ЁОжЊЪЖеєСѓ2018ЁПKnowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
?? ТлЮФ: https://arxiv.org/pdf/1811.03233.pdf
вЛ жївЊЫМЯы:
??ШУНЬЪІЭјТчВуЕФЩёОдЊЕФМЄЛюБпНчОЁСПКЭбЇЩњЭјТчЕФвЛбљЁЃЫљЮНЕФМЄЛюБпНчжИЕФЪЧЗжРыГЌЦНУц(еыЖдЕФЪЧRELUетжжМЄЛюКЏЪ§),ЦфОіЖЈСЫЩёОдЊЕФМЄЛюгыЪЇЛюЁЃБОЮФЬсГіЕФМЄЛюзЊвЦЫ№ЪЇ,ШУНЬЪІЭјТчгыбЇЩњЭјТчжЎМфЕФЗжРыБпНчОЁПЩФмвЛжТЁЃ
Жў ЮЪЬтРДдДМАЭЦЕМФЃаЭ:
1. ЮЪЬтМАЭЦЕМ
??

??
??ЖЈвх: НЬЪІЭјТчЕНзюКѓвўВиВуЕФКЏЪ§T,ЯргІбЇЩњЮЊS(дкМЄЛюКЏЪ§жЎЧА)ЁЃЮЊСЫЗНБу,ЯШМйЩшНЬЪІбЇЩњзюКѓвўВиВуОпгаЯрЭЌГпДчДѓаЁЮЊRMЁЃ
??еыЖдЭМЦЌI,ЯргІгаT(I),S(I)
ЁЪ
\in
ЁЪ RMЁЃ
??
??вдЧАЪЙгУЕФЫ№ЪЇКЏЪ§жаШчЯТ(1):

??ЦфжаМЄЛюКЏЪ§
Ів
(
x
)
=
m
a
x
(
0
,
x
)
\sigma(x)=max(0,x)
Ів(x)=max(0,x)ЁЃ
??
??

??ВњЩњЕФЮЪЬт: Ы№ЪЇ(1)ЪЙбЇЩњНіНіНќЫЦРЯЪІЕФЩёОдЊЗДгІ,ЕЋНсЙћЕФМЄЛюБпНчПЩФмгаКмДѓЕФВЛЭЌЁЃгШЦфЪЧВЛКУЧјЗжШѕЗДгІКЭЧПЗДгІЁЃ
??
??
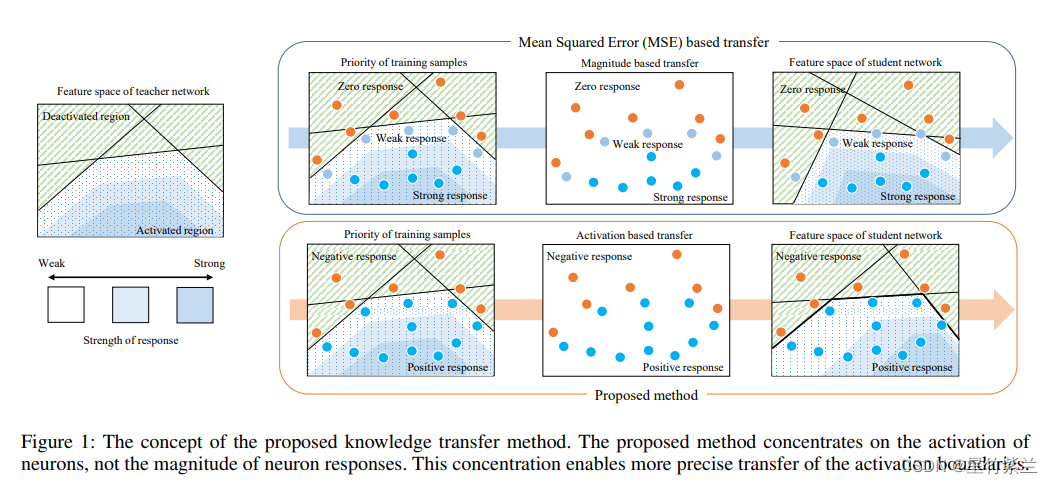
??ЮЊСЫзМШЗЕизЊвЦМЄЛюБпНч,ЮвУЧЕФЯыЗЈЪЧЗХДѓдкМЄЛюБпНчИННќЧјгђЕФПЩКіТдЕФзЊвЦЫ№ЪЇЁЃЮЊСЫЗХДѓЫ№ЪЇ,ЮвУЧЖЈвхСЫвЛИідЊЫиМЄЛюжИЪОЦїКЏЪ§РДБэЪО:

??ЭМ1ЕФЯТАыВПЗжЯдЪОСЫЪЙгУМЄЛюзЊвЦЫ№ЪЇЕФжЊЪЖзЊвЦЁЃЫфШЛЩёОдЊЗДгІЕФДѓаЁУЛгаКмКУЕиДЋЕн,ЕЋЫќБЛбЕСЗвдБЃГжНЬЪІЩёОдЊЕФМЄЛюЁЃвђДЫ,МЄЛюБпНчБЛзМШЗЕиДЋЕнЁЃПМТЧЕНМЄЛюБпНчдкЩёОЭјТчжаЕФживЊад,МЄЛюДЋЕнЫ№ЪЇдкжЊЪЖДЋЕнжаБШОљЗНЮѓВюИќгааЇЁЃ
??гЩгкІб()ЪЧвЛИіРыЩЂКЏЪ§,МЄЛюзЊвЦЫ№ЪЇВЛФмЭЈЙ§ЬнЖШЯТНЕзюаЁЛЏЁЃвђДЫ,ЮвУЧЬсГіСЫвЛИіПЩБЛЬнЖШЯТНЕзюаЁЛЏЕФЬцДњЫ№ЪЇЁЃ
??зюаЁЛЏМЄЛюзЊвЦЫ№ЪЇРрЫЦгкбЇЯАЖўжЕЗжРрЦїЁЃ
?? ШчЙћНЬЪІЩёОдЊЪЧЛюдОЕФдђбЇЩњЩёОдЊЕФЗДгІгІДѓгк0;ШчЙћНЬЪІЩёОдЊЪЧВЛЛюдОЕФ,дђаЁгк0ЁЃНшМјСЫhinge loss:
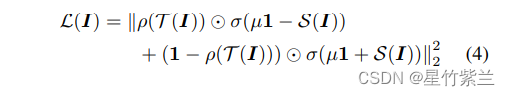
??
2.ВЙГф:
??1).ЕБРЯЪІКЭбЇЩњЕФзюКѓГпДчВЛвЛжТЪБ,ЬэМгСЊЭЈКЏЪ§r:

??
??
??2).ОэЛ§ЭјТчЭЌбљЪЪгУЁЃ

??
Ш§ ЪЕбщНсЙћ:
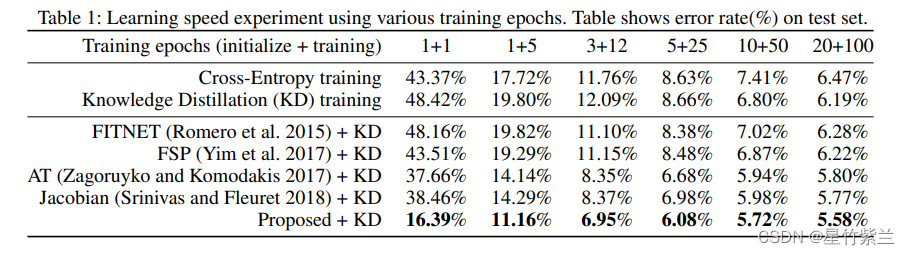
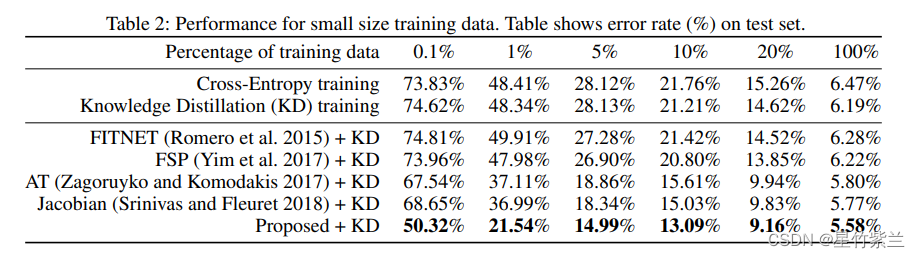
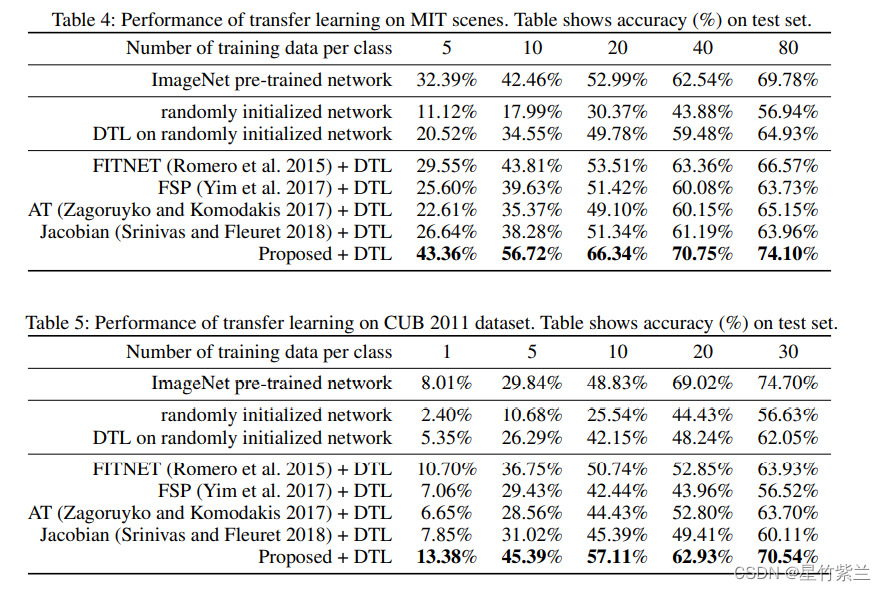
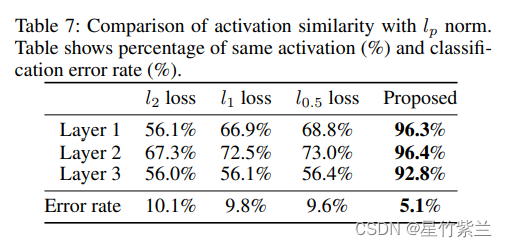
??ЙигкБОЮФЬсГіЕФЬцДњЫ№ЪЇЪЧЗёЪЙЩёОдЊМЄЛюЯрЫЦЁЃЮЊСЫНјааБШНЯ,ЮвУЧЛЙЦРЙРСЫl1КЭl0.5ЕФЫ№ЪЇКЏЪ§,вдМАl2ЕФЫ№ЪЇЁЃ
??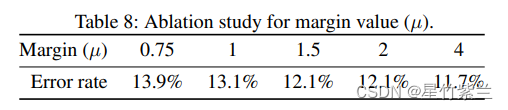
??зюКѓЖдБпдЕжЕІЬНјааСЫЯћШкбаОПЁЃ