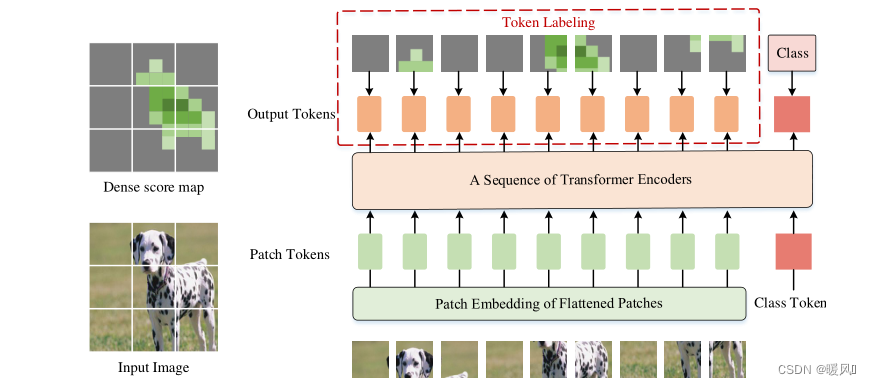
这篇文章是对ViT训练的一种增强方法LV-ViT。以往的Vision Transformer 分类任务都只是应用class token聚集全局信息,用于最后的分类。作者提出将patch token也用作loss的计算。相当于将一张图像的分类问题,转换成了每个token的识别问题,每个token的分类标签是由机器生成的监督(supervision)。
原文链接:All Tokens Matter: Token Labeling for Training Better Vision Transformers
另一版:Token Labeling: Training a 85.5% Top-1 Accuracy Vision Transformer with 56M Parameters on ImageNet
源码地址: https://github.com/zihangJiang/TokenLabeling
All Tokens Matter: Token Labeling for Training Better Vision Transformers[NIPS2021]
Abstract
在本文中,提出了一个新的训练目标,即Token Labeling,用于训练高性能Vision Transformer(VIT)。ViTs的标准训练目标是在一个额外的可训练class token上计算分类损失,提出的目标是利用所有的图像patch token密集地计算训练损失。
也就是说将图像分类问题重新描述为多个token级别的识别问题,并为每个patch token分配由机器注释器生成的特定于位置的单独监督supervision。
26M的Transformer模型使用Token Labeling,能在在ImageNet上可以达到84.4%的Top-1精度。
通过将模型尺寸稍微扩大到150M,结果可以进一步增加到86.4%,使以前的模型(250M以上)中的最小尺寸模型达到86%。
1 Introduction
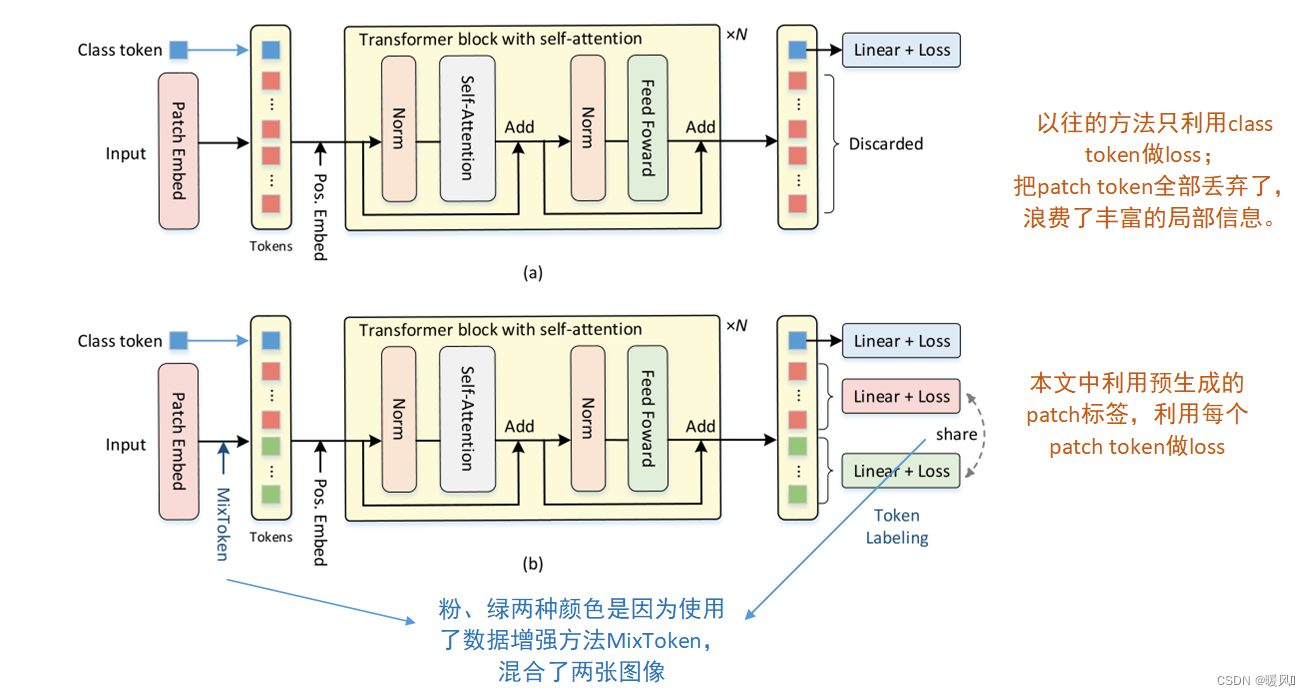
最近的vision transformers通常使用的class token来预测输出类,而忽略了其他patch token的作用,这些标记在各自的局部图像patch上编码了丰富的信息。
在本文中,提出了一个新的Vision Transformer训练方式称为LV-ViT,同时利用了patch token 和class token。该方法采用机器注释器生成的K维分数图作为监督,以密集方式监督所有token,其中K是目标数据集的类别数。通过这种方式,每个patch token显式地与指示相应图像patch内存在目标物体的单个位置特定监督相关联,从而在计算开销可以忽略不计的情况下提高vision Transformer的物体识别能力。这是首次证明密集监控有利于图像分类中的vision Transformer的工作。
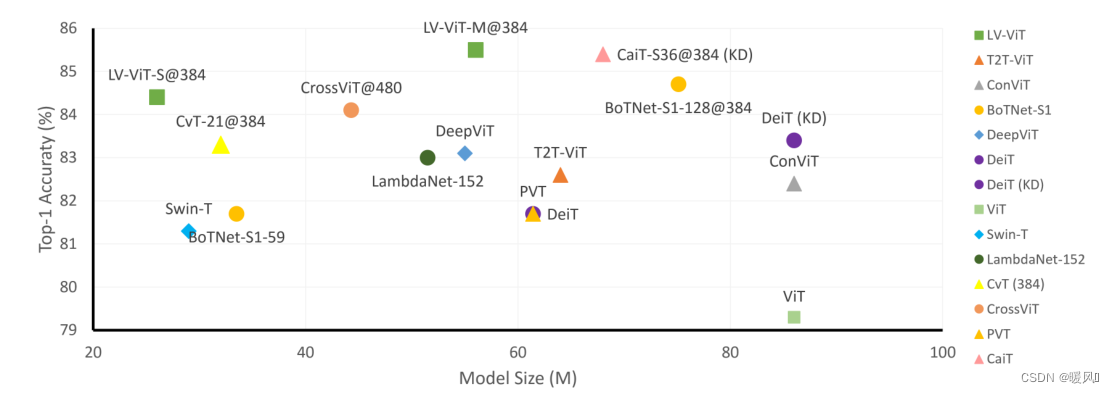
如图,LV ViT具有56M参数,在ImageNet上产生85.4%的top-1精度,其性能优于所有其他参数不超过100M的基于Transformer的模型。当模型尺寸放大到150M时,结果可以进一步提高到86.4%。
2 Method
常规的ViT将图像分割为patch,再加入一个class token,经过多轮相似度计算后,将图像信息聚合到class token中,最后只采用图像级标签作为监督,而忽略了嵌入在每个图像块中的丰富信息。其中
X
c
l
s
X^{cls}
Xcls是最后一个Transformer Black的输出,
H
(
?
,
?
)
H(・,・)
H(?,?)是softmax交叉熵损失,
y
c
l
s
y^{cls}
ycls是类标签。
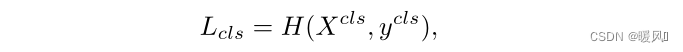
本文中提出了一种新的训练目标token标记,该标记利用了patch token和class token之间的互补信息。
2.1 Token Labeling
Token Labeling强调所有输出token的重要性,并主张每个输出token应与单个位置特定的标签相关联。因此,输入图像的标签不仅涉及单个K维向量 y c l s y^{cls} ycls(图像级标签),还涉及 K × N K×N K×N矩阵或称为K维分数图如 [ y 1 , . . . , y N ] [y^1,...,y^N] [y1,...,yN],其中N是输出patch token的数量。也就是说,一个token一个标签,那不就可以每个token都做loss来作为辅助了。但是这个标签指示的是目标物体是否在对应的 image patch 中存在。K维分数图怎么获得的文中并没有细说,也超出了我的方向,感兴趣的同学可以看这篇Token Labeling。
每个训练图像利用密集分数图,并使用每个输出patch token和密集分数图中相应对齐标签之间的交叉熵损失作为训练阶段的辅助损失。patch token的loss函数定义为:
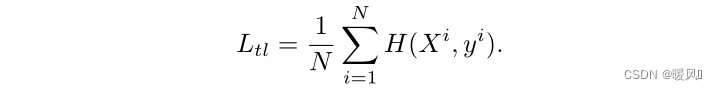
整体的loss函数就是常规的class token loss加patch token loss,其中β是平衡这两项的超参数。经过实验将其设置为0.5。公式为:
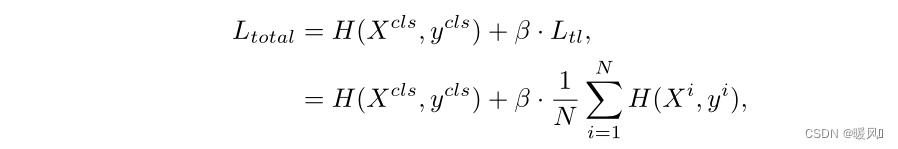
Token Labeling具有以下优点:
- 知识蒸馏的方式通常需要teacher模型在线生成监督标签,而token labeling是一种更简单的操作。密集分数图可以通过预先训练的模型生成(例如,EfficientNet 、NFNet)。在训练过程中,只需要裁剪分数图,插值后与空间坐标中裁剪的图像对齐。因此,额外的计算成本可以忽略不计。
- 其次,与大多数分类模型和重新标记策略中使用单个标签向量作为监督不同,本方法还利用分数图以密集方式监督模型,因此每个patch token的标签提供
位置特定信息,这可以帮助训练模型轻松发现目标对象并提高识别精度。 - 由于训练中采用了密集监督,具有token labeling的预训练模型有利于具有密集预测的下游任务,如语义分割。
2.2 Token Labeling with MixToken
列几种先前的增强方法:
- Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
- Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
- CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。
本文中作者提出了一种一种新的图像增强方法MixToken,并和CutMix进行了比较。CutMix对输入图像进行操作后会产生包含两幅图像中混合区域的patch也就是红色的的部分。而MixToken的目标是在patch嵌入后混合token。这使得patch嵌入后的每个token都有干净的内容。

产生方式:
对于两个图像表示为
I
1
、
I
2
I1、I2
I1、I2已经预生成了对应token的标签
Y
1
=
[
y
1
1
,
…
,
y
1
N
]
Y_1=[y_1^1,…,y^N_1]
Y1?=[y11?,…,y1N?]以及
Y
2
=
[
y
2
1
,
…
,
y
2
N
]
Y_2=[y^1_2,…,y^N_2]
Y2?=[y21?,…,y2N?]。
两个图像输入patch嵌入模块中,得到最终的token序列:
T
1
=
[
t
1
1
,
…
,
t
1
N
]
T_1=[t^1_1,…,t^N_1]
T1?=[t11?,…,t1N?]和
T
2
=
[
t
2
1
,
…
,
t
2
N
]
T_2=[t^1_2,…,t^N_2]
T2?=[t21?,…,t2N?]。然后通过二进制掩码M生成一个新的token序列,公式:⊙ 是点积,掩码M是根据论文“Regularization strategy to train strong classifiers with localizable features” 中的方法生成的。
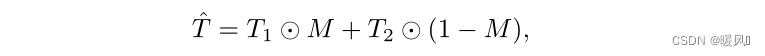
对标签进行相同的操作:
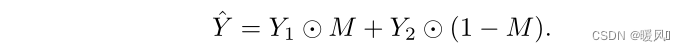
类标签就变成了两张图像标签的平均,公式如下:其中
M
ˉ
\bar M
Mˉ是M中所有元素的平均值。
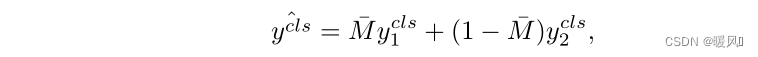
3 Conclusion
- 这篇文章核心思想就是利用了之前被忽视的patch token作为辅助loss。
- 每个patch token 对应的标签是通过预生成获得的,文中没有详述,具体方法参看:Token Labeling
- 使用了新的数据增强方法MixToken,防止两张图像结合的边界处出现混合区域。
最后祝各位科研顺利,身体健康,万事胜意~