CIFAR-100���ݼ��ڼ���CNN(LeNet-5��)�ͼ���DNN��Ч���Ա�
��Ŀ˵��
����ĿΪ�γ���ҵ,ʵ����̵�û�зdz��Ͻ�,����������ָ��,�ἰʱ����!
ժҪ
���Ķ���ͬ���ݼ�ʹ�ü�������������;������������̽��,�ֱ�ʹ��3�����������LeNet-5���İ汾(ͨ������)����ѵ����������������з�����ͨ��ʵ��̽�������������������������ͬ���ݼ��µ�ѵ��Ч�������,����̽��ѵ��,����CNN��DNNģ���ڸ����ݼ������ü����塣
�ؼ���
������,CIFAR-100,CNN,DNN
����
���˹����ܼ���ʢ�еĽ���,��cv(������Ӿ�)�������Ч�����ѵ�ģ�ͷ�ӻԾ,�ع˷�չ��ʷ���������������Ų��ɺ��ӵ����������,Ϊ��̽����ͬ���ݼ��ڼ����������������������֮���Ч������,��������ʵ��,ͨ�����ݼ�����,���ݴ���,ģ����,ģ��ѵ��,ѵ��������ӻ��ȷ�ʽ������Ч������չʾ,ͨLoss��ACC��ģ��Ч�����м����жϡ�
import paddle
import numpy as np
import matplotlib.pyplot as plt
import paddle.nn as nn
from paddle.vision.datasets import Cifar100
from paddle.vision.transforms import Normalize
paddle.__version__
'2.3.0'
����˵��
CIFAR-100 ���ݼ��� 100 ������ 60000 �� 32x32 ��ɫͼ�����,ÿ�������� 6000 ��ͼ���� 500 ��ѵ��ͼ��� 100 ������ͼ��CIFAR-100 �е� 100 �����Ϊ 20 �����ࡣÿ��ͼ����һ������ϸ����ǩ(����������)��һ�������ԡ���ǩ(�������ij���)��
| ���� | �γ� |
|---|---|
| ˮ�����鶯�� | ����, ����, ˮ̡, ����, ���� |
| �� | ������, ��Ŀ��, ����, ����, ���� |
| ���� | ��������ڡ�õ�塢���տ��������� |
| ʳƷ���� | ƿ���롢�ޡ������� |
| ˮ�����߲� | ƻ����Ģ�������ӡ��桢�� |
| ���õ��� | ʱ��, ���Լ���, ��, �绰, ���� |
| �ҾӼҾ� | ��, ����, ɳ��, ����, �¹� |
| ���� | �۷�, �׳�, ����, ëë��, ��� |
| ����ʳ��� | ��, ��, ʨ��, ��, �� |
| �������컧����Ʒ | ��, �DZ�, ��, ·, Ħ���¥ |
| ������Ȼ���ⳡ�� | ��, ɭ��, ɽ, ƽԭ, �� |
| ������ʳ����Ͳ�ʳ���� | ����, ţ, ������, ����, ���� |
| ���Ͳ��鶯�� | ���ꡢ������������ܡ����� |
| ������������ | �з����Ϻ����ţ��֩�롢��� |
| ���� | ����, �к�, Ů��, ����, Ů�� |
| ����� | ����, ����, ����, ��, �� |
| С�Ͳ��鶯�� | ����, ����, ����, ����, ���� |
| ��ľ | ��ľ, ��ľ, ���, ����, ���� |
| ���� 1 | ���г�, ��������, Ħ�г�, Ƥ����, �� |
| ���� 2 | ��ݻ�, ���, �й�糵, ̹��, ������ |
�ο���ַ:https://www.cs.toronto.edu/~kriz/cifar.html
���ݵ���
# ����Ԥ��������
normalize = Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5],
data_format='HWC')
# ѵ��������֤������
train_cifar100 = Cifar100(mode='train', transform=normalize)
test_cifar100 = Cifar100(mode='test', transform=normalize)
�������ݲ���shape
���ݵ���״Ϊ(32,32,3)�����ͨ����ƽʱ����ʹ�õķ�ʽ��һ������ͨ��paddle.io.dataset���½��й���ʹ�����ݱ��(3,32,32)����ʽ
'''
�Զ������ݼ�
'''
from paddle.io import Dataset
class MyDataset(paddle.io.Dataset):
"""
����һ:�̳�paddle.io.Dataset��
"""
def __init__(self, data_):
"""
�����:ʵ�ֹ��캯��,�������ݼ���С
"""
super(MyDataset, self).__init__()
self.data = []
self.label = []
for i in range(len(data_)):
x = data_[i][0].transpose((2, 0, 1))
y = data_[i][1]
self.data.append(x)
self.label.append(np.array(y).astype('int64'))
def __getitem__(self, index):
"""
������:ʵ��__getitem__����,����ָ��indexʱ��λ�ȡ����,�����ص�������(ѵ������,��Ӧ�ı�ǩ)
"""
# ���ص�һ���ݺͱ�ǩ
data = self.data[index]
label = self.label[index]
# ע:���ر�ǩ����ʱ������int64
return data, np.array(label, dtype='int64')
def __len__(self):
"""
������:ʵ��__len__����,�������ݼ�����Ŀ
"""
# ������������
return len(self.data)
# ���Զ�������ݼ�
train_dataset = MyDataset(data_=train_cifar100)
eval_dataset = MyDataset(data_=test_cifar100)
print('=============train_dataset =============')
# ������ݼ�����״�ͱ�ǩ
print(train_dataset.__getitem__(1)[0].shape,train_dataset.__getitem__(1)[1])
# ������ݼ��ij���
print(train_dataset.__len__())
print('=============eval_dataset =============')
# ������ݼ�����״�ͱ�ǩ
for data, label in eval_dataset:
print(data.shape, label)
break
# ������ݼ��ij���
print(eval_dataset.__len__())
DNN����(���������)
DNN���ڵ�3��������,һ�������ϴ��������������������DNN��DNN��ʱҲ��������֪��(Multi-Layer perceptron,MLP)
DNN��һ����������硣������Ԫ�ֱ����ڲ�ͬ�IJ�,ÿ����Ԫ��ǰһ���������Ԫ������,�źŴ������������㵥����

��DNN����ͬ���λ�û���,DNN�ڲ������������Է�Ϊ����,�����,���ز�������,����ͼʾ��,һ����˵��һ���������,���һ���������,���м�IJ����������ز㡣
�����֮����ȫ���ӵ�,Ҳ����˵,��i�������һ����Ԫһ�����i+1�������һ����Ԫ��������ȻDNN�������ܸ���,���Ǵ�С�ľֲ�ģ����˵,���Ǻ�֪��һ��,��һ�����Թ�ϵ ����һ���������
����˵����һ�������������ز��������㹹�ɵļ��������硣���ز�������һ���̶��Ͼ���ģ�͵ĸ��ӶȺ�Ч����
DNNģ�͵Ĺ���
from paddle.nn import Linear
import paddle.nn.functional as F
import paddle
# ����DNN����
class MyDNN(paddle.nn.Layer):
def __init__(self):
super(MyDNN, self).__init__()
self.hidden1 = Linear(3*32*32, 2048) # ����㶨��
self.hidden2 = Linear(2048, 1024) # ���ز�1����
self.hidden3 = Linear(1024, 128) # ���ز�2����
self.hidden4 = Linear(128, 100) # ����㶨��
def forward(self, input):
# print(input.shape)
x = paddle.reshape(input, shape=[-1,3*32*32]) # ������ֱ
x = self.hidden1(x) # �����
x =F.relu(x) # �����
# print(x.shape)
x = self.hidden2(x) # ���ز�1
x = F.relu(x)
# print(x.shape)
x = self.hidden3(x) # ���ز�2
x = F.relu(x)
# print(x.shape)
x = self.hidden4(x) # �����
y = F.softmax(x)
# print(y.shape)
return y
model = MyDNN() # ����ʵ����
paddle.summary(model,(3,32,32)) # ����ṹ�鿴
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Linear-1 [[1, 3072]] [1, 2048] 6,293,504
Linear-2 [[1, 2048]] [1, 1024] 2,098,176
Linear-3 [[1, 1024]] [1, 128] 131,200
Linear-4 [[1, 128]] [1, 100] 12,900
===========================================================================
Total params: 8,535,780
Trainable params: 8,535,780
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.03
Params size (MB): 32.56
Estimated Total Size (MB): 32.60
---------------------------------------------------------------------------
{'total_params': 8535780, 'trainable_params': 8535780}
ʹ��DNNģ�Ͷ����ݽ���ѵ��
ͨ�������ģ�͵Ľṹ�鿴�����������,�����Ϊ(1, 3072)����(3, 32, 32)������ƽ�����ز�Ϊ��������Խṹ�������Ϊ100�����������㡣
����,ģ�ͽ���ѵ��,�˴�ʹ����Adam�Ż���,�ܹ������ݶȵ�һ�ع��ƺͶ��ع��ƶ�̬����ÿ��������ѧϰ�ʡ���������µļ��㹫ʽ����:

�����:Adam: A Method for Stochastic Optimization https://arxiv.org/abs/1412.6980
��ʧ����:ʹ�õ���CrossEntropyLoss,���ڼ�������input�ͱ�ǩlabel��Ľ�������ʧ ,������� LogSoftmax �� NLLLoss �ļ���,������ѵ��һ�� n ���������
����ָ��:ʹ�õ���Accuracy,���ڼ���ȷ�ʡ�
����ѵ������50��,����128,������������ѵ����
# ��Model��װģ��
model = paddle.Model(MyDNN())
# ������ʧ����
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))
# ѵ�����ӻ�VisualDL���ߵĻص�����
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# ����ģ��ȫ����ѵ��
model.fit(train_dataset, # ѵ�����ݼ�
eval_dataset, # �������ݼ�
epochs=50, # �ܵ�ѵ���ִ�
batch_size = 128, # ���μ������������С
shuffle=True, # �Ƿ����������
verbose=1, # ��־չʾ��ʽ
save_dir='./chk_points/', # �ֽε�ѵ��ģ�ʹ洢·��
callbacks=[visualdl]) # �ص�����ʹ��
# ����ģ��
model.save('model_save_dir')
ѵ�����ݿ��ӻ�
ͨ����ѵ�����ݽ��п��ӻ�չʾ���Եõ���������
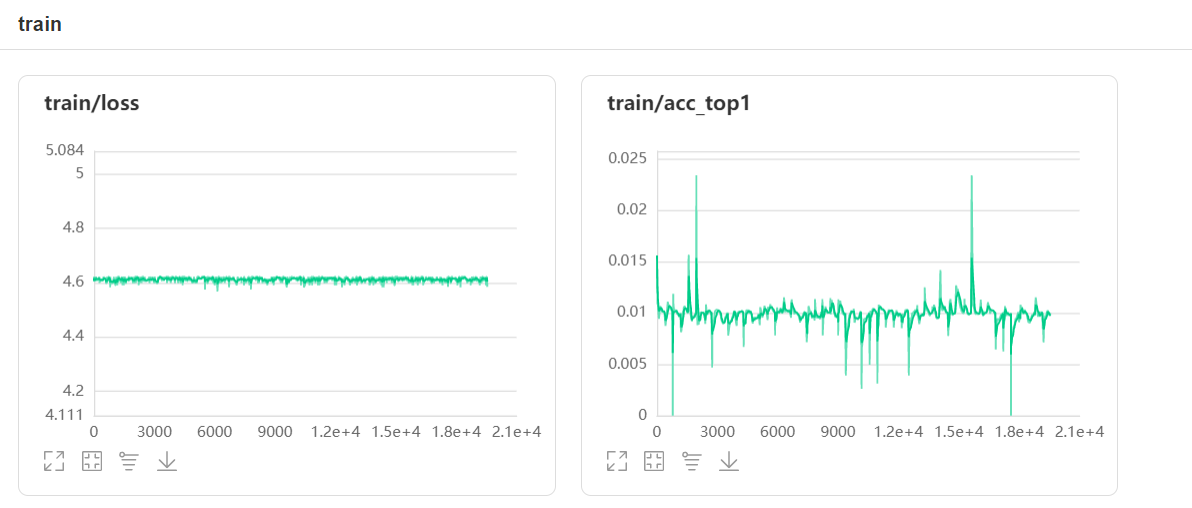

DNN������Ϣ
ͨ��ѵ�����ݿ��Կ��������Լ�����loss�Ƚ��ȶ�,acc����һ���IJ���,����lossֵƫ��,ACCƫ��,���Կ���Ч���ϲͨ��loss���ȶ����Կ�������һ���̶��ϸ�ģ���Ѿ��ﵽһ�ֱ��ͳ̶�,ģ���ӵĺ���Ȳ�����֧�ָ������ѵ����
CNN
CNN��һ��ͨ�����������ǰ��������,����������ѧ�ϵĸ���Ұ���������,����ƽ�Ʋ�����,ʹ�þ�����,����Ӧ���˾ֲ���Ϣ,������ƽ��ṹ��Ϣ��
ʹ�÷����㷨ѵ���Ķ�������繹���˳ɹ��Ļ����ݶȵ�ѧϰ����,�����ʵ�������ܹ�,�����ݶȵ�ѧϰ�㷨�����ںϳɸ��ӵľ�����,�þ�������Զ���д�ַ��ȸ�άģʽ���з���,��Ԥ�������١�����������ר��������ڴ��� 2D ��״�Ŀɱ���,���������ڵ�ʱ����������������(�ü���Ϊ1998��ļ���,�������³ɹ�)����Ҫʹ�õ���LeNet-5����д����ʶ��(http://yann.lecun.com/exdb/mnist/ )��Ŀ�ϵ�,�ڵ�ʱ���űȽϺõ�Ч����
LeNet-5
LeNet-5�ǻ�������������
�Ǵ�ԭʼ�źš�>���ֱ�Ե�ͷ���>���ϳ���>���ϳ����һ������
LeNet-5�������,��������������ƽ���ػ������,��������������Բ㻹��һ������㡣
������쳣�������ͼ��ԭ���ġ�
�ο���ַ:https://ieeexplore.ieee.org/document/726791
���ĵ�ַ(ֱ�ӿɶ�):https://arxiv.org/abs/1412.6980
[1] Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, ��Gradient-based learning applied to document recognition,�� in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
�������ػ��ͼ����˵��
����
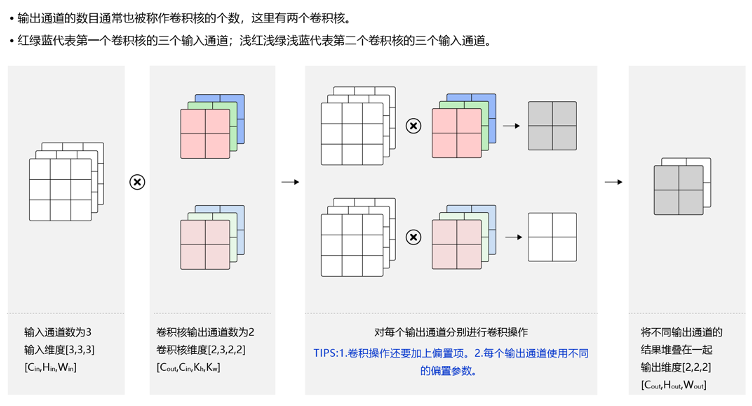
ÿ��������Ԫ�IJ�������ͨ�������㷨��ѻ��õ��ġ����������Ŀ������ȡ����IJ�ͬ����,��һ����������ֻ����ȡһЩ�ͼ����������Ե�������ͽǵȲ㼶,��������·�ܴӵͼ������е�����ȡ�����ӵ�������
-
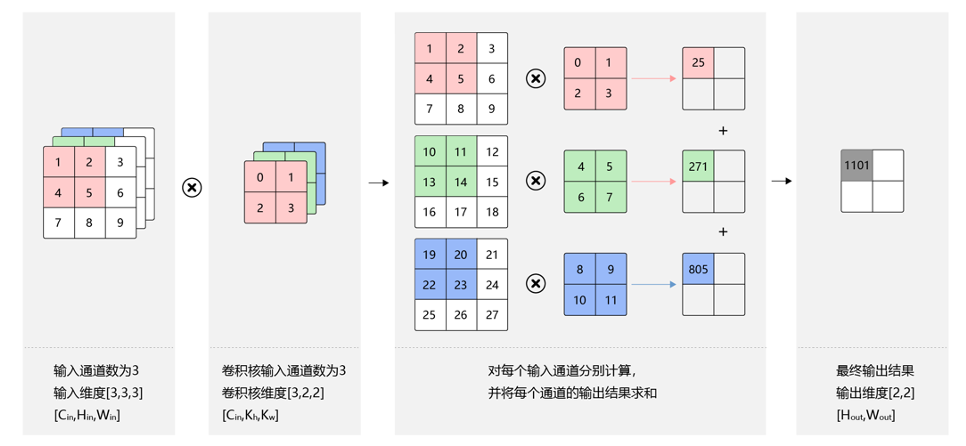
�������:
���������ں;�������ָ��������������Ȼ�������µľ��о���������������
-
������:
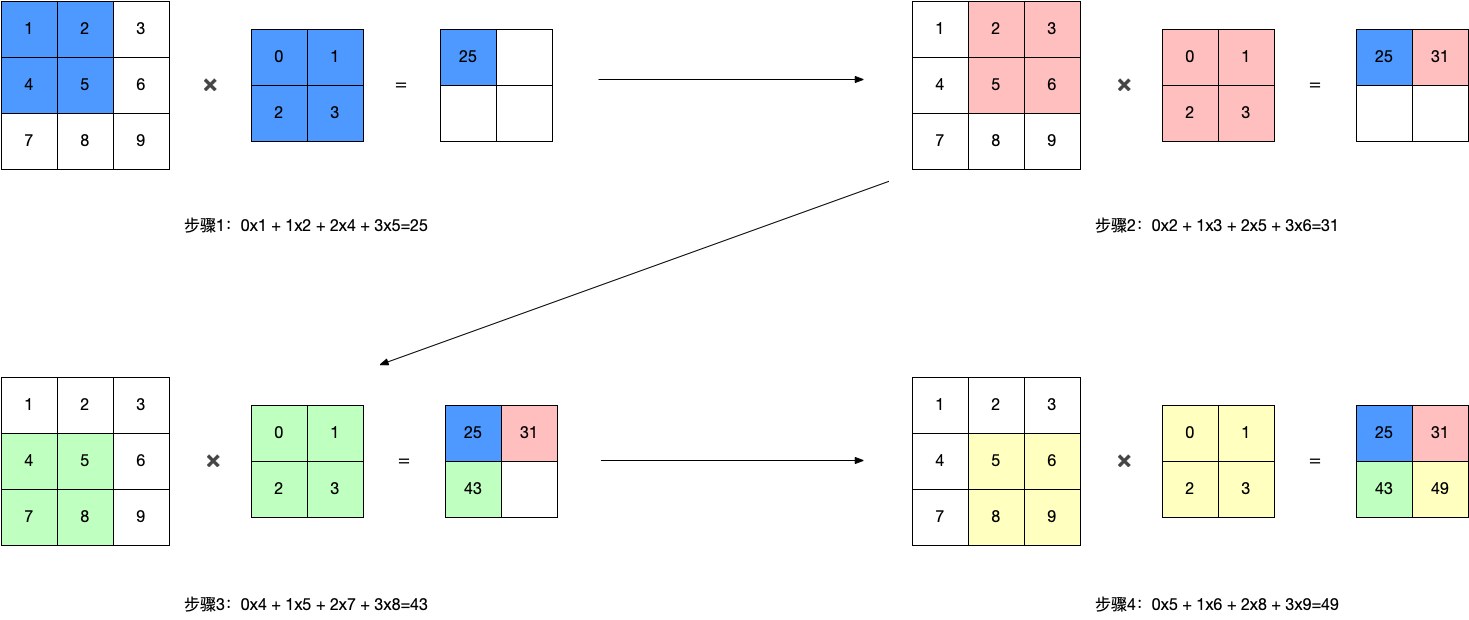
�͵��������ͬ,���������µ�����Ҳ�Ƕ�������
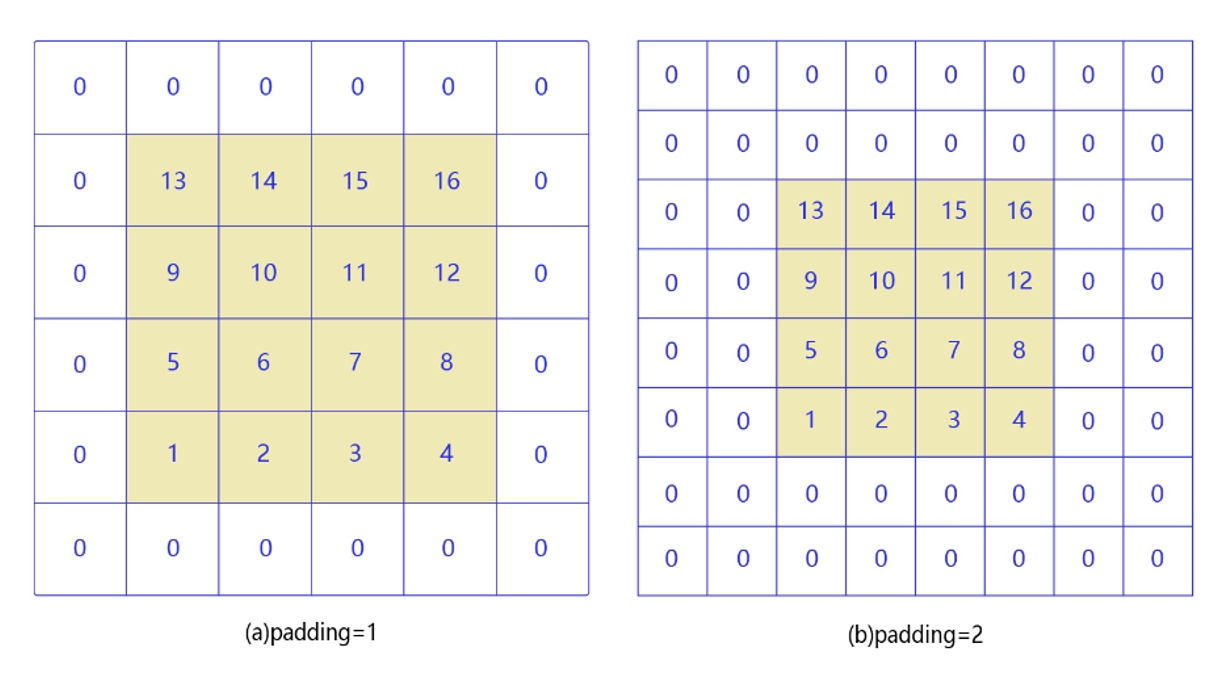
- ���(Padding)
�����Ե������,ֻ��һ�������������ʹ��,��Ϊ��λ�����3��3�������һ�ǡ�����������м�����ص�,�ͻ�������3��3��������֮�ص���
������Щ�ڽ�����߱�Ե��������ص�������в��ý���,��ζ���㶪����ͼ���Եλ�õ�������Ϣ��
��ô���ֵ�һ������취����������,��ԭͼ����Χ��0�������,�ڲ�Ӱ��������ȡ��ͬʱ,�����˶Ա�Ե��Ϣ��������ȡ��
����һ���ô���,����������������ʱ,ÿ����һ�ξ������ǵ�����ͼ���С�ͻ��С,�����ξ����������ǵ�ͼ������ر�С,���Dz�ϣ��ͼ���С�Ļ��Ϳ���ͨ����������
�ػ�
�ػ���ʹ��ijһλ�õ��������������ͳ���������������ڸ�λ�õ����,��ô��ǵ�����������������ƽ��ʱ,�����ػ�������Ĵ����������ܱ��ֲ��䡣����:��ʶ��һ��ͼ���Ƿ�������ʱ,������Ҫ֪�����������һֻ�۾�,�ұ�Ҳ��һֻ�۾�,������Ҫ֪���۾��ľ�ȷλ��,��ʱ��ͨ���ػ�ijһƬ��������ص����õ�����ͳ���������Եú����á����ڳػ�֮������ͼ���ø�С,����������ӵ���ȫ���Ӳ�,����Ч�ļ�С��Ԫ�ĸ���,��ʡ�洢�ռ䲢�����Ч�ʡ�
�ػ�������
�ػ���������ѡ�����Ϣ���˵Ĺ���,�����л���ʧһ������Ϣ,���ǻ�ͬʱ����ٲ����ͼ�����,��ģ��Ч���ͼ�������֮��Ѱ��ƽ��,���������ٶȵIJ������,�������ܻ���һЩ����ϵı仯,������Щ�����Ѿ���ʼ���û��߲��óػ��㡣
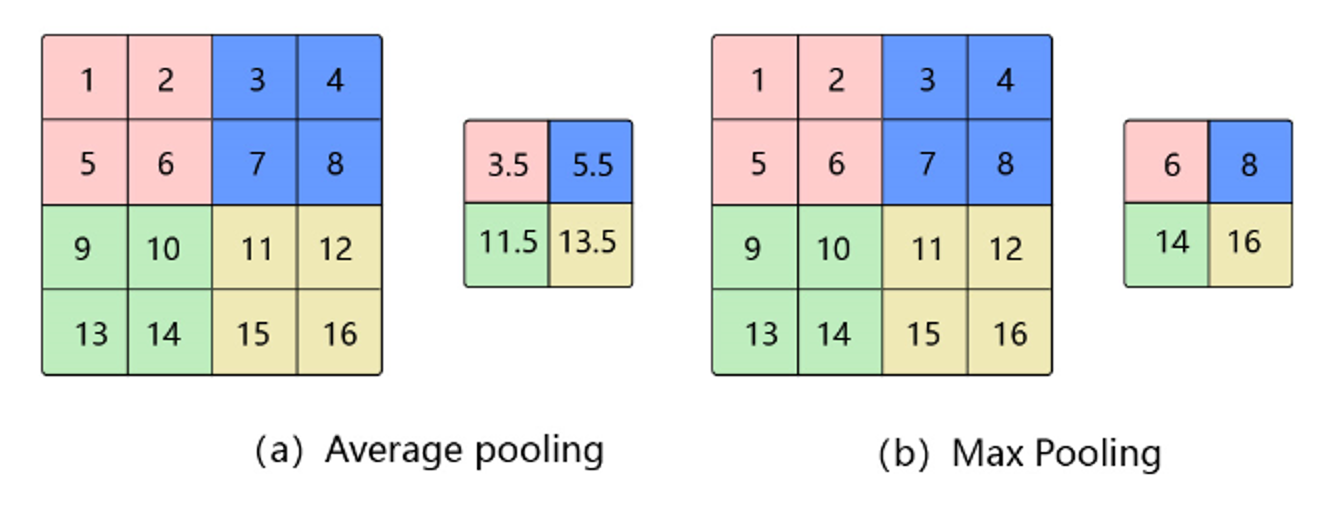
�ػ��IJ����;����˵Ĵ�С�й�,Ĭ�ϳ���Ϊ2
ƽ���ػ�(Avg Pooling)
����������������ƽ��
- ��ȱ��:�ܺܺõı�������,������ʹ��ͼƬ��ģ��
- ����:������ȡƽ��
- ����:����ֵ���������С��ƽ��,Ȼ��ÿ������λ��
���ػ�(Max Pooling)
��������������ȡ���
- ��ȱ��:�ܺܺõı���һЩ�ؼ�����������,���ڸ������ʹ��Max Pooling��������Avg Pooling
- ����:ȡ���������,����ס���ֵ������λ��,�Է��㷴��
- ����:������ֵ��䵽������,ֵ��������λ��,����λ�ò�0
�������Ĵ�С��ʾ
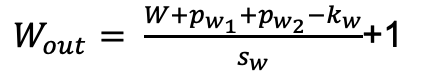
�����
- Sigmoid
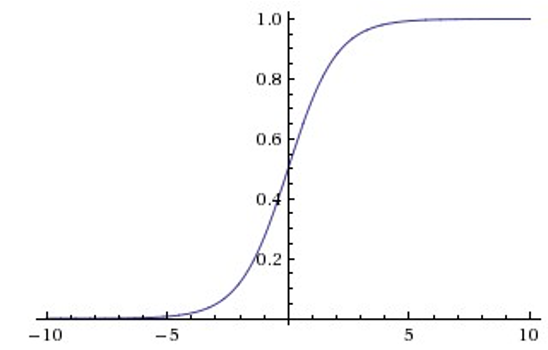
- Tanh
Sigmoid��Tanh������й�ͬ��ȱ��:����z�ܴ���Сʱ,�ݶȼ���Ϊ��,���ʹ���ݶ��½��Ż��㷨�������������
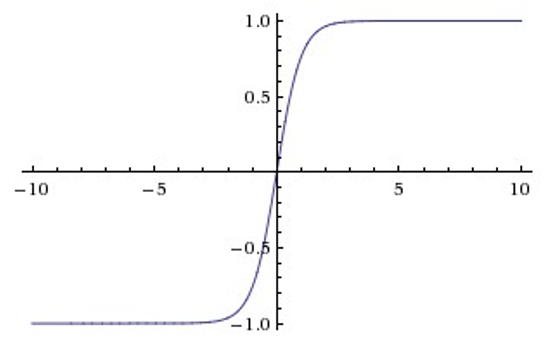
- ReLU
ReluĿǰ��ѡ�ñȽ϶�ļ����,����Ҳ����һЩȱ��,��zС��0ʱ,б�ʼ�����Ϊ0��
Ϊ�˽���������,����Ҳ�������Leaky Relu�����,����Ŀǰʹ�õIJ����ر�ࡣ
- ע�˴�ʹ�õ���Tanh�����
LeNet-5ģ�ʹ
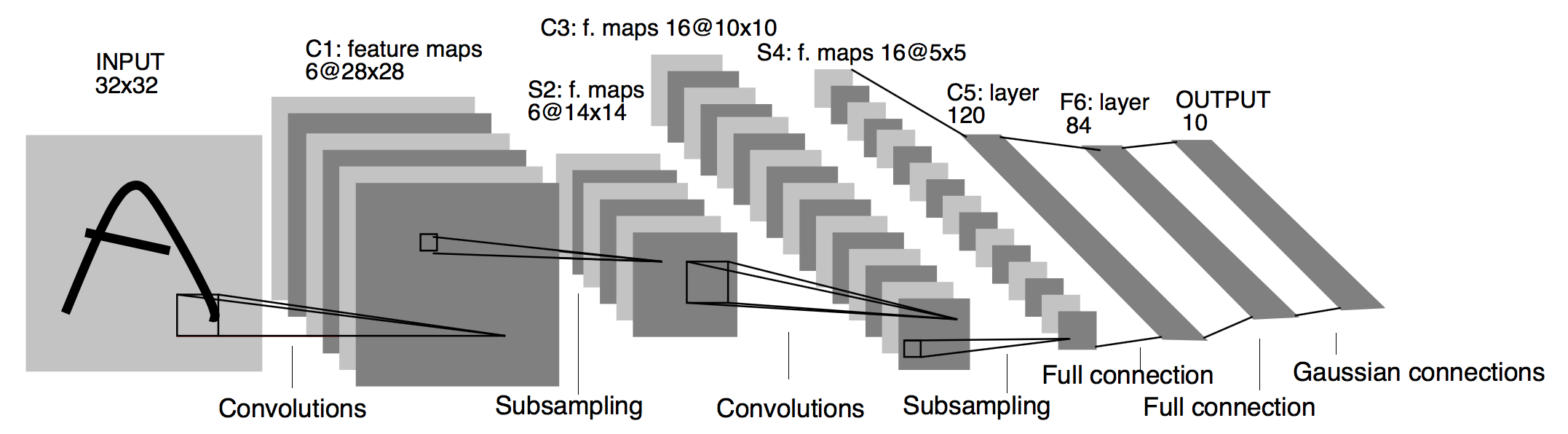
# LeNet-5
network = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # C1 ������
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S2 ƽ�ֳػ���
nn.Sigmoid(), # Sigmoid�����
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # C3 ������
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S4 ƽ���ػ���
nn.Sigmoid(), # Sigmoid�����
nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # C5 ������
nn.Tanh(),
nn.Flatten(),
nn.Linear(in_features=120, out_features=84), # F6 ȫ���Ӳ�
nn.Tanh(),
nn.Linear(in_features=84, out_features=10) # OUTPUT ȫ���Ӳ�
)
paddle.summary(network, (1, 1, 32, 32))
ģ����Ϊ3��
# LeNet-5��
network = nn.Sequential(
nn.Conv2D(in_channels=3, out_channels=6, kernel_size=5, stride=1, padding=0), # C1 ������
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S2 ƽ�ֳػ���
nn.Sigmoid(), # Sigmoid�����
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # C3 ������
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S4 ƽ���ػ���
nn.Sigmoid(), # Sigmoid�����
nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # C5 ������
nn.Tanh(),
nn.Flatten(),
nn.Linear(in_features=120, out_features=100), # F6 ȫ���Ӳ�
nn.Tanh(),
nn.Linear(in_features=100, out_features=100) # OUTPUT ȫ���Ӳ�
)
paddle.summary(network, (1, 3, 32, 32))
�������µĹ��캯�����и�д
��paddle.nn.Layer���м̳�,��������ǰ����������зֿ���д,���ӷ����������˽�Ͷ�����IJ鿴
class LeNet_G(nn.Layer):
"""
�̳�paddle.nn.Layer��������ṹ
"""
def __init__(self, num_classes=100):
"""
��ʼ������
"""
super(LeNet_G, self).__init__()
self.conv2D1 = nn.Conv2D(in_channels=3, out_channels=6, kernel_size=5, stride=1, padding=0) # C1 ������
self.conv2D2 = nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0) # C3 ������
self.conv2D3 = nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0) # C5 ������
self.avgpool2D1 = nn.AvgPool2D(kernel_size=2, stride=2) # S2ƽ���ػ�
self.avgpool2D2 = nn.AvgPool2D(kernel_size=2, stride=2) # S4 ƽ���ػ���
self.sigmoid = nn.Sigmoid() # �����
self.tanh = nn.Tanh()
self.linear1 = nn.Linear(in_features=120, out_features=100) # F6 ȫ���Ӳ�
self.linear2 = nn.Linear(in_features=100, out_features=num_classes) # OUTPUT ȫ���Ӳ�
def forward(self, inputs):
"""
ǰ�����
"""
inputs = paddle.to_tensor(inputs)
x = self.conv2D1(inputs)
x = self.tanh(x)
x = self.avgpool2D1(x)
x = self.sigmoid(x)
x = self.conv2D2(x)
x = self.tanh(x)
x = self.avgpool2D2(x)
x = self.sigmoid(x)
x = self.conv2D3(x)
x = self.tanh(x)
x = paddle.flatten(x, 1)
x = self.linear1(x)
x = self.tanh(x)
y = self.linear2(x)
return x
network_1 = LeNet_G()
paddle.summary(network_1, (1, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 32, 32]] [1, 6, 28, 28] 456
Tanh-1 [[1, 100]] [1, 100] 0
AvgPool2D-1 [[1, 6, 28, 28]] [1, 6, 14, 14] 0
Sigmoid-1 [[1, 16, 5, 5]] [1, 16, 5, 5] 0
Conv2D-2 [[1, 6, 14, 14]] [1, 16, 10, 10] 2,416
AvgPool2D-2 [[1, 16, 10, 10]] [1, 16, 5, 5] 0
Conv2D-3 [[1, 16, 5, 5]] [1, 120, 1, 1] 48,120
Linear-1 [[1, 120]] [1, 100] 12,100
Linear-2 [[1, 100]] [1, 100] 10,100
===========================================================================
Total params: 73,192
Trainable params: 73,192
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.07
Params size (MB): 0.28
Estimated Total Size (MB): 0.36
---------------------------------------------------------------------------
{'total_params': 73192, 'trainable_params': 73192}
����ģ�ͽ���ѵ��
# ��Model��װģ��
model = paddle.Model(network_1)
# ������ʧ����
model.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# ѵ�����ӻ�VisualDL���ߵĻص�����
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# ����ģ��ȫ����ѵ��
model.fit(train_dataset, # ѵ�����ݼ�
eval_dataset, # �������ݼ�
epochs=50, # �ܵ�ѵ���ִ�
batch_size = 256, # ���μ������������С
shuffle=True, # �Ƿ����������
verbose=1, # ��־չʾ��ʽ
save_dir='./CNN_points/', # �ֽε�ѵ��ģ�ʹ洢·��
callbacks=[visualdl]) # �ص�����ʹ��
# ����ģ��
shuffle=True, # �Ƿ����������
verbose=1, # ��־չʾ��ʽ
save_dir='./CNN_points/', # �ֽε�ѵ��ģ�ʹ洢·��
callbacks=[visualdl]) # �ص�����ʹ��
# ����ģ��
model.save('cnn_model_save_dir')
ѵ�����ݿ��ӻ�

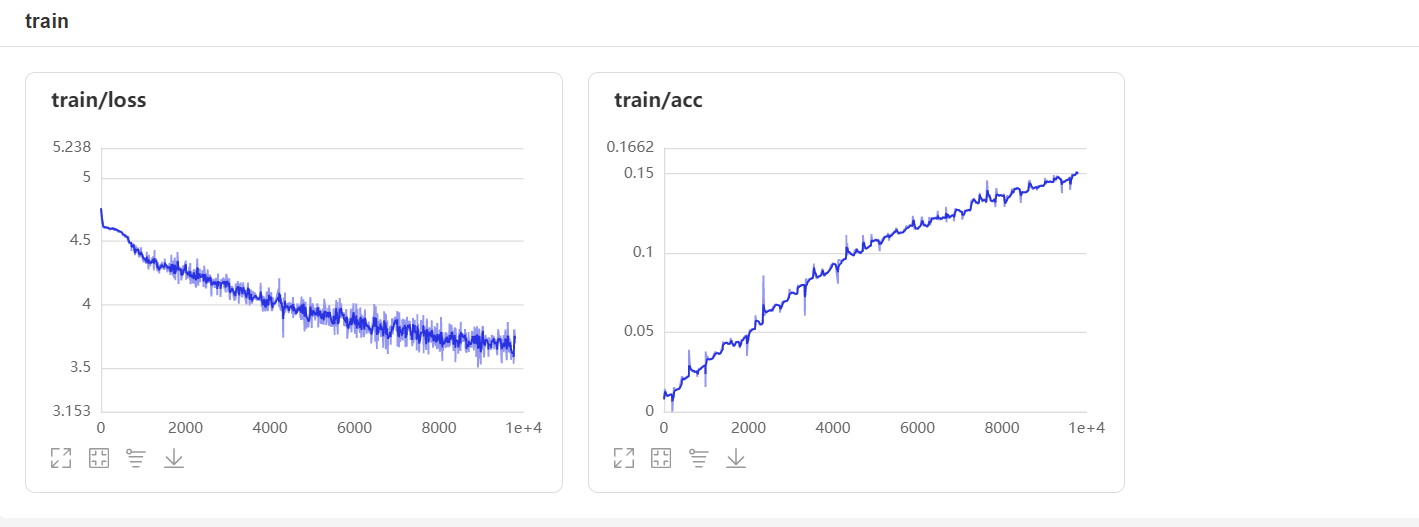
CNNѵ����Ϣ
ͨ��ѵ�����Ͳ��Լ��������Կ���loss���ڲ����½���״̬,���Կ�����ѧϰ���Ǿ��г�Ч��,ͨ��ACC������Ҳ����֤��ѵ���Ľ�����г�Ч�ġ����Ǿ�ѵ������������,Ч������,��Ҫԭ����ܻ������¼�������:
1����������϶�,���ǵ��������������������㹻
2��ģ�ͽ�Ϊ��,���ӵĺ���ȶ�����
3��ѵ������,ѧϰ�ʵȲ��������Խ��������͵���
�ڵ�ǰ����¿��Կ�����ģ������һ��Ч����,�����ڵ�ǰ�IJ�����������Ч��������,���нϴ�������ռ䡣
�ܽ�
ͨ�������������������ͼ��ķ���������,������Ч��û�мľ�����,���Ҽ��������������ռ��Ѿ�û����,���K��,ֻ�ܹ�ͨ����������������ķ�ʽ����,����ͬ������ѵ����,�������绹�нϴ�������ռ䡣��һ���̶��Ͽ��Եõ������ڶ�ͼ��������Ŀ�ϼ���������Ч��û�мľ�����,������50�ֵ�һ��ѵ��������,�����������Ѿ��ﵽ��ѧϰ��ֵ,�����ռ�С,���ľ��������ڲ��ı����縴�ӵĺ���ȵ�ǰ����,���нϴ�������ռ�,����:����ѵ������,��ѧϰ�ʵȲ���,���нϴ������ռ䡣
ͨ����ʵ��һ���̶����˽��˼�DNN����(3��)��CNN����(���ε�LeNet-5����,�ij���3ͨ��)��ѧϰ��Ϊ:0.001,��ʧ����Ϊ������(cross entropy)(CrossEntropyLoss),����ָ��ΪAccuracy��ǰ����,��ͼ����з��ദ��(CV��������),ͨ��50�ֵ�ѵ���õ���Ч��,ͨ��Ч���ó�����,����CNN�ڶ�ͼ����������ϵ�Ч�����ڼ���DNN,���ڸ�������CNN���н�һ��ѧϰ���Ż��Ŀռ䡣
�����������ڶ�ͼ���������Ϣ��ȡ�Ͼ��в���ĥ�������,���ڽ�Щ��ĸ����о��ɹ���Ҳ����֤����������������Ч�ġ�
�����
����:����
����:��ѧpython,���ڻ켣��paddle����,ϣ���ʹ��һ��ӻ�������,һ��ѧϰPaddle
csdn��ַ:https://blog.csdn.net/weixin_45623093/article/list/3
����AI Studio�ϻ������ȼ�,����10������,������ѽ~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/284366
��˵�еķɽ�������˴�����,������һ��Ŭ��!
��ס:�����Ʒ���Ǿ�Ʒ (��Ҫ��ϵ��)