������ѧϰ�����类�����һ������ѧϰ�ķ���֮һ,�����������Ҿ��к�ǿ�Ŀɽ�����,��������Ȼ�ڱ��㷺ʹ�á�
һ��������ѧϰ����
(�Ƚϼ�,һ������)?
��:����һ���˶�?
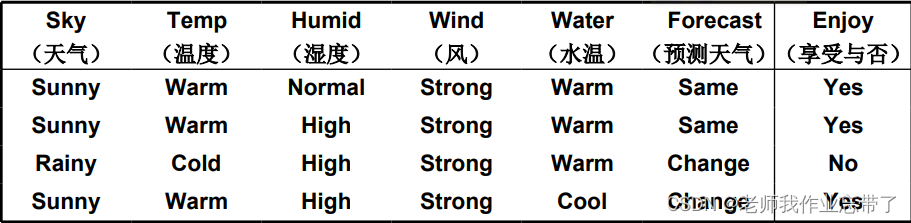
?�����µ�һ��,�Ƿ����ȥ�����˶�?
���þ�����ѧϰ�ľ���Ŀ������
- ���з���ֵ�����ķ�������
- ��ɢ����
- û�����ƶȵ�
- ��������
��һ������:ˮ��
- ��ɫ:��ɫ����ɫ����ɫ
- ��С:С���С���
- ��״:���Ρ�ϸ��
- �:����
������ʾ
���Ե��б�������ֵ����
���������˶�������:
- 6ֵ����:�������¶ȡ�ʪ�ȡ��硢ˮ�¡�Ԥ������
- ijһ�������ʵ��:{�硢ů��һ�㡢ǿ��ů������}
����ˮ��������:
- 4ֵԪ��:��ɫ����С����״��ζ��
- ij��ˮ����ʵ��: {�졢���Ρ�С����}
ѵ������
����������
��������չ��ʷ-��̱�
? 1966,��Hunt�������
? 1970��s~1980��s
????????? CART ��Friedman, Breiman���
????????? ID3 �� Quinlan ���
? ��1990��s����
????????? �Ա��о����㷨�Ľ�(Mingers, Dietterich, Quinlan, etc.)
????????? ��㷺ʹ�õľ������㷨: C4.5 �� Quinlan �� 1993 ����
?
��������������㷨 �C ID3
�Զ�����,̰������
�ݹ��㷨
����ѭ��:
- A :�ҳ���һ�� ��� ��������
- �� A ��Ϊ��ǰ�ڵ��������
- ������A (vi )��ÿ��ֵ,���������Ӧ���µ��ӽڵ�
- ��������ֵ��ѵ���������䵽�����ڵ�
- ��� ѵ����������������,���˳�ѭ��,�������ݹ�״̬��������̽�����µ�Ҷ�ڵ�
��:outlook�������ҳ�����Ѿ�������,���ǾͰ������ɵ�ǰ�ĸ��ڵ�,����outlookҲ��������������Ǿͻ��в�ͬ�ķ�֧��ͬ���ӽڵ�,����sunny��overcast��rain,�絽��overcast���Ѿ�����/�б�ǩ��,˵���Ѿ����ֺ���,�����û���ֺ�,���ǾͰ������ݵ�ȡֵ��һ�����ݷֵ�sunny��rain��Ӧ�ķ�֧��,humidity��wind,����ݹ����ִ�С����ʱhumidity������ѡ���������ԡ�
����:
- ʲô������Ϥ����ѵľ�������?
- ʲô����ѵ��������������?
Q1:�ĸ��������������?
������������������ A1(ʪ��)�� A2(����)(64������,29������35������)
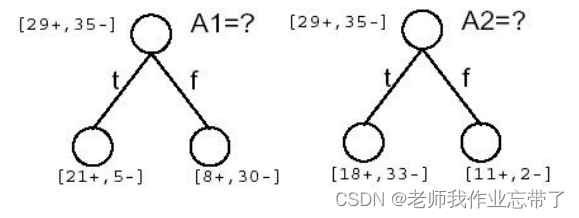
A1Ϊtrue(ʪ�ȴ�)����21�� 5�� Ϊfalse(ʪ��С)����8��30��
A2Ϊtrue(������)����18��33�� Ϊfalse(����С)����11��2��
ע:������ȥ�˶�,�����Dz�ȥ��
��ʱ����A1��A2(ʪ�Ⱥͷ���)�ĸ���Ϊ���ڵ�/��Ѿ������Ժ���?
��ǰ��ѽڵ�ѡ��Ļ���ԭ��:���
????????????????????????----����ƫ����ʹ�ü��ľ��н��ٽڵ����
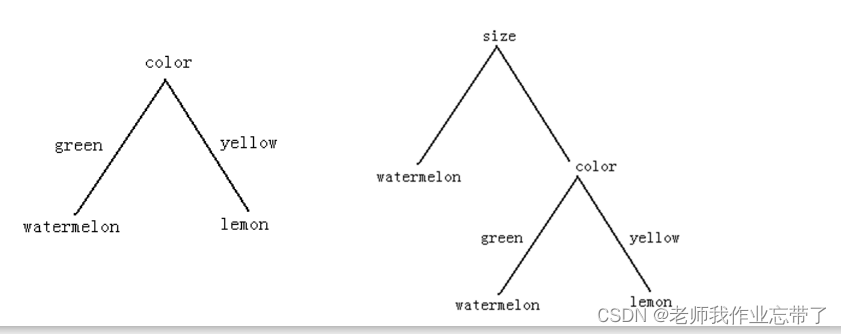
����ͼ,����������ˮ��,���Ϻ����ʡ�����ʹ����ɫcolor��Ϊ���ڵ���ֻ��Ҫ����green����yellow���ܹ��ж������ϻ������ʡ����������ѡ��size��С,��Ŀ϶���������,��С��˵��������С����,���Ի�Ҫ������ɫ���жϡ�
����ѡ��ͽڵ���Ӷ�(Impurity)
����ѡ��Ļ���ԭ��:���
????????????????���� ����ƫ����ʹ�ü��ľ��н��ٽڵ����
��ÿ���ڵ� N��,����ѡ��һ������ T,ʹ�õ��ﵱǰ�����ڵ�����ݾ����� ������
����(purity) �C ���Ӷ�(impurity)
����ͼ��һ��������,������ ��ɫ ,�������ɫ���������ұ�ɫ��������
���ڵڶ��� �ߴ� С �Ľڵ���,����������������,�Ͳ��� ����
��κ������Ӷ�?
1.?��(Entropy) (�㷺ʹ��)
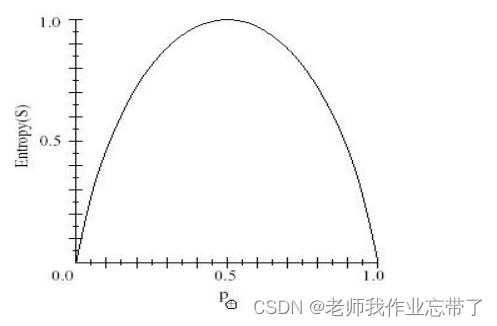
�ڵ�N���ر�ʾΪ������ڵ��²�ͬ��ȡֵ(w:��size��СΪ��w1�Ǵ�w2��С,
Ϊw1�ĸ���,
Ϊw2�ĸ��ʡ�),ÿһ��
�ĺ͵��෴����
- ����: 0log0=0
- ����Ϣ������,�ض�������Ϣ�Ĵ���/���Ӷ�,������Ϣ�IJ�ȷ����
- ����ͼ��֪,������ʱ�����Ϊһ��һ��,����ʱ�ȷ����
- ��̬�ֲ� �C ����������ֵ
���㲢�ж���ͼ����:
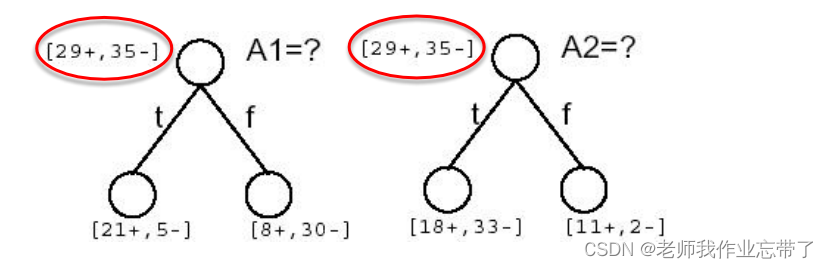
?���Կ���A1 A2����29+,35-,�ӽ�һ��һ��,��Ӧ���ǽӽ���1�ġ�
?
?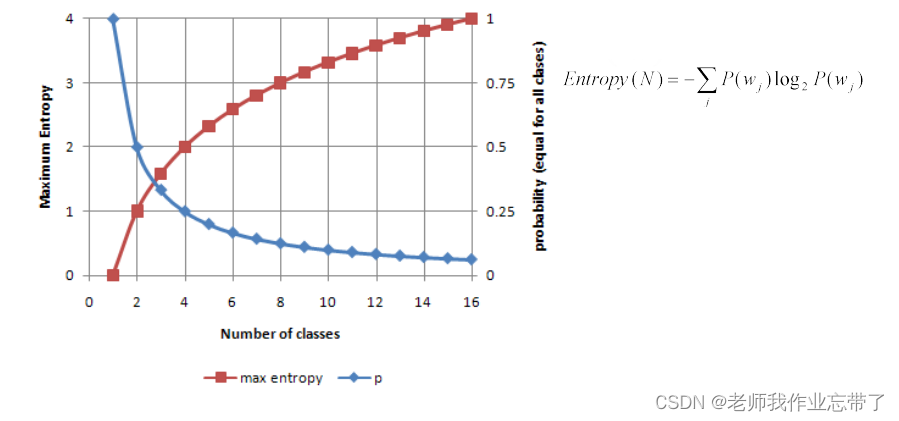
����:1����ʱ����Ϊ1,2����ʱ����Ϊ0.5,16����ʱ����Ϊ1/16
����:1����ʱ�����Ϊ0,2����ʱ�����Ϊ1,����������(�������ʱΪ���ȷֲ���)
?
2. Gini ���Ӷ� ( Duda ������ʹ�� Gini ���Ӷ�)
�ھ���ѧ�����ѧ�������� ����ϵ�� ������һ�����ҷ�չ��ƽ�����
��ʾ���в���ͬ����ij˻�(�����A��B���������p(A)*p(B),�����A��B��C���������p(A)*p(B)+p(A)*p(C)+p(B)*p(C))
����?1-��ͬ����ij˻� ()
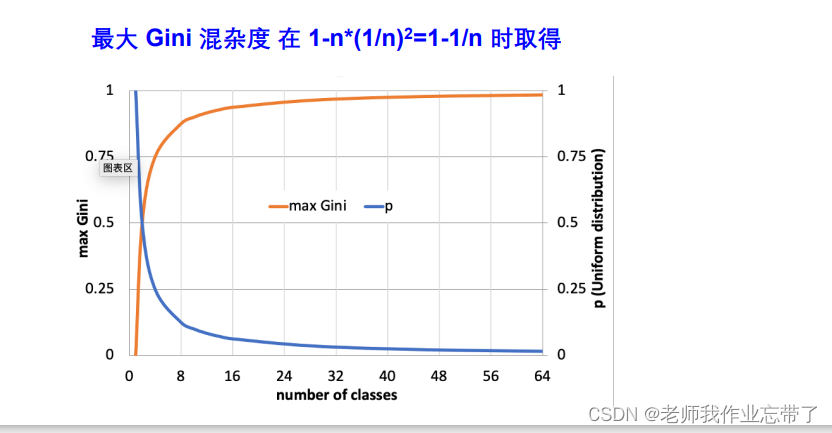
n = number of class(Ҳ����Ϊ�Ǿ��ȷֲ���,�����ֶ���1/n)
��������,����Ϊ1.
?
3. ��������Ӷ�
1-�����ĸ���,��1-�����������Ǹ���(�ֶ���,1-���Ǵ���)
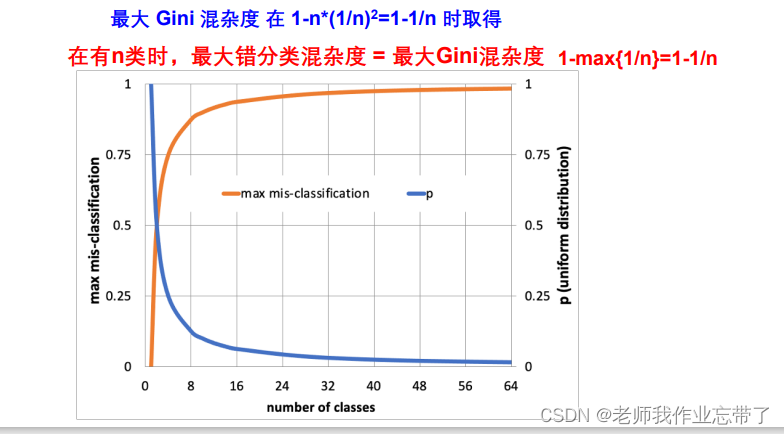
?
�������Ӷȵı仯--��Ϣ����(IG)
���ڶ�A�����������������ص�����������
?ԭʼS����ֵ-��������A�����Ժ��������ֵ
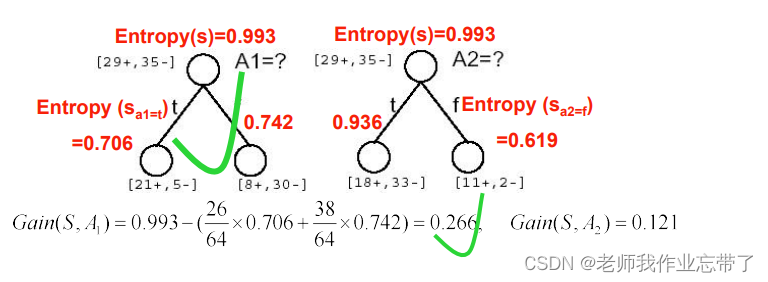 ������,�ɼ�A1(ʪ��)��IG(��Ϣ����)����һЩ,Ҳ����ζ�����ǻ���˸������Ϣ(���ٵ��ظ���һЩ),����ѡ��A1��Ϊ���ڵ㡣
������,�ɼ�A1(ʪ��)��IG(��Ϣ����)����һЩ,Ҳ����ζ�����ǻ���˸������Ϣ(���ٵ��ظ���һЩ),����ѡ��A1��Ϊ���ڵ㡣
?
��:�����±�ѡ�����ĸ����������ڵ�

Outlook��Gain���,ѡ����Ϊ���ڵ㡣?
?
Q2: ��ʱ����(ֹͣ���ѽڵ�)??
�����ѵ���������������ࡱ
? ���� 1: �����ǰ�Ӽ����������� ����ȫ��ͬ��������,��ô��ֹ
?
? ���� 2: �����ǰ�Ӽ����������� ����ȫ��ͬ����������,��ô��ֹ
????????����:����-��-ʪ������-�¶Ⱥ���,����е�ȥ���е�ûȥ����ʱ��ʹ����ֹҲû�취��,��Ϊ���õ���Ϣ�Ѿ������ˡ�����ζ��:1������������noise����Ҫ��������,�����������˵���������������á�2��©������Ҫ��Feature,����©���˵����Ƿ��п�,�пξ�û�취��ȥ�档
?
���ܵ�����3: ��� �������Է��ѵ���Ϣ����Ϊ0, ��ô��ֹ? ?���Ǹ����뷨��?(No)
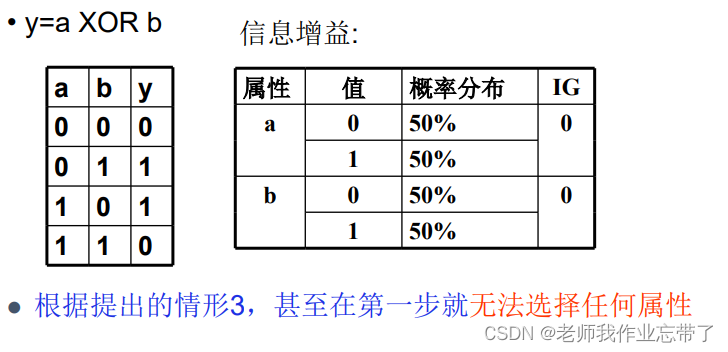
����ͼ��ʱ���ĵ�һ���ڵ㶼�Ҳ�����(IG����0),���3˵�ö�,�Ǵ�ʱ����������������
�������Dz�Ҫ�������,������һ��,IG����0,������ֵ��ʱ�����ѡһ����ϵ�ͱ�����������(��ʱҲ����������)
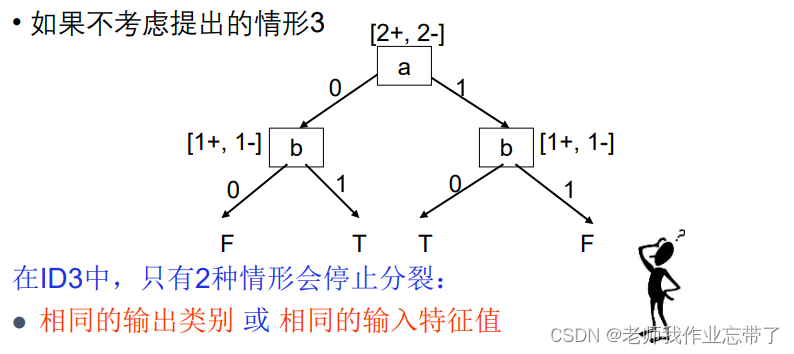
?����ID3��ֻ���������������ֹͣ����,���IG=0,�����ȡһ���ͺá�
?
ID3�㷨�����ļ���ռ�

- ����ռ����걸��(���ܴ������Ե���ȡ���ܴ������Եĺ�ȡ)
????????Ŀ�꺯��һ���ڼ���ռ���
- �����������(��������һ��·����ȥ)
????????������20������(���ݾ���,һ��feature������20��,���ڸ������Ƚϳ�Ҳ���ײ��������)
- û�л���(��A1�����ڵ�,û�취�˻�ȥ��A2�����ڵ���ô��)
????????�ֲ�����
- ��ÿһ����ʹ���Ӽ�����������(�����ݶ��½��㷨��Ȩֵ�ĸ��²�����ÿ�����ݸ���һ�εĻ�,�Ǿ���ÿ��ֻʹ��һ������)
????????��������������ѡ��
????????������������³����
?
ID3�еĹ���ƫ��(Inductive Bias)
- ����ռ� H ���������������� X �ϵ�
????????û�жԼ���ռ�������
- ƫ�����ڿ������ڵ㴦�����Ծ��и�����Ϣ�������
????????�����ҵ���̵���
????????���㷨��ƫ�����ڶ�ijЩ�������һЩƫ�� (����ƫ��), �����ǶԼ���ռ� H ������(����ƫ��).
????????�¿�ķ�굶(Occam��s Razor)*:ƫ���ڷ������ݵ���̵ļ���
?
CART (����ͻع���)
һ��ͨ�õĿ��:
- ����ѵ�����ݹ���һ�þ�����
- ����������ѵ�����Ϸֳ�Խ��ԽС���Ӽ�
- ���Ӽ��������ٷ���
- ���߽���һ���������ľ���
����������㷨������������,����ID3��C4.5�ȵȡ�
?
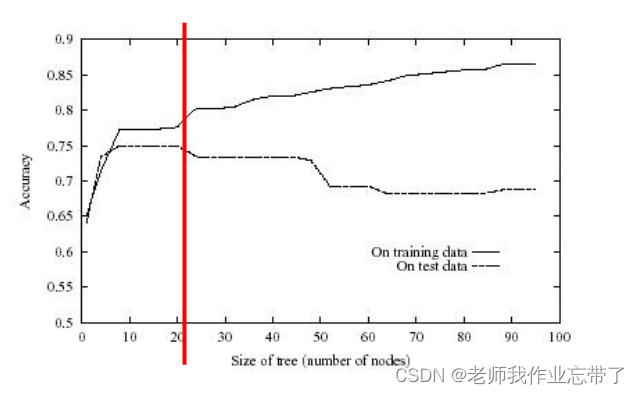
�������������
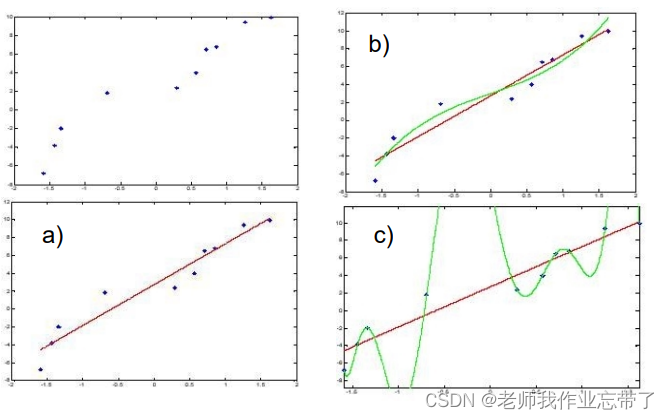
����ͼ,b��a����,�������cһ��ÿ���㶼�����������,������Ϊ0,���������һ���µĵ�:
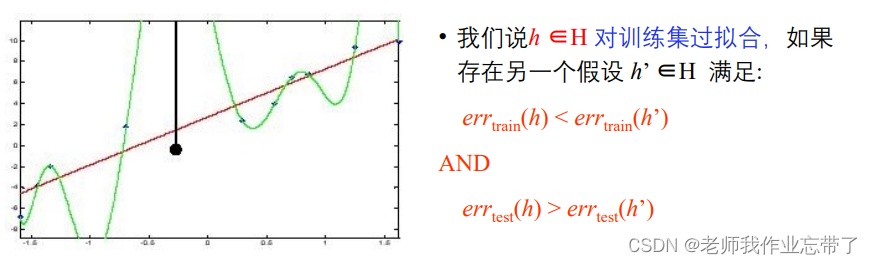
��ʱc���㷨������̫����,����ƥ��ѵ��������,ʹ�����ڲ��Եĸ���δ��ʵ���ϵķ��������½��ˡ�
����������ϵ�һ����������:
- ÿ��Ҷ�ڵ㶼��Ӧ����ѵ������ ���� ÿ��ѵ���������������ط���
- �������൱�ڽ�����һ�����ݲ���㷨�ļ�ʵ��
����ʱ��������һ�����ݲ��,����������ݽṹ���ϣ��������ζ�Ų���ʱֻ�ܲ��ұ����е�����,����û�е����ݲ鲻��,ûʲô����������
?
�ġ���α�������
�Ծ�������˵�����ַ�����������
- �����ݵķ�����ͳ�������ϲ�������(��������)ʱ,��ֹͣ����:Ԥ��֦
- ����һ����ȫ��,Ȼ���������֦
��ʵ��Ӧ����,һ��Ԥ��֦����, �����֦�õ�����ȷ�ʸ��ߡ�?
����Ԥ��֦
���ѹ������Ĵ�С
Ԥ��֦: ����������
ͨ��һ���ڵ㲻�ټ�������,��:
- ����һ���ڵ��ѵ��������С��ѵ�����ϵ�һ���ض����� (���� 5%)
- ���ۻ��ӶȻ�������Ƕ���
- ԭ��:���ڹ������������ľ���������ϴ����ͷ�������(ä������)
������100������,����ǰ�ڵ�ֻ��5��������,�Ͳ��������·���,���ۼ�����������,˵���ֵĹ�ϸ�ˡ�
Ԥ��֦: ������Ϣ�������ֵ
- �趨һ����С����ֵ,�����������������ֹͣ����:
- �ŵ�: 1. �õ�������ѵ������? 2. Ҷ�ڵ���������е��κ�һ��
- ȱ��: �����趨һ���õ���ֵ
ѡIG���Ϊ�ڵ�,���IG���Ļ����е�С��,?��ֹͣ��
���ں��֦:
? ���ѡ�� ����ѡ� ����?
????????���������֤�����ϲ���Ч��
? MDL (Minimize Description Length ����������):
????????minimize ( size(tree) + size(misclassifications(tree)) ) ���Ĵ�С�ʹ����ʵĺ���С
���֦: ���ͼ�֦
? �����ݼ���Ϊѵ��������֤��
????????? ��֤��:
????????????????? ��֪��ǩ
????????????????? ������
????????????????? ��Ҫ����֤���ϲ���ģ����!
? ��ֱ֦���ټ��ͻ��������:
????????? ����֤���ϲ��Լ�ȥÿ�����ܽڵ�(������Ϊ��������)��Ӱ��
????????? ̰�ĵ�ȥ��ij������������֤��ȷ�ʵĽڵ�
����ij���ڵ��,��ζ����µ�Ҷ�ڵ�(����)�ı�ǩ��?
��֦���µ�Ҷ�ڵ�ı�ǩ��ֵ����
? ��ֵ����������(60��data,50��+10��-,�Ǿ�+)
? ������ڵ�����ı�ǩ
????????ÿ�������һ��֧�ֶ�(5/6:1/6) (����ѵ������ÿ�ֱ�ǩ����Ŀ)
????????����ʱ: ���ݸ���(5/6:1/6)ѡ��ij������ѡ������ǩ
? �����һ���ع��� (��ֵ��ǩ),������ƽ�����Ȩƽ��
? ����
���ͼ�֦��Ч��
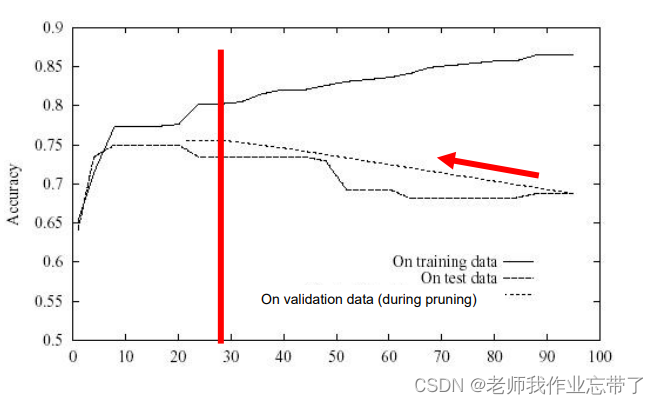
�Ӻ�ǰ,����֤����һ����֦��?
���֦: ������֦
1. ����ת���ɵȼ۵��ɹ��ɵļ���
????????? e.g. if (outlook=sunny)^ (humidity=high) then playTennis = no
2. ��ÿ��������м�֦,ȥ����Щ�ܹ������ù���ȷ�ʵĹ���ǰ��
????????? i.e. (outlook=sunny)60%, (humidity=high)85%,(outlook=sunny)^ ????????????????(humidity=high)80%
3. �����������һ������ (��֤��:���ݹ����ȷ�ʴӸ���������)
4. �ø������е����չ�����������з���(���β鿴�Ƿ������������,���ڹ�����һ��һ��������ֱ�����жϳ���)
(ע:�ڹ���֦��,�����ܲ����ָܻ���һ����)
һ�ֱ��㷺ʹ�õķ���,����C4.5
Ϊʲô�ڼ�֦ǰ��������ת��Ϊ����?
? ������������
????????? ����,�����������֦,������ѡ��:
????????????????? ��ȫɾ���ýڵ�
????????????????? ������
? �����ָ��ڵ��Ҷ�ڵ�
? �����ɶ���
?
�塢��չ: ��ʵ�����еľ�����ѧϰ
1. ��������ֵ

? ����һЩ��ɢ����ֵ,���仯,���ڽ�����֧
? ��ѡ�IJ���:
????????? I.ѡ�����ڵ��в�ͬ���ߵ�ֵ���м�ֵ?
? ? ? ? ? ??��ͼ48��60,80��90֮��yes no����,���ǿ���ȡ�м�ֵ
? ? ? ? ? ? (Fayyad ��1991��֤��������������������ֵ������Ϣ����IG���)
????????? II. ���Ǹ���??
? ? ? ? ? ? ?����̬�ֲ������ܶȺ���ͼ��,���䳤�̿��Բ�ͬ,�������/��������ͬ�ġ�
2. ���й���ȡֵ������
����:
? ƫ��: ��������кܶ�ֵ,������Ϣ����IG,�����ȱ�ѡ��
????????? e.g. �����˶���������,��һ�����ÿһ����Ϊ����(�ֱ��������)
? һ�����ܵĽ������: �� GainRatio (�����)�����

3. δ֪����ֵ
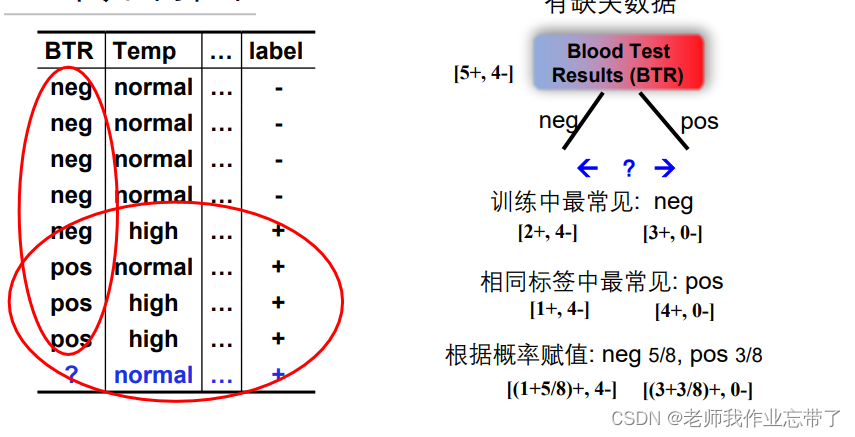
�е��������Dz�֪����ʲô,���Ѳ�֪����ѡ�ɳ�����,���߸��ݸ��ʸ�ֵ��
4. �д��۵�����

�����feature��,IG���Գ���һ���ͷ���,�д��ۿ��Գ���cost...
?
����������Ϣ
? ���������������Ƶ��ʹ�õ��㷨
????????? ��������
????????? ����ʵ��
????????? ����ʹ��
????????? ���㿪��С
? ����ɭ��:
????????? ��C4.5���������������
? ���µ��㷨:C5.0 http://www.rulequest.com/see5-info.html
? Ross Quinlan����ҳ: http://www.rulequest.com/Personal/
?
?