Multi-Label Classification
首先分清一下multiclass和multilabel:
- 多类分类(Multiclass classification): 表示分类任务中有多个类别, 且假设每个样本都被设置了一个且仅有一个标签。比如从100个分类中击中一个。
- 多标签分类(Multilabel classification): 给每个样本一系列的目标标签,即表示的是样本各属性而不是相互排斥的。比如图片中有很多的概念如天空海洋人等等,需要预测出一个概念集合。
Challenge
多标签任务的难度主要集中在以下问题:
- 标签数量较大且基本会呈现长尾形态。
- 往往类标之间相互依赖并不独立。
- absence标签占比较高,即标注的标签并不能完美覆盖所有概念面。
- 标签往往较短语义少,理解困难。
Solution
现有的方法应对multi的预测主要有2大路线:
- 改造数据适应算法:将多个类别合并成单个类别。
- 改造算法适应数据:控制激活函数阈值得到结果。
而一般研究最多的应对relation会有3种策略:
一阶策略:忽略和其它标签的相关性,比如把多标签分解成多个独立的二分类问题。
二阶策略:考虑标签之间的成对关联,比如为相关标签和不相关标签排序。
高阶策略:考虑多个标签之间的关联,比如对每个标签考虑所有其它标签的影响。
Densenet

它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
DenseBlock
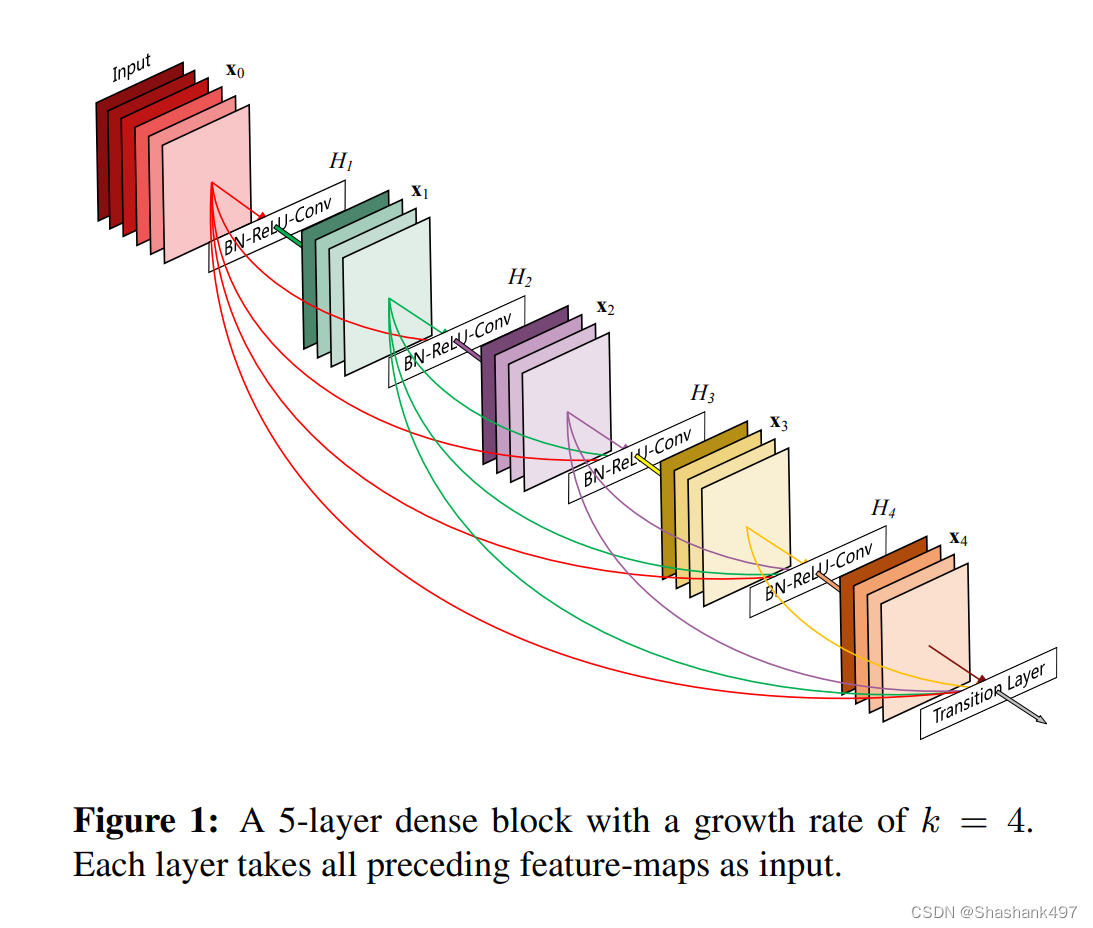
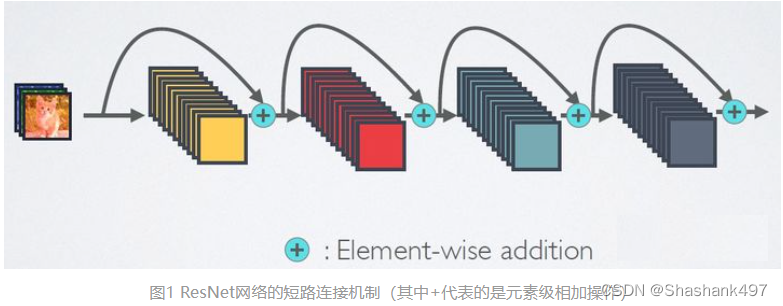
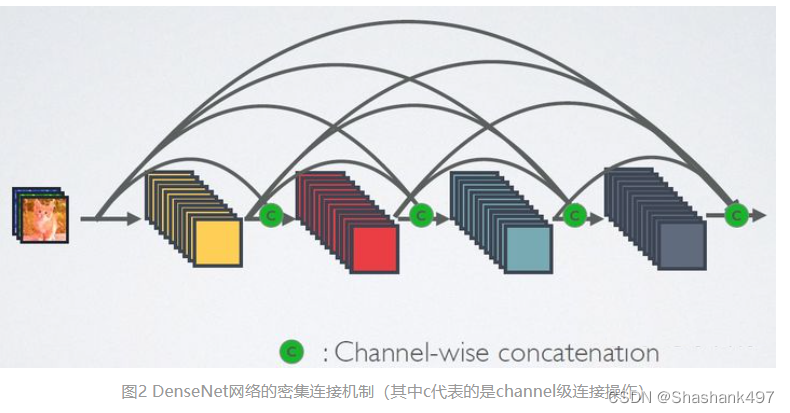
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L 层的网络,包含个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。

整体网络结构
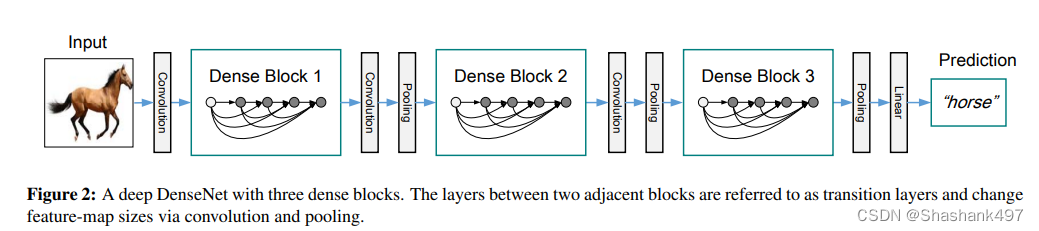
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。上图给出了DenseNet的网络结构,它共包含3个DenseBlock,各个DenseBlock之间通过Transition连接在一起。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。
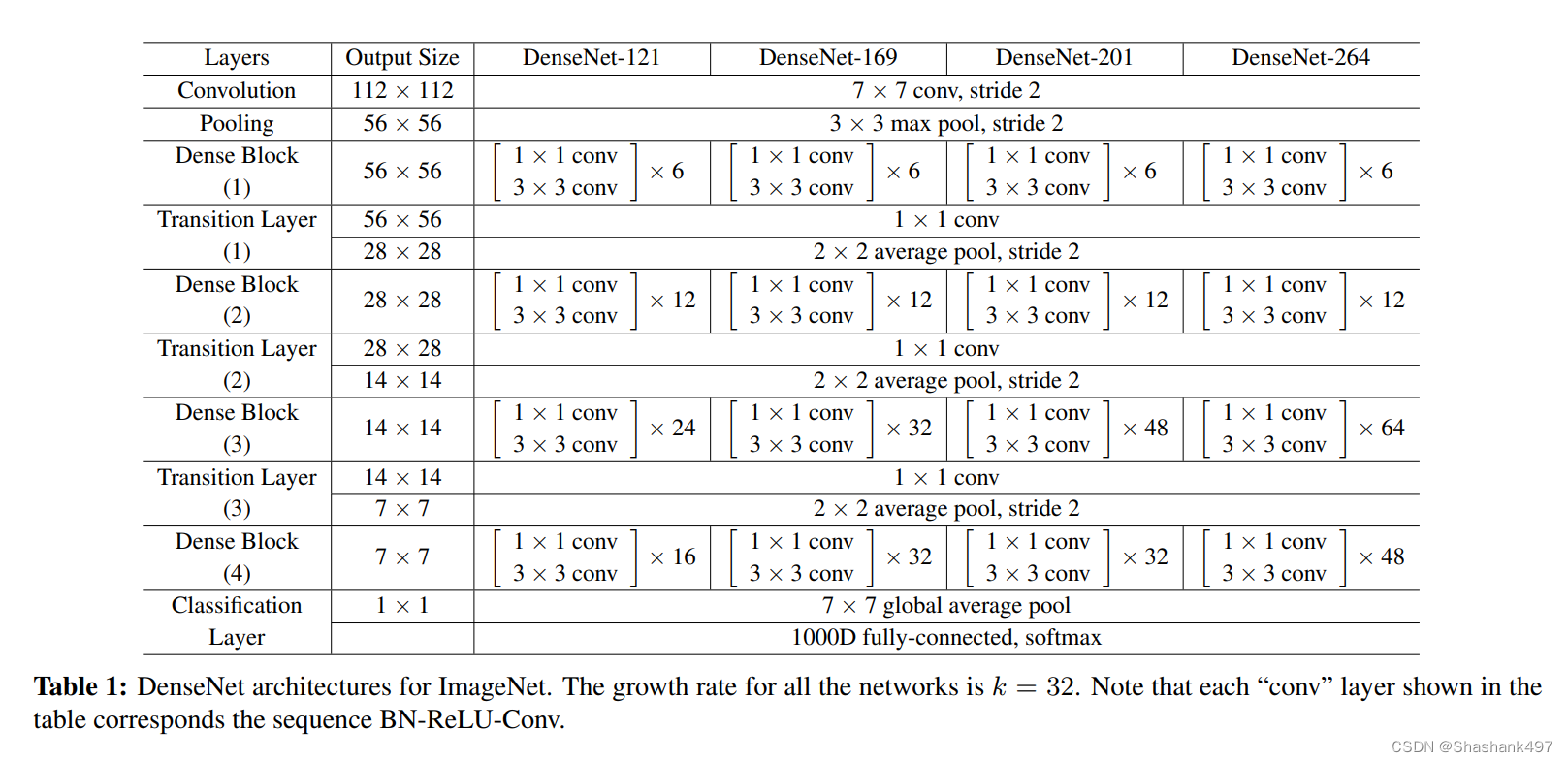
原论文实验结果
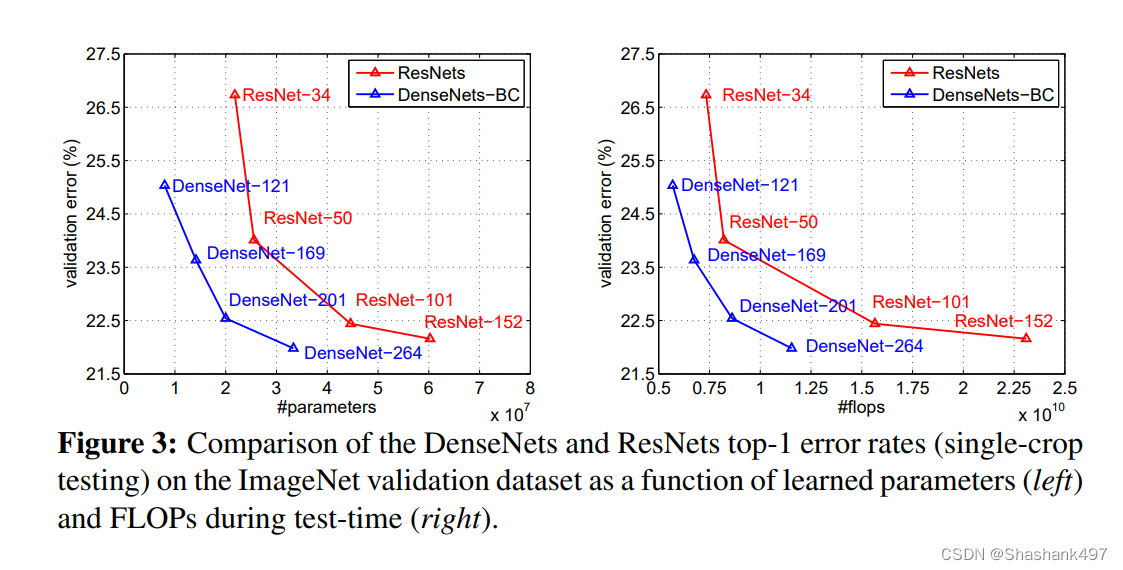
综合来看,DenseNet的优势主要体现在以下几个方面:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
服装多标签分类小实验
数据划分
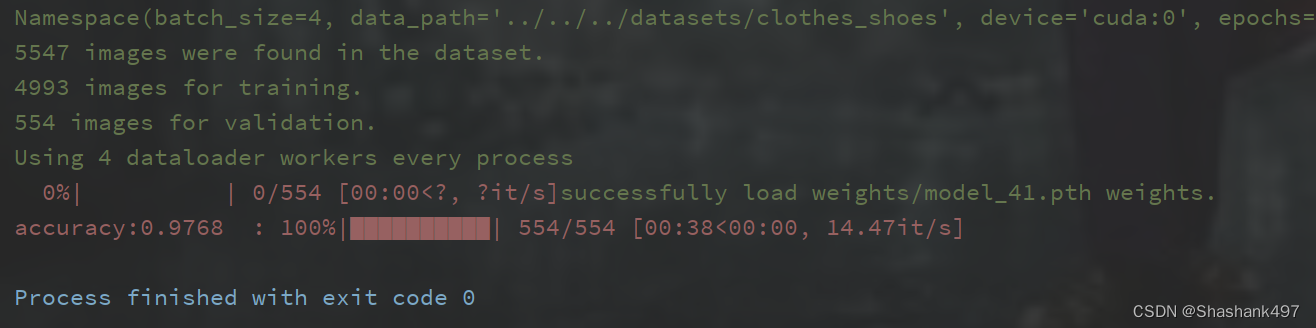
总数据量:5547
训练(4993):测试(554) = 9 :1
def read_split_data(root: str, test_rate: float = 0.1):
random.seed(0) # 保证随机结果可复现
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 拿到所有类别
class_ = set()
for cla in os.listdir(root):
class_.add(cla.split('_')[0])
class_.add(cla.split('_')[1])
class_ = list(class_)
class_.sort()
# 建立类别索引并存储
class_indices = dict((k, v) for v, k in enumerate(class_))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 读取所有图像路径和对应类别索引
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
# onehot编码形式表示出每张图像的label
images_path_and_onehot = {}
for dir_ in os.listdir(root):
for img_name in os.listdir(os.path.join(root, dir_)):
image_path = os.path.join(root, dir_, img_name)
onehot_class = [0] * 9
# print(str(image_path), str(image_path).split('\\'))
class0, class1 = str(image_path).split('\\')[-2].split('_')[0], image_path.split('\\')[-2].split('_')[1]
idx0, idx1 = class_indices[class0], class_indices[class1]
onehot_class[idx0], onehot_class[idx1] = 1, 1
images_path_and_onehot[image_path] = onehot_class
# 随机抽取相应比例的数据作为测试集
test_path = random.sample(list(images_path_and_onehot), k=int(len(list(images_path_and_onehot)) * test_rate))
# 分别存储训练和测试的图像路径及其对应onehot标签
for image_path in images_path_and_onehot.keys():
if image_path in test_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(image_path)
val_images_label.append(images_path_and_onehot[image_path])
else: # 否则存入训练集
train_images_path.append(image_path)
train_images_label.append(images_path_and_onehot[image_path])
print("{} images were found in the dataset.".format(len(images_path_and_onehot.keys())))
print("{} images for training.".format(len(train_images_path)))
print("{} images for validation.".format(len(val_images_path)))
return train_images_path, train_images_label, val_images_path, val_images_label
模型
- 使用densenet121网络,
- loss函数:二值交叉熵
- pretrain:imagenet 1000k
- lr: 0.0001
- epoches: 50(实际跑42epoch就收敛了)
- scheduler:余弦衰减
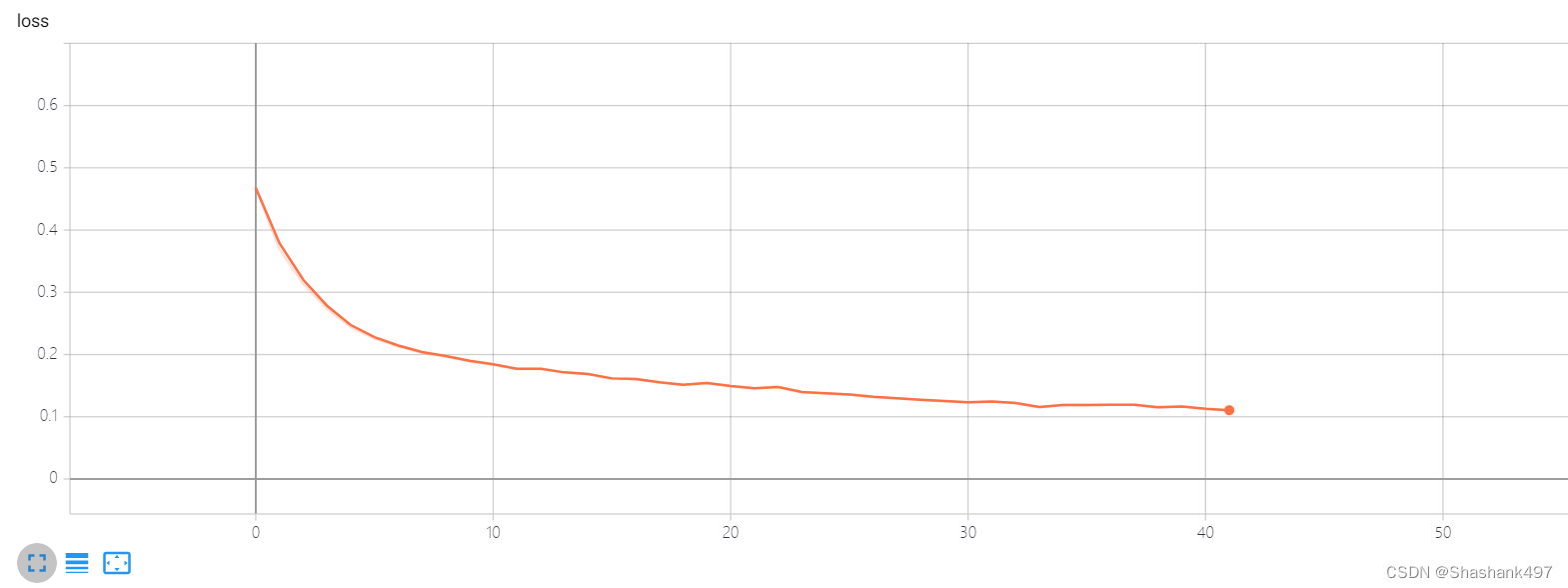
loss
结果评估
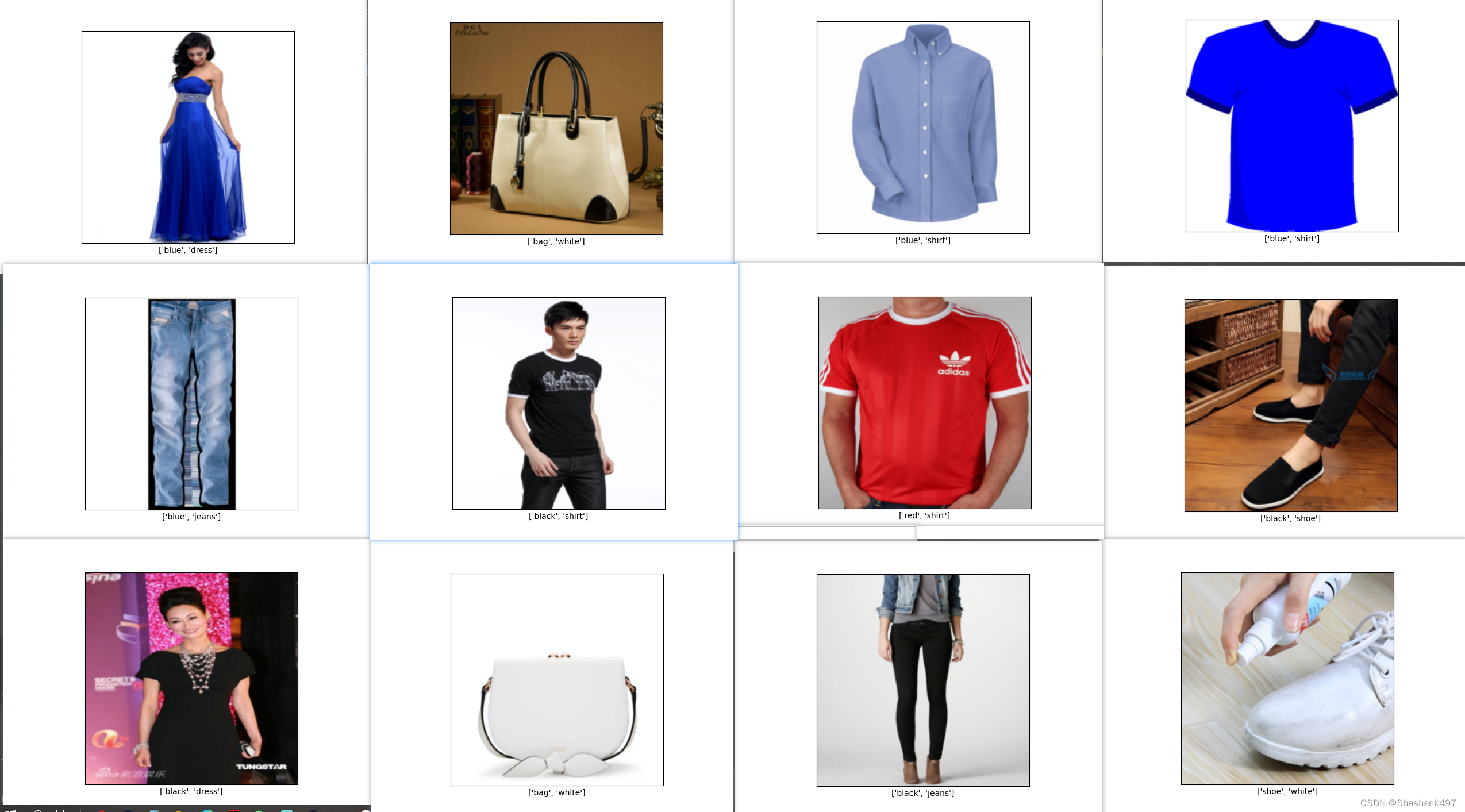
部分测试图像预测可视化:
【参考】
https://zhuanlan.zhihu.com/p/37189203
https://nakaizura.blog.csdn.net/article/details/114753747?spm=1001.2014.3001.5506