任务描述
本关任务:填写python代码,完成fit与predict函数,分别实现模型的训练与预测。
相关知识
为了完成本关任务,你需要掌握:
- 朴素贝叶斯分类算法的预测流程
- 朴素贝叶斯分类算法的训练流程
引例
在炎热的夏天你可能需要买一个大西瓜来解暑,但虽然你的挑西瓜的经验很老道,但还是会有挑错的时候。尽管如此,你可能还是更愿意相信自己经验。假设现在在你面前有一个纹路清晰,拍打西瓜后声音浑厚,按照你的经验来看这个西瓜是好瓜的概率有80%,不是好瓜的概率有20%。那么在这个时候你下意识会认为这个西瓜是好瓜,因为它是好瓜的概率大于不是好瓜的概率。
朴素贝叶斯分类算法的预测流程
朴素贝叶斯分类算法的预测思想和引例中挑西瓜的思想一样,会根据以往的经验计算出待预测数据分别为所有类别的概率,然后挑选其中概率最高的类别作为分类结果。
假如现在一个西瓜的数据如下表所示:
| 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|
| 绿 | 清脆 | 清晰 | ? |
若想使用朴素贝叶斯分类算法的思想,根据这条数据中颜色、声音和纹理这三个特征来推断是不是好瓜,我们需要计算出这个西瓜是好瓜的概率和不是好瓜的概率。
假设事件A1为好瓜,事件B为绿,事件C为清脆,事件D为清晰,则这个西瓜是好瓜的概率为P(A1|BCD)。根据上一关中最后提到的公式可知:
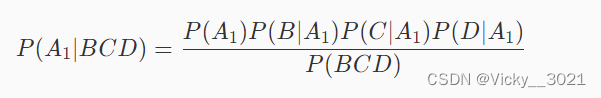
同样,假设事件A2为好瓜,事件B为绿,事件C为清脆,事件D为清晰,则这个西瓜不是好瓜的概率为P(A2|BCD)。根据上一关中最后提到的公式可知:
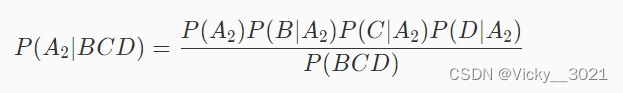
朴素贝叶斯分类算法的思想是取概率最大的类别作为预测结果,所以如果满足下面的式子,则认为这个西瓜是好瓜,否则就不是好瓜:
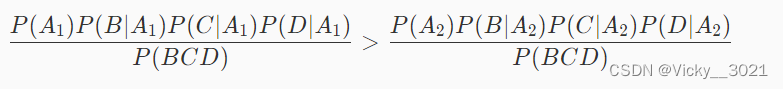
从上面的式子可以看出,P(BCD)是多少对于判断哪个类别的概率高没有影响,所以式子可以简化成如下形式:
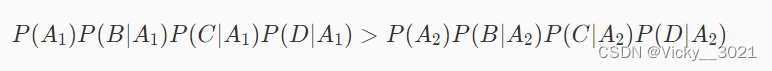
所以在预测时,需要知道P(A1),P(A2),P(B|A_1),P(C|A_1),P(D|A_1)等于多少。而这些概率在训练阶段可以计算出来。
朴素贝叶斯分类算法的训练流程
训练的流程非常简单,主要是计算各种条件概率。假设现在有一组西瓜的数据,如下表所示:
| 编号 | 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|---|
| 1 | 绿 | 清脆 | 清晰 | 是 |
| 2 | 黄 | 浑厚 | 模糊 | 否 |
| 3 | 绿 | 浑厚 | 模糊 | 是 |
| 4 | 绿 | 清脆 | 清晰 | 是 |
| 5 | 黄 | 浑厚 | 模糊 | 是 |
| 6 | 绿 | 清脆 | 清晰 | 否 |
从表中数据可以看出:
P(是好瓜)=4/6,
P(颜色绿|是好瓜)=3/4,
P(颜色黄|是好瓜)=1/4,
P(声音清脆|是好瓜)=1/2,
P(声音浑厚|是好瓜)=1/2,
P(纹理清晰|是好瓜)=1/2,
P(纹理模糊|是好瓜)=1/2,
P(不是好瓜)=2/6,
P(颜色绿|不是好瓜)=1/2,
P(颜色黄|是好瓜)=1/2,
P(声音清脆|不是好瓜)=1/2,
P(声音浑厚|不是好瓜)=1/2,
P(纹理清晰|不是好瓜)=1/2,
P(纹理模糊|不是好瓜)=1/2。
当得到以上概率后,训练阶段的任务就已经完成了。我们不妨再回过头来预测一下这个西瓜是不是好瓜。
| 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|
| 绿 | 清脆 | 清晰 | ? |
假设事件A1为好瓜,事件B为绿,事件C为清脆,事件D为清晰。则有:

假设事件A2为不是瓜,事件B为绿,事件C为清脆,事件D为清晰。则有:
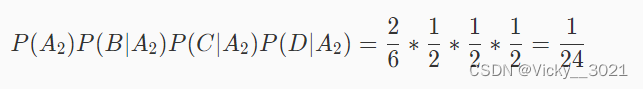
由于 1/8 > 1/24,所以这个西瓜是好瓜。
编程要求
根据提示,完成fit与predict函数,分别实现模型的训练与预测。(PS:在fit函数中需要将预测时需要的概率保存到self.label_prob和self.condition_prob这两个变量中)
其中fit函数参数解释如下:
- feature:训练数据集所有特征组成的ndarray
- label:训练数据集中所有标签组成的ndarray
- return:无返回
predict函数参数解释如下:
- feature:测试数据集所有特征组成的ndarray。(PS:feature中有多条数据)
- return:模型预测的结果。(PS:feature中有多少条数据,就需要返回长度为多少的list或者ndarry)
测试说明
部分训练数据如下(PS:数据以ndarray的方式存储,不包含表头。其中颜色这一列用1表示绿色,2表示黄色;声音这一列用1表示清脆,2表示浑厚。纹理这一列用1表示清晰,2表示模糊,3表示一般):
| 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|
| 2 | 1 | 1 | 1 |
| 1 | 2 | 2 | 0 |
| 2 | 2 | 2 | 1 |
| 2 | 1 | 2 | 1 |
| 1 | 2 | 3 | 1 |
| 2 | 1 | 1 | 0 |
代码
import numpy as np
class NaiveBayesClassifier(object):
def __init__(self):
'''
self.label_prob表示每种类别在数据中出现的概率
例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667
'''
self.label_prob = {}
'''
self.condition_prob表示每种类别确定的条件下各个特征出现的概率
例如训练数据集中的特征为 [[2, 1, 1],
[1, 2, 2],
[2, 2, 2],
[2, 1, 2],
[1, 2, 3]]
标签为[1, 0, 1, 0, 1]
那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0;
当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333;
因此self.condition_prob的值如下:
{
0:{
0:{
1:0.5
2:0.5
}
1:{
1:0.5
2:0.5
}
2:{
1:0
2:1
3:0
}
}
1:
{
0:{
1:0.333
2:0.666
}
1:{
1:0.333
2:0.666
}
2:{
1:0.333
2:0.333
3:0.333
}
}
}
'''
self.condition_prob = {}
def fit(self, feature, label):
'''
对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: 无返回
'''
#********* Begin *********#
row_num = len(feature)
col_num = len(feature[0])
for c in label:
if c in self.label_prob:
self.label_prob[c] += 1
else:
self.label_prob[c] = 1
for key in self.label_prob.keys():
self.label_prob[key] /= row_num
self.condition_prob[key] = {}
for i in range(col_num):
self.condition_prob[key][i] = {}
for k in np.unique(feature[:,i], axis=0):
self.condition_prob[key][i][k] = 0
for i in range(len(feature)):
for j in range(len(feature[i])):
if feature[i][j] in self.condition_prob[label[i]]:
self.condition_prob[label[i]][j][feature[i][j]] += 1
else:
self.condition_prob[label[i]][j][feature[i][j]] = 1
for label_key in self.condition_prob.keys():
for k in self.condition_prob[label_key].keys():
total = 0
for v in self.condition_prob[label_key][k].values():
total += v
for kk in self.condition_prob[label_key][k].keys():
self.condition_prob[label_key][k][kk] /= total
#********* End *********#
def predict(self, feature):
'''
对数据进行预测,返回预测结果
:param feature:测试数据集所有特征组成的ndarray
:return:
'''
# ********* Begin *********#
result = []
for i,f in enumerate(feature):
prob=np.zeros(len(self.label_prob.keys()))
i1 = 0
for label,label_prob in self.label_prob.items():
prob[i1] = label_prob
for j in range(len(feature[0])):
prob[i1] *= self.condition_prob[label][j][f[j]]
i1 += 1
result.append(list(self.label_prob.keys())[np.argmax(prob)])
return np.array(result)
#********* End *********#