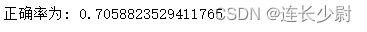1. ��Ŀ:
���ʵ�ֶ��ʻع�,�������������ݼ�3.0���ϵĽ����
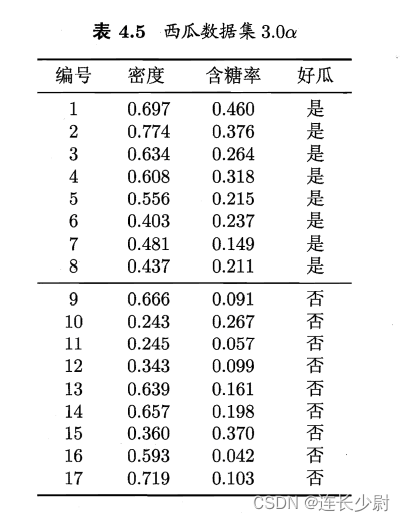
���ݼ�3.0������ͼ
2. ���ʻع�(�����ع�)ģ�ͼ��:
���Ȼع����Իع�ģ��:
y
=
w
T
x
+
b
y = \boldsymbol{w^{T}}\boldsymbol{x}+b
y=wTx+b
��ģ��ѵ����,���ջ��ҵ�y��x֮������Թ�ϵ������Щ���ݲ��������������Թ�ϵ,���Ƿ���g(y)��x�����Թ�ϵ,���������ݵ�Ҫ��ͽ�����,�������������������Իع�ģ��:
y
=
g
?
1
(
w
T
x
+
b
)
y = g^{-1}(\boldsymbol{w^{T}}\boldsymbol{x}+b)
y=g?1(wTx+b)
������ģ�����ڻع�����,������Ƿ�������,������Ҫ��y�����������������Ŀ�����,����Ҫ��֤Ԥ��ֵ������0-1֮��,����������Ҫ��y��������һ���������ʺ���:
g
(
x
)
=
ln
?
x
1
?
x
g(x) = \ln \frac{x}{1-x}
g(x)=ln1?xx?
���������ʺ������뵽�������Իع�ģ��,���ɵõ����ʻع�ģ��:
ln
?
y
1
?
y
=
w
T
x
+
b
\ln \frac{y}{1-y} = \boldsymbol{w^{T}}\boldsymbol{x}+b
ln1?yy?=wTx+b
Ҳ��д��
y
=
1
1
+
e
?
(
w
T
x
+
b
)
y = \frac{1}{1+e^{-(\boldsymbol{w^{T}}\boldsymbol{x}+b)}}
y=1+e?(wTx+b)1?
3.���ѵ��(���ʻع��Ƶ�)
����,������Ҫ��y�����������ļ���,д��p(y=1|x),
1-y�����Ƿ����ļ���,д��p(y=0|x)�����뵽���ʻع�ģ��(�����Ǹ�)���п��Ե�:
ln
?
p
(
y
=
1
�O
x
)
p
(
y
=
0
�O
x
)
=
w
T
x
+
b
\ln \frac{p(y=1|x)}{p(y=0|x)} = \boldsymbol{w^{T}}\boldsymbol{x}+b
lnp(y=0�Ox)p(y=1�Ox)?=wTx+b
������p(y=1|x):
ln
?
p
(
y
=
1
�O
x
)
1
?
p
(
y
=
1
�O
x
)
=
w
T
x
+
b
\ln \frac{p(y=1|x)}{1-p(y=1|x)} = \boldsymbol{w^{T}}\boldsymbol{x}+b
ln1?p(y=1�Ox)p(y=1�Ox)?=wTx+b
p
(
y
=
1
�O
x
)
1
?
p
(
y
=
1
�O
x
)
=
e
w
T
x
+
b
\frac{p(y=1|x)}{1-p(y=1|x)} =e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}
1?p(y=1�Ox)p(y=1�Ox)?=ewTx+b
1
1
?
p
(
y
=
1
�O
x
)
?
1
=
e
w
T
x
+
b
\frac{1}{1-p(y=1|x)} - 1 =e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}
1?p(y=1�Ox)1??1=ewTx+b
p
(
y
=
1
�O
x
)
=
e
w
T
x
+
b
e
w
T
x
+
b
+
1
p(y=1|x) =\frac{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b} }{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}+1 }
p(y=1�Ox)=ewTx+b+1ewTx+b?
��p(y=0|x):
p
(
y
=
0
�O
x
)
=
1
?
p
(
y
=
1
�O
x
)
p(y=0|x) = 1 - p(y=1|x)
p(y=0�Ox)=1?p(y=1�Ox)
p
(
y
=
0
�O
x
)
=
1
e
w
T
x
+
b
+
1
p(y=0|x) = \frac{1 }{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}+1 }
p(y=0�Ox)=ewTx+b+11?
����,�õ������������ĸ��ʷֲ�,������Ҫ���ľ��ǽ�w��b���Ƴ���,�������Ҫ�õ�������������ͳ�ƵIJ�������֪ʶ�еļ�����Ȼ����������Ȼ�������ڷֲ���֪,����δ֪�����,�����������������������Ȼ��Ҫ�����ҵ���������Ȼ������l(w,b),���̾����Ƚ�ÿ��������Ӧ�ĸ��ʵõ�,Ȼ�����,��ȡ����,�Ϳ��ҵ�������Ȼ����,Ȼ���ҵ��ú����ü���ֵ��,��Ӧ����w��b�ù���ֵ���ص�������,���ȵõ�������ȻΪ:
l
(
w
,
b
)
=
��
i
=
1
m
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
\boldsymbol{l}(\boldsymbol{w},b) = \sum_{i=1}^{m}\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b)
l(w,b)=i=1��m?lnp(yi?�Oxi?;w,b)
Ȼ��,����������,Ϊ����,�涨�˷���:
��
=
(
w
;
b
)
\boldsymbol{\beta}=(\boldsymbol{w};b)
��=(w;b)
x
^
=
(
x
;
1
)
\boldsymbol{\widehat{x}}=(\boldsymbol{x};1)
x
=(x;1)
p
1
(
x
^
;
��
)
=
p
(
y
=
1
�O
x
^
;
��
)
p_{1}(\boldsymbol{\widehat{x};\beta})=p(y=1|\boldsymbol{\widehat{x};\beta})
p1?(x
;��)=p(y=1�Ox
;��)
p
0
(
x
^
;
��
)
=
p
(
y
=
0
�O
x
^
;
��
)
p_{0}(\boldsymbol{\widehat{x};\beta})=p(y=0|\boldsymbol{\widehat{x};\beta})
p0?(x
;��)=p(y=0�Ox
;��)
����Զ���Ȼ�������д:
p
(
y
i
�O
x
i
;
w
,
b
)
=
y
i
p
1
(
x
^
i
;
��
)
+
(
y
i
?
1
)
p
0
(
x
^
i
;
��
)
p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) = y_{i}p_{1}(\boldsymbol{\widehat{x}_{i};\beta})+(y_{i}-1)p_{0}(\boldsymbol{\widehat{x}_{i};\beta})
p(yi?�Oxi?;w,b)=yi?p1?(x
i?;��)+(yi??1)p0?(x
i?;��)
���Կ���,��ѵ��������,yֻ��ȡ0��1,��y=1ʱ,ֻ��ǰһ����Ч,y=0ʱ,ֻ�к�һ����Ч��
Ȼ��,��
p
(
y
=
1
�O
x
)
=
e
w
T
x
+
b
e
w
T
x
+
b
+
1
p(y=1|x) =\frac{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b} }{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}+1 }
p(y=1�Ox)=ewTx+b+1ewTx+b?
��
p
(
y
=
0
�O
x
)
=
1
e
w
T
x
+
b
+
1
p(y=0|x) = \frac{1 }{e^{ \boldsymbol{w^{T}}\boldsymbol{x}+b}+1 }
p(y=0�Ox)=ewTx+b+11?
�������:
p
1
(
x
^
;
��
)
=
e
��
T
x
^
e
��
T
x
^
+
1
p_{1}(\boldsymbol{\widehat{x};\beta}) =\frac{e^{\beta^{T}\widehat{x}} }{e^{\beta^{T}\widehat{x}}+1 }
p1?(x
;��)=e��Tx
+1e��Tx
?
��
p
0
(
x
^
;
��
)
=
1
e
��
T
x
^
+
1
p_{0}(\boldsymbol{\widehat{x};\beta}) =\frac{1}{e^{\beta^{T}\widehat{x}}+1 }
p0?(x
;��)=e��Tx
+11?
Ȼ��,��������ʽ�Ӵ��뵽��Ȼ����:
p
(
y
i
�O
x
i
;
w
,
b
)
=
y
i
e
��
T
x
^
i
e
��
T
x
^
i
+
1
+
(
1
?
y
i
)
1
e
��
T
x
^
i
+
1
p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) = y_{i}\frac{e^{\beta^{T}\widehat{x}_{i}} }{e^{\beta^{T}\widehat{x}_{i}}+1 }+(1-y_{i})\frac{1}{e^{\beta^{T}\widehat{x}_{i}}+1 }
p(yi?�Oxi?;w,b)=yi?e��Tx
i?+1e��Tx
i??+(1?yi?)e��Tx
i?+11?
����ȡln,��
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
=
ln
?
[
y
i
e
��
T
x
^
i
e
��
T
x
^
i
+
1
+
(
1
?
y
i
)
1
e
��
T
x
^
i
+
1
]
\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) =\ln[ y_{i}\frac{e^{\beta^{T}\widehat{x}_{i}} }{e^{\beta^{T}\widehat{x}_{i}}+1 }+(1-y_{i})\frac{1}{e^{\beta^{T}\widehat{x}_{i}}+1 }]
lnp(yi?�Oxi?;w,b)=ln[yi?e��Tx
i?+1e��Tx
i??+(1?yi?)e��Tx
i?+11?]
��yi = 1ʱ:
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
=
ln
?
e
��
T
x
^
i
e
��
T
x
^
i
+
1
=
��
T
x
^
i
?
ln
?
(
e
��
T
x
^
i
+
1
)
\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) =\ln \frac{e^{\beta^{T}\widehat{x}_{i}} }{e^{\beta^{T}\widehat{x}_{i}}+1 }= \beta^{T}\widehat{x}_{i}-\ln(e^{\beta^{T}\widehat{x}_{i}}+1)
lnp(yi?�Oxi?;w,b)=lne��Tx
i?+1e��Tx
i??=��Tx
i??ln(e��Tx
i?+1)
��yi = 0ʱ:
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
=
ln
?
1
e
��
T
x
^
i
+
1
=
?
ln
?
(
e
��
T
x
^
i
+
1
)
\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) =\ln \frac{1}{e^{\beta^{T}\widehat{x}_{i}}+1 }= -\ln(e^{\beta^{T}\widehat{x}_{i}}+1)
lnp(yi?�Oxi?;w,b)=lne��Tx
i?+11?=?ln(e��Tx
i?+1)
����������,���Կ���,��������
��
T
x
^
i
\beta^{T}\widehat{x}_{i}
��Tx
i?��,���Կ����ڸ���ǰ�����yi,�õ�����Ϊ:
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
=
y
i
��
T
x
^
i
?
ln
?
(
e
��
T
x
^
i
+
1
)
\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b) = y_{i}\beta^{T}\widehat{x}_{i}-\ln(e^{\beta^{T}\widehat{x}_{i}}+1)
lnp(yi?�Oxi?;w,b)=yi?��Tx
i??ln(e��Tx
i?+1)
���Կ���,��yi=1ʱ,��һ����Ч,��yi=0ʱ,��һ����Ч��
Ȼ��,���ǽ������Ƶ���
ln
?
p
(
y
i
�O
x
i
;
w
,
b
)
\ln p(y_{i}|\boldsymbol{x_{i}};\boldsymbol{w},b)
lnp(yi?�Oxi?;w,b)�Ż�������Ȼ������(Ϊ������,�ظ�ͼ�����)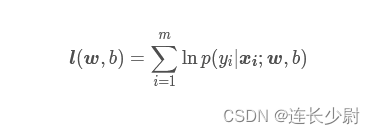
���Եõ�:
l
(
��
)
=
��
i
=
1
m
[
y
i
��
T
x
^
i
?
ln
?
(
e
��
T
x
^
i
+
1
)
]
\boldsymbol{l}(\boldsymbol{\beta}) = \sum_{i=1}^{m}[y_{i}\beta^{T}\widehat{x}_{i}-\ln(e^{\beta^{T}\widehat{x}_{i}}+1)]
l(��)=i=1��m?[yi?��Tx
i??ln(e��Tx
i?+1)]
����,��������˶�����Ȼ���̵Ĺ���,���ռ�����Ȼ��������,������ֻ��Ҫ���������Ȼ��
l
(
��
)
\boldsymbol{l}(\boldsymbol{\beta})
l(��),�Ϳɵõ�w��b�Ĺ���ֵ������,���ڶԻ���ѧϰ��һ��ϰ���ڡ���С����(������С����ʧ����),�����������ǽ�
l
(
��
)
\boldsymbol{l}(\boldsymbol{\beta})
l(��)ȡ���෴���õ�
l
��
(
��
)
\boldsymbol{l{}'}(\boldsymbol{\beta})
l��(��):
l
��
(
��
)
=
��
i
=
1
m
[
?
y
i
��
T
x
^
i
+
ln
?
(
e
��
T
x
^
i
+
1
)
]
\boldsymbol{l{}'}(\boldsymbol{\beta}) = \sum_{i=1}^{m}[-y_{i}\beta^{T}\widehat{x}_{i}+\ln(e^{\beta^{T}\widehat{x}_{i}}+1)]
l��(��)=i=1��m?[?yi?��Tx
i?+ln(e��Tx
i?+1)]
���
l
(
��
)
\boldsymbol{l}(\boldsymbol{\beta})
l(��)��ʵ�͵�ͬ����С��
l
��
(
��
)
\boldsymbol{l{}'}(\boldsymbol{\beta})
l��(��)��
����,�Ϳ���ʹ���ݶ��½���,�ҵ�
l
��
(
��
)
\boldsymbol{l{}'}(\boldsymbol{\beta})
l��(��)�ļ�С�㡣�����ݶ��½����ܽ���������һ����ʽ:
��
t
+
1
=
��
t
?
s
?
l
��
(
��
)
?
��
\boldsymbol{\beta} ^{t+1}=\boldsymbol{\beta} ^{t}-s\frac{\partial \boldsymbol{l{}'}(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}}
��t+1=��t?s?��?l��(��)?
����
?
l
��
(
��
)
?
��
\frac{\partial \boldsymbol{l{}'}(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}}
?��?l��(��)?Ϊ:
?
l
��
(
��
)
?
��
=
?
��
i
=
1
m
x
^
i
(
y
i
?
p
1
(
x
^
i
;
��
)
)
\frac{\partial \boldsymbol{l{}'}(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}}=-\sum_{i=1}^{m}\boldsymbol{\widehat{x}_{i}}(y_{i}-p_{1}(\boldsymbol{\widehat{x}_{i}};\boldsymbol{\beta}))
?��?l��(��)?=?i=1��m?x
i?(yi??p1?(x
i?;��))
s�Dz���,
?
l
��
(
��
)
?
��
\frac{\partial \boldsymbol{l{}'}(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}}
?��?l��(��)?Ϊ�ݶ�,ÿ���½������ݶȷ����ƶ�s��λ,�Ϳ�������С�㡣�ҵ���С���,��Ӧ��
��
\beta
������ѵ�������
4.����ʵ��(python)
import numpy as np
import openpyxl
import matplotlib.pyplot as plt
from matplotlib import cm
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def init_xy():
sheet1 = openpyxl.load_workbook('./xigua3.0.xlsx')['Sheet1']
x = np.zeros((2,17))
y = np.zeros((1,17))
for i in range(17):
x[0][i] = sheet1[chr(ord('A')+i)+'1'].value
for i in range(17):
x[1][i] = sheet1[chr(ord('A')+i)+'2'].value
for i in range(17):
y[0][i] = sheet1[chr(ord('A')+i)+'3'].value
return x.T, y.T
def function_p1(x_hat, b):
a = np.math.exp(np.dot(np.transpose(b), x_hat))
return a / (1+a)
def function_p2(x, b):
return 1 - function_p1(x, b)
def train():
x,y = init_xy()
b = np.ones((3,1))
dl_sub = 0
train_n = 2000
step_size = 0.1
for step in range(train_n):
dl = 0
for i in range(17):
x_t = x[i]
x_hat = np.append(x_t, 1)
x_hat = x_hat.reshape(3,1)
dl_sub = np.dot(x_hat, y[i][0] - function_p1(x_hat, b))
dl += dl_sub
b = b + step_size * dl
return b
def test(x, y, b):
right = 0
for i in range(17):
x_hat = np.append(x[i], 1)
y_pre = sigmoid(np.dot(b.T, x_hat))
if (y_pre >= 0.5 and y[i] == 1) or (y_pre < 0.5 and y[i] == 0):
right += 1
print("��ȷ��Ϊ:", right/17)
b = train()
x,y = init_xy()
test(x, y, b)
5.����