЪ§зїЮЊМЄЛюКЏЪ§,ФЧЪфГіВЛдйЪЧЪфШыЕФЯпадзщКЯ,ПЩвдБЦНќШЮвтКЏЪ§ЁЃГЃгУЕФМЄЛюКЏЪ§га:
3.1.1 Sigmoid/logisticsКЏЪ§
Ъ§бЇБэДяЪНЮЊ:
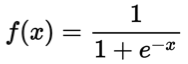
ЧњЯпШчЯТЭМЫљЪО:

sigmoid дкЖЈвхгђФкДІДІПЩЕМ,ЧвСНВрЕМЪ§ж№НЅЧїНќгк0ЁЃШчЙћXЕФжЕКмДѓЛђепКмаЁЕФЪБКђ,ФЧУДКЏЪ§ЕФЬнЖШ(КЏЪ§ЕФаБТЪ)ЛсЗЧГЃаЁ,дкЗДЯђДЋВЅЕФЙ§ГЬжа,ЕМжТСЫЯђЕЭВуДЋЕнЕФЬнЖШвВБфЕУЗЧГЃаЁЁЃДЫЪБ,ЭјТчВЮЪ§КмФбЕУЕНгааЇбЕСЗЁЃетжжЯжЯѓБЛГЦЮЊЬнЖШЯћЪЇЁЃвЛАуРДЫЕ, sigmoid ЭјТчдк 5 ВужЎФкОЭЛсВњЩњЬнЖШЯћЪЇЯжЯѓЁЃЖјЧв,ИУМЄЛюКЏЪ§ВЂВЛЪЧвд0ЮЊжааФЕФ,ЫљвддкЪЕМљжаетжжМЄЛюКЏЪ§ЪЙгУЕФКмЩйЁЃsigmoidКЏЪ§вЛАужЛгУгкЖўЗжРрЕФЪфГіВуЁЃ
ЪЕЯжЗНЗЈ:
# ЕМШыЯргІЕФЙЄОпАќ
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# ЖЈвхxЕФШЁжЕЗЖЮЇ
x = np.linspace(-10, 10, 100)
# жБНгЪЙгУtensorflowЪЕЯж
y = tf.nn.sigmoid(x)
# ЛцЭМ
plt.plot(x,y)
plt.grid()
ЪфГіНсЙћЮЊ:

3.1.2 tanh(ЫЋЧње§ЧаЧњЯп)
Ъ§бЇБэДяЪНШчЯТ:
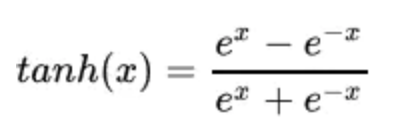
ЧњЯпШчЯТЭМЫљЪО:

tanhвВЪЧвЛжжЗЧГЃГЃМћЕФМЄЛюКЏЪ§ЁЃгыsigmoidЯрБШ,ЫќЪЧвд0ЮЊжааФЕФ,ЪЙЕУЦфЪеСВЫйЖШвЊБШsigmoidПь,МѕЩйЕќДњДЮЪ§ЁЃШЛЖј,ДгЭМжаПЩвдПДГі,tanhСНВрЕФЕМЪ§вВЮЊ0,ЭЌбљЛсдьГЩЬнЖШЯћЪЇЁЃ
ШєЪЙгУЪБПЩдквўВиВуЪЙгУtanhКЏЪ§,дкЪфГіВуЪЙгУsigmoidКЏЪ§ЁЃ
ЪЕЯжЗНЗЈЮЊ:
# ЕМШыЯргІЕФЙЄОпАќ
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# ЖЈвхxЕФШЁжЕЗЖЮЇ
x = np.linspace(-10, 10, 100)
# жБНгЪЙгУtensorflowЪЕЯж
y = tf.nn.tanh(x)
# ЛцЭМ
plt.plot(x,y)
plt.grid()
ЛцжЦНсЙћЮЊ:

3.1.3 RELU
Ъ§бЇБэДяЪНЮЊ:
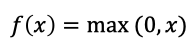
ЧњЯпШчЯТЭМЫљЪО:

ReLUЪЧФПЧАзюГЃгУЕФМЄЛюКЏЪ§ЁЃ ДгЭМжаПЩвдПДЕН,ЕБx<0ЪБ,ReLUЕМЪ§ЮЊ0,ЖјЕБx>0ЪБ,дђВЛДцдкБЅКЭЮЪЬтЁЃЫљвд,ReLU ФмЙЛдкx>0ЪББЃГжЬнЖШВЛЫЅМѕ,ДгЖјЛКНтЬнЖШЯћЪЇЮЪЬтЁЃШЛЖј,ЫцзХбЕСЗЕФЭЦНј,ВПЗжЪфШыЛсТфШыаЁгк0Чјгђ,ЕМжТЖдгІШЈжиЮоЗЈИќаТЁЃетжжЯжЯѓБЛГЦЮЊЁАЩёОдЊЫРЭіЁБЁЃ
гыsigmoidЯрБШ,RELUЕФгХЪЦЪЧ:
- ВЩгУsigmoidКЏЪ§,МЦЫуСПДѓ(жИЪ§дЫЫу),ЗДЯђДЋВЅЧѓЮѓВюЬнЖШЪБ,ЧѓЕМЩцМАГ§ЗЈ,МЦЫуСПЯрЖдДѓ,ЖјВЩгУReluМЄЛюКЏЪ§,ећИіЙ§ГЬЕФМЦЫуСПНкЪЁКмЖрЁЃ
- sigmoidКЏЪ§ЗДЯђДЋВЅЪБ,КмШнвзОЭЛсГіЯжЬнЖШЯћЪЇЕФЧщПі,ДгЖјЮоЗЈЭъГЩЩюВуЭјТчЕФбЕСЗЁЃ
- ReluЛсЪЙвЛВПЗжЩёОдЊЕФЪфГіЮЊ0,етбљОЭдьГЩСЫЭјТчЕФЯЁЪшад,ВЂЧвМѕЩйСЫВЮЪ§ЕФЯрЛЅвРДцЙиЯЕ,ЛКНтСЫЙ§ФтКЯЮЪЬтЕФЗЂЩњЁЃ
ЪЕЯжЗНЗЈЮЊ:
# ЕМШыЯргІЕФЙЄОпАќ
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# ЖЈвхxЕФШЁжЕЗЖЮЇ
x = np.linspace(-10, 10, 100)
# жБНгЪЙгУtensorflowЪЕЯж
y = tf.nn.relu(x)
# ЛцЭМ
plt.plot(x,y)
plt.grid()
ЛцжЦНсЙћЮЊ:

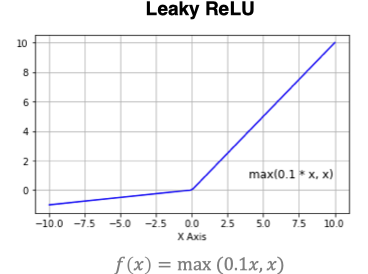
3.1.4 LeakReLu
ИУМЄЛюКЏЪ§ЪЧЖдRELUЕФИФНј,Ъ§бЇБэДяЪНЮЊ:
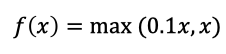
ЧњЯпШчЯТЫљЪО:
ЪЕЯжЗНЗЈЮЊ:
# ЕМШыЯргІЕФЙЄОпАќ
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# ЖЈвхxЕФШЁжЕЗЖЮЇ
x = np.linspace(-10, 10, 100)
# жБНгЪЙгУtensorflowЪЕЯж
y = tf.nn.leaky_relu(x)
# ЛцЭМ
plt.plot(x,y)
plt.grid()
3.1.5 SoftMax
softmaxгУгкЖрЗжРрЙ§ГЬжа,ЫќЪЧЖўЗжРрКЏЪ§sigmoidдкЖрЗжРрЩЯЕФЭЦЙу,ФПЕФЪЧНЋЖрЗжРрЕФНсЙћвдИХТЪЕФаЮЪНеЙЯжГіРДЁЃ
МЦЫуЗНЗЈШчЯТЭМЫљЪО:
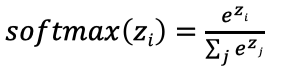
ЪЙгУЗНЗЈ:

softmaxжБАзРДЫЕОЭЪЧНЋЭјТчЪфГіЕФlogitsЭЈЙ§softmaxКЏЪ§,ОЭгГЩфГЩЮЊ(0,1)ЕФжЕ,ЖјетаЉжЕЕФРлКЭЮЊ1(ТњзуИХТЪЕФаджЪ),ФЧУДЮвУЧНЋЫќРэНтГЩИХТЪ,бЁШЁИХТЪзюДѓ(вВОЭЪЧжЕЖдгІзюДѓЕФ)НгЕу,зїЮЊЮвУЧЕФдЄВтФПБъРрБ№ЁЃ
ЪЕЯж,вдЩЯЭМжаЪ§зж9ЕФЗжРрНсЙћЮЊР§ИјДѓМвНјаабнЪО:
# ЕМШыЯргІЕФЙЄОпАќ
import tensorflow as tf
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import numpy as np
# Ъ§зжжаЕФscore
x = tf.constant([0.2,0.02,0.15,1.3,0.5,0.06,1.1,0.05,3.75])
# НЋЦфЫЭШыЕНsoftmaxжаМЦЫуЗжРрНсЙћ
y = tf.nn.softmax(x)
# НЋНсЙћНјааДђгЁ
print(y)
ЗжРрНсЙћЮЊ:
tf.Tensor(
[0.02167152 0.01810157 0.02061459 0.06510484 0.02925349 0.01884031
0.05330333 0.01865285 0.75445753], shape=(9,), dtype=float32)
3.1.6 ЦфЫћМЄЛюКЏЪ§

3.1.7 ШчКЮбЁдёМЄЛюКЏЪ§
вўВиВу:
- гХЯШбЁдёRELUМЄЛюКЏЪ§
- ШчЙћReLuаЇЙћВЛКУ,ФЧУДГЂЪдЦфЫћМЄЛю,ШчLeaky ReLuЕШЁЃ
- ШчЙћФуЪЙгУСЫRelu, ашвЊзЂвтвЛЯТDead ReluЮЪЬт, БмУтГіЯжДѓЕФЬнЖШДгЖјЕМжТЙ§ЖрЕФЩёОдЊЫРЭіЁЃ
- ВЛвЊЪЙгУsigmoidМЄЛюКЏЪ§,ПЩвдГЂЪдЪЙгУtanhМЄЛюКЏЪ§
ЪфГіВу:
- ЖўЗжРрЮЪЬтбЁдёsigmoidМЄЛюКЏЪ§
- ЖрЗжРрЮЪЬтбЁдёsoftmaxМЄЛюКЏЪ§
- ЛиЙщЮЪЬтбЁдёidentityМЄЛюКЏЪ§( f ( x ) = x f(x)=x f(x)=x)
3.2 ВЮЪ§ГѕЪМЛЏ
ЖдгкФГвЛИіЩёОдЊРДЫЕ,ашвЊГѕЪМЛЏЕФВЮЪ§гаСНРр:вЛРрЪЧШЈжиW,ЛЙгавЛРрЪЧЦЋжУb,ЦЋжУbГѕЪМЛЏЮЊ0МДПЩЁЃЖјШЈжиWЕФГѕЪМЛЏБШНЯживЊ,ЮвУЧзХжиРДНщЩмГЃМћЕФГѕЪМЛЏЗНЪНЁЃ

3.2.1 ЫцЛњГѕЪМЛЏ
ЫцЛњГѕЪМЛЏДгОљжЕЮЊ0,БъзМВюЪЧ1ЕФИпЫЙЗжВМжаШЁбљ,ЪЙгУвЛаЉКмаЁЕФжЕЖдВЮЪ§WНјааГѕЪМЛЏЁЃ
3.2.2 БъзМГѕЪМЛЏ
ШЈжиВЮЪ§ГѕЪМЛЏДгЧјМфОљдШЫцЛњШЁжЕЁЃМДдк(-1/ЁЬd,1/ЁЬd)ОљдШЗжВМжаЩњГЩЕБЧАЩёОдЊЕФШЈжи,ЦфжаdЮЊУПИіЩёОдЊЕФЪфШыЪ§СПЁЃ
3.2.3 XavierГѕЪМЛЏ
ИУЗНЗЈЕФЛљБОЫМЯыЪЧИїВуЕФМЄЛюжЕКЭЬнЖШЕФЗНВюдкДЋВЅЙ§ГЬжаБЃГжвЛжТ,вВНазіGlorotГѕЪМЛЏЁЃдкtf.kerasжаЪЕЯжЕФЗНЗЈгаСНжж:
- е§ЬЌЛЏXavierГѕЪМЛЏ:
Glorot е§ЬЌЗжВМГѕЪМЛЏЦї,вВГЦЮЊ Xavier е§ЬЌЗжВМГѕЪМЛЏЦїЁЃЫќДгвд 0 ЮЊжааФ,БъзМВюЮЊ stddev = sqrt(2 / (fan_in + fan_out)) ЕФе§ЬЌЗжВМжаГщШЁбљБО, Цфжа fan_in ЪЧЪфШыЩёОдЊЕФИіЪ§, fan_out ЪЧЪфГіЕФЩёОдЊИіЪ§ЁЃ
ЪЕЯжЗНЗЈЮЊ:
# ЕМШыЙЄОпАќ
import tensorflow as tf
# НјааЪЕР§ЛЏ
initializer = tf.keras.initializers.glorot_normal()
# ВЩбљЕУЕНШЈжижЕ
values = initializer(shape=(9, 1))
# ДђгЁНсЙћ
print(values)
ЪфГіНсЙћЮЊ:
tf.Tensor(
[[ 0.71967787]
[ 0.56188506]
[-0.7327265 ]
[-0.05581591]
[-0.05519835]
[ 0.11283273]
[ 0.8377778 ]
[ 0.5832906 ]
[ 0.10221979]], shape=(9, 1), dtype=float32)
- БъзМЛЏXavierГѕЪМЛЏ
Glorot ОљдШЗжВМГѕЪМЛЏЦї,вВГЦЮЊ Xavier ОљдШЗжВМГѕЪМЛЏЦїЁЃЫќДг [-limit,limit] жаЕФОљдШЗжВМжаГщШЁбљБО, Цфжа limit ЪЧ sqrt(6 / (fan_in + fan_out)), Цфжа fan_in ЪЧЪфШыЩёОдЊЕФИіЪ§, fan_out ЪЧЪфГіЕФЩёОдЊИіЪ§ЁЃ
# ЕМШыЙЄОпАќ
import tensorflow as tf
# НјааЪЕР§ЛЏ
initializer = tf.keras.initializers.glorot_uniform()
# ВЩбљЕУЕНШЈжижЕ
values = initializer(shape=(9, 1))
# ДђгЁНсЙћ
print(values)
ЪфГіНсЙћЮЊ:
tf.Tensor(
[[-0.59119344]
[ 0.06239486]
[ 0.65161395]
[-0.30347362]
[-0.5407096 ]
[ 0.35138106]
[ 0.41150713]
[ 0.32143414]
[-0.57354397]], shape=(9, 1), dtype=float32)
3.2.4 HeГѕЪМЛЏ
heГѕЪМЛЏ,вВГЦЮЊKaimingГѕЪМЛЏ,ГіздДѓЩёКЮт§УїжЎЪж,ЫќЕФЛљБОЫМЯыЪЧе§ЯђДЋВЅЪБ,МЄЛюжЕЕФЗНВюБЃГжВЛБф;ЗДЯђДЋВЅЪБ,ЙигкзДЬЌжЕЕФЬнЖШЕФЗНВюБЃГжВЛБфЁЃдкtf.kerasжавВгаСНжж:
- е§ЬЌЛЏЕФheГѕЪМЛЏ
He е§ЬЌЗжВМГѕЪМЛЏЪЧвд 0 ЮЊжааФ,БъзМВюЮЊ stddev = sqrt(2 / fan_in) ЕФНиЖЯе§ЬЌЗжВМжаГщШЁбљБО, Цфжа fan_inЪЧЪфШыЩёОдЊЕФИіЪ§,дкtf.kerasжаЕФЪЕЯжЗНЗЈЮЊ:
# ЕМШыЙЄОпАќ
import tensorflow as tf
# НјааЪЕР§ЛЏ
initializer = tf.keras.initializers.he_normal()
# ВЩбљЕУЕНШЈжижЕ
values = initializer(shape=(9, 1))
# ДђгЁНсЙћ
print(values)
ЪфГіНсЙћЮЊ:
tf.Tensor(
[[-0.1488019 ]
[-0.12102155]
[-0.0163257 ]
[-0.36920077]
[-0.89464396]
[-0.28749225]
[-0.5467023 ]
[ 0.27031776]
[-0.1831588 ]], shape=(9, 1), dtype=float32)
- БъзМЛЏЕФheГѕЪМЛЏ
He ОљдШЗНВюЫѕЗХГѕЪМЛЏЦїЁЃЫќДг [-limit,limit] жаЕФОљдШЗжВМжаГщШЁбљБО, Цфжа limit ЪЧ sqrt(6 / fan_in), Цфжа fan_in ЪфШыЩёОдЊЕФИіЪ§ЁЃЪЕЯжЮЊ:
# ЕМШыЙЄОпАќ
import tensorflow as tf
# НјааЪЕР§ЛЏ
initializer = tf.keras.initializers.he_uniform()
# ВЩбљЕУЕНШЈжижЕ
values = initializer(shape=(9, 1))
# ДђгЁНсЙћ
print(values)
ЪфГіНсЙћЮЊ:
tf.Tensor(
[[ 0.80033934]
[-0.18773115]
[ 0.6726284 ]
[-0.23672342]
[-0.6323329 ]
[ 0.6048162 ]
[ 0.1637358 ]
[ 0.60797024]
[-0.46316862]], shape=(9, 1), dtype=float32)
4. ЩёОЭјТчЕФДюНЈ
НгЯТРДЮвУЧРДЙЙНЈШчЯТЭМЫљЪОЕФЩёОЭјТчФЃаЭ:

tf.KerasжаЙЙНЈФЃгаСНжжЗНЪН,вЛжжЪЧЭЈЙ§SequentialЙЙНЈ,вЛжжЪЧЭЈЙ§ModelРрЙЙНЈЁЃЧАепЪЧАДвЛЖЈЕФЫГађЖдВуНјааЖбЕў,ЖјКѓепПЩвдгУРДЙЙНЈНЯИДдгЕФЭјТчФЃаЭЁЃЪзЯШЮвУЧНщЩмЯТгУРДЙЙНЈЭјТчЕФШЋСЌНгВу:
tf.keras.layers.Dense(
units, activation=None, use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros')
жївЊВЮЪ§:
- units: ЕБЧАВужаАќКЌЕФЩёОдЊИіЪ§
- Activation: МЄЛюКЏЪ§,relu,sigmoidЕШ
- use_bias: ЪЧЗёЪЙгУЦЋжУ,ФЌШЯЪЙгУЦЋжУ
- Kernel_initializer: ШЈжиЕФГѕЪМЛЏЗНЪН,ФЌШЯЪЧXavierГѕЪМЛЏ
- bias_initializer: ЦЋжУЕФГѕЪМЛЏЗНЪН,ФЌШЯЮЊ0
4.1 ЭЈЙ§SequentialЙЙНЈ
Sequential() ЬсЙЉвЛИіВуЕФСаБэ,ОЭФмПьЫйЕиНЈСЂвЛИіЩёОЭјТчФЃаЭ,ЪЕЯжЗНЗЈШчЯТЫљЪО:
# ЕМШыЯрЙиЕФЙЄОпАќ
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# ЖЈвхвЛИіSequentialФЃаЭ,АќКЌ3Ву
model = keras.Sequential(
[
# ЕквЛВу:МЄЛюКЏЪ§ЮЊrelu,ШЈжиГѕЪМЛЏЮЊhe_normal
layers.Dense(3, activation="relu",
kernel_initializer="he_normal", name="layer1",input_shape=(3,)),
# ЕкЖўВу:МЄЛюКЏЪ§ЮЊrelu,ШЈжиГѕЪМЛЏЮЊhe_normal
layers.Dense(2, activation="relu",
kernel_initializer="he_normal", name="layer2"),
# ЕкШ§Ву(ЪфГіВу):МЄЛюКЏЪ§ЮЊsigmoid,ШЈжиГѕЪМЛЏЮЊhe_normal
layers.Dense(2, activation="sigmoid",
kernel_initializer="he_normal", name="layer3"),
],
name="my_Sequential"
)
НгЯТРДЮвУЧЪЙгУ:
# еЙЪОФЃаЭНсЙћ
model.summary()
ШчЯТЫљЪО:
Model: "my_Sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
layer1 (Dense) (None, 3) 12
_________________________________________________________________
layer2 (Dense) (None, 2) 8
_________________________________________________________________
layer3 (Dense) (None, 2) 6
=================================================================
Total params: 26
Trainable params: 26
Non-trainable params: 0
_________________________________________________________________
ЭЈЙ§етжжsequentialЕФЗНЪНжЛФмЙЙНЈМђЕЅЕФађСаФЃаЭ,НЯИДдгЕФФЃаЭУЛгаАьЗЈЪЕЯжЁЃ
вдЕквЛИівўВуЮЊР§:ИУвўВуга3ИіЩёОдЊ,УПИіЩёОдЊЕФВЮЪ§ЮЊ:4Иі(w1,w2,w3,b1),ЫљвдвЛЙВгУ3x4=12ИіВЮЪ§ЁЃ

4.2 РћгУfunction APIЙЙНЈ
tf.keras ЬсЙЉСЫ Functional API,НЈСЂИќЮЊИДдгЕФФЃаЭ,ЪЙгУЗНЗЈЪЧНЋВузїЮЊПЩЕїгУЕФЖдЯѓВЂЗЕЛиеХСП,ВЂНЋЪфШыЯђСПКЭЪфГіЯђСПЬсЙЉИј tf.keras.Model ЕФ inputs КЭ outputs ВЮЪ§,ЪЕЯжЗНЗЈШчЯТ:
# ЕМШыЙЄОпАќ
import tensorflow as tf
# ЖЈвхФЃаЭЕФЪфШы
inputs = tf.keras.Input(shape=(3,),name = "input")
# ЕквЛВу:МЄЛюКЏЪ§ЮЊrelu,ЦфЫћФЌШЯ
x = tf.keras.layers.Dense(3, activation="relu",name = "layer1")(inputs)
# ЕкЖўВу:МЄЛюКЏЪ§ЮЊrelu,ЦфЫћФЌШЯ
x = tf.keras.layers.Dense(2, activation="relu",name = "layer2")(x)
# ЕкШ§Ву(ЪфГіВу):МЄЛюКЏЪ§ЮЊsigmoid
outputs = tf.keras.layers.Dense(2, activation="sigmoid",name = "layer3")(x)
# ЪЙгУModelРДДДНЈФЃаЭ,жИУїЪфШыКЭЪфГі
model = tf.keras.Model(inputs=inputs, outputs=outputs,name="my_model")
ЭЌбљЭЈЙ§:
# еЙЪОФЃаЭНсЙћ
model.summary()
НсЙћШчЯТЫљЪО:
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, 3)] 0
_________________________________________________________________
layer1 (Dense) (None, 3) 12
_________________________________________________________________
layer2 (Dense) (None, 2) 8
_________________________________________________________________
layer3 (Dense) (None, 2) 6
=================================================================
Total params: 26
Trainable params: 26
Non-trainable params: 0
_________________________________________________________________
СэЭтвВПЩвдЭЈЙ§:
# ФЃаЭеЙЪО
keras.utils.plot_model(model,show_shapes=True)

4.3 ЭЈЙ§modelЕФзгРрЙЙНЈ
ЭЈЙ§modelЕФзгРрЙЙНЈФЃаЭ,ДЫЪБашвЊдк__init__жаЖЈвхЩёОЭјТчЕФВу,дкcallЗНЗЈжаЖЈвхЭјТчЕФЧАЯђДЋВЅЙ§ГЬ,ЪЕЯжЗНЗЈШчЯТ:
# ЕМШыЙЄОпАќ
import tensorflow as tf
# ЖЈвхmodelЕФзгРр
class MyModel(tf.keras.Model):
# дкinitЗНЗЈжаЖЈвхЭјТчЕФВуНсЙЙ
def __init__(self):
super(MyModel, self).__init__()
# ЕквЛВу:МЄЛюКЏЪ§ЮЊrelu,ШЈжиГѕЪМЛЏЮЊhe_normal
self.layer1 = tf.keras.layers.Dense(3, activation="relu",
kernel_initializer="he_normal", name="layer1",input_shape=(3,))
# ЕкЖўВу:МЄЛюКЏЪ§ЮЊrelu,ШЈжиГѕЪМЛЏЮЊhe_normal
self.layer2 =tf.keras.layers.Dense(2, activation="relu",
kernel_initializer="he_normal", name="layer2")
# ЕкШ§Ву(ЪфГіВу):МЄЛюКЏЪ§ЮЊsigmoid,ШЈжиГѕЪМЛЏЮЊhe_normal
self.layer3 =tf.keras.layers.Dense(2, activation="sigmoid",
kernel_initializer="he_normal", name="layer3")
# дкcallЗНЗЈжаЭђЭъГЩЧАЯђДЋВЅ
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
return self.layer3(x)
# ЪЕР§ЛЏФЃаЭ
model = MyModel()
# ЩшжУвЛИіЪфШы,ЕїгУФЃаЭ(ЗёдђЮоЗЈЪЙгУsummay())
x = tf.ones((1, 3))
y = model(x)
ЭЌбљЕФЮвУЧвВПЩвдЭЈЙ§summayЗНЗЈРДВщПДФЃаЭЙЙНЈЕФНсЙћ
5. ЩёОЭјТчЕФгХШБЕу
1.гХЕу
- ОЋЖШИп,адФмгХгкЦфЫћЕФЛњЦїбЇЯАЗНЗЈ,ЩѕжСдкФГаЉСьгђГЌЙ§СЫШЫРр
- ПЩвдНќЫЦШЮвтЕФЗЧЯпадКЏЪ§
- ЫцжЎМЦЫуЛњгВМўЕФЗЂеЙ,НќФъРДдкбЇНчКЭвЕНчЪмЕНСЫШШХѕ,гаДѓСПЕФПђМмКЭПтПЩЙЉЕїгУ
2.ШБЕу
- КкЯф,КмФбНтЪЭФЃаЭЪЧдѕУДЙЄзїЕФ
- бЕСЗЪБМфГЄ,ашвЊДѓСПЕФМЦЫуСІ
- ЭјТчНсЙЙИДдг,ашвЊЕїећГЌВЮЪ§
- аЁЪ§ОнМЏЩЯБэЯжВЛМб,ШнвзЗЂЩњЙ§ФтКЯ