论文题目:End-to-End Object Detection with Transformers
论文链接:DETR
摘要:
??提出新的方法,直接将目标检测视为一个集合预测的问题(其实无论proposal,anchor,window centers方法本质上都是集合预测的方法,用大量的先验知识去人工干预,例如NMS);而DETR是纯end-to-end,整个训练都是不需要人工提前干预。DETR训练步骤有:(1)CNN为backbone去抽特征(2)Transformer encoder学全局特征(3)transformer decoder生成预测框(100)(4)预测框和GT做匹配文章亮点。推理的时候不需要(4),生成预测框后通过阈值判断再输出。
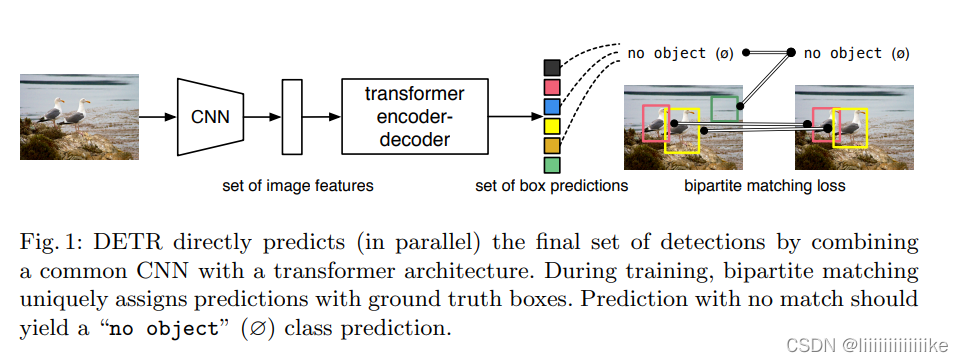
简介
??DETR采用一种基于transformer的编码器-解码器结构,利用自注意力机制来显示编码序列中所有元素间的相互作用,这样做的好处是可以删除目标检测中产生的冗余框!!,DETR一次性预测所有目标,并通过集合损失函数进行端到端的训练,该函数在预测结果和真实结果之间进行二部图匹配。(例如产生100框,GT为10,计算预测和GT最match的10框,我们认为其是正样本,其余90均为负样本,这样不需要NMS)
相关工作
DETR工作建立在:(1)用于集合预测的二部图匹配损失 (2)transformer encoder-decoder (3)并行解码和目标检测。
(1)集合预测
目前大部分检测器需要使用后处理NMS来去除冗余框。但是直接进行集合预测不需要后处理,全局推理模式来模拟所有预测元素之间的相互作用,可以避免冗余。对于常数集的集合预测,MLP就ok了(暴力:每一个都算匹配程度),但是成本高。通常解决方案是匈牙利算法基础上设计一个损失,以找到真实值与预测值之间的二部匹配。
(2)Transformer结构
注意力机制可以从整个输入序列中聚集信息。基于自注意力的模型主要优点之一:是其全局计算和完美记忆性。(感受野!)
(3)目标检测
大多数目标检测主要是proposal,anchor,window center来进行预测,但是由于产生了很多冗余的框,这里就不得不使用NMS。而DETR可以去除NMS从而达到end-to-end。
DETR模型
在目标检测模型中,有两个因素对直接集合预测至关重要:
(1)集合预测损失,它强制保证预测和GT之间的唯一匹配
(2)一次性预测一组对象并对它们之间的关系建模
集合预测损失
在一次decoder过程中,DETR推荐出N个结果的预测集合,N类似给图片分配N个框。训练的主要难点之一是根据真实值对预测对象(类别,位置,大小)进行评分。论文设置了预测目标和GT之间的最佳二部匹配,然后优化特定目标边界框的损失。
- 第一步是得到唯一的二部匹配代价,为了在预测框和真实框之间找到一个二部匹配(类似:3个工人,A适合1任务,B适合2任务,C适合3任务,怎么分配代价最小),寻找一个N个元素排列使得开销最小。(即最优分配)
前人工作,匈牙利算法
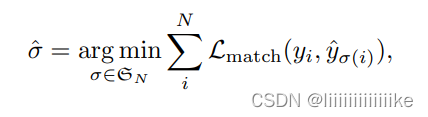
论文:真值集合中的每个元素i可以被看作是yi =( ci,bi ),ci是目标类标签(注意可能是 ?);bi是一个向量 [0, 1]^4,定义了b-box的中心坐标和其相对于图像大小的高度和宽度。

- 第二步是计算损失函数,即前一步所有匹配对的匈牙利损失。我们对损失的定义类似于一般的目标检测器的损失,即类预测的负对数似然和后面定义的检测框损失Lbox的线性组合:
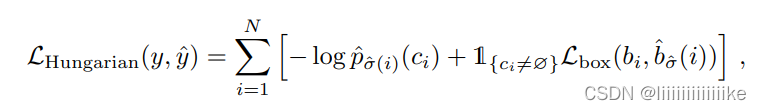
3. 边界框损失:
对边界框进行评分。不像许多检测器通过一些最初的猜测做边界框预测,我们直接做边界框预测。虽然这种方法简化了实现,但它提出了一个相对缩放损失的问题。最常用的L1损失对于小边界框和大边界框有不同的尺度,即使它们的相对误差是相似的。为了缓解这个问题,我们使用L1损失和尺度不变的广义IoU损失的线性组合。
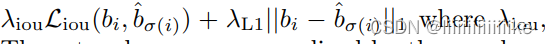
DETR框架
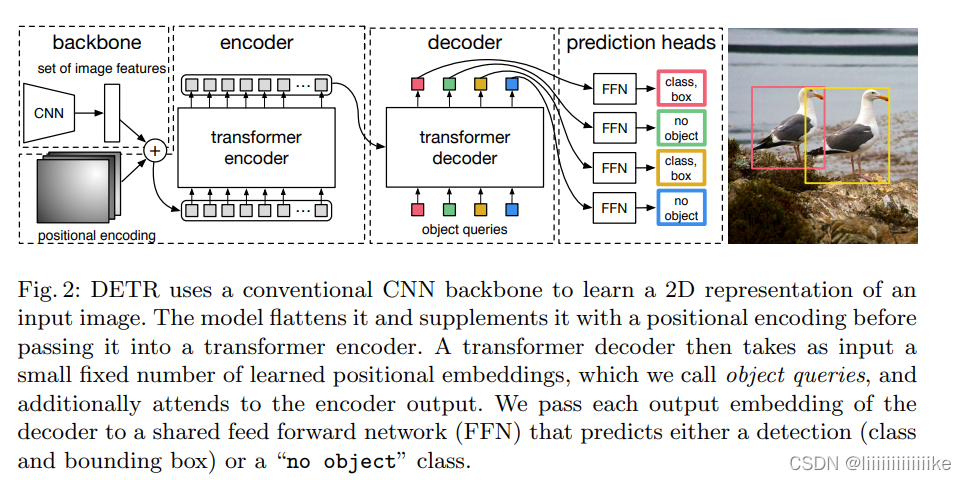
backbone:
初始图像:H * W *3,经过传统的CNN生成一个低分辨率的特征图(H/32, W/32,2048)
Transformer encoder:
首先利用1*1 conv降维成(H/32, W/32,256),将该特征图拉成序列,方便作为transformer的输入,每个编码器都有一个标准结构,由一个多头自注意力模块和一个FFN(MLP)组成。由于transformer架构是对顺序不敏感的,我们用固定位置编码对其进行补充,并将其添加到每个注意力层的输入。
Transformer decoder:
解码器遵循transformer的标准架构,转换为尺寸为d的N个嵌入。与原始Transformer不同在于,每一个解码器都是并行解码N个对象。由于解码器是不变的,所以N个输入嵌入必须不同才能产生不同的结果,这些输入嵌入就是学习到的位置编码,成为object queries。跟encoder一样,将其添加到decoder中。然后通过FFN,将它们独立解码为框坐标和类标签,最终得到N个预测。对这些嵌入使用自注意力和encoder-decoder,模型利用所有对象之间的成对关系进行全局推理,同时能够使用整个图像作为上下文!!
FFN:
最后预测是由一个Relu、3层的MLP和一个线性投射层计算的。FFN预测输入图像的归一化中心坐标、框的高度和宽度,线性层使用softmax函数预测类标签。由于预测了一个包含固定大小N个边界框的集合,其中N通常比图像中GT数量大得多,因此使用一个额外的特殊类标签来表示此位置没有检测到目标。
在训练过程中,辅助编码损失在解码器中是很有帮助的,特别是在帮助模型输出每个类对象的正确数量方面,在每个编码器层后加入预测FFS和匈牙利损失。所有预测FFN都共享参数。