
背景
预训练模型方向一直都是大小厂的必争之地。对于中文预训练模型,将中文文本转成对应的token,到底是以字、还是词、或者字+词为单位,大家各有看法。字的话,词表肯定小,训练快,模型参数量小,但是单个字含的信息没有词的信息更具体。词的话,很容易出现OOV问题。所以,通常是字+词混合,如: WoBert、Roformer。即使是字+词,词表也会相应变大,对应模型参数量也就有所增加。
本文提出了一种在预训练任务中,加入词边界,来学习词信息的模型MarkBert。
模型

模型很简单,如上图a,首先是对文本进行分词,其中Pos Tagggins是对应词的词性。 b图是标准BERT模型,以字为单位进行训练。c图就是本文提出的第一个模型MarkBERT-base,在每个词之间加入一个标记符[S],用来区分词的边界。d图是第二个模型MarkBERT-pos,在词之间加入前一个词的词性信息。即显性输入了词性信息,又可以用来区分词边界。
在训练的过程中,主要包含两个任务:
- 替换词的检测: 就是按词(文本的span)进行替换。如果当前词被替换,预测标记为“False”, 否则为“True”。假设第i个标记的表示为 x i x_i xi?,标签为True或False。则替换词检测的损失为:

说白了就是一个二分类的交叉熵损失。针对每个词做损失计算,最后累加。
- MASK词的预测(MLM): 这个任务就不多讲了,常规了MASK词预测任务。本文MASK时,也是有可能MASK掉词边界标识符的。
作者在论文的附录,给出了替换词检测的实现方式,如下图:

其实很简单,就是用词后面那个边界符去判断前面的词是否被替换。
至此,模型就介绍完了。
实验
因为本文主要是为了强化词的信息,那肯定在NER任务上可能会表现很好。因此,第一个实验就是在NER任务上的对比:
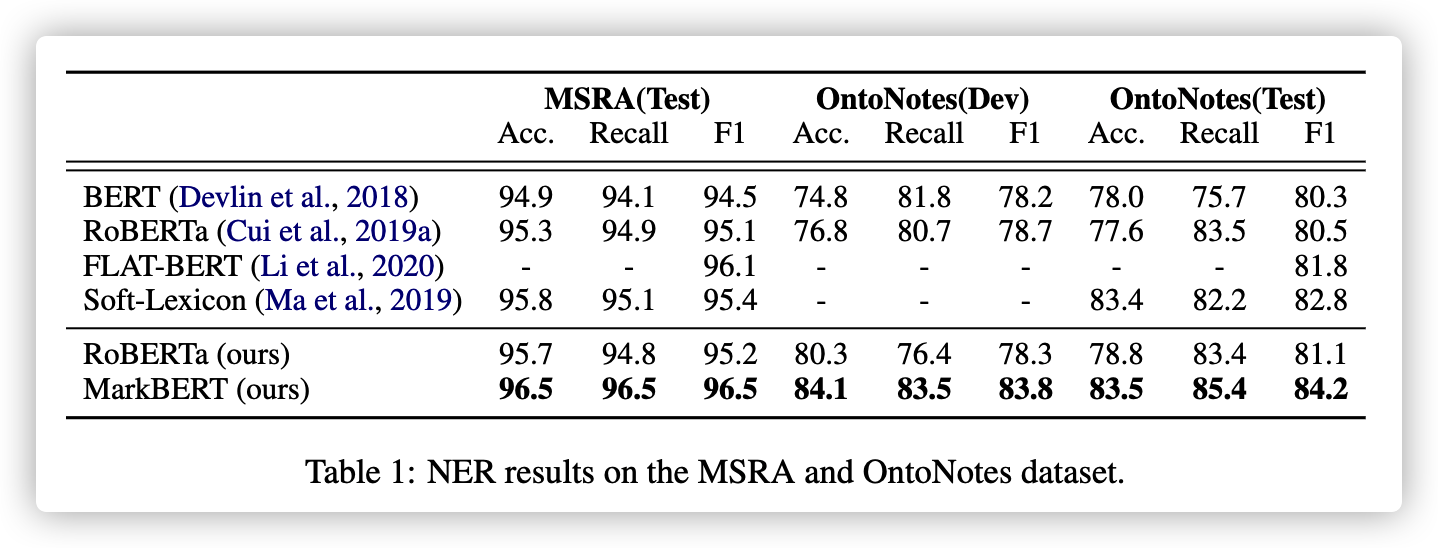
另外,作者也做了其他NLU任务,如下:

