ЪЖБ№ЪжаДЪ§зжЪЧЩюЖШбЇЯАжаБШНЯЛљДЁЕФЯюФП,МђЕЅРДЫЕ,ЪжаДЪ§зжЪЖБ№ЯрЕБгкЪЧГЬађЩшМЦгябдРяЕФ Hello World ШЮЮё,гУгкЖд 0 ~ 9 ЕФЪЎРрЪ§зжНјааЗжРр,МДЪфШыЪжаДЪ§зжЕФЭМЦЌ,ЪЙЕУМЦЫуЛњФмЙЛЪЖБ№ГіетИіЭМЦЌжаЕФЪ§зжЁЃЬ§Ц№РДЪЕЯжИУЙІФмПЩФмОрРыЮвУЧБШНЯвЃдЖ,ЕЋЪЧжЛвЊФуСЫНтЕНpaddlepaddleЩюЖШбЇЯАПђМм,ЯраХФуОЭжЊЕРЪЕЯжетИіШЮЮёЪЧЖрУДЧсЫЩМггфПь!

1.ЛЗОГДюНЈ
дкЭъГЩетИіШЮЮёжЎЧА,ЮвУЧашвЊАВзАВЂЕМШыЗЩНЌПтЁЃ
дкPyCharmБрвыЦїжа,ДђПЊжеЖЫ,дкУќСюааЪфШыШчЯТУќСю
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddlepaddle
ЯТдиВЂАВзАЭъБЯКѓ,ЮвУЧПЩвдДДНЈpythonЯюФП,ЕМШыВЂМьбщpaddlepaddleЪЧЗёАВзАГЩЙІ,ОпЬхДњТыШчЯТЫљЪО
import paddle
print(paddle.__version__)
дЫаааЇЙћФмЙЛе§ШЗЪфГіpaddleЕФАцБОКХМДБэЪОМьбщЭЈЙ§,МДАВзАГЩЙІ!
ШчЙћдкЛЗОГДюНЈЕФЙ§ГЬжагіЕНTypeError: Descriptors cannot not be created directlyЕФДэЮѓ,НтОіЗНАИЧыВЮПМВЉПЭНтОіЗНАИЁЃ
2.Ъ§ОнМЏЖЈвхгыМгди
дкАйЖШЗЩНЌжа,MNISTЪЧвЛИіЪжаДЬхЪ§зжЕФЭМЦЌЪ§ОнМЏ,MNISTЪЧЩюЖШбЇЯАСьгђБъзМЁЂвзгУЕФГЩЪьЪ§ОнМЏ,ИУЪ§ОнМЏРДгЩУРЙњЙњМвБъзМгыММЪѕбаОПЫљ(National Institute of Standards and Technology (NIST))ЗЂЦ№ећРэ,вЛЙВЭГМЦСЫРДзд250ИіВЛЭЌЕФШЫЪжаДЪ§зжЭМЦЌ,Цфжа50%ЪЧИпжаЩњ,50%РДздШЫПкЦеВщОжЕФЙЄзїШЫдБЁЃИУЪ§ОнМЏЕФЪеМЏФПЕФЪЧЯЃЭћЭЈЙ§ЫуЗЈ,ЪЕЯжЖдЪжаДЪ§зжЕФЪЖБ№ЁЃ
дкБОШЮЮёжа,ЮвЯШКѓМгдиСЫ MNIST бЕСЗМЏ(mode=ЁЎtrainЁЏ)КЭВтЪдМЏ(mode=ЁЎtestЁЏ),бЕСЗМЏгУгкбЕСЗФЃаЭ,ВтЪдМЏгУгкЦРЙРФЃаЭаЇЙћЁЃИУЪ§ОнМЏАќКЌ60000еХбЕСЗЭМЦЌ,10000еХВтЪдЭМЦЌ,ЭМЦЌЕФЗжБцТЪЮЊ28*28,вдМАЖдгІЕФЗжРрБъЧЉЮФМўЁЃВПЗжЭМЦЌвдМАЖдгІЕФЗжРрБъЧЉШчЯТЭМЫљЪО:

ОпЬхМгдиmnistЪ§ОнМЏЕФДњТыШчЯТЫљЪО:
import paddle
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# ЯТдиЪ§ОнМЏВЂГѕЪМЛЏ DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# ДђгЁЪ§ОнМЏРяЭМЦЌЪ§СП
print('{} images in train_dataset, {} images in test_dataset'.format(len(train_dataset
NormalizeКЏЪ§ЕФзїгУЪЧЪЙЕУУЛгаПЩБШадЕФЪ§ОнБфЕУОпгаПЩБШад,ЭЌЪБгжБЃГжЯрБШНЯЕФСНИіЪ§ОнжЎМфЕФЯрЖдЙиЯЕЁЃЦфЪЕ,ВщПДдДТыОЭЛсЗЂЯж,ЙщвЛЛЏОЭЪЧНЋЧѓГіФГвЛжжЪ§ОнЕФОљжЕгыЗНВю,НЋУПвЛИіЪ§ОнМѕШЅОљжЕ,ШЛКѓдкГ§ШЅБъзМВюКѓЕУЕНЕФБъзМЛЏЪ§ОнЁЃ
paddle.vision.datasets.MNIST(mode=ЁЎtrainЁЏ, transform=transform)ЪЧЮЊСЫМгдиMINSTЕФ60000аабЕСЗМЏЪ§ОнВЂЖдЪ§ОнНјааЙщвЛЛЏ;paddle.vision.datasets.MNIST(mode=ЁЎtestЁЏ, transform=transform)ЪЧМгдиMINSTЕФ10000ааВтЪдМЏЪ§ОнВЂНјааЙщвЛЛЏЁЃ
3.ФЃаЭзщЭј
ЗЩНАЕФФЃаЭзщЭјгаЖржжЗНЪН,МШПЩвджБНгЪЙгУЗЩНАФкжУЕФФЃаЭ,вВПЩвдздЖЈвхзщЭјЁЃ
ЁКЪжаДЪ§зжЪЖБ№ШЮЮёЁЛБШНЯМђЕЅ,ЦеЭЈЕФЩёОЭјТчОЭФмДяЕНКмИпЕФОЋЖШ,дкБОШЮЮёжаЪЙгУСЫЗЩНАФкжУЕФ LeNet зїЮЊФЃаЭЁЃЗЩНАдк paddle.vision.models ЯТФкжУСЫ CV(Computer Vision) МЦЫуЛњЪгЭМСьгђЕФвЛаЉОЕфФЃаЭ,LeNet ОЭЪЧЦфжажЎвЛ,ЕїгУКмЗНБу,жЛашвЛааДњТыМДПЩЭъГЩ LeNet ЕФЭјТчЙЙНЈКЭГѕЪМЛЏЁЃnum_classes зжЖЮжаЖЈвхЗжРрЕФРрБ№Ъ§,вђЮЊашвЊЖд 0 ~ 9 ЕФЪЎРрЪ§зжНјааЗжРр,ЫљвдЩшжУЮЊ 10ЁЃ
СэЭтЭЈЙ§ paddle.summary ПЩЗНБуЕиДђгЁЭјТчЕФЛљДЁНсЙЙКЭВЮЪ§аХЯЂЁЃ
paddle.summary(net, input_size=None, dtypes=None, input=None)
ВЮЪ§ЫЕУї:
net (Layer) - ЭјТчЪЕР§,БиаыЪЧ Layer ЕФзгРрЁЃ
input_size (tuple|InputSpec|list[tuple|InputSpec) - ЪфШыеХСПЕФДѓаЁЁЃШчЙћЭјТчжЛгавЛИіЪфШы,ФЧУДИУжЕашвЊЩшЖЈЮЊtupleЛђInputSpecЁЃШчЙћФЃаЭгаЖрИіЪфШыЁЃФЧУДИУжЕашвЊЩшЖЈЮЊlist[tuple|InputSpec],АќКЌУПИіЪфШыЕФshapeЁЃФЌШЯжЕ:NoneЁЃ
dtypes (str,ПЩбЁ) - ЪфШыеХСПЕФЪ§ОнРраЭ,ШчЙћУЛгаИјЖЈ,ФЌШЯЪЙгУ float32 РраЭЁЃФЌШЯжЕ:NoneЁЃ
input (tensor,ПЩбЁ) - ЪфШыеХСПЪ§Он,ШчЙћИјГі input ,ФЧУД input_size КЭ dtypes ЕФЪфШыНЋБЛКіТдЁЃФЌШЯжЕ:NoneЁЃ
# ФЃаЭзщЭјВЂГѕЪМЛЏЭјТч
lenet = paddle.vision.models.LeNet(num_classes=10)
# ПЩЪгЛЏФЃаЭзщЭјНсЙЙКЭВЮЪ§
paddle.summary(lenet,(1, 1, 28, 28))
4.ФЃаЭбЕСЗгыЦРЙР
ФЃаЭбЕСЗашЭъГЩШчЯТВНжш:
ЪЙгУ paddle.Model ЗтзАФЃаЭЁЃ НЋЭјТчНсЙЙзщКЯГЩПЩПьЫйЪЙгУ ЗЩНАИпВу API НјаабЕСЗЁЂЦРЙРЁЂЭЦРэЕФЪЕР§,ЗНБуКѓајВйзїЁЃ
ЪЙгУ paddle.Model.prepare ЭъГЩбЕСЗЕФХфжУзМБИЙЄзїЁЃ АќРЈЫ№ЪЇКЏЪ§ЁЂгХЛЏЦїКЭЦРМлжИБъЕШЁЃЗЩНАдк paddle.optimizer ЯТЬсЙЉСЫгХЛЏЦїЫуЗЈЯрЙи API,дк paddle.nn LossВу ЬсЙЉСЫЫ№ЪЇКЏЪ§ЯрЙи API,дк paddle.metric ЯТЬсЙЉСЫЦРМлжИБъЯрЙи APIЁЃ
ЪЙгУ paddle.Model.fit ХфжУбЛЗВЮЪ§ВЂЦєЖЏбЕСЗЁЃ ХфжУВЮЪ§АќРЈжИЖЈбЕСЗЕФЪ§ОндД train_datasetЁЂбЕСЗЕФХњДѓаЁ batch_sizeЁЂбЕСЗТжЪ§ epochs ЕШ,жДааКѓНЋздЖЏЭъГЩФЃаЭЕФбЕСЗбЛЗЁЃ
вђЮЊЪЧЗжРрШЮЮё,етРяЫ№ЪЇКЏЪ§ЪЙгУГЃМћЕФ CrossEntropyLoss (НЛВцьиЫ№ЪЇКЏЪ§),гХЛЏЦїЪЙгУ Adam,ЦРМлжИБъЪЙгУ Accuracy РДМЦЫуФЃаЭдкбЕСЗМЏЩЯЕФОЋЖШЁЃ
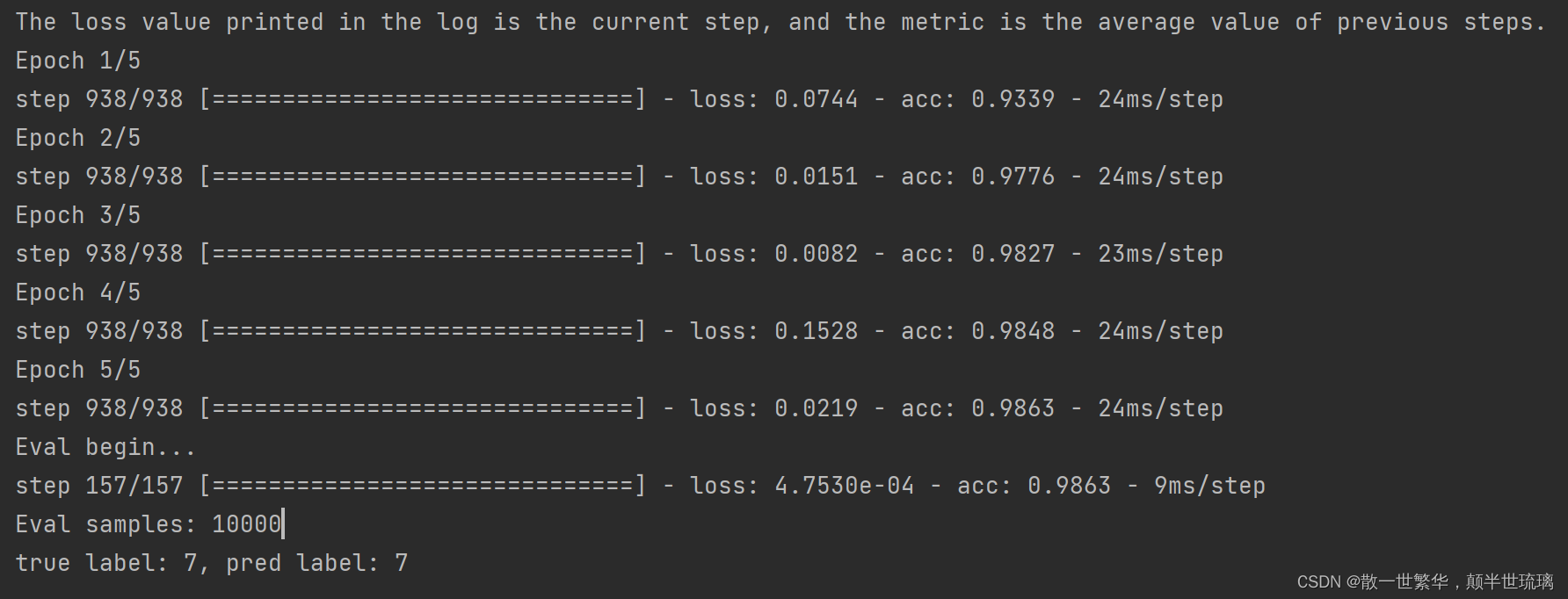
ФЃаЭбЕСЗЭъГЩжЎКѓ,ЕїгУ paddle.Model.evaluate ,ЪЙгУдЄЯШЖЈвхЕФВтЪдЪ§ОнМЏ,РДЦРЙРбЕСЗКУЕФФЃаЭаЇЙћ,ЦРЙРЭъГЩКѓНЋЪфГіФЃаЭдкВтЪдМЏЩЯЕФЫ№ЪЇКЏЪ§жЕ loss КЭОЋЖШ accЁЃ
# ЗтзАФЃаЭ,БугкНјааКѓајЕФбЕСЗЁЂЦРЙРКЭЭЦРэ
model = paddle.Model(lenet)
# ФЃаЭбЕСЗЕФХфжУзМБИ,зМБИЫ№ЪЇКЏЪ§,гХЛЏЦїКЭЦРМлжИБъ
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# ПЊЪМбЕСЗ
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# НјааФЃаЭЦРЙР
model.evaluate(test_dataset, batch_size=64, verbose=1)
5.ФЃаЭЭЦРэ
жДааФЃаЭЭЦРэЪБ,ПЩЭЈЙ§ paddle.Model.predict_batch жДааЭЦРэВйзїЁЃ
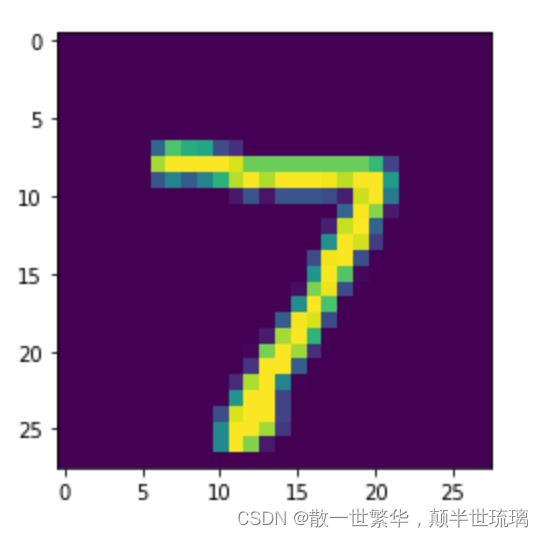
ШчЯТЪОР§жа,бЁдёВтЪдМЏжаЕФвЛеХЭМЦЌ test_dataset[0] зїЮЊЪфШы,жДааЭЦРэВЂДђгЁНсЙћ,МьбщЭЦРэЕФНсЙћгыПЩЪгЛЏЭМЦЌЪЧЗёвЛжТЁЃ
# ДгВтЪдМЏжаШЁГівЛеХЭМЦЌ
img, label = test_dataset[0]
# НЋЭМЦЌshapeДг1*28*28БфЮЊ1*1*28*28,діМгвЛИіbatchЮЌЖШ,вдЦЅХфФЃаЭЪфШыИёЪНвЊЧѓ
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# жДааЭЦРэВЂДђгЁНсЙћ,ДЫДІpredict_batchЗЕЛиЕФЪЧвЛИіlist,ШЁГіЦфжаЪ§ОнЛёЕУдЄВтНсЙћ
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# ПЩЪгЛЏЭМЦЌ
from matplotlib import pyplot as plt
plt.imshow(img[0])
plt.show()
6.ШЋВПДњТыеЙЪО
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
# ЖдЪ§ОнНјааЙщвЛЛЏ
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# ЯТдиЪ§ОнМЏВЂГѕЪМЛЏ DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# ФЃаЭзщЭјВЂГѕЪМЛЏЭјТч
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# ФЃаЭбЕСЗЕФХфжУзМБИ,зМБИЫ№ЪЇКЏЪ§,гХЛЏЦїКЭЦРМлжИБъ
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# ФЃаЭбЕСЗ
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# ФЃаЭЦРЙР
model.evaluate(test_dataset, batch_size=64, verbose=1)
# ДгВтЪдМЏжаШЁГівЛеХЭМЦЌ
img, label = test_dataset[0]
# НЋЭМЦЌshapeДг1*28*28БфЮЊ1*1*28*28,діМгвЛИіbatchЮЌЖШ,вдЦЅХфФЃаЭЪфШыИёЪНвЊЧѓ
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# жДааЭЦРэВЂДђгЁНсЙћ,ДЫДІpredict_batchЗЕЛиЕФЪЧвЛИіlist,ШЁГіЦфжаЪ§ОнЛёЕУдЄВтНсЙћ
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# ПЩЪгЛЏЭМЦЌ
from matplotlib import pyplot as plt
plt.imshow(img[0])
plt.show()
дЫааНсЙћеЙЪО: