Ŀ¼
һ�����ؼ���������
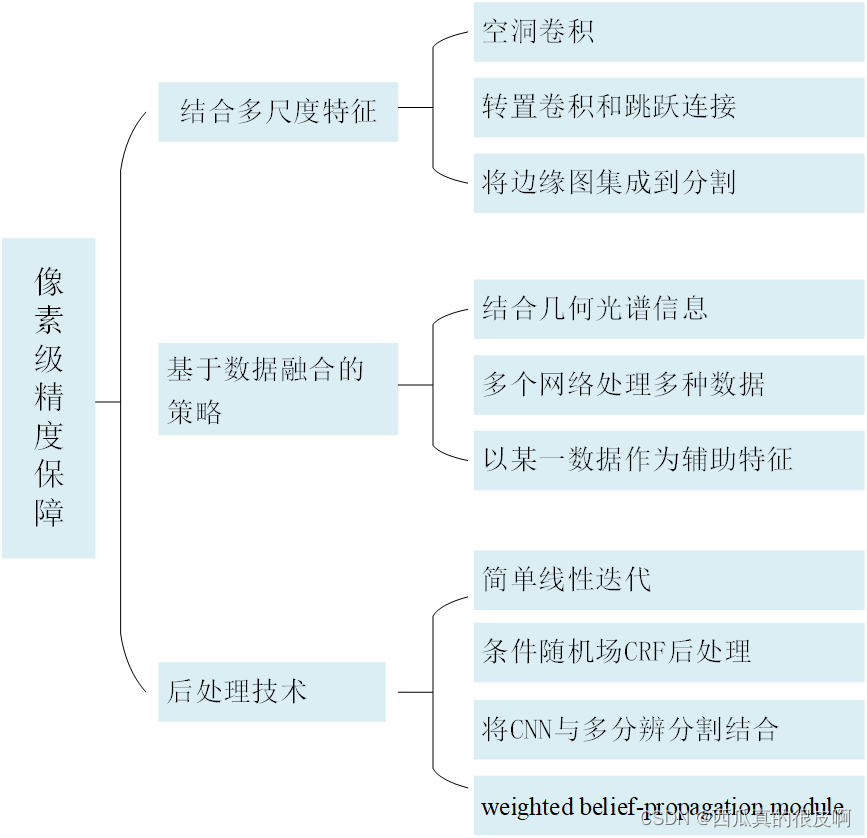
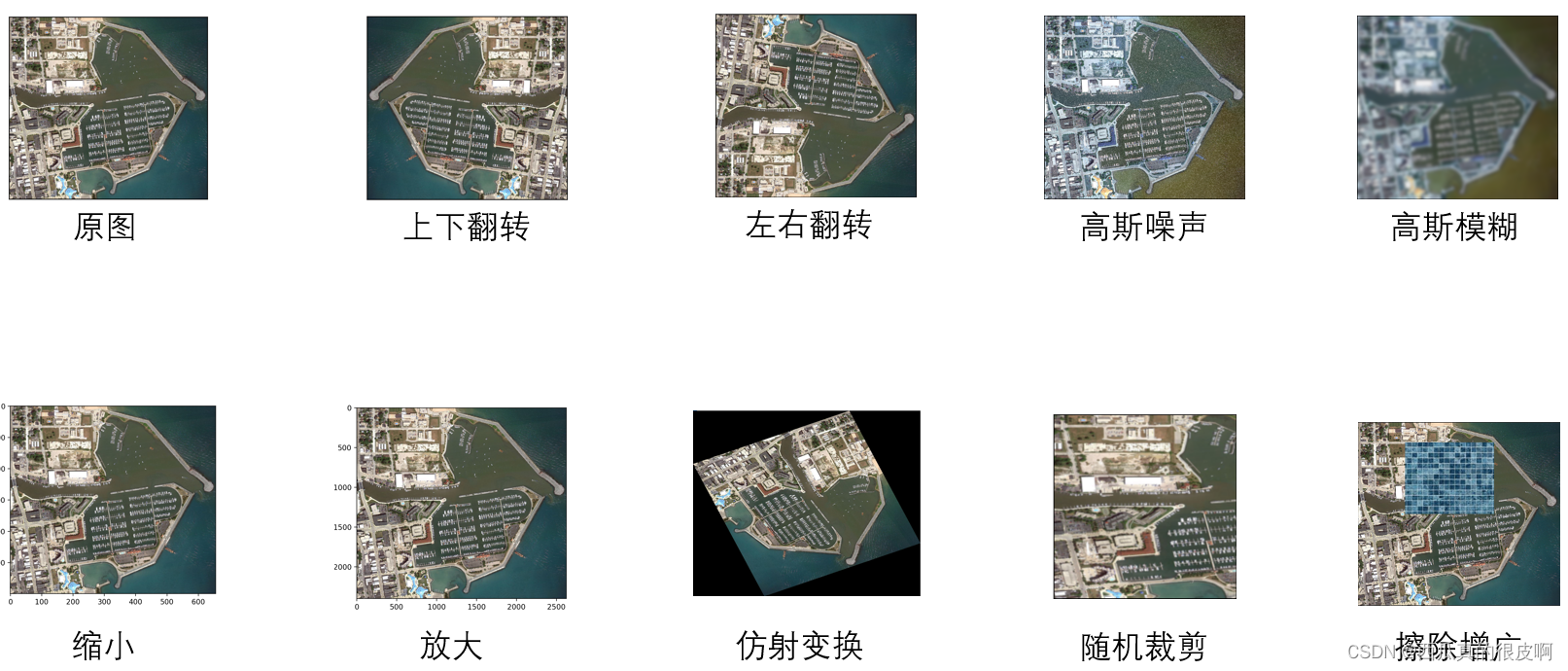
���ڽ�����ؼ�����,һ�����Է�Ϊ3�����,����ͼ��ʾ:
��������û����ϸѧϰ,�����õ�����ѧ��!����Խ�϶�߶������ͻ��������ںϵIJ�����һ����ϸ���ܡ�
1. ��϶�߶�����
1.1 �ն�����
�ն�����������ָ�����dz�����,�Һ���Ч��,���Ǿ����ᵽ���� dilated network��Deeplabϵ�����綼�ǻ��ڿն�������������,��ѡ��һƪ����(Ҳ�����ر���д�����,����ҵ�,�պÿ���),���ܡ�
ʾ��: Liu Y , Fan B , Wang L , et al.? Semantic Labeling in Very High Resolution Images via a Self-Cascaded Convolutional Neural Network[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 145(NOV.):78-95.
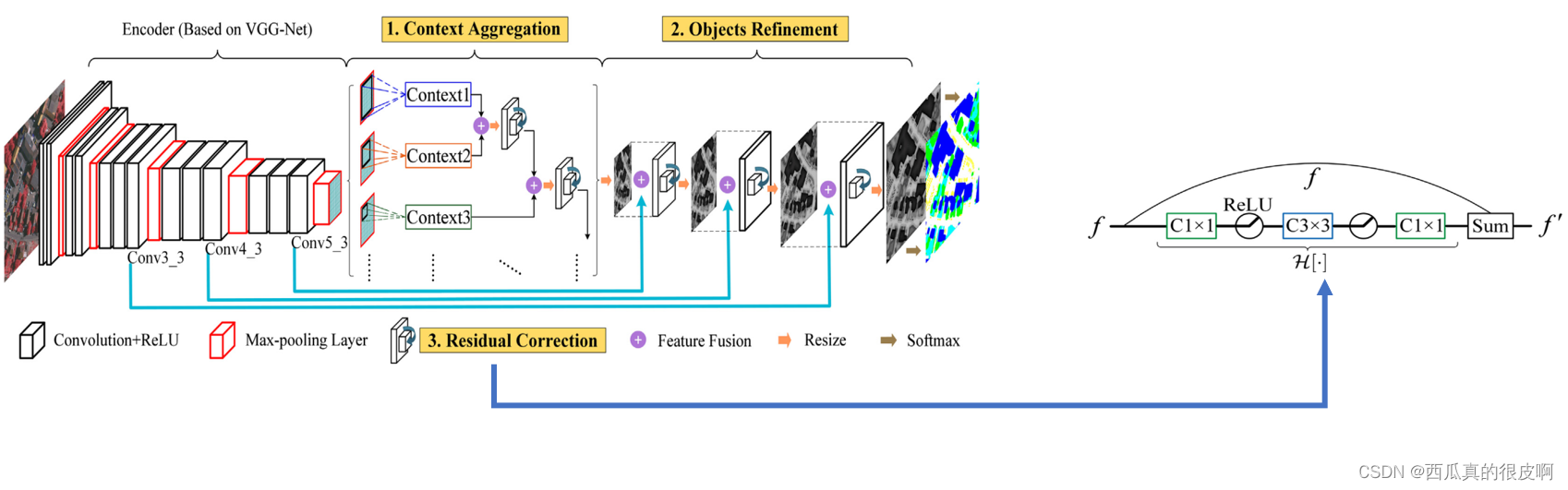
����������������ͼ��ʾ��
��ƪ���µ�������:���²�������֮��,���ò�ͬ����ϵ���Ŀն���������������ͼ���д���,��ò�ͬ����Ұ������������(�е�����ASPP�ṹ,���Ǻ����Ӧ�ü��ںϲ�ͬ),Ȼ�����ںϡ�����������,cnn����ֱ���������ĵײ�ӳ�䡣����,���漰���ںϲ�ͬ���������ʱ,��������ø������ء����,��ͬ����Ķ�������ں�ʱ����DZ�ڵ���ϲв�,�����ںϹ�������Ϣ��ȱʧ�����,���������һ�ֲв�У��,����У���������ں�������հ������DZ����ϲв
���ĵ�����:
(1)��߶��ᄈ�ۺ�,����ʶ����������Ϊ����;
(2)���õײ������Ծ�ϸ�ṹ�Ķ������ϸ��;
(3)�в�У��,����Ч�Ķ������ںϡ�
1.2 ת�þ�������Ծ����
?ת�þ�������Ծ���ӵ����ò��ö�˵,�Ѿ��кܶ���������ķdz���,��ҿ������аٶȡ������һ����������,����Unet�ĸĽ�,DeepUnet
ʾ��:DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation[J]. IEEE, 2018(11).
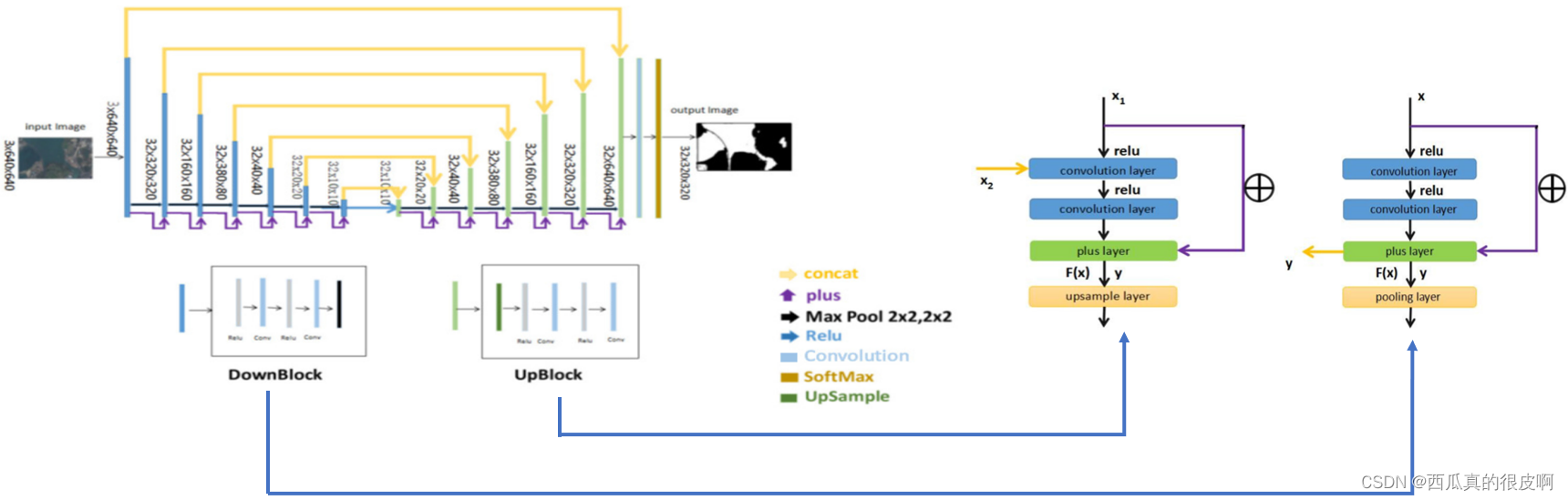
DeepUnet����������ͼ����ͼ��ʾ,����Unet�IJ�ͬ��Ҫ�ǽ�Unet�еľ����㻻����DownBlock��UpBlock,�����dz����������²���,����һ��Plus������
1.3 ����Եͼ���ɵ��ָ�
����Եͼ����,��ʵһ��ʼ������ָ��ʱ��,�ҵ�ʱ����û��ô������,���ſ������ñ�Ե�������ָ�,�о������Ǹ�����ĵ���,�������ĺ�ŷ���,����2016���ʱ�������,���Ц��,��Ȼ,�����е�ʱ��,�������һ��ͻȻ�����Լ��뵽һ�������о���ĵ���,���ѵ�,��һ��������û����!!!
ʾ��: Fid A , Fw B , Pc A , et al. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data - ScienceDirect[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162:94-114.
���������һ��ResUnet-a����ṹ,������ǽ����Unet�Ŀ�ܺ�Resnet��˼��,����ṹͼ����:
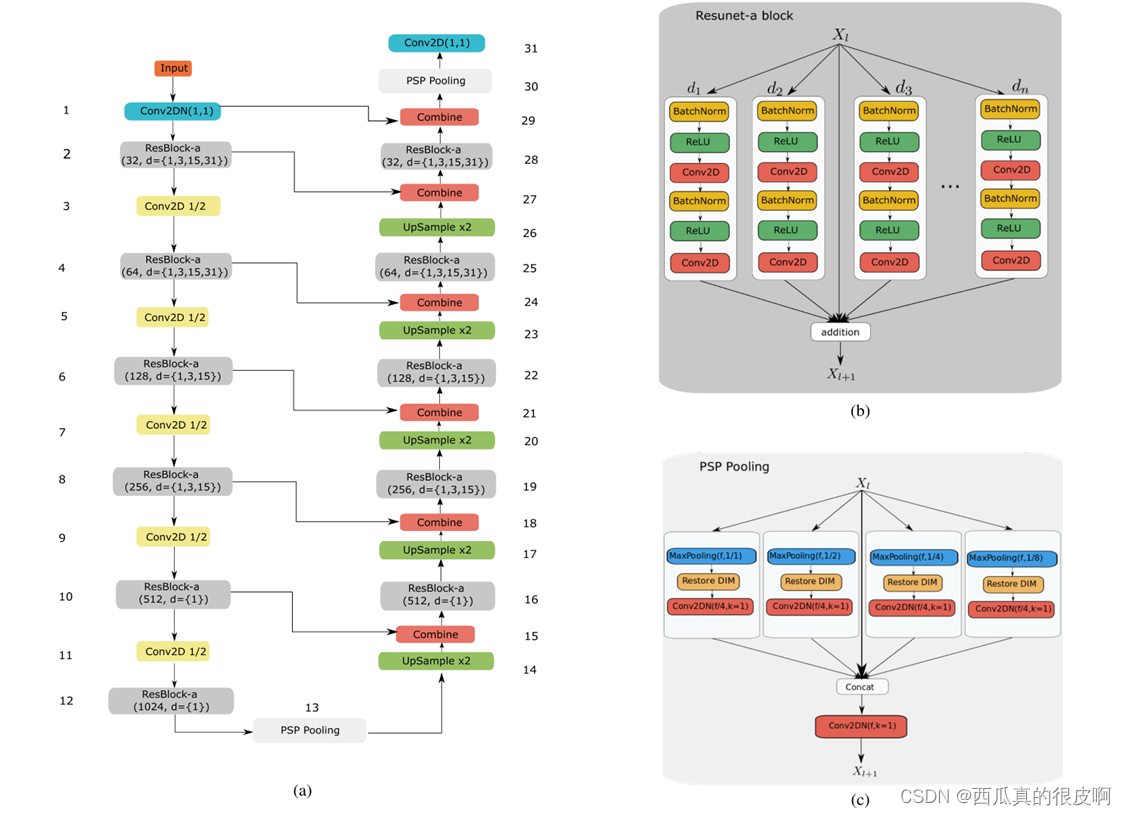
ResUNet-a ʹ��Unet�ı�����/����������,��ϲв����ӡ�atrous���������������������غͶ������������÷����Ƶ���Ŀ��߽硢�ָ�����ľ���任���ָ������Լ�������ع���(��һ�����ں�)
2. ���������ںϵIJ���
2.1?��ϼ��κ�����Ϣ����߷ָ��
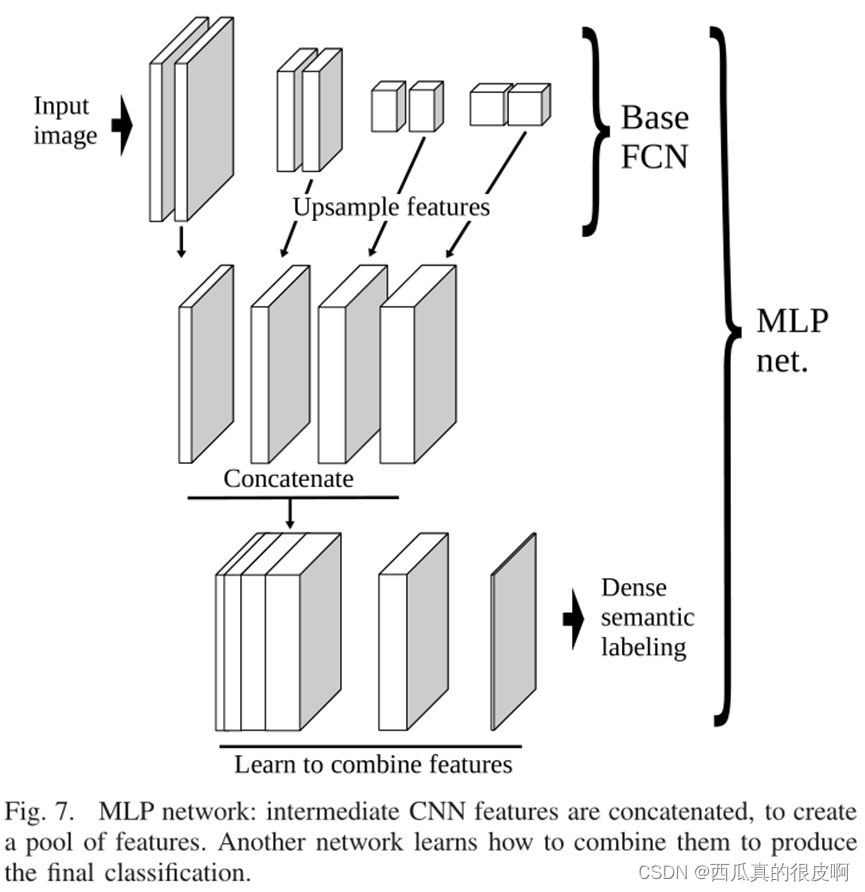
ʾ��: Maggiori E ,? Tarabalka Y ,? Charpiat G , et al. High-Resolution Aerial Image Labeling With Convolutional Neural Networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, PP(12):1-12.
���ò�ͬ�ֱ��ʵĶ���м����Բ���������ƺ���һ�ֺ����ķ���,�����ر������ػ�/ʶ��Ȩ������,������Ծ����һ���������ַ�����,�߷ֱ����������н�С�Ľ���Ұ,���ͷֱ����������нϿ��Ľ���Ұ���������ȷʵ�����˶���Դ����Ч����,��Ϊ����ʵ���ϲ���Ҫ�߷ֱ����˲�����ӵ�й㷺�Ľ�����,��ѭ��ͼ��ԭ��(����������ԽԶ,�ֱ��ʿ���Խ��,��Ӱ�����������)��

����������ķ�����,����������ȡ�м�����,��ƽ�ȶԴ�,����һ�����Բ�ͬ�ֱ��ʵ������ء�Ȼ��������ѧϰ��ν����Щ�������������յķ�����ۡ���������ѧϰ��ͬ����֮������ӹ�ϵ�������,���ƹ�����Ծ��ϵ�ṹ��Ԫ�ؼ����ӡ���Ծ�����������Բ�ͬ�ֱ��ʵ�Ԥ��,��ÿ����ĵ÷�ͼ��
������������ͼ��ʾ,�������²���:
1)����������ȡ�м������Ӽ�����Щ�������ϲ���,��ƥ��ֱ��ʸ��ߵ������ķֱ��ʡ���Ҫע�����,cnnͨ����ѧϰ�����ϲ������(����ͼ��������ȵı仯��ʾ)��
2)Ȼ����Щ�����������������Գء�ע��,��Ȼ����ͼ�Ŀռ�ά�ȶ�����ͬ��,������������Բ�ͬ�ķֱ��ʡ�ͨ�����ַ�ʽ,��ռ�������Ӧ�ı仯����ijЩ��ͼ�ϸ�ƽ��,����������ͼ�ϸ�����
3)���������������Ԥ�����յķ���ͼ���������������Ϊ��������,�������еĿռ��������Ѿ���ǰ��IJ����д����ˡ�
?2.2 ��������+�������ṹ
�ڴ�ͳң��Ӱ��Ĵ���������,Ҳ�������õ��������͵�����һ����,�����ѧӰ��+SARӰ��+�����״�����,����ң��Ӱ�����ݽ�ϸ߾���DEM��DOM��DSM�������ҿ���һƪ���е��ϵ�����,��Ҫ��Ϊ�˺�����һƪ�����γɶԱ�,��Ϊ���߶��õ��ǹ�ѧӰ��+DSM,����������ͬ������Ҫ�Ĵ�ҿ���������,Ӧ���кܶ��������¡�
ʾ��:Marmanis D et al. Semantic Segmentation of Aerial Images with an Ensemble of CNSS[C]// ISPRS Congress. ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2016.
?�������,ʹ�÷dz��߷ֱ���ͼ����Զ����ر������ս�Ե���,һ�������ǵĹ��ֱ���(���ֱ���ָ����IJ��η�Χ,�ֵ���ϸ,��������,���ֱ��ʾ�����,ϸ�ֹ���������Զ����ֺ�ʶ��Ŀ�����ʺ���ɳɷֵ�������)�����ͱȽϵ�,��һ����С�����С�߶ȱ���������Ŀɼ�����֮,���ͼ��ĸ����ڿɱ���ͬʱ�������졣
2.3 ��ijһ������Ϊ��������
��������ƪ���²�ͬ,�����DSMû��ѵ��,������Ϊ������������������ѵ���ĸ��á�
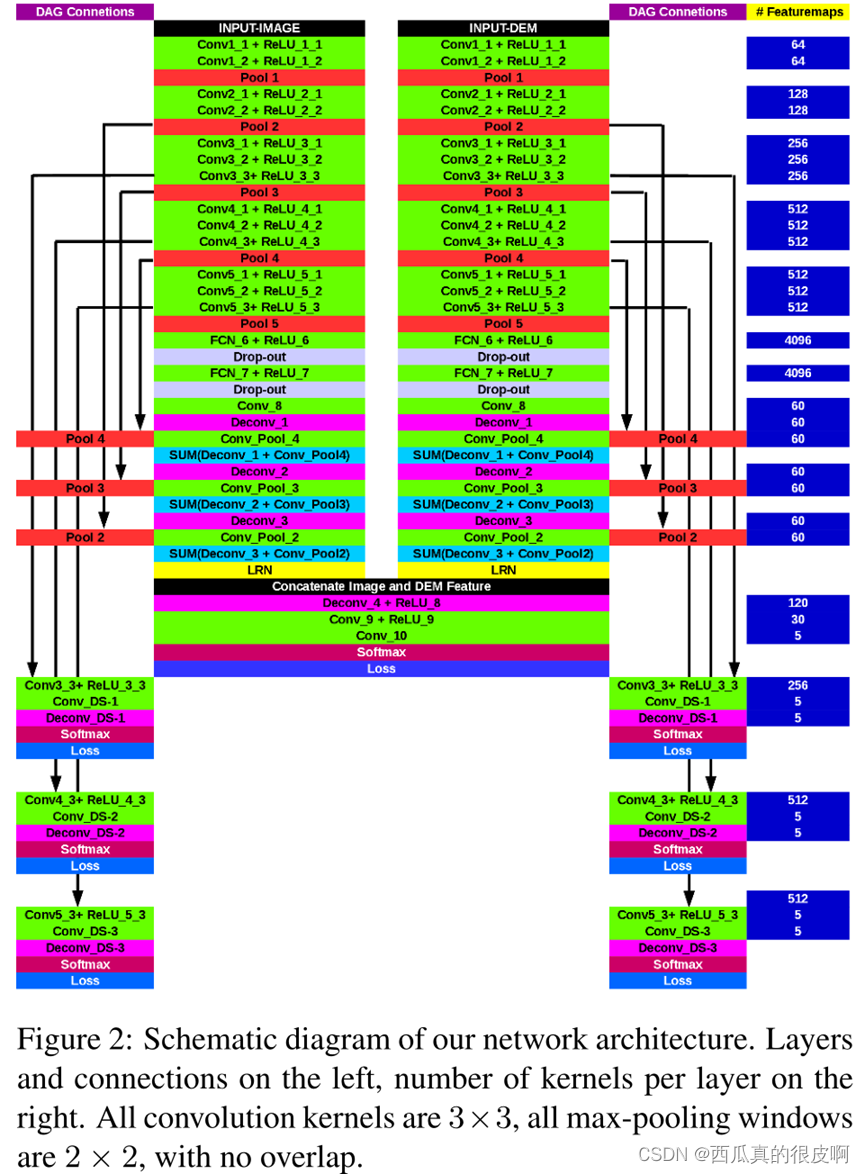
?ʾ��:Sun W ,? Wang R . Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM[J]. IEEE Geoscience & Remote Sensing Letters, 2018:1-5.
���������һ��������̬ѧ�����DSM���,�Ӳ�ɫͼ���DSM��ͬʱ��ȡ������Ϣ��
���ĵ���Ҫ�����ǻ���DSM��VHRң��ͼ������ָ��������ͼ��ʾ,������ķ���������������:1)ʹ���������MFS(maximum fusion strategy)��FCN�Ӳ�ɫͼ���м����ʼ��ǩͼ,2)ʹ�ó�ʼ��ǩ��ͼ��DSM,���DSM���������FCN����еĴ���DSM��˸���FCN�ij�ʼ��ǩͼ��DSM����ȡ�ر������õ����FCN�������ϸ�����÷�����Ч���ں��˲�ɫͼ��Ĺ�����Ϣ��DSM�ļ�����Ϣ,������VHRң��ͼ�������ָ

(1)����ںϲ���
�������ص����ص��ں�,˫���Բ�ֵ�ָ�����ӳ��ӵ�λ����ͬ��С������ͼ�߷ֱ��ʵ�dz�㵥Ԫ��ֵ������С,�ܹ�������Ծ�ϸ�ı߽���Ϣ�����,������㵥λ�ķ���������dz�㵥λ�ķ���������������,�����ٵ�ϸ�ڡ��ںϲ��Ե�Ŀ����ͨ���ںϲ�ͬ��Ԫ���������������������ϸ�ڡ���Ҫע�����,�����ϸ�ڵ�����ȡ�����������͡����,���ǽ���MFS����ѡ���Ե�ѡ��ͬ����������ϸ�ڡ������������,(c)������յ÷ּ���Ϊ

(2)DSM��˴���
DSM��������������:1)����DSM��FCN����Ķ�Ӧ�ij�ʼ��ǩͼ,����ÿ�����ص���Χ����(H2G)ͼ��ĸ߶�;2)����H2Gͼ��ȥ����top-hats;3)����H2Gͼ��ȥ����ground��
?������������ֻ�����̬ѧ�������㷨����:
�� H2Gͼ��:����,����FCN���MFS����ȷ��(OA)�ﵽ90%���ϵ����,��ȡ���͵���(���ݵغ͵�·)����ģ�����,����ر�,�����ǵر�������DSM(ground_DSM)��������������ground_DSM�лָ���ground����ĸ߶ȡ�����,ͨ��DSM��ȥ�ر��õ�H2Gͼ��
�� False Ground:����H2Gͼ��,�����ʼ��ǩ��ͼ�����Ground�����롣����ͨ���Գ�ʼ��ǩͼ����,ʹtop-hats(��ñ)�������ϴ�,�������������С,�Գ�ʼ��ǩ��ͼ�������Ͳ���,��top-hats��Χ��һ���̶���С�Ĵ�����,��ȡ������ĵ��档�ڼ���ٵ���ģ֮ǰ,���Ƕ�H2Gͼ�������С�ߴ��(5 �� 5)����ʴ����,�Ա�����DSM��ȷ���ݶ���Ե���ּٵ���ģ�Ĵ������,���㷨��DSM�о��״�ݶ���Ե���������н�ǿ��³���ԡ�
�� ��Top-Hat:�������Ƕ�H2Gͼ��������Ų��������,����H2Gͼ��������ñ��ģ;����,�Ա����ı�ǩӳ�������ʴ����,ȥ����ñ�ӡ�
�����dz������ݷ���
?���ڷdz�������,��ң��������,�߹�������(��ʮ�ɰٸ���)��SAR���ݡ���������,���ʹ�ͳ����ȻӰ���кܴ����,�������Ƕ���Ϊ�dz�������,����ķdz��治�������ݱ������κ����⡣
���ڽ���dz������ݷ���,Ŀǰ������������:
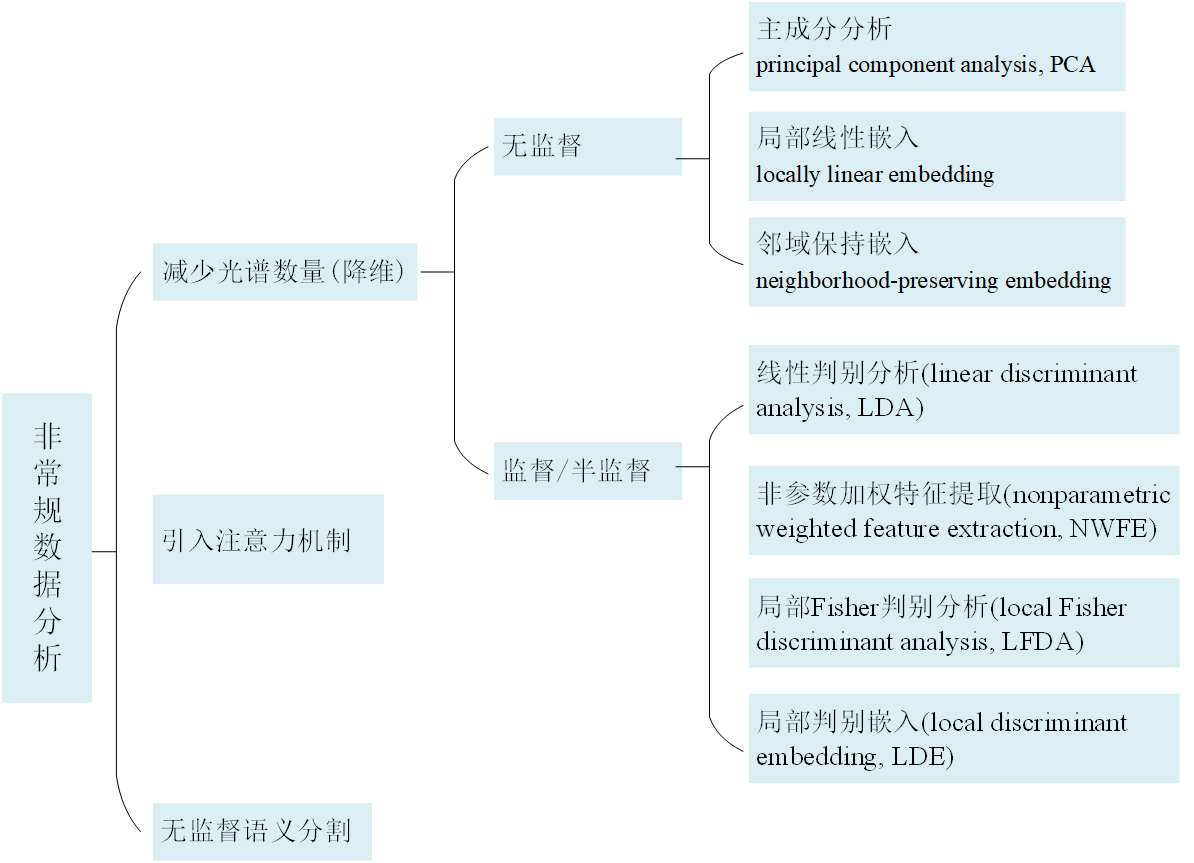
1.?���ٹ�������
?ʾ��:Zhao W ,? Du S . Spectral�CSpatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(8):4544-4554.
��ά�Dz�ʹ��ȫ���ײ��ν������ݴ���,����Ѱ��߹���Ӱ��(Hyperspectral images,HSI)���͵ĵ�ά��ʾ�����,��ά������Ч���ҵ����ض����ӿռ�,Ҳ���Ը��õؽ������ܡ�
(1)���Ŀ��
��SSFC(spectral�Cspatial feature based classification)��,����BLDE�����Ը�ά������Ϣ���н�ά����,��ȡ��ά�����������ռ�������ͨ��ѵ��CNN��ԭʼ���ݼ���������һ���ɷ�(PC)�����ϵõ��ġ����������ںϼ���[26]���ɹ��ռ����������,���ڹ���-�ռ��������ѵ��������,����ͼ��ʾ�����������SSFC�������ص����¡�1)�����һ�ֻ���cnn�Ŀռ�������ȡ��������HSI���ࡣ�봫ͳ�ֹ���ȡ�����ֿռ��������,��ȡ�����ֿռ��������и�ǿ��³���Ժ���Ч�ԡ�2)�������BLDE�ܹ�ƽ��ֲ�����ɢ���������ɢ�����,�Ӷ���ø��õ��б�ͶӰ��3)���������������cnn�Ŀռ���Ϣ���ϵIJ��Կ��Ժܺõؽ�ʾԭʼ�������������������ԡ�
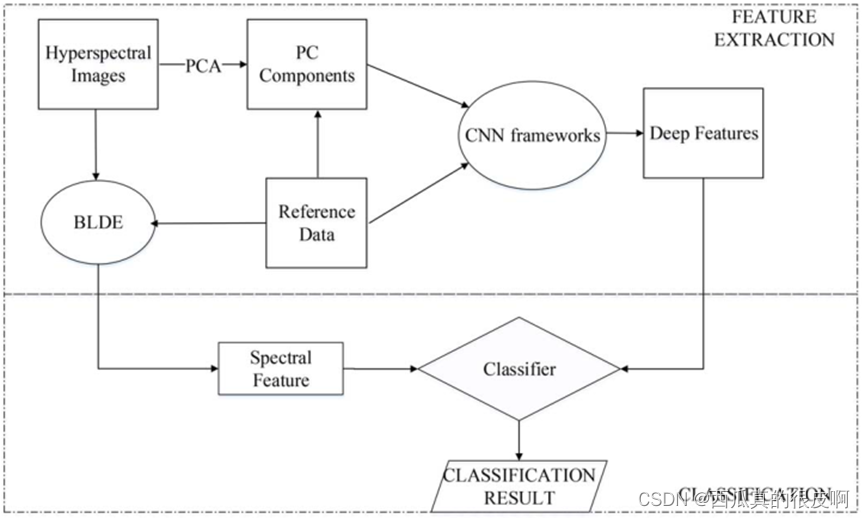
��������Ļ��ڹ��ռ������ķ���(spectral�Cspatial feature based classification,ssfc)��HSI�����㷨�ṹ����ͼ��ʾ�������Է�Ϊ������Ҫ���֡���һ��,�ֱ���ȡ���������Ϳռ�����;���ڹ�������,ͨ��������ý�ά����������ά��;�������,���о�ѡ��(balanced local discriminant embedding,BLDE)�㷨��HSIͼ����е�ά��ʾ������CNN����Զ���ȡ��ռ���صĸ߲�����������Ȼ��,������bldeb�Ĺ������������cnn�Ŀռ���������,�õ�������Ĺ��ռ����������,�����ӵ���������LR������,�õ���������
2. �ල/��ල�ָ�
2.1 �����Ա�������ѧϰ
���Ϻܶ�,�����ͼ�����������������:?
(1)�Ա�����ģ��
�Ա�������������Ϊһ����ͼȥ��ԭ��ԭʼ�����ϵͳ���Ա�����ģ������ͼ��ʾ:
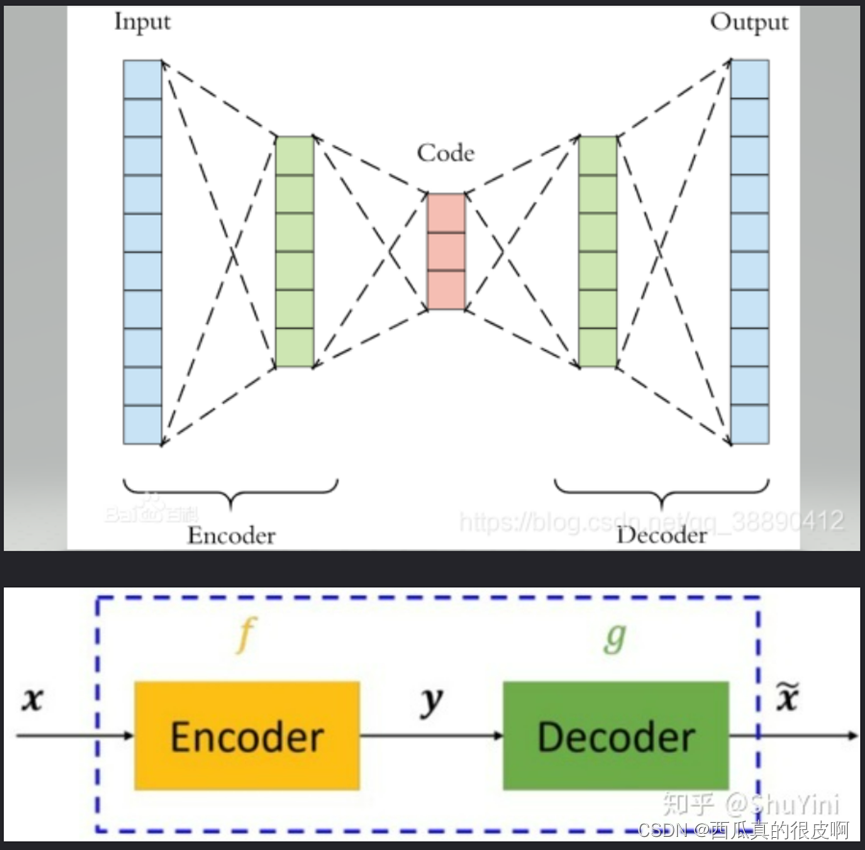
����ͼ���Կ���,�Ա�����ģ����Ҫ�ɱ�����(Encoder)�ͽ�����(Decoder)���,����ҪĿ���ǽ�����xת�����м����y,Ȼ���ٽ�yת����x![]() ,Ȼ��Ա�����x�����x
,Ȼ��Ա�����x�����x![]() ʹ�������������ӽ���
ʹ�������������ӽ���
(2) �������Ա���ģ��
�����ѧϰ��,�Զ���������һ���ල��������ģ��,������ѧϰ���������ݵ���������,���Ϊ����(coding),ͬʱ��ѧϰ���������������ع���ԭʼ��������,��֮Ϊ����(decoding)����ֱ��������,�Զ���������������������ά,�������ɷַ���PCA,���������PCA�����ܸ�ǿ,��������������ģ�Ϳ�����ȡ����Ч�������������˽���������ά,�Զ�������ѧϰ�������������������мලѧϰģ����,�����Զ�������������������ȡ�������á��ٸ�����,����һ������ͼƬ,������ͨ��������ѹ������ͼƬ�Ĵ�С(���չ�ֳ������ܱȽ�ģ��),Ȼ������Ҫ�����ʱ���仹ԭ��������ͼƬ�������������ͼ��ʾ:
���ͼƬ����:(39����Ϣ) ���������Ա�����Autoencoder_�����Ұ�~�IJ���-CSDN����_�Ա�����������
(3) �Զ�����������������
�� �Զ���������������ص�(data-specific �� data-dependent),����ζ���Զ�������ֻ��ѹ����Щ��ѵ���������Ƶ����ݡ�����,ʹ������ѵ���������Զ���������ѹ�����ͼƬ,������ľʱ���ܺܲ�,��Ϊ��ѧϰ������������������صġ�
�� �Զ��������������,��˼�ǽ�ѹ���������ԭ��������������˻���,MP3,JPEG��ѹ���㷨Ҳ����ˡ���������ѹ���㷨��ͬ��
�� �Զ��������Ǵ������������Զ�ѧϰ��,����ζ�ź�����ָ���������ѵ����һ���ض��ı�����,������Ҫ����κ��¹�����
2.2 �����ޡ���ල��ʾ������
ʾ��:Ronald K ,? Ryan L ,? Christopher K . Low-Shot Learning for the Semantic Segmentation of Remote Sensing Imagery[J]. IEEE Transactions on Geoscience & Remote Sensing, 2018, PP:1-10.
��ѧ����ѧϰ�����������ڸ��������ϵ��ලѧϰ,Ȼ�����мලϵͳ��ʹ����Щ��������ල�㷨ͨ���ලѧϰ���ලѧϰ����ල�����ϵķ�������,�Ӷ���߲��������ϵķ������ܡ��������������,��ֻ�����������HSI����ʱ,�ලѧϰ��������Щ�㷨�������ϡ�
��ල��ܸ���ģ�����������ռ�ά�ȵ�����,��ʹ�����ܹ��˽���Ż���������Ҫ������,Ҳʹ�����ܹ��ں���ע�����ݵ�����±������õ����ܡ�
(1)���ĵ���Ҫ��������:
1)�������������ڷ�rgbң��Ӱ��ռ����������ȡ�Ķѵ�����ľ����Ա�����(SMCAE)ģ��(����ͼ)��SMCAE�����ල��ѧѧϰ�ķ��������һ����ȵ�������ȡ�⡣SuSAʹ��SMCAE����������ȡ��
2)��������˰�ල����֪��(SS-MLP)ģ�����ڷ�rgbң��ͼ�������ָSuSA����SS-MLP������SMCAE��������ʾ���з���,��SS-MLP�İ�ල����ʹ���ڵ;�ͷѧϰ�б������á�
3)����֤��,SuSA��IEEE GRSS���ݺ��㷨������(DASE)�Լ�ISPRS���ݼ���ʵ�������Ƚ��Ľ����
(2)���ĵ���Ҫ���
��������������ͼ��ʾ���Խ̰�ල�Զ�������(self-taught semi - supervised autoencoder, SuSA)����ָ��ܡ�SuSA�������Ϊ����ͼ��ע��ϡȱ�Ķ����(multispectral image,MSI)�߹���(Hyperspectral image, HSI)�����ϱ������á�SuSA������ģ����ɡ���һ��ģ�鸺����ȡ�ռ��������,�ڶ���ģ�����Щ�������з��ࡣ
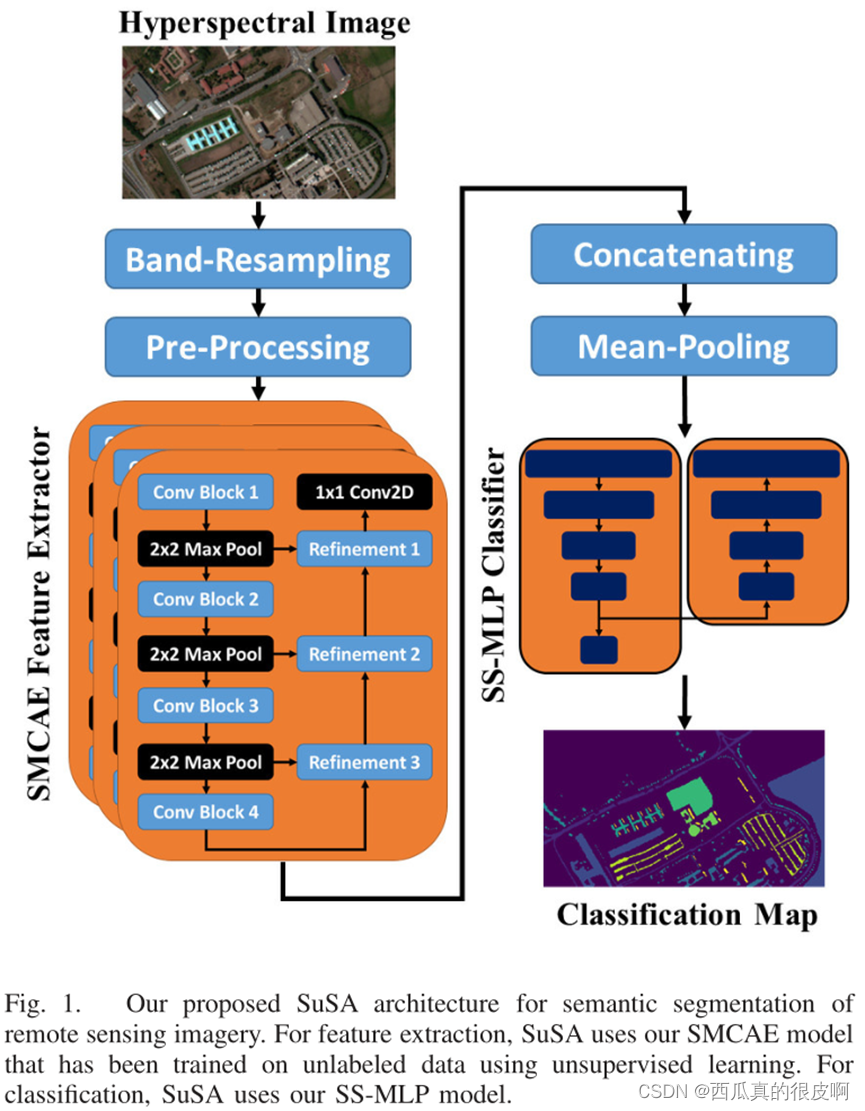
?(3)stacked multi-loss convolutional autoencoder, SMCAE
MCAE�����ϻ���һ���Ա�����,����ͼ��ʾ,�����һ���������ṹ,�Ҳ���һ���������ṹ,�м��ö����ʧԼ��,���յ�������X�� ֮�����ʧԽСԽ�á�
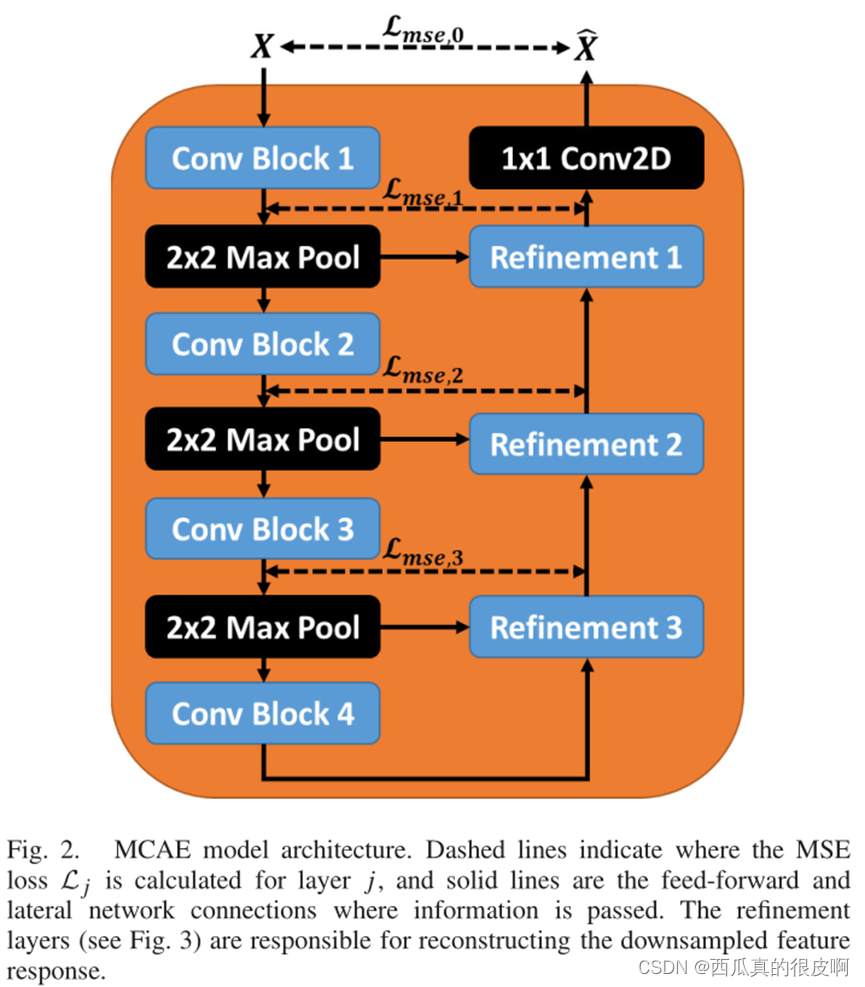
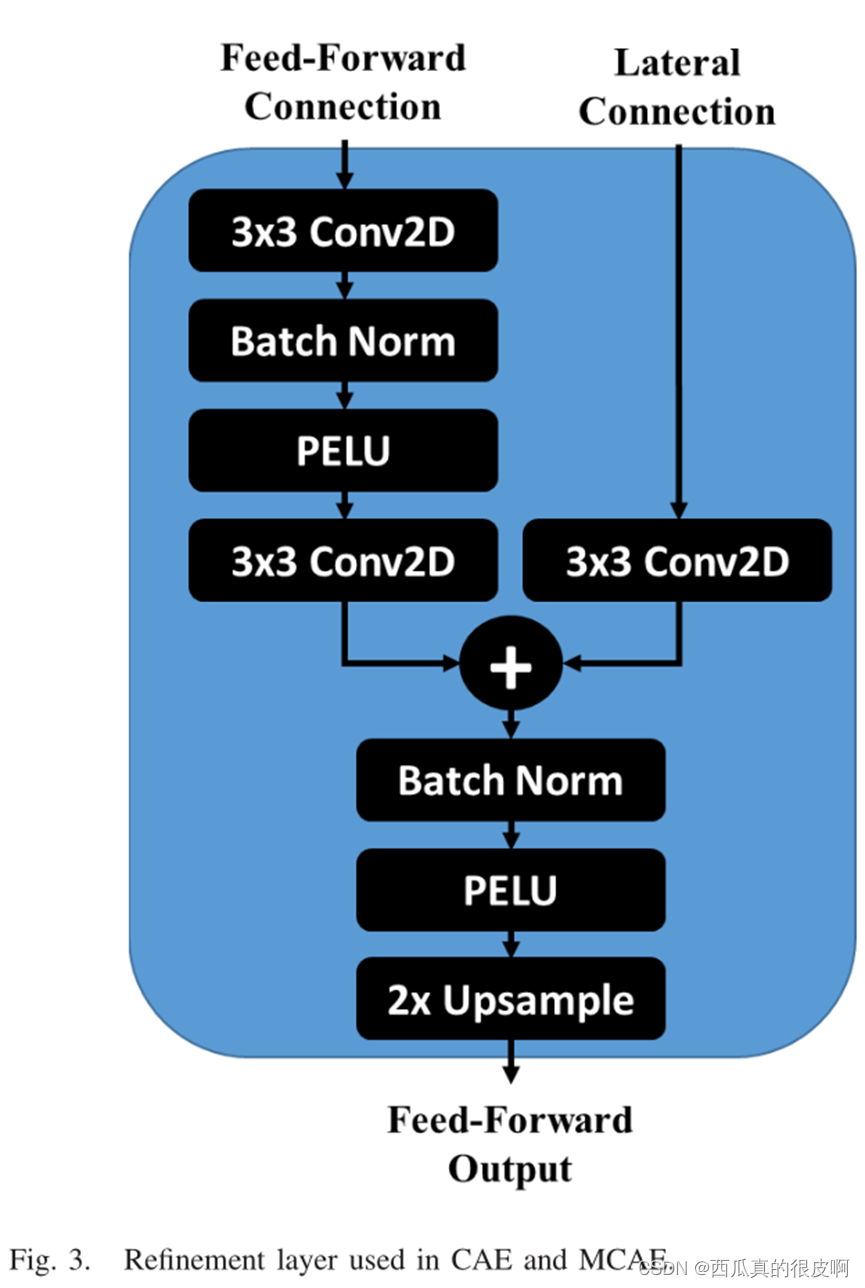
?�������ṹ��,refinement�Ľṹ����ͼ��ʾ,����,����Lateral Connection�������DZ������ж�Ӧ�����������������(Ҳ������Ծ����)��
?
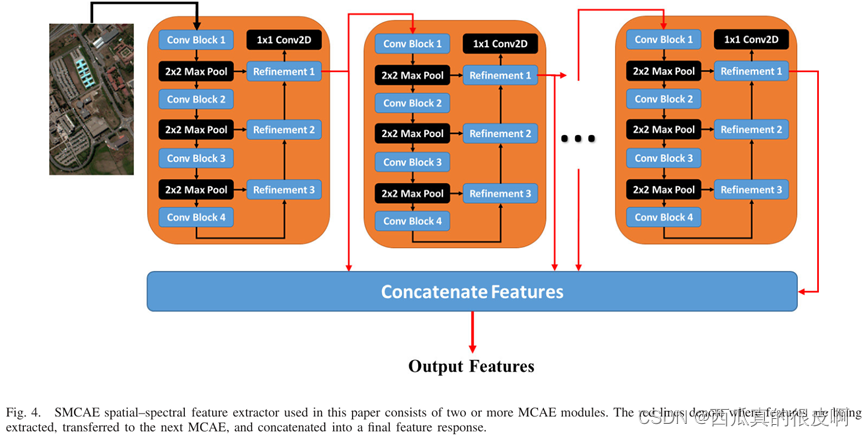
������������,������������ϵ�иĽ�,��ջ����ľ����Զ�������(stacked multi-loss convolutional autoencoder, SMCAE),ÿһ���Ա�������������һ�����һ�����ز�����,����ѵ�������
����ͼ��ʾ:
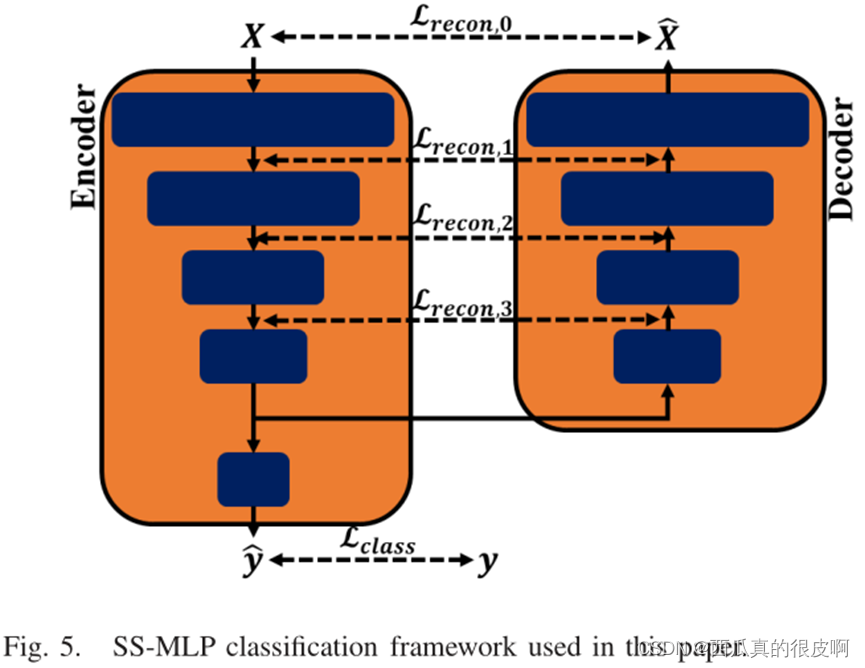
(4)��ල����֪��������Semisupervised Multilayer Perceptron Neural Network
SS-MLP���жԳƵı�����-��������ܡ�ǰ�������������ԭʼ������зֶ�,�������ع�ԭʼ�����ѹ��������ʾ���ؽ���Ϊһ�ֶ����������,���Է�ֹ��ѵ���������ٵ������ģ����ϡ�SS-MLPͨ����С���ܼල���ල��ʧ��ѵ����
?
?������������
�������ѧϰ��˵,���ݼ������ѧϰ������֮��,Ϊ��Ӧ���������ٵ����,���з�����������:

?1. ���ݺϳɡ���������
�������ݺϳ�,��һЩר�ŵĺϳ�����,���ﲻ������������һ����һЩ���õ����㷽��:
?2.��ල
��һ����Ҫ�ο���һƪ����,�Լ�����������д��һƪ֪��,д�ķdz���:[CVPR 2021] CPS: ���ڽ���α�ල�İ�ල����ָ� - ֪�� (zhihu.com)
2.1��ල֪ʶѧϰ
���ǽ���ල�ָ�Ĺ����ܽ�Ϊ����:self-training��consistency learning(һ����ѧϰ)��һ����˵,self-training�����ߴ����Ĺ���,��consistency learning�����ߴ����ġ�
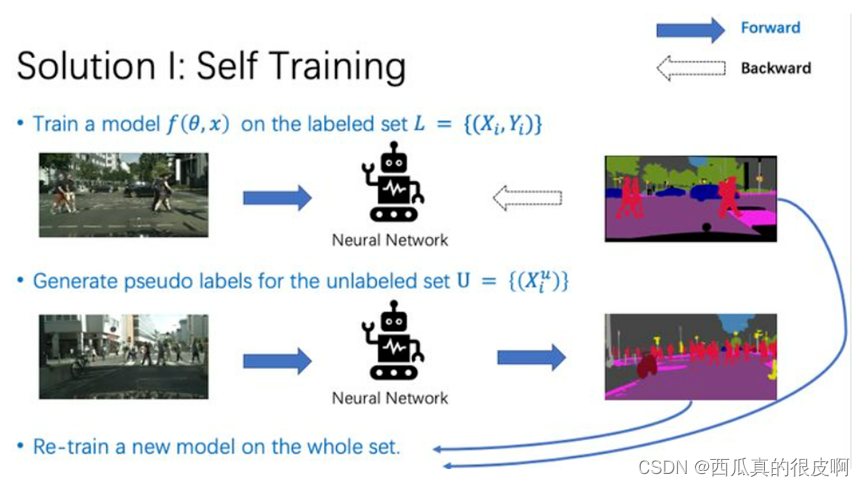
(1)Self-training
Self-training��Ҫ��Ϊ3������һ��,�������б�ǩ������ѵ��һ��ģ�͡��ڶ���,������Ԥѵ���õ�ģ��,Ϊ�ޱ�ǩ���ݼ�����α��ǩ��������,ʹ���б�ע���ݼ�����ֵ��ǩ,���ޱ�ע���ݼ���α��ǩ,����ѵ��һ��ģ�͡�
?(2)Consistency learning
Consistency learning�ĺ���idea��:����ģ�ͶԾ�����ͬ�任��ͬһ���������Ƶ����������任��������˹�����������ת����ɫ�ĸı�ȵȡ�
Consistency learning������������:smoothness assumption �� cluster assumption��
Smoothness assumption: samples close to each other are likely to have the same label.
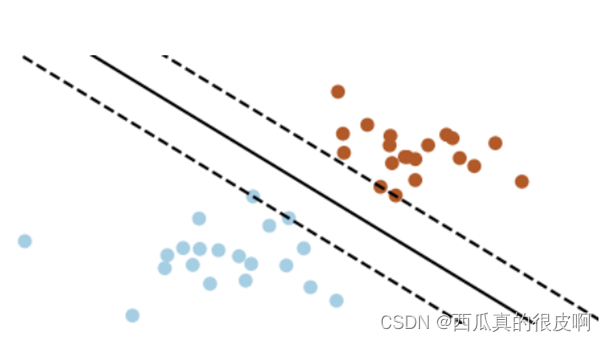
Cluster assumption: Decision boundary should lie in low-density regions of the data distribution.
Smoothness assumption����˵���Ľ�������ͨ������ͬ������ǩ��������ͼ��,��ɫ���ڲ�����С����ɫ�����ɫ��ľ��롣Cluster assumption��˵,ģ��Ԥ��ľ��߽߱�,ͨ�����������ֲ��ܶȵ͵�������ô����������ܶȵ͡�?����֪��,��������֮�������,�����DZȽ�ϡ���,��ôһ���õľ��߽߱�Ӧ�þ����ܴ�����������ϡ�������,�������ܸ��õ����ֲ�ͬ����������������ͼ������������,�����������߽߱�,ʵ�ߵķ���Ч�����Ժ���������������,����Ǵ��ڵ��ܶ�����ľ��߽߱硣
��ô,consistency learning��������ģ��Ч������?��consistency learning��,����ͨ����һ�����������Ŷ�(���������ȵ�),���ı�������feature space�е�λ�á�������ϣ��ģ�Ͷ��ڸı�֮�������,Ԥ���ͬ�����������ͻᵼ��,��ģ������������ռ���,ͬ����������������ĸ���,����ͬ����������ĸ�Զ��ֻ������,�Ŷ�֮��Ų����õ�ǰ��������������ĸ��Ƿ�Χ����Ҳ�͵���ѧϰ��һ������compact���������롣
��ǰ,Consistency learning��Ҫ����������:mean teacher,CPC,PseudoSeg��
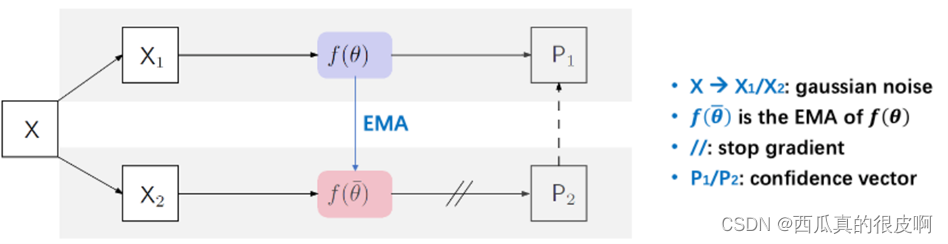
�� mean teacher
Mean teacher��17�������ģ�͡�����һ������ͼ��X,���Ӳ�ͬ�ĸ�˹������õ�X1��X2�����ǽ�X1��������f(��)��,�õ�Ԥ��P1;���Ƕ�f(��)����EMA(����Ȩ��),�õ���һ������,Ȼ��X2�������EMAģ��,�õ���һ�����P2�����,������P2��ΪP1��Ŀ��,��MSE lossԼ����
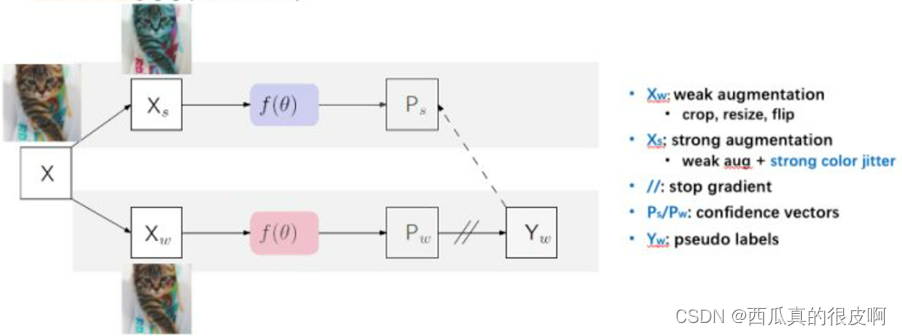
��??PseudoSeg
PseudoSeg��google������ICLR 2021�Ĺ��������Ƕ������ͼ��X�����β�ͬ��������ǿ,һ�֡�����ǿ��(random crop/resize/flip),һ�֡�ǿ��ǿ��(color jittering)�����ǽ�������ǿ��ͼ������ͬһ������f(��),�õ�������ͬ���������Ϊ������ǿ����ѵ�������ȶ�,�����á�����ǿ�����ͼ����Ϊtarget��
�� CPC:Cross Probability consistency
CPC�Ƿ�����ECCV 2020�Ĺ���(Guided Collaborative Training for Pixel-wise Semi-Supervised Learning)���汾��������,ֻ���������ǵĺ��Ľṹ�����ǽ�ͬһͼ������������ͬ����,Ȼ��Լ�������������������Ƶġ����ַ�����Ȼ��,����Ч���ܲ�����
?
CPC
GTC(CPC��֮ǰ��ԭ����)
?2.2 �������
��ƪ�����Ƿ�����2021CVPR��,����Ȥ����ȥ��ԭ���ġ�
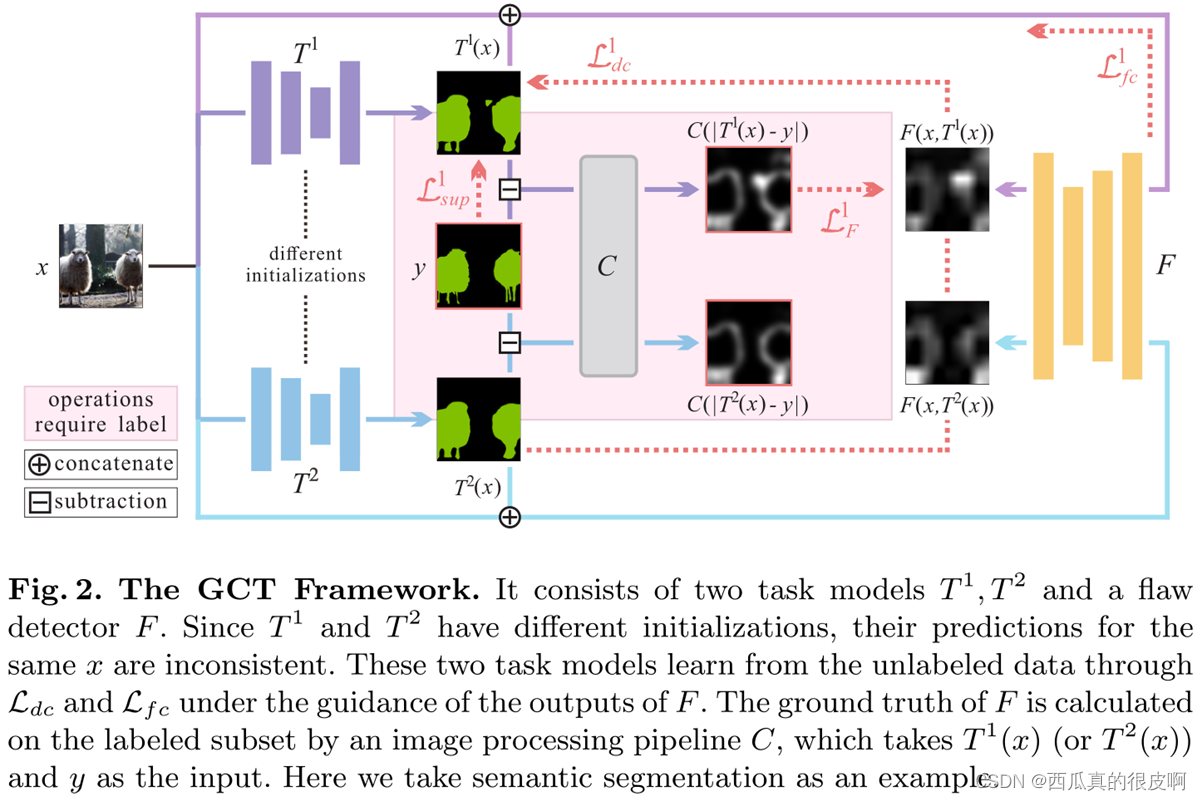
ʾ��:Chen X ,? Yuan Y ,? Zeng G , et al. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision[C]// 2021.
����N���б�ǩ��Ӱ��,M���ޱ�ǩ��Ӱ��,��ල����ָ������Ŀ����ͨ�����б��ͼ����ޱ��ͼ����о���ѧϰ�ָ����硣
����α�ල���÷������������зָ��������:
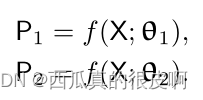
���������������ͬ�Ľṹ,��Ȩֵ��1�ͦ�2��ʼ����ͬ������X����ͬ������,P1 (P2)�Ƿָ�����ͼ,��softmax��һ������������������ķ���������˵������:
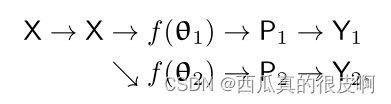
�����Y1 (Y2)��Ԥ���one-hot��ǩӳ��,��Ϊα�ָ�ӳ�䡣��ÿ��λ��i,��ǩ����y1i (y2i)������Ӧ����������p1i (p2i)�����one-hot���������Ƿ����������汾����ͼ��ʾ,����û�������������а�����ʧ�ල:
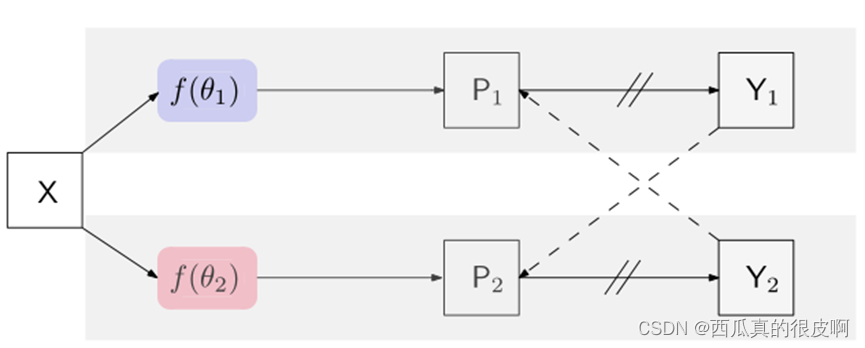
?ѵ��Ŀ�����������ʧ:�ල��ʧLs�ͽ���α�ල��ʧLcps���ල��ʧLs�������������зָ������ϱ��ͼ��ı����ؽ�������ʧ���ƶ���:
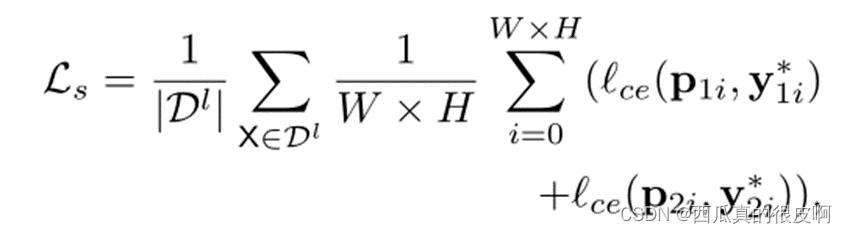
?����α�ල��ʧ��˫���:һ�Ǵ�f(��1)��f(��2)������ʹ��һ������f(��1)��������ؼ����ȱ�ǩͼY1���ල��һ������f(��2)�����ؼ����Ŷ�ͼP2,����һ�������Ǵ�f(��2)��f(��1)����δ������ݵĽ���α�ල��ʧдΪ: