用PyTorch实现基于神经网络的图像风格迁移
风格迁移,又称为风格转换。只需要给定原始图片,并选择艺术家的风格图片,就能把原始图片转换成具有相应艺术家风格的图片。图像的风格迁移始于2015年Gatys的论文“Image Style Transfer Using Convolutional Neural Networks”,所做的工作就是由一张内容图片和一张风格图片进行融合之后,得到经风格渲染之后的合成图片。示例如下:

1. 风格迁移原理介绍
风格迁移中有两类图片:一类是风格图片,通常是一些艺术家的作品,往往具有明显的艺术家风格,包括色彩、线条、轮廓等;另一类是内容图片,这些图片往往来自现实世界,如个人摄影等。利用风格迁移能够将内容图片转换成具有艺术家风格的图片。
Gatys等人提出的方法被称为Neural Style,但是他们在实现上过于复杂。Justin Johnson等提出了一种快速实现风格迁移的算法,称为Fast Neural Style。当用Fast Neural Style训练好一个风格的模型之后,通常只需要GPU运行几秒,就能生成对应的风格迁移效果。
Fast Neural Style 和Neural Style主要有以下两点区别:
(1)Fast Neural Style针对每一个风格图片训练一个模型,而后可以反复使用,进行快速风格迁移。Neural Style不需要专门训练模型,只需要从噪声中不断地调整图像的像素值,指导最后得到结构,速度较慢,需要十几分钟到几十分钟不等。
(2)普遍认为Neural Style生成的图片的效果会比Fast Neural Style的效果好。
这里主要介绍Fast Neural Style的实现。
要产生效果逼真的风格迁移图片,有两个要求:
- 要生成的图片在内容、细节上尽可能地与输入的内容图片相似;
- 要生成的图片在风格上尽可能地与风格图片相似。
相应地,定义两个损失content loss和style loss,分别用来衡量上述两个指标。
- content loss 比较常用的做法是采用逐像素计算差值,又称pixel-wise loss,追求生成的图片和原始图片逐像素的差值尽可能小。但是这种方法有诸多不合理之处,Justin提出了一种更好的计算content loss的方法,称为perceptual loss。不同于pixel-wise loss计算像素层面的差异,perceptual loss计算的是图像在更高层语义层次上的差异。使用预训练好的神经网络的高层作为图片的知觉特征,进而计算二者的差异值作为perceptual loss。
在进行风格迁移时,并不要求生成图片的像素和原始图片中的每一个像素都一样,追求的是生成图片和原图片具有相同的特征。
一般使用Gram矩阵来表示图像的风格特征。对于每一张图片,卷积层的输出形状为
C
×
H
×
W
C\times H\times W
C×H×W,C是卷积核的通道数,一般称为有C个卷积核,每个卷积核学习图像的不同特征。每一个卷积核输出的
H
×
W
H\times W
H×W代表这张图像的一个feature map,可以认为是一张特殊的图像――原始彩色图像可以看作RGB三个feature map拼接组成的特殊feature map。通过计算每个feature map之间的相似性,就可以得到图像的风格特征。对于一个
C
×
H
×
W
C\times H\times W
C×H×W的feature maps
F
F
F,Gram Matrix的形状为
C
×
C
C\times C
C×C,其第
i
,
j
i,j
i,j个元素
G
i
,
j
G_{i,j}
Gi,j?的计算方式如下:
G
i
,
j
=
∑
k
F
i
k
F
j
k
G_{i,j}=\sum_{k}F_{ik}F_{jk}
Gi,j?=k∑?Fik?Fjk?
其中
F
i
k
F_{ik}
Fik?代表第i个feature map的第k个像素点。
需要注意的是:
- Gram Matrix的计算采用了累加的形式,抛弃了空间信息。
- Gram Matrix的结果与feature maps F的尺度无关,只与通道数有关。无论H,W的大小如何,最后Gram Matrix的形状都是C×C。
- 对于一个 C × H × W C\times H\times W C×H×W的feature maps,可以通过调整形状和矩阵乘法快速计算它的Gram Matrix,即先将F调整为 C × ( H W ) C\times (HW) C×(HW)的二维矩阵,然后再计算 F ? F T F\cdot F^T F?FT,结果就是Gram Matrix。
实践证明利用Gram Matrix表征图像的风格特征在风格迁移、纹理合成等任务中表现十分出众。总之:
- 神经网络的高层输出可以作为图像的知觉特征描述
- 神经网络的高层输出的Gram Matrix可以作为图像的风格特征描述。
- 风格迁移的目标是使生成图片和原图片的知觉特征尽可能相似,并且和风格图片的风格特征尽可能地相似。
2. Fast Neural Style网络结构
Fast Neural Style专门涉及了一个网络用来进行风格迁移,输入原图片,网络将自动生成目标图片。如下图所示:
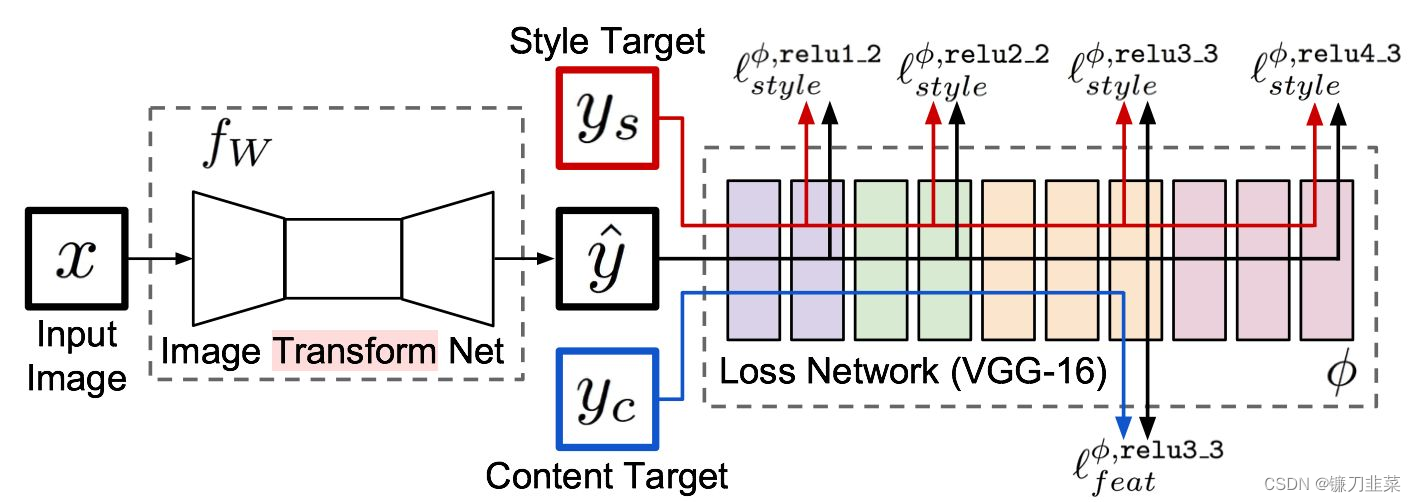
整个网络是由两部分组成:Image transformation network、 Loss Netwrok;
- Image Transformation network是一个deep residual conv netwrok,用来将输入图像(content image)直接transform为带有style的图像;
- 而loss network参数是fixed的,这里的loss network和 A Neural Algorithm of Artistic Style 中的网络结构一致,只是参数不做更新(neural style的weight也是常数,不同的是像素级loss和per loss的区别,neural style里面是更新像素,得到最后的合成后的照片),只用来做content loss 和style loss的计算,这个就是所谓的perceptual loss,
一个是生成图片的网络,就是图片中前面那个,主要用来生成图片,其后面的是一个VGG网络,主要是提取特征,其实就是用这些特征计算损失的,我们训练的时候只训练前面这个网络,后面的使用基于ImageNet训练好的模型,直接做特征提取。
如上图所示,
x
x
x是输入图像,在风格迁移任务中
y
c
=
x
y_c=x
yc?=x,
y
s
y_s
ys?是风格图片,Image Transform Net
f
W
f_W
fW?是我们涉及的风格迁移网络,针对输入的图像
x
x
x,能够返回一张新的图像
y
^
\hat{y}
y^?,
y
^
\hat{y}
y^?在图像内容上与
y
c
y_c
yc?相似,但在风格上与
y
s
y_s
ys?相似。损失网络(loss network)不用训练,只是用来计算知觉特征和风格特征。损失网络采用ImageNet上预训练好的VGG-16。
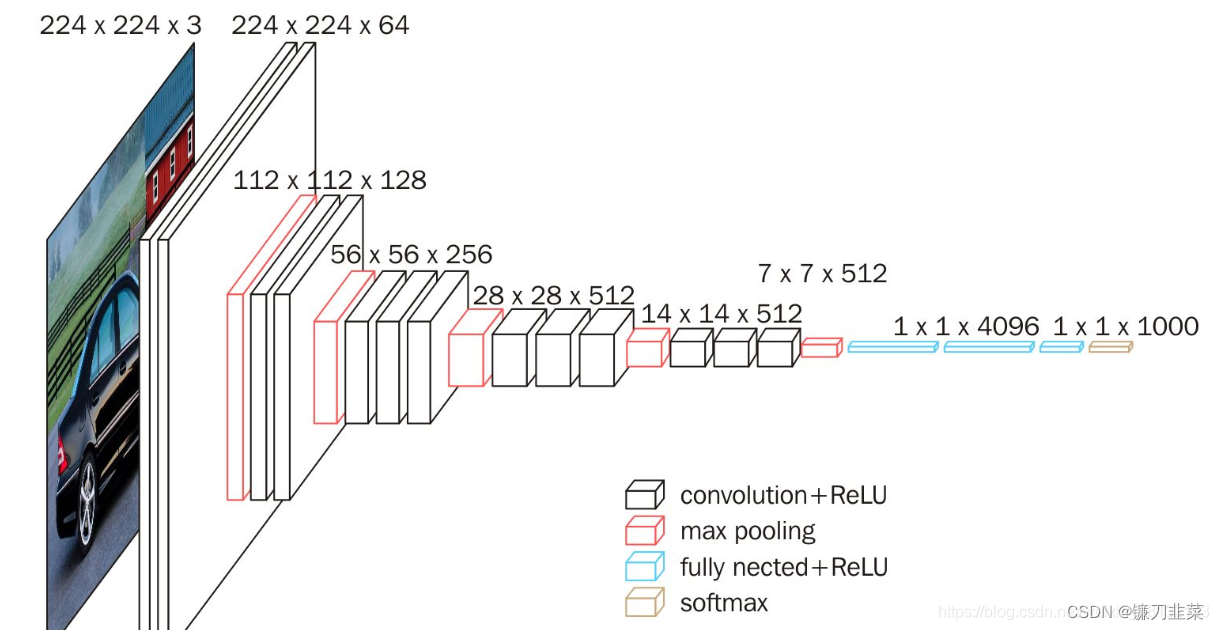
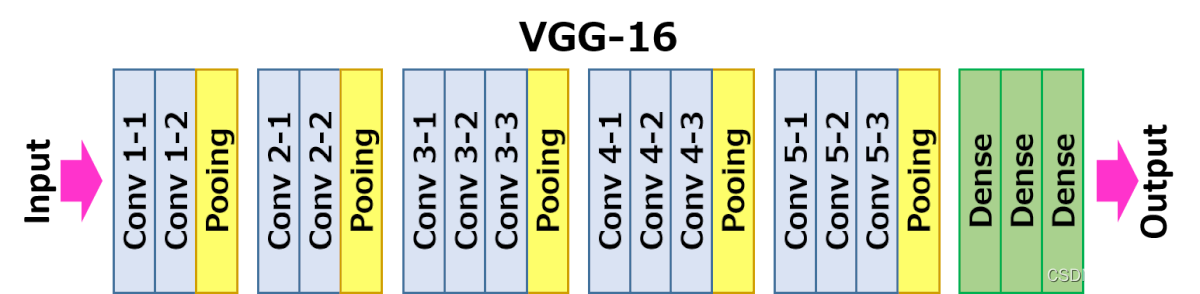
网络从左到右有5个卷积块,两个卷积块之间通过MaxPooling层区分,每个卷积块有2~3个卷积层,每一个卷积层后面都跟着一个ReLU激活曾。其中relu2_2表示第2个卷积块的第2个卷积层的激活层(ReLU)输出。
Fast Neural Style的训练步骤如下:
(1)输入一张图片x到
f
W
f_W
fW?中,得到结果
y
^
\hat{y}
y^?;
(2)将
y
^
\hat{y}
y^?和
y
c
y_c
yc?(其实就是x)输入到loss network(VGG-16)中,计算它在relu3_3的输出,并计算它们之间的均方误差作为content loss。
(3)将
y
^
\hat{y}
y^?和
y
s
y_s
ys?(风格图片)输入到loss network中,计算它在relu1_2,relu2_2,relu3_3和relu4_3的输出,再计算它们的Gram Matrix的均方误差作为style loss。
(4)两个损失相加,并反向传播。更新
f
W
f_W
fW?的参数,固定loss network不动。
(5)跳回第一步,继续训练
f
W
f_W
fW?。
先了解全卷积网络的结构。输入是图片,输出也是图片,对这种网络一般实现为一个全部都是卷积层而没有全连接层的网络结构。对于卷积层,当输入feature map(或者图片)的尺寸为
C
i
n
×
H
i
n
×
W
i
n
C_{in}\times H_{in}\times W_{in}
Cin?×Hin?×Win?,卷积核有
C
o
u
t
C_{out}
Cout?个,卷积核尺寸为
K
K
K,padding大小为
P
P
P、步长为
S
S
S时,输出的feature maps的形状为
C
o
u
t
×
H
o
u
t
×
W
o
u
t
C_{out}\times H_{out}\times W_{out}
Cout?×Hout?×Wout?,其中
H
o
u
t
=
f
l
o
o
r
(
H
i
n
+
2
?
P
?
K
)
/
S
+
1
H_{out}=floor(H_{in}+2\ast P-K)/S+1
Hout?=floor(Hin?+2?P?K)/S+1
W
o
u
t
=
f
l
o
o
r
(
W
i
n
+
2
?
P
?
K
)
/
S
+
1
W_{out}=floor(W_{in}+2\ast P-K)/S+1
Wout?=floor(Win?+2?P?K)/S+1
如果输入图片的尺寸是3×256×256,第一层卷积的卷积核大小为3,padding为1,步长为2,通道数为128,那么输出的feature map形状,按照上述公式计算结果就是:
H
o
u
t
=
f
l
o
o
r
(
256
+
2
?
1
?
3
)
/
2
+
1
=
128
H_{out} = floor(256+2\ast 1-3)/2+1=128
Hout?=floor(256+2?1?3)/2+1=128
W
o
u
t
=
f
l
o
o
r
(
256
+
2
?
1
?
3
)
/
2
+
1
=
128
W_{out} =floor(256+2\ast 1-3)/2+1=128
Wout?=floor(256+2?1?3)/2+1=128
所以最后的输出是
C
o
u
t
×
H
o
u
t
×
W
o
u
t
=
128
×
128
×
128
C_{out}\times H_{out}\times W_{out}=128\times 128\times 128
Cout?×Hout?×Wout?=128×128×128,即尺度缩小一半,通道数增加。如果把步长由2改成1,则输出的形状就是128×256×256,即尺度不变,只是通道数增加。
除了卷积层之外,还有一种叫做转置卷积层(Transposed Convolution),也有人称之为反卷积(DeConvolution),它可以简单地看成是卷积操作的逆运算。对于卷积操作,当步长大于1时,执行的是类似下采样的操作,而对于转置卷积,当步长大于1时,执行的是类似于上采样的操作。全卷积网络的一个重要优势在于对输入的尺寸没有要求,这样在进行风格迁移时就能够接受不同分辨率的图片。
论文中提到的风格迁移结构全部由卷积层、Batch Normalization和激活层组成,不包含全连接层,这里我们不使用Batch Normalization,取而代之的是Instance Normalization。
Instance Normalization和Batch Normalization的唯一区别就在于InstaneNorm只对每一个样本求均值和方差,而BatchNorm则会对一个batch中所有的样本求均值。
例如对于一个B×C×H×W的tensor,在Batch Normalization中计算均值时,就会计算B×H×W个数的均值,共有C个均值,而Instance Normalization会计算H×W个数的均值,即共有B×C个均值。
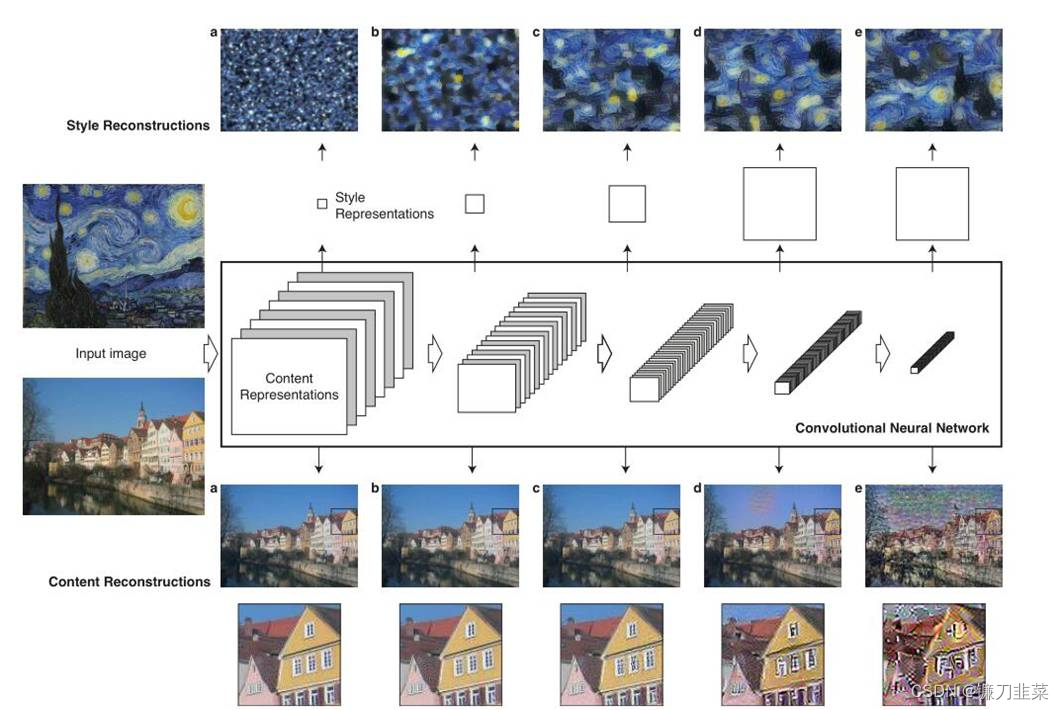
如上图所示,最左侧的两张图片(input image)一张是作为内容输入,一张是作为风格输入,分别经过VGG16的5个block,由浅及深可以看出,得到的特征图(feature map)的高和宽逐渐减小,但是深度是逐渐加大,Gatys为了更直观地让人看到每个block提取到的特征,所以做了一个trick,即特征重建,把提取到的特征做了一个可视化。但是可以看出,**对于内容图片特征的提取在很大程度上是保留了原图的信息,但是对于风格图片来说,基本上看不出原图的样貌,而是可以粗略的认为提取到了风格。这是为什么呢?**原来对于这两张图片做的特征提取处理是不一样的,在下一张图就可以看出。
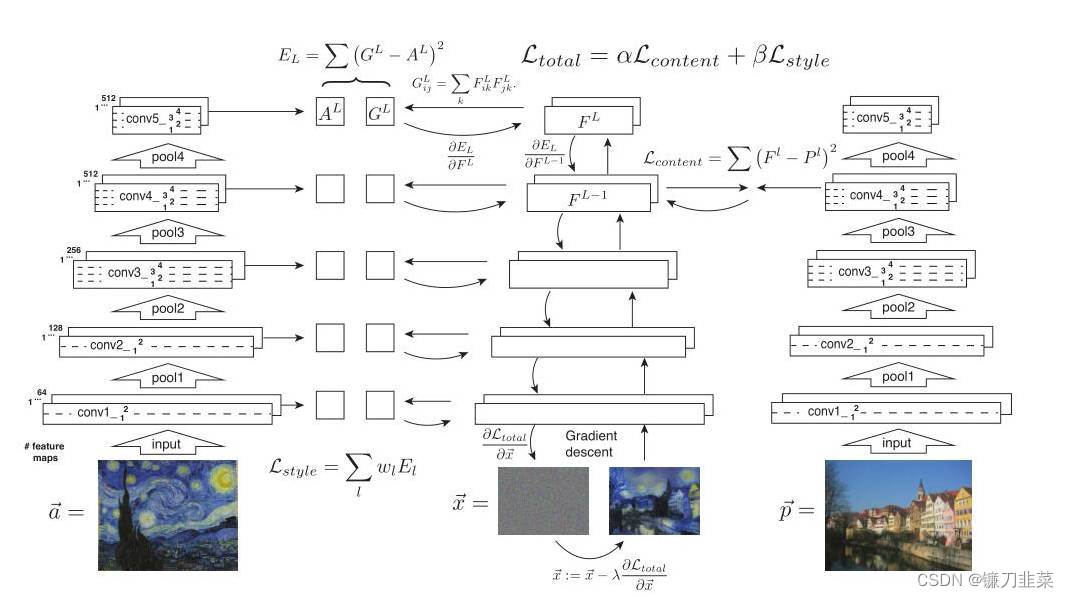
两侧的图片分别是风格图片,记为
a
→
\overrightarrow{a}
a,和内容图片
p
→
\overrightarrow{p}
p?,同时还需要有第三张随机产生的噪声图片,需要不断地在噪声图片上迭代,直到得到结合了内容和风格的合成图片。内容图片
p
→
\overrightarrow{p}
p?经过VGG16网络的5个block会在每层都得到feature map,记为
P
l
P^l
Pl,即第l个block得到的特征,噪声图片
x
→
\overrightarrow{x}
x经过VGG16网络的5个block得到的特征图记为
F
l
F^l
Fl。
对于内容损失,只取Conv4_2层的特征,计算内容图片特征和噪声图片特征之间的欧式距离,公式为:
L
c
o
n
t
e
n
t
(
p
→
,
x
→
,
l
)
=
1
2
∑
i
,
j
(
F
i
j
l
?
P
i
j
l
)
2
\mathcal{L}_{content}(\overrightarrow{p},\overrightarrow{x}, l)=\frac{1}{2}\sum_{i,j}(F_{ij}^l-P_{ij}^l)^2
Lcontent?(p?,x,l)=21?i,j∑?(Fijl??Pijl?)2
对于风格损失,计算方法有些不同。根据上面已知,噪声图片
x
→
\overrightarrow{x}
x经过VGG16网络的5个block得到的特征记为
F
l
F^l
Fl,
F
l
F^l
Fl的gram矩阵记为
G
l
G^l
Gl,风格图片
a
→
\overrightarrow{a}
a得到的特征图,再计算gram矩阵后得到的内容记为
A
l
A^l
Al,之后计算
G
l
G^l
Gl和
A
l
A^l
Al之间的欧式距离,其中gram矩阵的公式为:
KaTeX parse error: Can't use function '$' in math mode at position 9: G_{ij}^l$?=\sum_k F_{ik}^…
风格损失的公式为:
E
l
=
1
4
N
l
2
M
l
2
∑
i
,
j
(
G
i
j
l
?
A
i
j
l
)
2
E_l=\frac{1}{4N_l^2M_l^2}\sum_{i,j}(G_{ij}^l-A_{ij}^l)^2
El?=4Nl2?Ml2?1?i,j∑?(Gijl??Aijl?)2
公式之前的系数是标准化操作,即除以面积的平方。
需要注意的是,在计算风格损失时,5个block提取的特征都用来计算了,而计算内容损失时,实际上只用了第四个block提取的特征。这是因为每个block提取到的风格特征都是不一样的,都参与计算可以增加风格的多样性,而内容图片每个block提取到的特征相差不大,所以只取一个就好。
总损失即为内容损失和风格损失的线性和,改变α和β的比重可以调整内容和风格的占比。
L
t
o
t
a
l
(
p
→
,
a
→
,
x
→
)
=
α
L
c
o
n
t
e
n
t
(
p
→
,
x
→
)
+
β
L
s
t
y
l
e
(
a
→
,
x
→
)
\mathcal{L}_{total}(\overrightarrow{p}, \overrightarrow{a}, \overrightarrow{x})=\alpha \mathcal{L}_{content}(\overrightarrow{p}, \overrightarrow{x})+\beta \mathcal{L}_{style}(\overrightarrow{a}, \overrightarrow{x})
Ltotal?(p?,a,x)=αLcontent?(p?,x)+βLstyle?(a,x)
代码中还使用了一个trick,总loss的计算还会加上一个total variation loss用来降噪,让合成的图片看起来更加平滑。
最后需要注意的是,Gatys计算出的total loss是对噪声图片 x → \overrightarrow{x} x求偏导,而Johnson计算出的loss是对自定义网络的权重w求偏导。
3. 用PyTorch实现风格迁移
数据集下载地址:https://pjreddie.com/projects/coco-mirror/

3.1 首先看看如何使用预训练的VGG。
class Vgg16(nn.Module):
def __init__(self, requires_grad=False):
super(Vgg16, self).__init__()
vgg_pretrained_ft = vgg16(pretrained=False)
vgg_pretrained_ft.load_state_dict(torch.load("vgg16-397923af.pth"))
vgg_pretrained_features = nn.Sequential(*list(vgg_pretrained_ft.features.children()))
self.slice1 = nn.Sequential()
self.slice2 = nn.Sequential()
self.slice3 = nn.Sequential()
self.slice4 = nn.Sequential()
for x in range(4):
self.slice1.add_module(str(x), vgg_pretrained_features[x])
for x in range(4, 9):
self.slice2.add_module(str(x), vgg_pretrained_features[x])
for x in range(9, 16):
self.slice3.add_module(str(x), vgg_pretrained_features[x])
for x in range(16, 23):
self.slice4.add_module(str(x), vgg_pretrained_features[x])
if not requires_grad:
for param in self.parameters():
param.requires_grad = False
def forward(self, X):
h = self.slice1(X)
h_relu1_2 = h
h = self.slice2(h)
h_relu2_2 = h
h = self.slice3(h)
h_relu3_3 = h
h = self.slice4(h)
h_relu4_3 = h
vgg_outputs = namedtuple('VggOutputs', ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3'])
result = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3)
return result
在风格迁移网络中,需要获得中间层的输出,因此需要修改网络的前向传播过程,将相应层的输出保存下来。同时有很多层不需要,可以删除以节省内容占用。
**在torchvision中, VGG的实现由两个nn.Sequential对象组成,一个是features,包含卷积、激活和MaxPool层,用来提取图片特征;另一个是classifier,包含全连接等,用来分类。**可以通过vgg.features直接获得对应的nn.Sequential对象。这样在前向传播时,当计算完指定层的输出后,就将结果保存于一个list中,然后再使用namedtuple进行名称绑定,这样可以通过output.relu1_2访问第一个元素,更为方便和直观。当然也可以利用layer.register_forward_hook的方式获取相应层的输出。
3.2 接下来要实现风格迁移网络
实现风格迁移网络参考了Pytorch的官方示例,其结构总结起来有以下几点:
- 先下采样,后上采样,使计算量变小
- 使用残差结构使网络变深
- 边缘补齐的方式不再是传统的补0,而是采用一种被称为Reflection Pad的补齐策略:上下左右反射边缘的像素进行补齐。
- 上采样不再使用传统的ConvTransposed2d,而是先用Upsample,然后用Conv2d,这样做避免Checkerboard Artifacts现象。
- Batch Normalization全部改成Instance Normalization。
- 网络中没有全连接层,线性操作是卷积,因此对输入和输出的尺寸没有要求。
对于常出现的网络结构,可以实现为nn.Module对象,作为一个特殊的层。因此,将Conv,UpConv和残差块都实现为一个特殊的层:
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: transformer_net.py
# Description:
# Author: PANG
# Date: 2022/6/27
# ----------------------------------------------
class ConvLayer(nn.Module):
"""
add ReflectionPad for Conv
默认的卷积的padding操作是补0,这里使用边界反射填充
"""
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(ConvLayer, self).__init__()
reflection_padding = int(np.floor(kernel_size / 2))
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
out = self.reflection_pad(x)
out = self.conv2d(out)
return out
class UpsampleConvLayer(nn.Module):
"""
默认的卷积的padding操作是补0,这里使用边界反射填充
先上采样,然后做一个卷积(Conv2d),而不是采用ConvTranspose2d
"""
def __init__(self, in_channels, out_channels, kernel_size, stride, upsample=None):
super(UpsampleConvLayer, self).__init__()
self.upsample = upsample
reflection_padding = int(np.floor(kernel_size / 2))
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
x_in = x
if self.upsample:
x_in = nn.functional.interpolate(x_in, mode='nearest', scale_factor=self.upsample)
out = self.reflection_pad(x_in)
out = self.conv2d(out)
return out
class ResidualBlock(nn.Module):
"""
introduced in: https://arxiv.org/abs/1512.03385
recommended architecture: http://torch.ch/blog/2016/02/04/resnets.html
"""
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in1 = nn.InstanceNorm2d(channels, affine=True)
self.conv2 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in2 = nn.InstanceNorm2d(channels, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
out = self.relu(self.in1(self.conv1(x)))
out = self.in2(self.conv2(out))
out = out + residual
return out
class TransformerNet(nn.Module):
def __init__(self):
super(TransformerNet, self).__init__()
# 下卷积层
self.initial_layers = torch.nn.Sequential(
ConvLayer(3, 32, kernel_size=9, stride=1),
nn.InstanceNorm2d(32, affine=True),
nn.ReLU(True),
ConvLayer(32, 64, kernel_size=3, stride=2),
torch.nn.InstanceNorm2d(64, affine=True),
torch.nn.ReLU(True),
ConvLayer(64, 128, kernel_size=3, stride=2),
torch.nn.InstanceNorm2d(128, affine=True),
torch.nn.ReLU(True)
)
# Residual layers(残差层)
self.res_layers = torch.nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
# Upsampling layers(上采样层)
self.upsample_layers = torch.nn.Sequential(
UpsampleConvLayer(128, 64, kernel_size=3, stride=1, upsample=2),
torch.nn.InstanceNorm2d(64, affine=True),
torch.nn.ReLU(True),
UpsampleConvLayer(64, 32, kernel_size=3, stride=1, upsample=2),
torch.nn.InstanceNorm2d(32, affine=True),
torch.nn.ReLU(True),
ConvLayer(32, 3, kernel_size=9, stride=1)
)
def forward(self, X):
y = self.initial_layers(X)
y = self.res_layers(y)
y = self.upsample_layers(y)
return y
在TransformerNet中包含三个部分:下采样的卷积层,深度残差层和上采样的卷积层。实现时充分利用了nn.Sequential,避免在forward中重复写代码。
搭建完网络之后,需要实现一些工具函数,例如gram_matrix。
from PIL import Image
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
def load_image(filename, size=None, scale=None):
img = Image.open(filename).convert('RGB')
if size is not None:
img = img.resize((size, size), Image.ANTIALIAS)
elif scale is not None:
img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)
return img
def save_image(filename, data):
img = data.clone().clamp(0, 255).numpy()
img = img.transpose(1, 2, 0).astype('uint8')
img = Image.fromarray(img)
img.save(filename)
def gram_matrix(y):
"""
输入形状b, c, h, w
输出形状b, c, c
:param y: image
:return: gram matrix
"""
(b, ch, h, w) = y.size()
features = y.view(b, ch, w * h)
features_t = features.transpose(1, 2)
gram = features.bmm(features_t) / (ch * h * w)
return gram
def normal_batch(batch):
"""
输入: b, ch, h, w 0~255, 是一个Variable
输出: b, ch, h, w 大约-2~2, 是一个Variable
:param batch:
:return:
"""
mean = batch.new_tensor(IMAGENET_MEAN).view(-1, 1, 1)
std = batch.new_tensor(IMAGENET_STD).view(-1, 1, 1)
batch = batch.div_(255.0)
return (batch - mean) / std
当将上述网络定义的工具和函数都实现之后,就开始训练网络了。
def train(args):
device = torch.device('cuda' if args.cuda else 'cpu')
np.random.seed(args.seed)
torch.manual_seed(args.seed)
# 数据加载
transform = transforms.Compose([
transforms.Resize(args.image_size),
transforms.CenterCrop(args.image_size),
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
train_dataset = datasets.ImageFolder(args.dataset, transform)
train_loader = DataLoader(train_dataset, batch_size=args.batch_size)
# 转换网络
transformer = TransformerNet().to(device)
optimizer = Adam(transformer.parameters(), args.lr)
mse_loss = torch.nn.MSELoss()
# VGG16
vgg = Vgg16(requires_grad=False).to(device)
# 获取风格图片的数据
style_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
style = utils.load_image(args.style_image, size=args.style_size)
style = style_transform(style)
style = style.repeat(args.batch_size, 1, 1, 1).to(device)
feature_style = vgg(utils.normal_batch(style))
gram_style = [utils.gram_matrix(y) for y in feature_style]
for e in range(args.epochs):
# 训练
agg_content_loss = 0
agg_style_loss = 0
count = 0
transformer.train()
for batch_id, (x, _) in enumerate(train_loader):
n_batch = len(x)
count += n_batch
optimizer.zero_grad()
x = x.to(device)
y = transformer(x)
y = utils.normal_batch(y)
x = utils.normal_batch(x)
features_y = vgg(y)
features_x = vgg(x)
# 计算content_loss, 只用到了relu2_2
content_loss = args.content_weight * mse_loss(features_y.relu2_2, features_x.relu2_2)
# style loss同时用到了4层输出
style_loss = 0
for ft_y, gm_s in zip(features_y, gram_style):
gm_y = utils.gram_matrix(ft_y)
style_loss += mse_loss(gm_y, gm_s[:n_batch, :, :])
style_loss *= args.style_weight
# 反向传播,更新梯度,这里只更新transformer的参数,不更新VGG16的
total_loss = content_loss + style_loss
total_loss.backward()
optimizer.step()
# 损失平滑
agg_content_loss += content_loss.item()
agg_style_loss += style_loss.item()
if (batch_id + 1) % args.log_interval == 0:
mesg = "{}\tEpoch {}:\t[{}/{}]\tcontent: {:.6f}\tstyle: {:.6f}\ttotal: {:.6f}".format(
time.ctime(), e + 1, count, len(train_dataset),
agg_content_loss / (batch_id + 1),
agg_style_loss / (batch_id + 1),
(agg_content_loss + agg_style_loss) / (batch_id + 1)
)
print(mesg)
if args.checkpoint_model_dir is not None and (batch_id + 1) % args.checkpoint_interval == 0:
transformer.eval().cpu()
ckpt_model_filename = "ckpt_epoch_" + str(e) + "_batch_id_" + str(batch_id + 1) + ".pth"
ckpt_model_path = os.path.join(args.checkpoint_model_dir, ckpt_model_filename)
torch.save(transformer.state_dict(), ckpt_model_path)
transformer.to(device).train()
# 保存模型
transformer.eval().cpu()
save_model_filename = "epoch_" + str(args.epochs) + "_" + str(time.ctime()).replace(' ', '_') + "_" + str(
args.content_weight) + "_" + str(args.style_weight) + ".model"
save_model_path = os.path.join(args.save_model_dir, save_model_filename)
torch.save(transformer.state_dict(), save_model_path)
print("\nDone, trained model saved at", save_model_path)
这里训练用的图片是MS COCO 2014 training的数据集,大约包含8万张图片,13GB。
训练完成之后,要加载预训练好的模型对指定的图片进行风格迁移的操作。代码如下:
def stylize(args):
device = torch.device('cuda' if args.cuda else 'cpu')
# 图片处理
content_image = utils.load_image(args.content_image, scale=args.content_scale)
content_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.mul(255))
])
content_image = content_transform(content_image)
content_image = content_image.unsqueeze(0)
if args.model.endswith('.onnx'):
output = stylize_onnx(content_image, args)
else:
with torch.no_grad():
# 模型
style_model = TransformerNet()
state_dict = torch.load(args.model)
# remove saved deprecated running_* keys in InstanceNorm from the checkpoint
for k in list(state_dict.keys()):
if re.search(r'in\d+\.running_(mean|var)$', k):
del state_dict[k]
# 风格迁移与保存
style_model.load_state_dict(state_dict).to(device).eval()
if args.export_onnx:
assert args.export_onnx.endswith('.onnx'), "Export model file should end with .onnx"
output = torch.onnx._export(
style_model, content_image, args.export_onnx, opset_version=11
).cpu()
else:
output = style_model(content_image).cpu()
utils.save_image(args.output_image, output[0])
参考资料
[1] 深度学习-VGG16原理详解
[2] 机器学习进阶笔记之二 | 深入理解Neural Style
[3] NEURAL TRANSFER USING PYTORCH
[4] PyTorch官方示例