混淆矩阵,精确率,召回率,特异度作为卷积神经网络的模型性能评价指标,它们的计算和绘制具有非常重要的意义,特别是在写论文的时候,我们往往需要这些指标来证明我们模型的优异性,这里给出相应的代码方便大家计算和绘制自己的混淆矩阵和计算各种指标。我这里是使用的网上开源的玉米病害数据集。下面给我的整个项目工程的数据集代码链接,你替换成你的数据集,模型结构代码即可。
首先是文件夹摆放方式:
num_classes.json为写自己数据种类的文件:
按照这样写入自己的数据种类名称即可,如果种类比这多或者少,相应删减即可

data文件夹下放置自己用来绘制混淆矩阵的数据集,数据集每一类文件夹的名称为这类数据集种类的名称即可:
?lenet.pth为自己训练的模型权重,这里将这个换成你自己的模型权重即可。
main.py为绘制混淆矩阵和计算其他指标的代码,我们需要注意一下这里,修改成自己的模型类的名称。
from model import lenet
#自己模型类的名字叫啥,这个lenet就改成啥,
#举例,如果是alexnet,就改成from model import alexnet
#模型代码放入model.py文件中自己模型类的名称,自行查看class后面,我这里是lenet

?main.py
import json
import torch
import matplotlib.pyplot as plt
from torchvision import transforms, datasets
import numpy as np
from tqdm import tqdm
from prettytable import PrettyTable
from model import lenet
#自己模型类的名字叫啥,这个lenet就改成啥,
#举例,如果是alexnet,就改成from model import alexnet
#模型代码放入model.py文件中
class Confusion_Matrix(object):
def __init__(self , labels: list):
self.num_classes = len(labels)
self.matrix = np.zeros((len(labels), len(labels)))
self.labels = labels
def Matrix_update(self, preds, labels):
for i, j in zip(preds, labels):
self.matrix[i, j] += 1
def Matrix_summary(self):
sum_TP = 0
for i in range(self.num_classes):
sum_TP += self.matrix[i, i]
accuracy = sum_TP / np.sum(self.matrix)
# "精确率", "召回率", "特异度"
table = PrettyTable()
table.field_names = ["num_classes", "Precision", "Recall", "Specificity"]
#num_classes 数据种类名称、Precision 精确率、Recall 召回率、Specificity 特异度
avaerage_Precision = []
avaerage_Recall = []
for i in range(self.num_classes):
TP = self.matrix[i, i]
FP = np.sum(self.matrix[i, :]) - TP
FN = np.sum(self.matrix[:, i]) - TP
TN = np.sum(self.matrix) - TP - FP - FN
Precision = round(TP / (TP + FP), 3) if TP + FP != 0 else 0.
avaerage_Precision.append(Precision)
Recall = round(TP / (TP + FN), 3) if TP + FN != 0 else 0.
avaerage_Recall.append(Recall)
Specificity = round(TN / (TN + FP), 3) if TN + FP != 0 else 0.
table.add_row([self.labels[i], Precision, Recall, Specificity])
print(table)
print("模型全部种类的总体识别率: ", accuracy)
print('平均精确率: ' , sum(avaerage_Precision)/self.num_classes)
print('平均召回率: ', sum(avaerage_Recall) / self.num_classes)
def Matrix_plot(self):
matrix = self.matrix
plt.imshow(matrix, cmap=plt.cm.Reds)
plt.xticks(range(self.num_classes), self.labels, rotation=45)
plt.yticks(range(self.num_classes), self.labels)
plt.colorbar()
plt.xlabel('真实类别')
plt.ylabel('预测类别')
plt.title('混淆矩阵')
plt.rcParams['font.sans-serif'] = ['SimHei']#设置汉语显示
plt.rcParams['axes.unicode_minus'] = False
# 在图中标注数量/概率信息
thresh = matrix.max() / 2
for x in range(self.num_classes):
for y in range(self.num_classes):
fin_matrix = int(matrix[y, x])
plt.text(x, y, fin_matrix,
verticalalignment='center',
horizontalalignment='center',
color="white" if fin_matrix > thresh else "black")
plt.tight_layout()
plt.savefig('./混淆矩阵.jpg')#保存图片到当前文件夹路径下,图片格式为jpg,也可以修改成其他格式,例如png等,根据需要自行修改即可
plt.show()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#gpu CUDA的使用情况
print(device)
data_transform = transforms.Compose([transforms.Resize((120, 120)), #这里的预习处理方式最好跟你训练代码里面验证集的预处理方式保持一致,这样可以保证结果的准确性
transforms.ToTensor(), #这里务必写成跟原数据验证集的图片预处理方式
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
image_root = "./data" # 画混淆矩阵图片数据路径,相对路径,绝对路径均可填写。不会填写的就放置到当前文件夹下的data文件中即可
val_data = datasets.ImageFolder(root = image_root , transform=data_transform)
val_loader = torch.utils.data.DataLoader(val_data , batch_size = 16 , shuffle=False , num_workers=0)
net = lenet()#这里改成直接的模型类的名字
model_path = "lenet.pth"#这里写自己训练好模型的路径,直接放到当前文件夹下即可
net.load_state_dict(torch.load(model_path, map_location = device))#读取自己的模型
net.to(device)
num_classes_path = './num_classes.json'#读取种类名称放置文件内数据种类的名称
json_file = open(num_classes_path, 'r',encoding='UTF-8')
class_indict = json.load(json_file,encoding='UTF-8')
nums_class = list(class_indict.keys())
nums_class.sort()
labels = [class_indict[i] for i in nums_class]
print('数据种类名称:' ,labels)
confusion = Confusion_Matrix(labels)
net.eval()
with torch.no_grad():
for val in tqdm(val_loader):
val_images, val_labels = val
outputs = net(val_images.to(device))
outputs = torch.argmax(outputs, dim=1)
confusion.Matrix_update(outputs.to("cpu").numpy(), val_labels.to("cpu").numpy())
confusion.Matrix_summary()
confusion.Matrix_plot()
model.py用来放置自己模型结构的代码,这里千万要换成自己模型结构的代码
from torch import nn
#自己模型结构的代码就放到这里,缺什么库就导入什么库
class lenet(nn.Module):
def __init__(self):
super(lenet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[48, 27, 27]
nn.Conv2d(16, 32, kernel_size=5), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[128, 13, 13]
nn.Flatten(),
nn.Linear(23328, 2048),
nn.Linear(2048, 2048),
nn.Linear(2048, 7),
)
def forward(self, x):
x = self.model(x)
return x?将这里一切工作都做好之后,运行main.py文件,
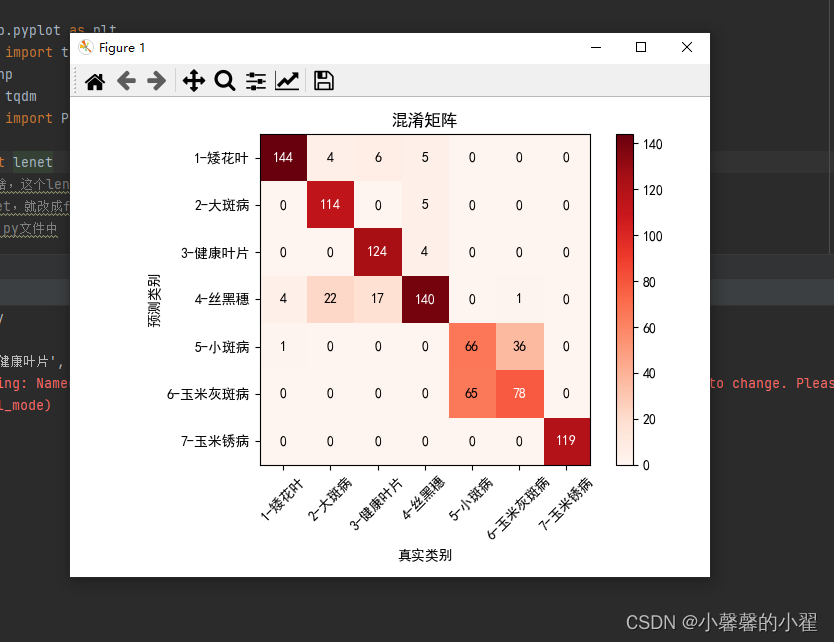
会输出你数据种类名称的数组,计算精确率,召回率和特异度和平均精确率和平均召回率,还会绘制相应的混淆矩阵图,且自动将图片保存在当前文件夹下。

?
代码下载链接:https://pan.baidu.com/s/1gXoVh2rfc19OgpGRS3IYjg?
提取码:8mqb
? ? ? ?如果觉得有用麻烦点个赞,有啥问题在评论中指出来,看到会回复,非常感谢支持