1.ЩёОЭјТч
1.1ЩёОЭјТчРраЭжкЖр,ЦфжазюЮЊживЊЕФЪЧЖрВуИажЊЛњЁЃЖрВуИажЊЛњжаЕФЬиеїЩёОдЊФЃаЭГЦЮЊИажЊЛњЁЃ
1.2
1.ЬнЖШЯћЪЇЪЧжИЭЈЙ§вўВиВуДгКѓЯђЧАПД,ЬнЖШЛсБфЕФдНРДдНаЁ,ЫЕУїЧАУцВуЕФбЇЯАЛсЯджјТ§гкКѓУцВуЕФбЇЯА,ЫљвдбЇЯАЛсПЈзЁ,Г§ЗЧЬнЖШБфДѓЁЃ
ЬнЖШЯћЪЇЕФдвђЪмЕНЖржжвђЫигАЯь,Р§ШчбЇЯАТЪЕФДѓаЁ,ЭјТчВЮЪ§ЕФГѕЪМЛЏ,МЄЛюКЏЪ§ЕФБпдЕаЇгІЕШЁЃдкЩюВуЩёОЭјТчжа,УПвЛИіЩёОдЊМЦЫуЕУЕНЕФЬнЖШЖМЛсДЋЕнИјЧАвЛВу,НЯЧГВуЕФЩёОдЊНгЪеЕНЕФЬнЖШЪмЕНжЎЧАЫљгаВуЬнЖШЕФгАЯьЁЃШчЙћМЦЫуЕУЕНЕФЬнЖШжЕЗЧГЃаЁ,ЫцзХВуЪ§діЖр,ЧѓГіЕФЬнЖШИќаТаХЯЂНЋЛсвджИЪ§аЮЪНЫЅМѕ,ОЭЛсЗЂЩњЬнЖШЯћЪЇЁЃ
2.ЬнЖШБЌеЈ дкЩюЖШЭјТчЛђбЛЗЩёОЭјТч(Recurrent Neural Network, RNN)ЕШЭјТчНсЙЙжа,ЬнЖШПЩдкЭјТчИќаТЕФЙ§ГЬжаВЛЖЯРлЛ§,БфГЩЗЧГЃДѓЕФЬнЖШ,ЕМжТЭјТчШЈжижЕЕФДѓЗљИќаТ,ЪЙЕУЭјТчВЛЮШЖЈ;дкМЋЖЫЧщПіЯТ,ШЈжижЕЩѕжСЛсвчГі,БфЮЊ
N
a
N
NaN
NaNжЕ,дйвВЮоЗЈИќаТЁЃ
1.3
ЛњЦїбЇЯА:РћгУМЦЫуЛњЁЂИХТЪТлЁЂЭГМЦбЇЕШжЊЪЖ,ЪфШыЪ§Он,ШУМЦЫуЛњбЇЛсаТжЊЪЖЁЃЛњЦїбЇЯАЕФЙ§ГЬ,ОЭЪЧбЕСЗЪ§ОнШЅгХЛЏФПБъКЏЪ§ЁЃ
? ЩюЖШбЇЯА:ЪЧвЛжжЬиЪтЕФЛњЦїбЇЯА,ОпгаЧПДѓЕФФмСІКЭСщЛюадЁЃЫќЭЈЙ§бЇЯАНЋЪРНчБэЪОЮЊЧЖЬзЕФВуДЮНсЙЙ,УПИіБэЪОЖМгыИќМђЕЅЕФЬиеїЯрЙи,ЖјГщЯѓЕФБэЪОдђгУгкМЦЫуИќГщЯѓЕФБэЪОЁЃ
? ДЋЭГЕФЛњЦїбЇЯАашвЊЖЈвхвЛаЉЪжЙЄЬиеї,ДгЖјгаФПЕФЕФШЅЬсШЁФПБъаХЯЂ, ЗЧГЃвРРЕШЮЮёЕФЬивьадвдМАЩшМЦЬиеїЕФзЈМвОбщЁЃЖјЩюЖШбЇЯАПЩвдДгДѓЪ§ОнжаЯШбЇЯАМђЕЅЕФЬиеї,ВЂДгЦфж№НЅбЇЯАЕНИќЮЊИДдгГщЯѓЕФЩюВуЬиеї,ВЛвРРЕШЫЙЄЕФЬиеїЙЄГЬ,етвВЪЧЩюЖШбЇЯАдкДѓЪ§ОнЪБДњЪмЛЖгЕФвЛДѓдвђЁЃ
1.4ЧАЯђДЋВЅгыЗДЯђДЋВЅ
ЩёОЭјТчЕФМЦЫужївЊгаСНжж:ЧАЯђДЋВЅ(foward propagation, FP)зїгУгкУПвЛВуЕФЪфШы,ЭЈЙ§ж№ВуМЦЫуЕУЕНЪфГіНсЙћ;ЗДЯђДЋВЅ(backward propagation, BP)зїгУгкЭјТчЕФЪфГі,ЭЈЙ§МЦЫуЬнЖШгЩЩюЕНЧГИќаТЭјТчВЮЪ§ЁЃ
МйЩшЩЯвЛВуНсЕу $ i,j,k,Ё $ ЕШвЛаЉНсЕугыБОВуЕФНсЕу $ w $ гаСЌНг,ФЧУДНсЕу $ w $ ЕФжЕдѕУДЫуФи?ОЭЪЧЭЈЙ§ЩЯвЛВуЕФ $ i,j,k,Ё $ ЕШНсЕувдМАЖдгІЕФСЌНгШЈжЕНјааМгШЈКЭдЫЫу,зюжеНсЙћдйМгЩЯвЛИіЦЋжУЯю(ЭМжаЮЊСЫМђЕЅЪЁТдСЫ),зюКѓдкЭЈЙ§вЛИіЗЧЯпадКЏЪ§(МДМЄЛюКЏЪ§),Шч
R
e
L
u
ReLu
ReLu,
s
i
g
m
o
i
d
sigmoid
sigmoid ЕШКЏЪ§,зюКѓЕУЕНЕФНсЙћОЭЪЧБОВуНсЕу $ w $ ЕФЪфГіЁЃ
Цфжа Layer $ L_1 $ ЪЧЪфШыВу,Layer $ L_2 $ ЪЧвўКЌВу,Layer $ L_3 $ ЪЧЪфГіВуЁЃ
? МйЩшЪфШыЪ§ОнМЏЮЊ $ D={x_1, x_2, Ё, x_n} $,ЪфГіЪ§ОнМЏЮЊ $ y_1, y_2, Ё, y_n $ЁЃ
? ШчЙћЪфШыКЭЪфГіЪЧвЛбљ,МДЮЊздБрТыФЃаЭЁЃШчЙћдЪМЪ§ОнОЙ§гГЩф,ЛсЕУЕНВЛЭЌгкЪфШыЕФЪфГіЁЃ
МйЩшгаШчЯТЕФЭјТчВу:
? ЪфШыВуАќКЌЩёОдЊ $ i_1, i_2 $,ЦЋжУ $ b_1 $;вўКЌВуАќКЌЩёОдЊ $ h_1, h_2 $,ЦЋжУ $ b_2 $,ЪфГіВуЮЊ $ o_1, o_2 , , , w_i $ ЮЊВугыВужЎМфСЌНгЕФШЈжи,МЄЛюКЏЪ§ЮЊ s i g m o i d sigmoid sigmoid КЏЪ§ЁЃЖдвдЩЯВЮЪ§ШЁГѕЪМжЕ,ШчЯТЭМЫљЪО:
Цфжа:
ЪфШыЪ§Он $ i1=0.05, i2 = 0.10 $
ЪфГіЪ§Он $ o1=0.01, o2=0.99 $;
ГѕЪМШЈжи $ w1=0.15, w2=0.20, w3=0.25,w4=0.30, w5=0.40, w6=0.45, w7=0.50, w8=0.55 $
ФПБъ:ИјГіЪфШыЪ§Он $ i1,i2 $ (
0.05
0.05
0.05КЭ
0.10
0.10
0.10 ),ЪЙЪфГіОЁПЩФмгыдЪМЪфГі $ o1,o2 $,(
0.01
0.01
0.01КЭ
0.99
0.99
0.99)НгНќЁЃ
ЧАЯђДЋВЅ
ЪфШыВу --> ЪфГіВу
МЦЫуЩёОдЊ $ h1 $ ЕФЪфШыМгШЈКЭ:
$$ net_{h1} = w_1 * i_1 + w_2 * i_2 + b_1 * 1\
net_{h1} = 0.15 * 0.05 + 0.2 * 0.1 + 0.35 * 1 = 0.3775 $$
ЩёОдЊ $ h1 $ ЕФЪфГі $ o1 $ :(ДЫДІгУЕНМЄЛюКЏЪ§ЮЊ sigmoid КЏЪ§):
o u t h 1 = 1 1 + e ? n e t h 1 = 1 1 + e ? 0.3775 = 0.593269992 out_{h1} = \frac{1}{1 + e^{-net_{h1}}} = \frac{1}{1 + e^{-0.3775}} = 0.593269992 outh1?=1+e?neth1?1?=1+e?0.37751?=0.593269992
ЭЌРэ,ПЩМЦЫуГіЩёОдЊ $ h2 $ ЕФЪфГі $ o1 $:
o u t h 2 = 0.596884378 out_{h2} = 0.596884378 outh2?=0.596884378
вўКЌВуЈC>ЪфГіВу: ЁЁЁЁ
МЦЫуЪфГіВуЩёОдЊ $ o1 $ КЭ $ o2 $ ЕФжЕ:
n e t o 1 = w 5 ? o u t h 1 + w 6 ? o u t h 2 + b 2 ? 1 net_{o1} = w_5 * out_{h1} + w_6 * out_{h2} + b_2 * 1 neto1?=w5??outh1?+w6??outh2?+b2??1
n e t o 1 = 0.4 ? 0.593269992 + 0.45 ? 0.596884378 + 0.6 ? 1 = 1.105905967 net_{o1} = 0.4 * 0.593269992 + 0.45 * 0.596884378 + 0.6 * 1 = 1.105905967 neto1?=0.4?0.593269992+0.45?0.596884378+0.6?1=1.105905967
o u t o 1 = 1 1 + e ? n e t o 1 = 1 1 + e 1.105905967 = 0.75136079 out_{o1} = \frac{1}{1 + e^{-net_{o1}}} = \frac{1}{1 + e^{1.105905967}} = 0.75136079 outo1?=1+e?neto1?1?=1+e1.1059059671?=0.75136079
етбљЧАЯђДЋВЅЕФЙ§ГЬОЭНсЪјСЫ,ЮвУЧЕУЕНЪфГіжЕЮЊ $ [0.75136079 , 0.772928465] $,гыЪЕМЪжЕ $ [0.01 , 0.99] $ ЯрВюЛЙКмдЖ,ЯждкЮвУЧЖдЮѓВюНјааЗДЯђДЋВЅ,ИќаТШЈжЕ,жиаТМЦЫуЪфГіЁЃ
**ЗДЯђДЋВЅ **
? 1.МЦЫузмЮѓВю
змЮѓВю:(етРяЪЙгУSquare Error)
E t o t a l = ЁЦ 1 2 ( t a r g e t ? o u t p u t ) 2 E_{total} = \sum \frac{1}{2}(target - output)^2 Etotal?=ЁЦ21?(target?output)2
ЕЋЪЧгаСНИіЪфГі,ЫљвдЗжБ№МЦЫу $ o1 $ КЭ $ o2 $ ЕФЮѓВю,змЮѓВюЮЊСНепжЎКЭ:
E o 1 = 1 2 ( t a r g e t o 1 ? o u t o 1 ) 2 = 1 2 ( 0.01 ? 0.75136507 ) 2 = 0.274811083 E_{o1} = \frac{1}{2}(target_{o1} - out_{o1})^2 = \frac{1}{2}(0.01 - 0.75136507)^2 = 0.274811083 Eo1?=21?(targeto1??outo1?)2=21?(0.01?0.75136507)2=0.274811083.
E o 2 = 0.023560026 E_{o2} = 0.023560026 Eo2?=0.023560026.
E t o t a l = E o 1 + E o 2 = 0.274811083 + 0.023560026 = 0.298371109 E_{total} = E_{o1} + E_{o2} = 0.274811083 + 0.023560026 = 0.298371109 Etotal?=Eo1?+Eo2?=0.274811083+0.023560026=0.298371109.
? 2.вўКЌВу --> ЪфГіВуЕФШЈжЕИќаТ:
вдШЈжиВЮЪ§ $ w5 $ ЮЊР§,ШчЙћЮвУЧЯыжЊЕР $ w5 $ ЖдећЬхЮѓВюВњЩњСЫЖрЩйгАЯь,ПЩвдгУећЬхЮѓВюЖд $ w5 $ ЧѓЦЋЕМЧѓГі:(СДЪНЗЈдђ)
? E t o t a l ? w 5 = ? E t o t a l ? o u t o 1 ? ? o u t o 1 ? n e t o 1 ? ? n e t o 1 ? w 5 \frac{\partial E_{total}}{\partial w5} = \frac{\partial E_{total}}{\partial out_{o1}} * \frac{\partial out_{o1}}{\partial net_{o1}} * \frac{\partial net_{o1}}{\partial w5} ?w5?Etotal??=?outo1??Etotal????neto1??outo1????w5?neto1??
1.5ГЌВЮЪ§
дкЛњЦїбЇЯАЕФЩЯЯТЮФжа,ГЌВЮЪ§ЪЧдкПЊЪМбЇЯАЙ§ГЬжЎЧАЩшжУжЕЕФВЮЪ§,ЖјВЛЪЧЭЈЙ§бЕСЗЕУЕНЕФВЮЪ§Ъ§ОнЁЃЭЈГЃЧщПіЯТ,ашвЊЖдГЌВЮЪ§НјаагХЛЏ,ИјбЇЯАЛњбЁдёвЛзщзюгХГЌВЮЪ§,вдЬсИпбЇЯАЕФадФмКЭаЇЙћЁЃ
ГЌВЮЪ§ЫбЫївЛАуЙ§ГЬ:
НЋЪ§ОнМЏЛЎЗжГЩбЕСЗМЏЁЂбщжЄМЏМАВтЪдМЏЁЃ
дкбЕСЗМЏЩЯИљОнФЃаЭЕФадФмжИБъЖдФЃаЭВЮЪ§НјаагХЛЏЁЃ
дкбщжЄМЏЩЯИљОнФЃаЭЕФадФмжИБъЖдФЃаЭЕФГЌВЮЪ§НјааЫбЫїЁЃ
ВНжш 2 КЭВНжш 3 НЛЬцЕќДњ,зюжеШЗЖЈФЃаЭЕФВЮЪ§КЭГЌВЮЪ§,дкВтЪдМЏжабщжЄЦРМлФЃаЭЕФгХСгЁЃ
Цфжа,ЫбЫїЙ§ГЬашвЊЫбЫїЫуЗЈ,вЛАуга:ЭјИёЫбЫїЁЂЫцЛњЫбЙ§ЁЂЦєЗЂЪНжЧФмЫбЫїЁЂБДвЖЫЙЫбЫїЁЃ
1.6МЄЛюКЏЪ§
1.МЄЛюКЏЪ§ЖдФЃаЭбЇЯАЁЂРэНтЗЧГЃИДдгКЭЗЧЯпадЕФКЏЪ§ОпгаживЊзїгУЁЃ
2.МЄЛюКЏЪ§ПЩвдв§ШыЗЧЯпадвђЫиЁЃШчЙћВЛЪЙгУМЄЛюКЏЪ§,дђЪфГіаХКХНіЪЧвЛИіМђЕЅЕФЯпадКЏЪ§ЁЃЯпадКЏЪ§вЛИівЛМЖЖрЯюЪН,ЯпадЗНГЬЕФИДдгЖШгаЯо,ДгЪ§ОнжабЇЯАИДдгКЏЪ§гГЩфЕФФмСІКмаЁЁЃУЛгаМЄЛюКЏЪ§,ЩёОЭјТчНЋЮоЗЈбЇЯАКЭФЃФтЦфЫћИДдгРраЭЕФЪ§Он,Р§ШчЭМЯёЁЂЪгЦЕЁЂвєЦЕЁЂгявєЕШЁЃ
3.МЄЛюКЏЪ§ПЩвдАбЕБЧАЬиеїПеМфЭЈЙ§вЛЖЈЕФЯпадгГЩфзЊЛЛЕНСэвЛИіПеМф,ШУЪ§ОнФмЙЛИќКУЕФБЛЗжРрЁЃ
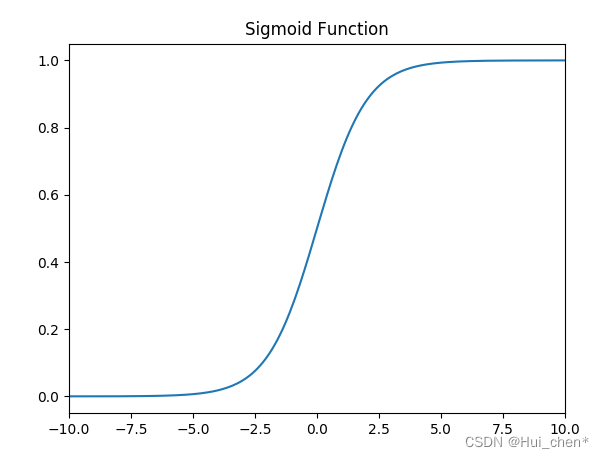
sigmoid МЄЛюКЏЪ§
КЏЪ§ЕФЖЈвхЮЊ:
f
(
x
)
=
1
1
+
e
?
x
f(x) = \frac{1}{1 + e^{-x}}
f(x)=1+e?x1?,ЦфжЕгђЮЊ
(
0
,
1
)
(0,1)
(0,1)ЁЃ
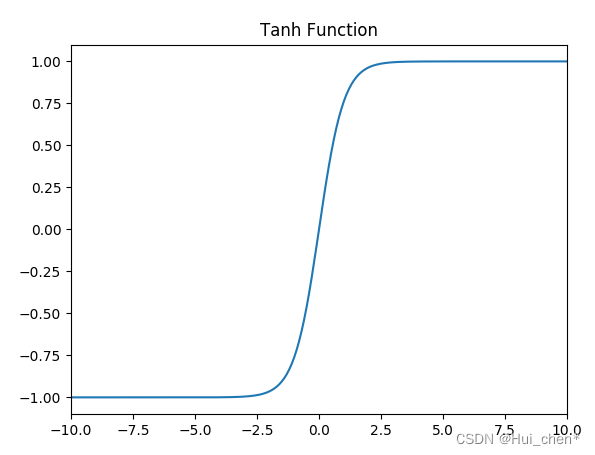
tanhМЄЛюКЏЪ§
КЏЪ§ЕФЖЈвхЮЊ:
f
(
x
)
=
t
a
n
h
(
x
)
=
e
x
?
e
?
x
e
x
+
e
?
x
f(x) = tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
f(x)=tanh(x)=ex+e?xex?e?x?,жЕгђЮЊ
(
?
1
,
1
)
(-1,1)
(?1,1)ЁЃ
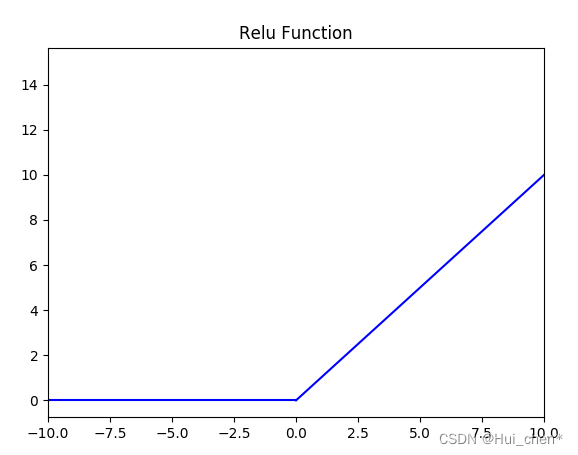
ReluМЄЛюКЏЪ§
КЏЪ§ЕФЖЈвхЮЊ:
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x) = max(0, x)
f(x)=max(0,x) ,жЕгђЮЊ
[
0
,
+
Ёо
)
[0,+Ёо)
[0,+Ёо);
Leak Relu МЄЛюКЏЪ§
КЏЪ§ЖЈвхЮЊ: $f(x) = \left{ \begin{aligned} ax, \quad x<0 \ x, \quad x>0 \end{aligned} \right. $,жЕгђЮЊ $ (-Ёо,+Ёо) $ЁЃ
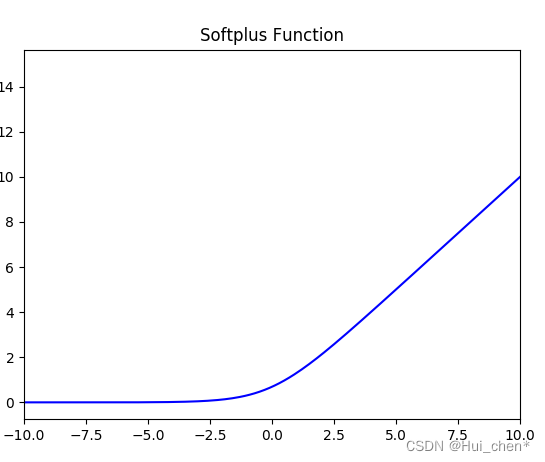
SoftPlus МЄЛюКЏЪ§
КЏЪ§ЕФЖЈвхЮЊ:
f
(
x
)
=
l
n
(
1
+
e
x
)
f(x) = ln( 1 + e^x)
f(x)=ln(1+ex),жЕгђЮЊ
(
0
,
+
Ёо
)
(0,+Ёо)
(0,+Ёо)ЁЃ
softmax КЏЪ§
КЏЪ§ЖЈвхЮЊ: Ів ( z ) j = e z j ЁЦ k = 1 K e z k \sigma(z)j = \frac{e^{z_j}}{\sum{k=1}^K e^{z_k}} Ів(z)j=ЁЦk=1Kezk?ezj??ЁЃ
Softmax ЖргУгкЖрЗжРрЩёОЭјТчЪфГі
1.ШчЙћЪфГіЪЧ 0ЁЂ1 жЕ(ЖўЗжРрЮЪЬт),дђЪфГіВубЁдё sigmoid КЏЪ§,ШЛКѓЦфЫќЕФЫљгаЕЅдЊЖМбЁдё Relu КЏЪ§ЁЃ
2.ШчЙћдквўВиВуЩЯВЛШЗЖЈЪЙгУФФИіМЄЛюКЏЪ§,ФЧУДЭЈГЃЛсЪЙгУ Relu МЄЛюКЏЪ§ЁЃгаЪБ,вВЛсЪЙгУ tanh МЄЛюКЏЪ§,ЕЋ Relu ЕФвЛИігХЕуЪЧ:ЕБЪЧИКжЕЕФЪБКђ,ЕМЪ§ЕШгк 0ЁЃ
3.sigmoid МЄЛюКЏЪ§:Г§СЫЪфГіВуЪЧвЛИіЖўЗжРрЮЪЬтЛљБОВЛЛсгУЫќЁЃ
4.tanh МЄЛюКЏЪ§:tanh ЪЧЗЧГЃгХауЕФ,МИКѕЪЪКЯЫљгаГЁКЯЁЃ
5.ReLu МЄЛюКЏЪ§:зюГЃгУЕФФЌШЯКЏЪ§,ШчЙћВЛШЗЖЈгУФФИіМЄЛюКЏЪ§,ОЭЪЙгУ ReLu Лђеп Leaky ReLu,дйШЅГЂЪдЦфЫћЕФМЄЛюКЏЪ§ЁЃ
6.ШчЙћгіЕНСЫвЛаЉЫРЕФЩёОдЊ,ЮвУЧПЩвдЪЙгУ Leaky ReLU КЏЪ§ЁЃ
7.ЪЙгУreluКЏЪ§ЕФгХЕу
дкЧјМфБфЖЏКмДѓЕФЧщПіЯТ,ReLu МЄЛюКЏЪ§ЕФЕМЪ§ЛђепМЄЛюКЏЪ§ЕФаБТЪЖМЛсдЖДѓгк 0,дкГЬађЪЕЯжОЭЪЧвЛИі if-else гяОф,Жј sigmoid КЏЪ§ашвЊНјааИЁЕуЫФдђдЫЫу,дкЪЕМљжа,ЪЙгУ ReLu МЄЛюКЏЪ§ЩёОЭјТчЭЈГЃЛсБШЪЙгУ sigmoid Лђеп tanh МЄЛюКЏЪ§бЇЯАЕФИќПьЁЃ
sigmoid КЭ tanh КЏЪ§ЕФЕМЪ§дке§ИКБЅКЭЧјЕФЬнЖШЖМЛсНгНќгк 0,етЛсдьГЩЬнЖШУжЩЂ,Жј Relu КЭLeaky ReLu КЏЪ§Дѓгк 0 ВПЗжЖМЮЊГЃЪ§,ВЛЛсВњЩњЬнЖШУжЩЂЯжЯѓЁЃ
ашзЂвт,Relu НјШыИКАыЧјЕФЪБКђ,ЬнЖШЮЊ 0,ЩёОдЊДЫЪБВЛЛсбЕСЗ,ВњЩњЫљЮНЕФЯЁЪшад,Жј Leaky ReLu ВЛЛсВњЩњетИіЮЪЬтЁЃ
ЕЅВрвжжЦ;
ЯрЖдПэРЋЕФаЫЗмБпНч;
ЯЁЪшМЄЛюад;
ReLU КЏЪ§ДгЭМЯёЩЯПД,ЪЧвЛИіЗжЖЮЯпадКЏЪ§,АбЫљгаЕФИКжЕЖМБфЮЊ 0,Жје§жЕВЛБф,етбљОЭГЩЮЊЕЅВрвжжЦЁЃ
вђЮЊгаСЫетЕЅВрвжжЦ,ВХЪЙЕУЩёОЭјТчжаЕФЩёОдЊвВОпгаСЫЯЁЪшМЄЛюадЁЃ
ЯЁЪшМЄЛюад:ДгаХКХЗНУцРДПД,МДЩёОдЊЭЌЪБжЛЖдЪфШыаХКХЕФЩйВПЗжбЁдёадЯьгІ,ДѓСПаХКХБЛПЬвтЕФЦСБЮСЫ,етбљПЩвдЬсИпбЇЯАЕФОЋЖШ,ИќКУИќПьЕиЬсШЁЯЁЪшЬиеїЁЃЕБ $ x<0 $ ЪБ,ReLU гВБЅКЭ,ЖјЕБ $ x>0 $ ЪБ,дђВЛДцдкБЅКЭЮЪЬтЁЃReLU ФмЙЛдк $ x>0 $ ЪББЃГжЬнЖШВЛЫЅМѕ,ДгЖјЛКНтЬнЖШЯћЪЇЮЪЬтЁЃ
8.Softmax КЏЪ§
softmax КЏЪ§МгШыСЫ $ e $ ЕФУнКЏЪ§е§ЪЧЮЊСЫСНМЋЛЏ:е§бљБОЕФНсЙћНЋЧїНќгк 1,ЖјИКбљБОЕФНсЙћЧїНќгк 0ЁЃ
1.7.Batch_Size
BatchЕФбЁдё,ЪзЯШОіЖЈЕФЪЧЯТНЕЕФЗНЯђЁЃ
ШчЙћЪ§ОнМЏБШНЯаЁ,ПЩВЩгУШЋЪ§ОнМЏЕФаЮЪН,КУДІЪЧ:
гЩШЋЪ§ОнМЏШЗЖЈЕФЗНЯђФмЙЛИќКУЕиДњБэбљБОзмЬх,ДгЖјИќзМШЗЕиГЏЯђМЋжЕЫљдкЕФЗНЯђЁЃ
гЩгкВЛЭЌШЈжиЕФЬнЖШжЕВюБ№ОоДѓ,вђДЫбЁШЁвЛИіШЋОжЕФбЇЯАТЪКмРЇФбЁЃ Full Batch Learning ПЩвдЪЙгУ Rprop жЛЛљгкЬнЖШЗћКХВЂЧвеыЖдадЕЅЖРИќаТИїШЈжЕЁЃ
1.Batch_Size ЬЋаЁ,ФЃаЭБэЯжаЇЙћМЋЦфдуИт(errorьЩ§)ЁЃ
2.ЫцзХ Batch_Size діДѓ,ДІРэЯрЭЌЪ§ОнСПЕФЫйЖШдНПьЁЃ
3.ЫцзХ Batch_Size діДѓ,ДяЕНЯрЭЌОЋЖШЫљашвЊЕФ epoch Ъ§СПдНРДдНЖрЁЃ
4.гЩгкЩЯЪіСНжжвђЫиЕФУЌЖм, Batch_Size діДѓЕНФГИіЪБКђ,ДяЕНЪБМфЩЯЕФзюгХЁЃ
5.гЩгкзюжеЪеСВОЋЖШЛсЯнШыВЛЭЌЕФОжВПМЋжЕ,вђДЫ Batch_Size діДѓЕНФГаЉЪБКђ,ДяЕН6.зюжеЪеСВОЋЖШЩЯЕФзюгХЁЃ
1.8ЙщвЛЛЏ
1.8.1ЮЊЪВУДвЊЙщвЛЛЏ?
ЮЊСЫКѓУцЪ§ОнДІРэЕФЗНБу,ЙщвЛЛЏЕФШЗПЩвдБмУтвЛаЉВЛБивЊЕФЪ§жЕЮЪЬтЁЃ
ЮЊСЫГЬађдЫааЪБЪеСВМгПьЁЃ
ЭЌвЛСПИйЁЃбљБОЪ§ОнЕФЦРМлБъзМВЛвЛбљ,ашвЊЖдЦфСПИйЛЏ,ЭГвЛЦРМлБъзМЁЃетЫуЪЧгІгУВуУцЕФашЧѓЁЃ
БмУтЩёОдЊБЅКЭЁЃЩЖвтЫМ?ОЭЪЧЕБЩёОдЊЕФМЄЛюдкНгНќ 0 Лђеп 1 ЪБЛсБЅКЭ,дкетаЉЧјгђ,ЬнЖШМИКѕЮЊ 0,етбљ,дкЗДЯђДЋВЅЙ§ГЬжа,ОжВПЬнЖШОЭЛсНгНќ 0,етЛсгааЇЕиЁАЩБЫРЁБЬнЖШЁЃ
БЃжЄЪфГіЪ§ОнжаЪ§жЕаЁЕФВЛБЛЭЬЪГЁЃ
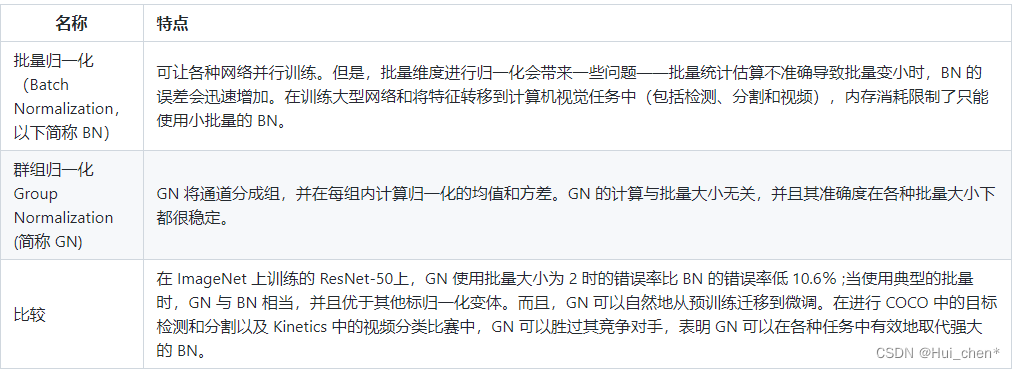
дкCNNжа,BNгІзїгУдкЗЧЯпадгГЩфЧАЁЃдкЩёОЭјТчбЕСЗЪБгіЕНЪеСВЫйЖШКмТ§,ЛђЬнЖШБЌеЈЕШЮоЗЈбЕСЗЕФзДПіЪБПЩвдГЂЪдBNРДНтОіЁЃСэЭт,дквЛАуЪЙгУЧщПіЯТвВПЩвдМгШыBNРДМгПьбЕСЗЫйЖШ,ЬсИпФЃаЭОЋЖШЁЃ
? BNБШНЯЪЪгУЕФГЁОАЪЧ:УПИіmini-batchБШНЯДѓ,Ъ§ОнЗжВМБШНЯНгНќЁЃдкНјаабЕСЗжЎЧА,вЊзіКУГфЗжЕФshuffle,ЗёдђаЇЙћЛсВюКмЖрЁЃСэЭт,гЩгкBNашвЊдкдЫааЙ§ГЬжаЭГМЦУПИіmini-batchЕФвЛНзЭГМЦСПКЭЖўНзЭГМЦСП,вђДЫВЛЪЪгУгкЖЏЬЌЕФЭјТчНсЙЙКЭRNNЭјТчЁЃ
1.9бЇЯАТЪ
дкЬнЖШЯТНЕЗЈжа,ЖМЪЧИјЖЈЕФЭГвЛЕФбЇЯАТЪ,ећИігХЛЏЙ§ГЬжаЖМвдШЗЖЈЕФВНГЄНјааИќаТ, дкЕќДњгХЛЏЕФЧАЦкжа,бЇЯАТЪНЯДѓ,дђЧАНјЕФВНГЄОЭЛсНЯГЄ,етЪББуФмвдНЯПьЕФЫйЖШНјааЬнЖШЯТНЕ,ЖјдкЕќДњгХЛЏЕФКѓЦк,ж№ВНМѕаЁбЇЯАТЪЕФжЕ,МѕаЁВНГЄ,етбљНЋгажњгкЫуЗЈЕФЪеСВ,ИќШнвзНгНќзюгХНтЁЃЙЪЖјШчКЮЖдбЇЯАТЪЕФИќаТГЩЮЊСЫбаОПепЕФЙизЂЕуЁЃ? дкФЃаЭгХЛЏжа,ГЃгУЕНЕФМИжжбЇЯАТЪЫЅМѕЗНЗЈга:ЗжЖЮГЃЪ§ЫЅМѕЁЂЖрЯюЪНЫЅМѕЁЂжИЪ§ЫЅМѕЁЂздШЛжИЪ§ЫЅМѕЁЂгрЯвЫЅМѕЁЂЯпадгрЯвЫЅМѕЁЂдыЩљЯпадгрЯвЫЅМѕ

1.10Dropout
ЩюЖШбЇЯАПЩФмДцдкЙ§ФтКЯЮЪЬтЁЊЁЊИпЗНВю,гаСНИіНтОіЗНЗЈ,вЛИіЪЧе§дђЛЏ,СэвЛИіЪЧзМБИИќЖрЕФЪ§Он,етЪЧЗЧГЃПЩППЕФЗНЗЈ,ЕЋФуПЩФмЮоЗЈЪБЪБПЬПЬзМБИзуЙЛЖрЕФбЕСЗЪ§ОнЛђепЛёШЁИќЖрЪ§ОнЕФГЩБОКмИп,ЕЋе§дђЛЏЭЈГЃгажњгкБмУтЙ§ФтКЯЛђМѕЩйФуЕФЭјТчЮѓВюЁЃ
ШчЙћФуЛГвЩЩёОЭјТчЙ§ЖШФтКЯСЫЪ§Он,МДДцдкИпЗНВюЮЪЬт,ФЧУДзюЯШЯыЕНЕФЗНЗЈПЩФмЪЧе§дђЛЏ,СэвЛИіНтОіИпЗНВюЕФЗНЗЈОЭЪЧзМБИИќЖрЪ§Он,етвВЪЧЗЧГЃПЩППЕФАьЗЈ,ЕЋФуПЩФмЮоЗЈЪБЪБзМБИзуЙЛЖрЕФбЕСЗЪ§Он,Лђеп,ЛёШЁИќЖрЪ§ОнЕФГЩБОКмИп,ЕЋе§дђЛЏгажњгкБмУтЙ§ЖШФтКЯ,ЛђепМѕЩйЭјТчЮѓВюЁЃ
? dropoutвЛДѓШБЕуОЭЪЧДњМлКЏЪ§JВЛдйБЛУїШЗЖЈвх,УПДЮЕќДњ,ЖМЛсЫцЛњвЦГ§вЛаЉНкЕу,ШчЙћдйШ§МьВщЬнЖШЯТНЕЕФадФм,ЪЕМЪЩЯЪЧКмФбНјааИДВщЕФЁЃЖЈвхУїШЗЕФДњМлКЏЪ§JУПДЮЕќДњКѓЖМЛсЯТНЕ,вђЮЊЮвУЧЫљгХЛЏЕФДњМлКЏЪ§JЪЕМЪЩЯВЂУЛгаУїШЗЖЈвх,ЛђепЫЕдкФГжжГЬЖШЩЯКмФбМЦЫу,ЫљвдЮвУЧЪЇШЅСЫЕїЪдЙЄОпРДЛцжЦетбљЕФЭМЦЌЁЃЮвЭЈГЃЛсЙиБеdropoutКЏЪ§,НЋkeep-probЕФжЕЩшЮЊ1,дЫааДњТы,ШЗБЃJКЏЪ§ЕЅЕїЕнМѕЁЃШЛКѓДђПЊdropoutКЏЪ§,ЯЃЭћдкdropoutЙ§ГЬжа,ДњТыВЂЮДв§ШыbugЁЃЮвОѕЕУФувВПЩвдГЂЪдЦфЫќЗНЗЈ,ЫфШЛЮвУЧВЂУЛгаЙигкетаЉЗНЗЈадФмЕФЪ§ОнЭГМЦ,ЕЋФуПЩвдАбЫќУЧгыdropoutЗНЗЈвЛЦ№ЪЙгУЁЃ
1.11Ъ§ОндіЧП
Color Jittering:ЖдбеЩЋЕФЪ§ОндіЧП:ЭМЯёССЖШЁЂБЅКЭЖШЁЂЖдБШЖШБфЛЏ(ДЫДІЖдЩЋВЪЖЖЖЏЕФРэНтВЛжЊЪЧЗёЕУЕБ);
PCA Jittering:ЪзЯШАДееRGBШ§ИібеЩЋЭЈЕРМЦЫуОљжЕКЭБъзМВю,дйдкећИібЕСЗМЏЩЯМЦЫуаЗНВюОиеѓ,НјааЬиеїЗжНт,ЕУЕНЬиеїЯђСПКЭЬиеїжЕ,гУРДзіPCA Jittering;
Random Scale:ГпЖШБфЛЛ;
Random Crop:ВЩгУЫцЛњЭМЯёВюжЕЗНЪН,ЖдЭМЯёНјааВУМєЁЂЫѕЗХ;АќРЈScale JitteringЗНЗЈ(VGGМАResNetФЃаЭЪЙгУ)ЛђепГпЖШКЭГЄПэБШдіЧПБфЛЛ;
Horizontal/Vertical Flip:ЫЎЦН/ДЙжБЗзЊ;
Shift:ЦНвЦБфЛЛ;
Rotation/Reflection:а§зЊ/ЗТЩфБфЛЛ;
Noise:ИпЫЙдыЩљЁЂФЃК§ДІРэ;
Label Shuffle:РрБ№ВЛЦНКтЪ§ОнЕФдіЙу;
в§гУhttps://github.com/scutan90/DeepLearning-500-questions/blob/master/ch03_%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80/%E7%AC%AC%E4%B8%89%E7%AB%A0_%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80.md