ǰ��
��Ŀ **Label Contrastive Coding based Graph Neural Network for Graph Classification **
�����Ŷ� Yuxiang Ren, Jiyang Bai,Jiawei Zhang
���ߵ�λ �������������ѧ
�������� https://arxiv.org/pdf/2101.05486.pdf
�������Է������������ѧ,����ʹ��ʵ�����ϸ���������Ϣ,���ڱ�ǩ�Ա���ʧ,�����һ�ֻ��ڱ�ǩ�Աȱ����ͼ��������,ʵ���˼ලʽ�ĶԱ�ѧϰ��
֮ǰѧϰ�Ļ��ڶԱ�ѧϰ�����ݶ����ޱ�ǩ��,����������б�ǩ��,�ලʽ�ĶԱ�ѧϰ��
���ĵ���Ҫ��������:
(1)�����һ�ֻ�����ǩ�Աȱ����ͼ������(LCGNN),�Ӷ�ʹ�ø����б���������Ϣǿ���ලʽ�� GNN��
(2)��ǩ�Ա���ʧ���Ա�ѧϰ��չ�����ලѧϰ������,�������ǿ���������ǩ��Ϣ,�Ӷ���֤���ڵľۺ��������Ŀɷ�����
(3)�������������ͼ����������̬��ǩ�洢����ʵ�ּලʽ�ĶԱ�ѧϰ��
Abstract
�ڸ��ָ�����Ӧ��������,ͼ�����һ����Ҫ���о����⡣Ϊ��ѧϰһ��ͼ����ģ��,Ŀǰ����Ϊ�㷺ʹ�õļලʽ������ʹ�������ı����ͷ�����ʧ(����,��������ʧ���� softmax �� Margin loss)����ʵ��,ʵ��֮����б�ʽ��Ϣ���ȸ�ϸ,��������ͼ��������Ϊ�˸���Ч����ȫ������ñ�ǩ��Ϣ,���������һ���µĻ��ڱ�ǩ�Աȱ����ͼ������(LCGNN)��LCGNN ��Ȼ���÷�����ʧ����֤��Ŀ��б��ԡ�ͬʱ,LCGNN �����Լලѧϰ���������ǩ�Ա���ʧ���ٽ�ʵ���������ھۺ��Ժ����ɷ�����Ϊ��ʵ�ֶԱ�ѧϰ,LCGNN ��������̬��ǩ�洢�����������±�������
1 Introduction
��ʵ���������������Ӧ�ö����ֳ���ͼ���ݽṹ����������,���罻����[15]������ƽ̨[20]��������Ϣѧ[5]��ͼ�����Ŀ����ʶ�����ݼ���ͼ�����ǩ,�����ڶ�Ӧ���е�һ����Ҫ���⡣����,������ѧ��,�����ʿ�����ͼ�α�ʾ,����ÿ��������л���һ���ڵ�,�л�֮��Ŀռ��ϵ(���롢�Ƕ�)��ͼ�εıߡ��Ա�ʾ�����ʵ�ͼ�ν��з���,������Ԥ�⵰���ʽӿ�[5]��
������,ͼ������(GNNs)��ͼ����������ȡ���˳�ɫ������[29,33]��GNNSּ�ڽ��ڵ�ת��Ϊ��ά����,�Ա���ͼ�ṹ��Ϣ������[34]������GNNSӦ����ͼ����ʱ,���ķ�����Ϊͼ�е����нڵ���������,Ȼ��������Щ�ڵ���������Ϊ����ͼ�ı�ʾ,����ʹ��һ������ͻ��ڽڵ�������[31]�����е������硣��������ͼ�ı�ʾ,ͨ��ʹ�üල�����ʵ��ͼ�����Ŀ�ġ����������ͷ�����ʧ(����,��������ʧ��softmax�����ʧ)����������gnn����õļල���[29,28,32,6]������ල�����ע��Ŀɼ�����,��������ʵ�����ļ����ʾ�����ѧϰ��ǿ��ʾ�������ڷ��������һ���������þ����ܶ���б���Ϣ��ǿ��ģ��[4]����ȷ��˵,���������ھۺ��Ժ����ɷ���[14]��ͼ��ʾ��ͼ���������и���Ч��
��������Լලѧϰ[3]�ͶԱ�ѧϰ[7,18]������,�Ա���ʧ[17]�ܹ���ȡ����ļ�����Ϣ�����ģ�͵����ܡ����ʹ�öԱ���ʧ���б�ʾѧϰ���о�[8,18,35]��Ҫ�����ලѧϰ�������½��еġ���Щ�Ա�ѧϰģ�ͽ�ÿ��ʵ����Ϊһ������������ͬʱ,�����Щʵ�������ǵ�ѧϰĿ��[7]���ڼ�����Ӿ�[26]������,һϵ�жԱ�ѧϰ�ѱ�֤���ܹ���Ч��ѧϰ��ϸ���ȵ�ʵ�������������,���Ǽƻ�����ͼ���������ϵĶԱ�ѧϰ���ֲ��ල�������ʵ������б���Ϣ�IJ��㡣Ȼ��,��Ӧ�öԱ�ѧϰʱ,���еĽϴ�����ڱ仯���ܻ��ͼ��������[14]��������������,���еĻ��ڶԱ�ѧϰ��GNNS(��GCC[18])������ģ�͵�ѵ��ǰ����������衣��˵���gnn���,ͨ���Ա�ѧϰѧϰ����ͼ��ʾ����ֱ������ͼ���������Ӧ������
Ϊ�˽��ͼ���������,������������ڱ�ǩ�Աȱ����ͼ������(LCGNN),������������ǩ�Ա���ʧ��ͬʱ��ǿʵ���������ھۺ��Ժ����ɷ����������е�ʹ�õ�����ʵ���ĶԱ�ѧϰ��ͬ,��ǩ�Աȱ��� �����ǩ��Ϣ,����������ͬ��ǩ��ʵ����Ϊ�����ʵ����ͨ�����ַ�ʽ,������ͬ��ǩ��ʵ���������ø���,��������ͬ��ǩ��ʵ�����˴��ƿ���ͬʱ���������ھۺ��Ժ����ɷ�������ǩ�Աȱ������Կ����Ƕ������������ֵ��������[7]��ѵ����Ϊ�˹���һ���㷺��һ�µ��ֵ�,���������һ����̬��ǩ�洢����һ���������µ�ͼ�α�������ͬʱ,LCGNN��ʹ����Classification Loss����֤����Ŀɷֱ��ԡ�LCGNN�������ñ�ǩ��Ϣ��ʵ�������༶����Ч��ȫ��������ø��ٵı�ǩ������ʵ�ֱȽ�����,������Ϊ��������һ�ֱ�ǩ��ǿ��������֤������8����ͼ���ݼ���,LCGNN��ͼ���������Ӱ�졣LCGNN��7��ͼ���ݼ���ʵ����SOTA���ܡ���ʲô����Ҫ����,��ʹ�ý��ٵ�ѵ������ʱ,LCGNN�ı������ڻ��߷���,�Ӷ���ȫ�����֤����Ա�ǩ��Ϣ��ѧϰ������
The contributions of our work are summarized as follows:
���������һ���µĻ��ڱ�ǩ�Աȱ����ͼ������(LCGNN),ʹ�мල��ͼ��������и���ļ�����Ϣ��
��ǩ�Ա���ʧ���Ա�ѧϰ��չ���ල����,�ڼල�����п��Ե����ǩ��Ϣ,�Ա�֤���ڵľۺ��Ժ����Ŀɷ��ԡ�
������������µ�ͼ����������̬��ǩ�������֧�����ǵļල�Ա�ѧϰ��
������8����ͼ���ݼ��Ͻ����˹㷺��ʵ�顣LCGNN�����ڶ�����ݼ���ʵ����SOTA����,���ҿ����ý��ٵı��ѵ�������ṩ�ɱȽϵĽ����
2 Related Works
���ֲ�ͬ�ļ�������������ͼ�ķ������⡣һ����Ҫ������ǻ���graph kernel�ķ���,��ѧϰһ��graph kernel������ͼ֮���������,������ͼ��ǩ[25]��The Weisfeiler-Lehman subtree kernel (WL) [21],Multiscale Laplacian graph kernels (MLG) [13], and Graphlets kernel(GK) ���Ǿ��д����Ե�ͼ�ˡ���һ���ؼ�����ǻ������ѧϰ�ķ�����Deep Graph Kernel (DGK) [30], Anonymous Walk Embeddings (AWE), and Graph2vec �����������ѧϰ��ܽ�����ȡͼ���������е�ͼ����������ͼ������(GNNS)������,ͨ��ѧϰͼ�ı�ʾ,����GNNSҲ������ͼ�ķ�������,���潫�Դ˽��н��ܡ�
Graph Neural Networkͼ������
ͼ������ͨ���ݹ������ۺϷ���[29]ѧϰ��άͼ��ʾ��������ͼ��ʾ�������ڸ�����������,��ͼ�����top-k���ƶ�����������ѧϰ����,Ŀǰ�ܹ�������ͼ�����GNN���Է�Ϊ�˵���ģ�ͺ�ѵ��ǰģ�͡��˵���ģ��ͨ���ڼල���ල������,���Ż����ඪʧ����ϢΪĿ��,��Ҫ����GIN[29]��CapsGNN[28]��DGCNN[32]��InfoGraph[23]��Ԥ��ѵ����gnnʹ���ض���ѵ��ǰ����[9]��ѧϰ�ල�����µ�ͼ��һ���ʾ��Ϊ��ִ��ͼ��������,��ʹ��һ���ֱ�ǩ���ݶ�ģ��[18]��������
Contrastive Learning �Ա�ѧϰ
�Ա�ѧϰ�ѱ��㷺�����ලѧϰ,ͨ��ѵ��������,���Բ������ݵ������ԡ��Ա���ʧͨ����һ���Ʒֺ���,�����ӵ���ƥ��ʵ���ķ���,���ٶ����ƥ��ʵ���ķ�������ͼ����,DGI�ǵ�һ�����öԱ�ѧϰ˼���GNNģ��,���нڵ��ͼ��ʾ֮��Ļ���Ϣ������Ϊ�Աȶ�����HDGI���û�����չ���칹ͼ��InfoGraph�ڰ�ලͼ����ʾѧϰ��ִ�жԱ�ѧϰ������Լලѧϰ������,��ͼ����ʱ,���ǻ���Ҫ���öԱ�ѧϰ�����������������ԡ�GCC���öԱ�ѧϰԤѵ��ģ��,ͨ���������������ε�ͼ�����������������,���ǵķ�����һ���˵���ģ��,��ִ�б�ǩ�Աȱ���,�Թ���ʵ���������ھۺ��Ժ����ɷ���
3 Proposed Method
�ڱ�����,���ǽ����˻��ڱ�ǩ�Աȱ����ͼ������(LCGNN)���ڽ���LCGNN֮ǰ,�����ȶ�ͼ������һ�������Ľ��ܡ�
3.1 Preliminaries
ͼ�����Ŀ���Ǹ���ͼ�Ľṹ��Ϣ�ͽڵ�����Ԥ��ͼ�����ǩ������ʽ��,����������ʾ:
����һ����ͼ G L = { ( G 1 , y 1 ) , ( G 2 , y 2 ) , �� } \mathbb{G}_{L}=\left\{\left(\mathcal{G}_{1}, y_{1}\right),\left(\mathcal{G}_{2}, y_{2}\right), \ldots\right\} GL?={(G1?,y1?),(G2?,y2?),��}�� y i y_{i} yi?�� G i G_{i} Gi?��Ӧ�ı�ǩ��
������ѧϰһ�����ຯ�� f f f: G ? Y \mathcal{G} \longrightarrow \mathbb{Y} G?Y��δ֪ͼ G U G_{U} GU?����Ԥ�⡣
3.2 LCGNN Architecture Overview
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-MLf8upu2-1656589160300)(https://secure2.wostatic.cn/static/4TJGcWY8SSKqTFFSWw44bS/image.png)]](https://img-blog.csdnimg.cn/6ceb62c865564236ac0840325ac76208.png)
Fg1.LCGNN�ĸ߲�ṹ��LCGNNʹ�������ʧѵ��ͼ������**** f q f_{q} fq?��ͼ��������Label Contrastive Loss��ǩ�Ա���ʧ ��Classification Loss������ʧ���ɻ����ʧ��LCGNN��ʹ�õ�������ʧ�ǽ�������ʧ����ǩ�Ա���ʧ���ֵ�������������query������ͼminiBatch��ÿ��ͼ,�ֵ���һ�����Բ���������֪��ǩͼ��ʾ�Ĵ洢�����洢���е�ͼ��ʾ������������ͼ������ f k f_k fk?�����¡�����ѵ��,ѧϰ����ͼ������ f q f_{q} fq?��ͼ��������������ͼ��������
���������LCGNN��ѧϰ������ͼ1��ʾ��ͨ��,���������ͼ,������Ҫͨ�������ܵ�ͼ����������ȡDZ�ڵ�����,�Է�����ͼ�ķ��ࡣΪ���������������ʧ(Label contrast loss & classification Loss), LCGNN��������ͼ������ f k f_{k} fk?�� f q f_{q} fq?,�ֱ����ڱ�������key graph��query graph��Label contrast Loss��ǩ�Ա���ʧ ͨ�������м��б��ʾ,����ʵ���������ھۺ��Ժ����ɷ���,�����ඪʧ��ȷ���༶�Ŀɷ�����һ�ְ����ؼ�ͼ��ʾ����Ӧ��ǩ�Ķ�̬�洢�����ڱ�ǩ�Ա���ļ��㡣ͼ��������ͼ������fq�ı�ʾ��Ϊ������Ԥ��ͼ��ǩ���������ǽ���ϸ����ÿ������Լ�LCGNN��ѧϰ���̡�
Label contrast Loss��ǩ�Ա���ʧ:�Ա�ѧϰ ��Ҫ������������ Ҳ����������������ĸ����,��������ԭ��
Classification Loss ���ඪʧ��ȷ���༶�Ŀɷ��� - �������ָ�Ĵ���,��è��
3.3 Label Contrastive Coding
���еĶԱ�ѧϰ�ѱ�֤����һ�ֳɹ��ķ���ȥѵ��������,���Բ���ͼ�����ݱ����ͨ�ýṹ��Ϣ����ͼ����������,��ͨ�õĽṹģʽ���,������Ҫ��ע�������صĽṹģʽ�����,�����������ǩ�Աȱ���ѧϰȥ���־��в�ͬ���ǩ��ʵ��,�����ǽ�ÿ��ʵ����Ϊ������һ����ͬ��,����������ͬ������жԱȡ�
�����ĶԱ�ѧϰloss:
�Ա�ѧϰ���Ա���Ϊ��ͨ���ֵ��������Ӷ���ɱ�����ѧϰ�����ǿ������������Ա�ѧϰ������һ������query q q q��һ������m������keys {k1, k2,��, km},��ֻ��һ�������� k + k+ k+(ͨ����q����ͬһ��ʵ��)���� q q q�������� k + k+ k+����,���븺��q(�ֵ�������������)��ͬʱ,���ֶԱ�ѧϰ����ʧ�ϵ͡�
һ���㷺ʹ�õĶԱ���ʧ��InfoNCE :
L = ? log ? exp ? ( q ? k + / �� ) �� i = 1 m exp ? ( q ? k i / �� ) \mathcal{L}=-\log \frac{\exp \left(\mathbf{q} \cdot \mathbf{k}_{+} / \tau\right)}{\sum_{i=1}^{m} \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)} L=?log��i=1m?exp(q?ki?/��)exp(q?k+?/��)?
����,�����¶ȳ�����[26]��������,InfoNCE����ʧ��һ�ַ�����ʧ,Ŀ���ǽ�q��m = 1����ൽ��k+��ͬ���ࡣ
����������֪��ǩ,�϶�����ֱ��ʹ�����loss
����,�����ͼ��������ʱ,���ǩ�Ѿ�ȷ��,����ϣ����ѵ�������е�����֪�ı�ǩ��Ϣ,�Ը����Ա�ѧϰ������ͼ������������,�����������ǩ�Աȱ���
Define similar and dissimilar ��ͼ����������,����Ѱ������ͬ��ǩ��ʵ�����ø���,��������ͬ��ǩ��ʵ�����˴��ƿ������,�ڱ�ǩ�Աȱ�����,���ǽ�������ͬ��ǩ������ʵ����Ϊ���ƶ� ������,��������ͬ��ǩʵ����ɵ�һ��ʵ����Ϊ��ͬ�� ��������
�������Moco������,Moco��ѡȡһ��������,�����䱾��ͨ����ͬ��������ǿ����,��������������������ǰѾ�����ͬ��ʵ������ ������ ��ͬ��ǩʵ������������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-tCsB5Lto-1656589160303)(https://secure2.wostatic.cn/static/qqDWWTaP7aENdX9vEe2Tx2/image.png)]](https://img-blog.csdnimg.cn/1fb403eb032845febf6b56a3525d6f24.png)
Fig. 2.Label Contrastive Loss.queryͼGq��keyͼGk�ֱ���fq��fk����Ϊ��ά��ʾq��k�� k 1 k_1 k1?�� k 2 k_2 k2?��q��ͬ�ı�ǩ��Ϊ�����������ڱ�ǩ��ͬ,K3��k4�Ǹ���������ǩ�Ա���ʧ ��ʹģ���������Ƶ�һ��(Gq, Gk1)��(Gq, Gk2)�Ͳ�ͬ��ʵ����(��������),��(Gq, Gk3)��
Label contrative loss ��Ȼ���ֵ���ҵĽǶ�����,����һ���б�ǩ�ı���query(q, y)��һ����m���б�ǩ���� k e y s ( k 1 , y 1 ) , ( k 2 , y 2 ) , �� , ( k m , y m ) �� �� �� , �� ǩ �� �� �� �� �� �� �� �� �� keys{{(k_{1}, y_{1}), (k_{2}, y_{2}),��,(k_{m}, y_{m})} }���ֵ�,��ǩ�Աȱ����е������� keys(k1?,y1?),(k2?,y2?),��,(km?,ym?)������,��ǩ������������������k+ �� �� ��y_{i} = y �� �� �ļ� ����k_i �� �� ǩ �� �� �� �� �� �� �� �� �� �� q u e r y q ƥ �� �� �� �� ����ǩ�Աȱ������ֵ��в���query qƥ������� ����ǩ��������������������queryqƥ��������k_i �� �� �� �� �� �� �� �����ڱ����� ��������������query (q, y) , �� �� ǩ �� �� �� ʧ ,���ǩ�Ա���ʧ ,����ǩ������ʧ\mathcal{L}_{L C}$����Ϊ
L L C ( q , y ) = ? log ? �� i = 1 m 1 y i = y ? exp ? ( q ? k i / �� ) �� i = 1 m exp ? ( q ? k i / �� ) \mathcal{L}_{L C}(\mathbf{q}, y)=-\log \frac{\sum_{i=1}^{m} \mathbb{1}_{y_{i}=y} \cdot \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)}{\sum_{i=1}^{m} \exp \left(\mathbf{q} \cdot \mathbf{k}_{i} / \tau\right)} LLC?(q,y)=?log��i=1m?exp(q?ki?/��)��i=1m?1yi?=y??exp(q?ki?/��)?
����,��� 1 statement? �� { 0 , 1 } \mathbb{1}_{\text {statement }} \in\{0,1\} 1statement??��{0,1}��һ��������ָʾ��,������Ϊ��,��1�����Ǿ���˵��ͼ2�еı�ǩ�Ա���ʧ�Թ��ο�����LCGNN��,key ��ͼ��ʾ�洢�ڶ�̬�洢���С�Ϊ�˼����,����û����ͼ2����ʾ�����ǽ���������ܶ�̬�洢�⼰����¹��̡�
The dynamic memory bank�ڱ�ǩ�Աȱ�����,m��С���ֵ��DZ�Ҫ�ġ�����ʹ��dynamic memory bank��Ϊ�ֵ䡣Ϊ�˳�����ñ�ǩ��Ϣ,�洢��Ĵ�С�����б�ǩ��ͼ�� G L G_{L} GL?�Ĵ�С,�� m = �O G L �O m = |G_L| m=�OGL?�O��Memory bank �洢��Ȱ�������ĵ�άkey��ͼ��ʾ,Ҳ������Ӧ�ı�ǩ,�� { ( k 1 , y 1 ) , ( k 2 , y 2 ) , �� , ( k �O G L �O , y �O G L �O ) } \left\{\left(\mathbf{k}_{1}, y_{1}\right),\left(\mathbf{k}_{2}, y_{2}\right), \ldots,\left(\mathbf{k}_{\left|\mathbb{G}_{L}\right|}, y_{\left|\mathbb{G}_{L}\right|}\right)\right\} {(k1?,y1?),(k2?,y2?),��,(k�OGL?�O?,y�OGL?�O?)}.����MoCo�еĽ���,��ѵ��������ͼ�α����� f k f_k fk?����������ʱ,Ӧ�����ܱ���key��ͼ��ʾ��һ���ԡ����,��ÿ��ѵ��ʱ��,�±����keyͼ�ᶯ̬���滻�洢���еľ���Կͼ��
3.4 Graph Encoder Design
���ڸ�����ͼ G q G_q Gq?�� G k G_k Gk?, LCGNN��������ͼ������ f q f_q fq?�� f k f_k fk?�������Ϊ��ά��ʾ��
q = f q ( G q ) k = f k ( G k ) \begin{aligned} \mathbf{q} &=f_{q}\left(\mathcal{G}^{q}\right) \\ \mathbf{k} &=f_{k}\left(\mathcal{G}^{k}\right) \end{aligned} qk?=fq?(Gq)=fk?(Gk)?
LCGNN��, f q f_q fq?�� f k f_k fk?������ͬ�Ľṹ��ͼ�������Ѿ�֤��������ͼ�ṹ���ݵ�ǿ���������������DZ�ڵ�ͼ�����������ΪLCGNN�е�ͼ��������
LCGNN�п��������ֱ���������һ����ͼͬ������Graph Isomorphism Network(GIN)[29]��GINʹ�ö���֪��(MLPs)����˼�ۺϷ���,�����ڵ��ʾ����Ϊ
h v k = MLP ? ( k ) ( ( 1 + ? ( k ) ) + �� u �� N ( v ) h u ( k ? 1 ) ) h_ {v}^{k}=\operatorname{MLP}^{(k)}\left(\left(1+\epsilon^{(k)}\right)+\sum_{u \in \mathcal{N}(v)} h_{u}^{(k-1)}\right) hvk?=MLP(k)???(1+?(k))+u��N(v)��?hu(k?1)????
ʽ��, ? \epsilon ?Ϊ��ѧϰ������̶�����,k��ʾ��k�㡣�ڸ��������ڵ�ı�ʾ�����,��GIN����˶�ȡ������������ͼg�ı�ʾg,����ͼ����
����
g = �� k = 1 K ( SUM ? ( { h v k �O v �� G } ) ) \boldsymbol{g}=\|_{k=1}^{K}\left(\operatorname{SUM}\left(\left\{h_{v}^{k} \mid v \in \mathcal{G}\right\}\right)\right) g=��k=1K?(SUM({hvk?�Ov��G}))
����,k�������������
���ǿ��ǵĵڶ����������Ǵ��ṹѧϰ�IJ��ͼ�ػ�(HGP-SL)[33]��HGP-SL��ͼ�ػ��ͽṹ��ѧϰ���ϵ�һ��ͳһ��ģ����,������ͼ�ķֲ��ʾ��HGP-SL�����һ��ͼ�ز���,ʶ����Ϣ�ڵ��Ӽ�,�γ�һ���µĵ���С��ͼ�����ڻ��������پ���ijػ���������ϸ��Ϣ�������õ�[33]������ͼG, HGPSL����ظ�ͼ�ľ����ͳػ�����,�ڲ�ͬ�IJ���ʵ�ֶ����ͼ:H1, H2,��,HK��HGP-SLʹ��mean-pooling��max-pooling���������ۺ���ͼ�е����нڵ��ʾ,������ʾ
r k = R ( H k ) = �� ( 1 n k �� p = 1 n k H k ( p , : ) �� max ? q = 1 d H k ( : , 1 ) ) \mathbf{r}^{k}=\mathcal{R}\left(\mathbf{H}^{k}\right)=\sigma\left(\frac{1}{n^{k}} \sum_{p=1}^{n^{k}} \mathbf{H}^{k}(p,:) \| \max _{q=1}^{d} \mathbf{H}^{k}(:, 1)\right) rk=R(Hk)=��???nk1?p=1��nk?Hk(p,:)��q=1maxd?Hk(:,1)???
ʽ�Ц�Ϊ�����Լ������NkΪ��k����ͼ�Ľڵ�����Ϊ��ʵ������ͼg�����ձ�ʾg,������һ��������������ͬ�����ͼ�������
g = SUM ? ( r k �O k = 1 , 2 , �� , K ) \boldsymbol{g}=\operatorname{SUM}\left(\mathbf{r}^{k} \mid k=1,2, \ldots, K\right) g=SUM(rk�Ok=1,2,��,K)
��ʵ�鲿��,���ǽ�չʾ��LCGNN��ʹ��GIN��HGP-SL��Ϊͼ�������������Լ�������
3.5 LCGNN Learning
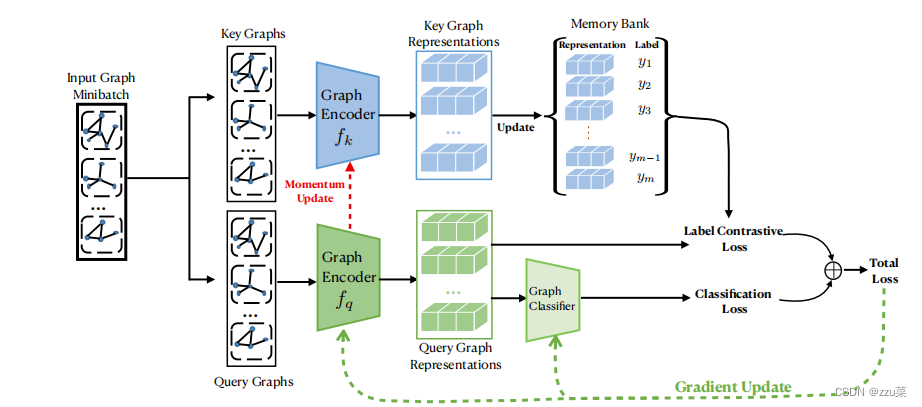
ͼ1�ṩ��ѵ������˵������ѵ��������,LCGNN��������һ����Ǻõ�ͼ G b ? G L \mathbb{G}_{b} \subset \mathbb{G}_{L} Gb??GL?�� ����ÿ��С������,keyͼ���Ϻ�queryͼ������ͬΪ G b \mathbb{G}_{b} Gb?.ͼ������ f q f_q fq?�� f k f_k fk?��ʼ��������ͬ ( �� q = �� k ) (��q = ��k) (��q=��k).The memory bank��s size is equal to the size of the set of labeled graphs ? ? G L ? ? ** \mathbb{G}_{L}** ??GL???.���� y i y_i yi?��ǩ�ı��ͼ G i G_i Gi?������һ�������ʾ����ʼ���洢������keyͼ������ f k f_k fk?����������Ϊ��άkeyͼ��ʾ K \mathbb{K} K,�Ӷ��滻�洢������Ӧ�ı�ʾ��queryͼ������fq����,��queryͼ��ʾ Q \mathbb{Q} Q,�� Q \mathbb{Q} QҲ��ͼ�����������롣��LCGNN��,���ع����Ϊͼ������������ͼ�����������,���Լ����������ʧ
L C l a = ? 1 �O Q �O �� q i �� Q �� j �� Y 1 q i , j log ? ( p q i , j ) \mathcal{L}_{C l a}=-\frac{1}{|\mathbb{Q}|} \sum_{\mathbf{q}_{i} \in \mathbb{Q}} \sum_{j \in \mathbb{Y}} \mathbb{1}_{\mathbf{q}_{i}, j} \log \left(p_{\mathbf{q}_{i}, j}\right) LCla?=?�OQ�O1?qi?��Q��?j��Y��?1qi?,j?log(pqi?,j?)
������1һ��������ָʾ��(0��1),��ʾ��ǩj�Ƿ��DZ����ѯͼ q i q_i qi?����ȷ���ࡣ( p q i p_{q_i} pqi??, j j j)ΪԤ�����
Q��memory bankһ����,ʵ��ǰ�������ı�ǩ�Աȱ��롣���ݹ�ʽ2,С����Gb�ı�ǩ�Ա���ʧΪ:
L L C = ? 1 �O Q �O �� q i �� Q L L C ( q i , y q i ) \mathcal{L}_{L C}=-\frac{1}{|\mathbb{Q}|} \sum_{\mathbf{q}_{i} \in \mathbb{Q}} \mathcal{L}_{L C}\left(\mathbf{q}_{i}, y_{\mathbf{q}_{i}}\right) LLC?=?�OQ�O1?qi?��Q��?LLC?(qi?,yqi??)
Ϊ�˸���Ч����ȫ������ñ�ǩ��Ϣ��ģ�ͽ���ѵ��,���ǽ�ϱ�ǩ�Ա���ʧ(label contrast loss)�ͷ�����ʧ(Classification loss),�����������»����ʧ:
L total? = L C l a + �� L L C \mathcal{L}_{\text {total }}=\mathcal{L}_{C l a}+\beta \mathcal{L}_{L C} Ltotal??=LCla?+��LLC?
����,�������¿��Ʊ�ǩ�Ա���ʧ�ͷ�����ʧ֮������Ȩ�ء� L total? \mathcal{L}_{\text {total }} Ltotal??����Ķ�����
L L C \mathcal{L}_{L C } LLC?����ʵ���������ھۺ��Ժ����ɷ�����,
�� L C l a \mathcal{L}_{C l a} LCla?ȷ����Ŀ������ԡ�
ͼ������fq��ͼ���������Ը������Ltotal���ж˵��˵ķ������¡�fk�IJ�����k���û��ڶ���������9����,�����Ƿ�����ʽ��������˵,�������¹���Ϊ
�� k ? �� �� k + ( 1 ? �� ) �� q \theta_{k} \longleftarrow \alpha \theta_{k}+(1-\alpha) \theta_{q} ��k??����k?+(1?��)��q?
���Ц�[0,1)Ϊ����fk�ݻ��ٶȵĶ���Ȩ�ء�����ʹ�����ֻ��ڶ����ĸ��»���,�������Լ��ٷ����Ŀ���,���ҿ����ڱ��������ϸĽ��������,���ִ洢���йؼ�ͼ��ʾ��һ���ԡ�
�����ģ��ѵ����,ѧϰ����ͼ������fq��ͼ�������������ڶ�δ��ǵ�ͼGU����ͼ��������