transformer论文学习:Attention Is All You Need
参考资源:
1、原论文
2、 https://www.bilibili.com/video/BV1P4411F77q?spm_id_from=333.337.search-card.all.click&vd_source=c88465974cab6da6ea3744fe14ca80f3
3、 https://github.com/aespresso/a_journey_into_math_of_ml/blob/master/03_transformer_tutorial_1st_part/transformer_1.ipynb
整体结构速览


一、网络结构

左侧为编码器,右侧为解码器。
论文中编码器N = 6 。 为了方便进行残差连接,模型中的所有sub-layer以及embedding layer都会产生维度 dmodel = 512 的输出。
解码器也是N = 6 。与编码器中block不同点如下:
1、多了一个sub-layer,该子层对编码器的block的输出进行 multi-head attention。
2、修改了解码器block中的自我注意sub-layer,以防止位置涉及后续位置。这种masking结合输出embeddings偏移一个位置的事实,确保位置i的预测只能依赖于位置小于i的已知输出。
二、注意力机制

1、最初的Q、K、V为线性计算所得,Wq、Wk、Wv均为embed.dim * embed.dim 大小的权重矩阵
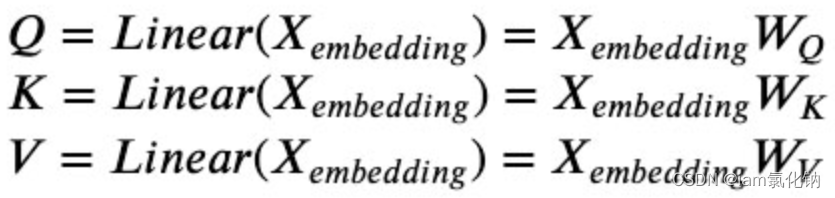
2、进行multi head attention ,即将Q、K、V分割成h份(h为超参数)
维度由[batch size,sequence length,h,embedding dimension]
变成了[batch size,sequence length,h,embedding dimension / h]
3、矩阵运算绘图演示

两个矩阵相乘后得到了注意力矩阵,注意力矩阵的作用就是一个注意力权重的概率分布,我们要用注意力矩阵的权重给V进行加权,上图中我们从注意力矩阵取出一行(和为1)然后依次点乘V的列,矩阵V的每一行代表着每个字向量的数学表达,

(1)除以dk开根是为了把注意力矩阵变成标准正态分布,使得softmax归一化之后的结果更加稳定,以便反向传播的时候获取平衡的梯度
(2)softmax归一化,使每个字跟其他所有字的注意力权重的和为1