前言
未决案件属于没有结案,一直滞留的案件,也没有历史标记,所以属于无监督类数据,适用于K-means算法,将数据分门别类,以让同类别的样本之间差异尽可能小,不同类别间的差异尽可能的大,然后将每个类别特征可视化,从特征出发,提供清理新思路。
一、算法实现过程简单说明
数据量:5018
average silhouette_score:0.52
聚类类别数:5
由于数据中的连续变量很少,分类变量较多,经过相关性验证结合经验,选取了4个连续型变量用于建模,尝试不同的分类变量组合测试,遍历2到5个类别下的聚类效果,并提取每个类别的特征进行验证,得到一个较为理想的聚类,这个过程结合代码可以完整说一篇了,就不详细描述了。
二、部分数据展示

三、类别可视化
1.总体展示
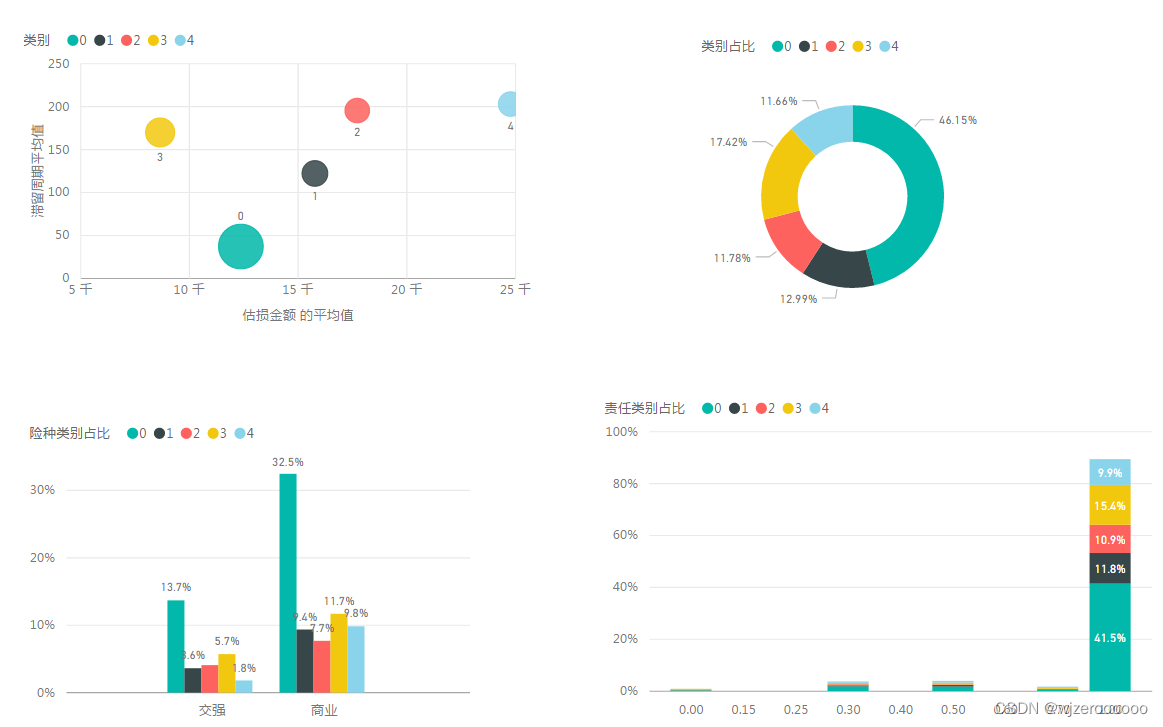
说明:散点图的大小表示数据量
类别0数据量较大,周期及金额较低;类别4周期及金额都较高,且4个类别主要表现在险种为商业险,责任为全责,这和原始数据这两个特征数据量占比较大有一定关系。
2.车型及环节展示

车型方面:类别1主要是以企业客车,类别2为营业货车,其余类别集中在家庭自用车
环节方面:主要集中在单证、定核损、结案、其他四个环节
3.其余特征展示
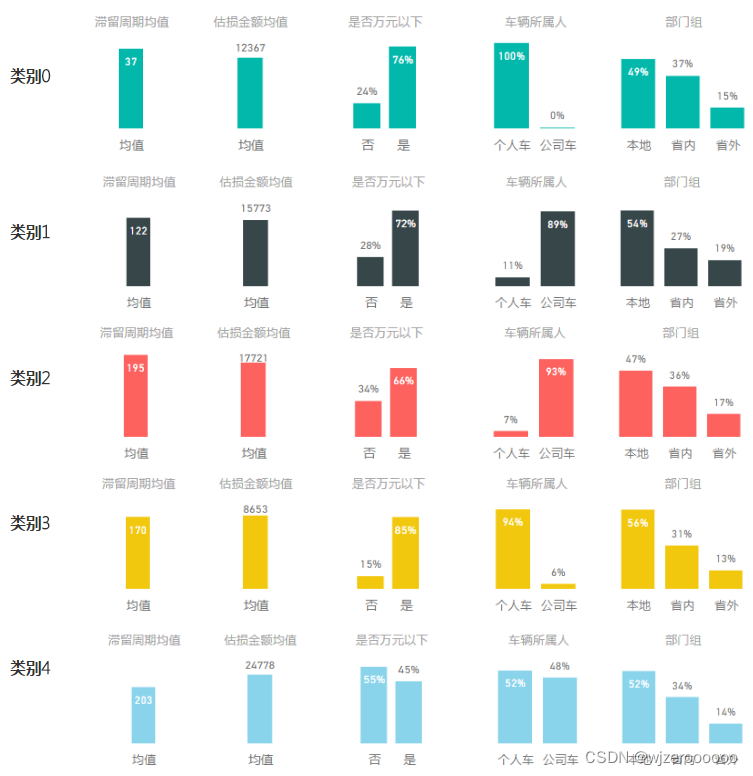
?以上对5个类别都进行了可视化对比,可以比较清晰的看出每个类别的特征差异
例如针对类别2:车型为营业货车、滞留周期195天、估损金额17721元、以小额及公司车占比为主、案件集中在本地及省内环节、险种为商业险、滞留环节为定核损、责任以全责为主,结合先验经验判断是否是配件价格、物损价格争议等原因导致。
总结
1.聚类算法偏向于众,异常检测算法偏向于少,所以两者结果会有差异,但可以结合两者结果对数据进行细分,找出原因,对症下药。
2.针对K-means算法,类别数也不是越多越好,类别太多,大量信息会被碎片化,特征会被分散,聚类效果就会不明显,尽量用较少的类别,达到较好的区分。
3.针对分类变量选取,不是越多越好,特征较多会导致聚类效果不好,根据研究情况选取适合的变量很重要
4.可以结合自身经验将一些变量数据通过数据库人员导入,可以更好的对数据进行分析、建模。