????????��Һ�,��ӭ����������������ѧ���ڶ��ڡ�������һ���˹����ܳ�ѧ��,���һ��ѧ��һ��Transformer����ر����ж����ر�ǿ���ģ��,���÷dz����ջ�,������dz�����������ô�Ҷ�����������������˽⡣Ȼ����Ϊ��Ҳֻ��һ��С��,�����д���ĵط���ϣ�������Ƕ��ָ����
? ? ? ? ��ʵ�����һ�����һ������,�����Լ����������������һ��Ubuntu��GPU����,Ȼ������������һ��AIʵʱ����ʶ���С������ʵ�����ҵ�һ�������Ӵ�Linuxϵͳ,֮ǰֻ��Ϲ��һ��,����û�������������ù��κ�ָ��,�������ϸ��������Ķ�û��,���������������ʵҲ�����˺ܶ�����,Ҳ�кܶ��ջ���Է���,���Ǽ�����Щ���ݵĻ���ε�ƪ����̫����,����������뿴�����ѿ�����������������,�һ�������ڡ�
Ŀ¼
1.4 Masked Multi-Head Attention
5. Transformer��CNN��RNN�������Ʒ���
������������:
���ڷ���:

Transformer��զ���°�
????????Transformer���ģ��Ӧ��˵��AI������ģ�����ȶȺ����ܵ��컨����,���Ѿ��������һ����������ȥ��Transformer�������ҵ��йر��ν�յ�����,ȫ�ǹ������AIģ�͵Ķ������������������һЩ��Conformer��Informer�����ĸĽ���,��Ҳֻ��������Transformer�Ŀ����������,������ǿ������Transformer�����������������ѿ��ܾ�Ҫ����,Ϊʲô��������Transformer��,���ͱ��ν�����κεĹ�ϵ��?
? ? ? ? ��Ͳ��ò��ᵽtransformer����ʱ�������˼�ˡ�
????????Ȼ���Ҿ������ű�ѹ����ͼ:

? ? ? ? �ٿ�����֪��������Transformer�Ľṹͼ:

? ? ? ? �����ƺ�����š�Ҳ������ôһ��ӽ�?
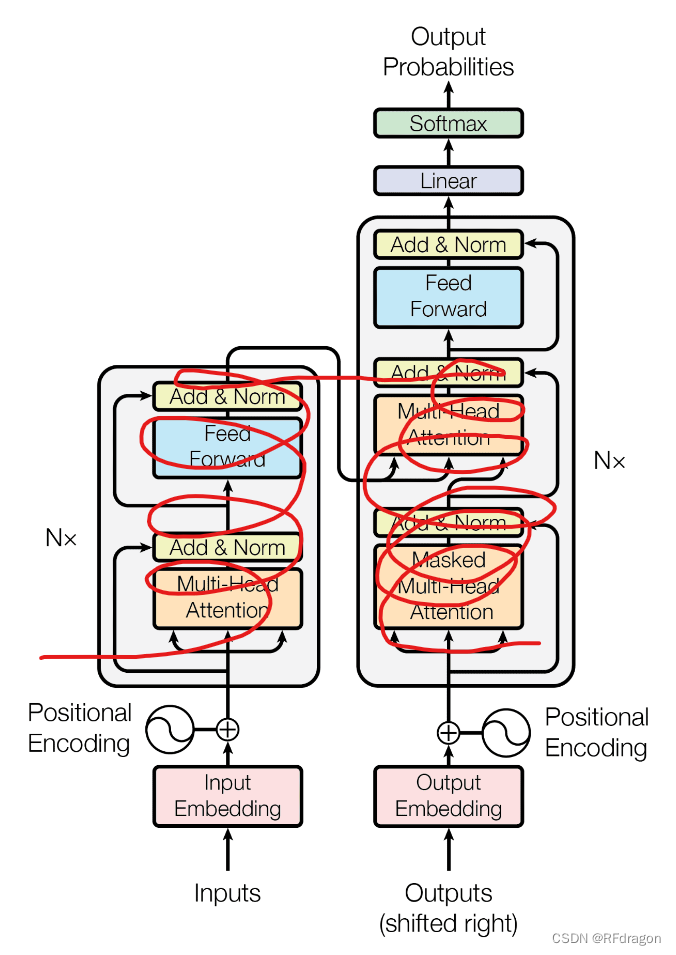
????????����,���Dz���������ˡ��ǽ�����,�Ҿʹ��Ŵ��һ��һ���ؿ���Transformer���Žṹͼ�ϵ�ÿ��ģ�鶼��ʲô����,���Ǻ�����������ô�����ġ�Ȼ����Ϊ����Python�ĸ����˹����ܿ�����϶��з�װ�õ�Transformer������е���ģ��,�����ҾͲ��Ŵ�����,���������Լ��Ĵ�������Ҫ�õ�Transformer�Ļ�,�һ��DZȽ��Ƽ����ֱ���÷�װ�õġ�
1. Multi-Head Attention
? ? ? ? ���Ŵ�Ҷ���������,Transformer��ƪ���ĵ���Ŀ�ͽС�Attention is All You Need��,������Ҳ����ζ�����Multi-Head Attention������Transformer�ĺ���,�����ṹ��ֻ�Ǹ�����Attention���Ӧ�ö������˽�,���û���˽�Ҳû��ϵ,��������1.1��ھͻ�ʹ������Attention����ô���¡�����Multi-Head Attention����ôһ������?��ҿ��ܻ���һ��Attention�����ö��ͷ,����ʲô��˼��,�������ġ�����ʵMulti-Head Attention�Ľṹ�dz���,��һ���Attention��˶��١�
1.1 Attention
????????���Ǵ���ͨAttention�Ľṹ��ʼ˵��,�Ѿ����˽�������ǿ��������ⲿ��,ֱ�ӿ�����1.3��Multi-Head��
????????����˼��,Attention��ʵ����ע��������ע������AI��ʲô��ϵ��?�ٸ�����,������������������һ��AI���������,����������AIһ������,���������Ӣ���������,Ȼ�����������Ӹ�AIһ���漰����������ϵͳ������������ȡ���Ƶȶ��רҵ���������:
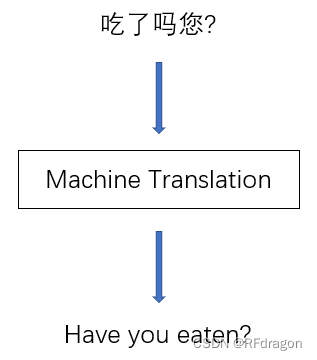
? ? ? ? ���ǿ��Կ���,��������������������ǡ�Have you eaten��,�����и�������˼�������,���Ƿ��֡��ԡ����ԭ���ھ��Ķ����ھ�������֮�����˾�β�ġ�eaten������������֪��,һ���ѭ��������,����LSTM,���������Եķ�ʽ���Ǵ�ǰ����,�Ӿ�������β����,����һ��,����LSTM���ܿ���ѧϰ�������ĸ���ϡ��Źֵ���,���ǻ��������ڴ����Ƚϳ��ľ��ӵĹ����д����Ŵ����žͰѾ����ǵ㶫��������,Ȼ���ž���:
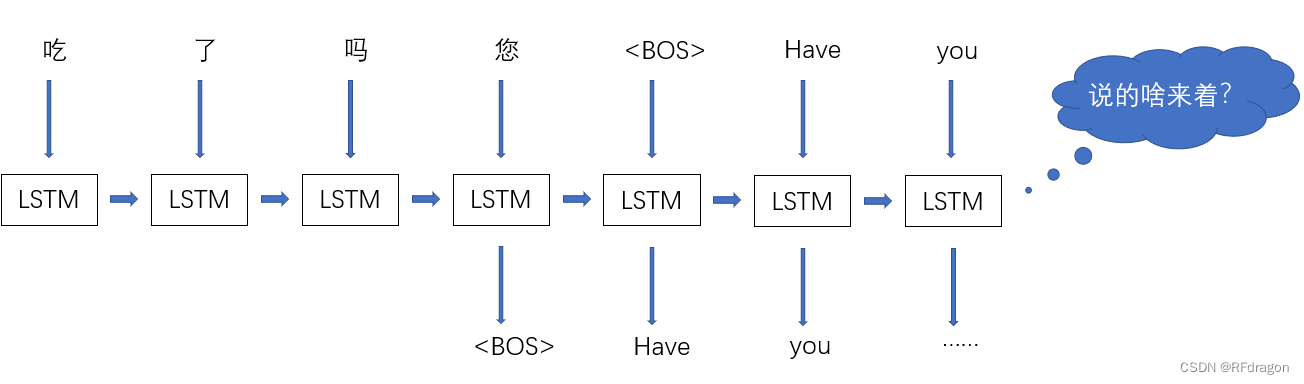
????????���ʱ��,���Ǿ�Ӧ�ø���AI,���ڷ��������you��֮��ͺ���Ȼ��Ӧ�ð�ע��������һ�������ϰ�,��ȥע��һ���Ǹ����ԡ��ò���?
? ? ? ? ����ôʵ����AI����ע������?��ʵ�뷨�ܼ�,����ÿ������һ����֮��,����ģ����������Ĵʴ����,�÷ָߵĴʾͻ��ڷ�����һ���ʵ�ʱ��������ע����������˵ģ���Ѿ��������ˡ�you��,�ǡ�you���ڴ�����Ӧ���������,��ô���ʴ��䶯���DZȽϳ�����,����ģ�;ͺܿ��ܻ��ڷ����ꡰyou��֮������ԡ�������ʴ�߷֡�
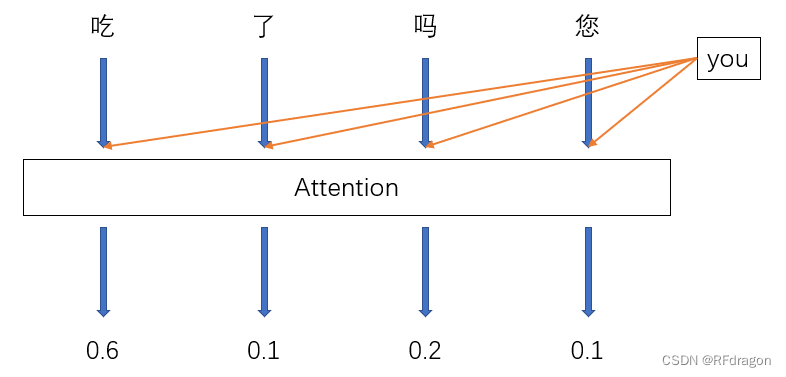
????????Ȼ�����ǰ�Attention�������ĵ÷��Ӹ�������,�����ͻ��ص����һ��������ԡ���
????????Ȼ����������,ģ������ô֪������֮��Ӧ�ýӶ�����?����ʵ��������ѵ�������ġ�����˵���ǰ������ÿ��������Ӧ��Embedding�����͡�you������Ӧ������ƴ����,Ȼ���һ��ȫ����������,�����������һ���÷�,�ٰ����е÷ֹ�һ��Softmax,ת��ΪȨ��,�Ǿ���ѵ��֮��,��������Ȼ�ͻ����������Ȩ��,����������˵��,����������֮��������ʵ�Ȩ�غܿ��ܾͻ��һ�㡣Ȼ�����ǰ���������Ĵʵ�Embedding����Attention������Ȩ����һ����Ȩƽ��,�ͻ�õ�һ��������������ʵ���Ϣ������,������Щ�ȽϹؼ��Ĵʵ���Ϣ�����ر���������,��Ϊ���DZ������˸��ߵ�Ȩ�ء�����,����������������з����ʱ��,���൱������������˵:���������ǰ������Ĵ�����,�Ͱ����дʵ���Ϣ�������������,������������и�����ڡ��ԡ�����Ϣ,���ص�ע��һ�¡���
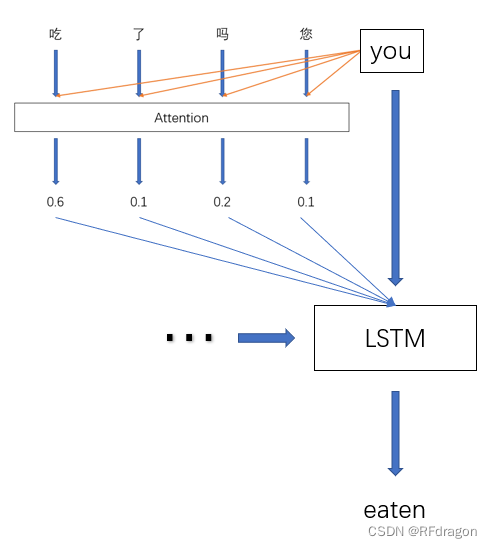
????????��Ȼ,����AttentionȨ�صķ�ʽ��ʵ�dz����,ֱ����ȫ������������һ���ð취,����Ҳ���Բ���,����˵���Լ����ϸ�����õĴ�(Ҳ������ͼ�еġ�you��)�������ÿ����֮����������ƶȻ��ߵ��,��Щ���ǿ��е�,���������Ȼ��Ȼ�ظ��������Attention�ķ������е���������Ҳ��һ����ֱ��������ʵ�Embeddingȥ����Attention,�����ȶ���ЩEmbeddingԤ����һ��,����˵�������ǹ�һ��encoder,Ȼ���ù���encoder֮��õ��Ľ��ȥ��Attention,����ͨ�����и��õ�Ч����
1.2 Self-Attention
????????˵��Multi-Head Attention,�Ͳ��ò��ᵽSelf-Attention���������ǿ����ֻ�����,��Self-Attention����ʲô��?�Լ�ע���Լ�?��ģ��������?
? ? ? ? ��ʵSelf-Attention�dz���,����ͨ��Attention����û��������������һ������,������Ҫ���һ������ģ�͵�ȷ��,����ϣ���ڿ�ʼ����֮ǰ����һ��encoder������ľ��ӽ���һЩԤ����,Ȼ��������:���GҪ����encoder��Ӹ�Attention�ɡ��������и����Ⱑ,������������һ������õĴ�ȥ������ľ�����Attention,�����������ǻ�û��ʼ������,����ʲôȥ�����������Attention��?
? ? ? ? ��,��ֻ������仰�Լ����Լ���Attention�ˡ�
? ? ? ? ���ǻ������桰����������������,���������ڰѡ�������ֹ�encoder,Ȼ�������붯��һ��Attention��������⡣����ʵ�����Attention�Ĺ��̺ܼ�,��������ȫһ��,ֻ�����������ͼ��ġ�you�����ɡ��𡱡�

????????�����Self-Attention,����ô��������������,����ΪʲôҪ��encoder����һ�������Լ����Լ���Attention��,����ʲô����?���ǿ��Կ�����һ������:���Ҳ������ֻ���¯ʯ,��û���ˡ��������������ġ�����ָ������ʲô��?�ǡ��ֻ������ǡ�¯ʯ��?��Ȼ���ֻ�,��Ϊֻ���ֻ��ſ��ܡ�û���ˡ������,��������encoder�ԡ������������Ԥ������ʱ��,��ϣ��ģ���ܶ��ע���ֻ��������ǡ�¯ʯ����Ϊ�˴ﵽ���Ŀ��,���ǾͿ�����Self-Attention���衰�ֻ����϶��Ȩ��,�ѡ������͡��ֻ�������������
1.3 Multi-Head
????????���ڵ��˹ؼ���Multi-Head���֡���ʵMulti-Head��ԭ��Ҳ�ر�������Ǽ������������Ǿ仰:���Ҳ������ֻ���¯ʯ,��û���ˡ��������ڰѡ�������encoder��ʱ��,���ܲ�����Ҫ��ע���ֻ�������Ϣ,��Ҫ��ע��û�硱����Ϣ,���һ����ܺ����ˡ����������ԭ�е���Ϣ��Ҳ����˵,���ǿ���Ҫ��һ������Attention������������ͬ�Ĵ�,����������Attention��˵���ܱȽ��ѡ�����ô����?�ܼ�,�������CNN��ͨ��������,Ҳ��Attention��ͨ��������������?

? ? ? ? ����ͼ��ʾ,���ǿ��ѡ��������������зֱ�������Self-Attention,���ѵõ��Ľ��ƴ��������Ϊ����Attention���������Ȩ�ز�ͬ,�������Ǻܿ��ܻ�ע���ͬ����Ϣ,�Ӷ��ѡ���������Ϣ�Ͳ�ͬ��λ�ù�������������,��������֮���Խ���Multi-Head������Ϊ����Attention�����кö���Դ�һ��,ÿ���Դ�ע������ľ����е�һ���ֹؼ�λ��,Ȼ�����е��Դ��������Ϳ���ע�����λ�á������Multi-Head Attention,��ĺܼ�
1.4 Masked Multi-Head Attention
????????���ǿ��Կ����ṹͼ�����½���һ��Multi-Head Attentionǰ����˸���Masked��,��ʲô�С�Masked����?�Dz�����Ϊ�����ԭ��,��Attention��Ҫ��������?������,��ʵ���Mask����һ������ģ��ѵ����С���ɡ�������֪��,������������ҪAIһ��һ���������������Ĵ�,������һ������������дʵķ���,�������뷭�롰�Ҳ������ֻ���¯ʯ,��û���ˡ���仰,�����ڰ���仰����encoder֮��,��Ҫ��decoderһ����һ���ʵ������������
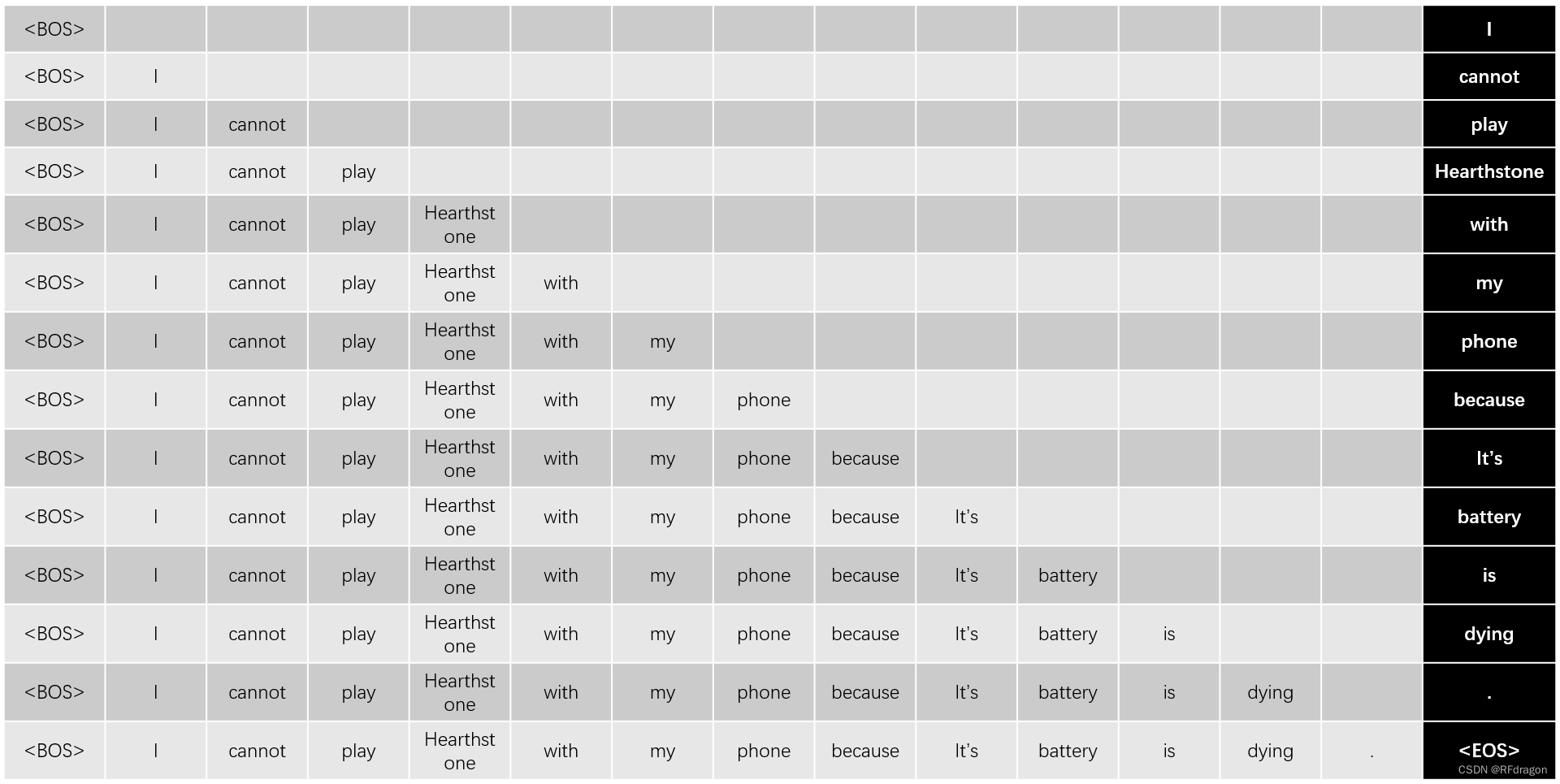
? ? ? ? ����ͼ��ʾ,�����Ȱ�һ���������뿪ʼ�ı��<BOS>(Beginning of Sequence)����decoder,��������<BOS>��encoder������������I��,Ȼ���ٰѡ�<BOS> I���Ž�decoder,��������encoder������������cannot��,�ٰѡ�<BOS> I cannot���Ž�decoder,���������play���������,���ǰѡ�<BOS> I cannot play Hearthstone with my phone because it's battery is dying��(���¼��Ϊ���������롱)�Ž�encoder,�������<EOS>(End of Sequence),��ʾ���������������ѵ����ʱ��,���һ����һ���ʵط���Ч��̫�͡����,��Ȼ�����Ѿ�֪���˷������ȷ��,���ǿ��ѡ�<BOS>������<BOS> I������<BOS> I cannot���������������롱��batchά��ƴ�ӳɵ�������,��Ϊһ��batch�ӽ�decoder,����decoder�Ϳ�����һ�μ���������дʵķ��롣���batch��ʵ������ͼ�����ұߺ�ɫ����һ��ȥ�������������ȡ���Ȼ��ƴ�ӵĹ��̱Ƚ��鷳,�������ǿ������batch�е��������붼�á��������롱����,����ͼ��ʾ:
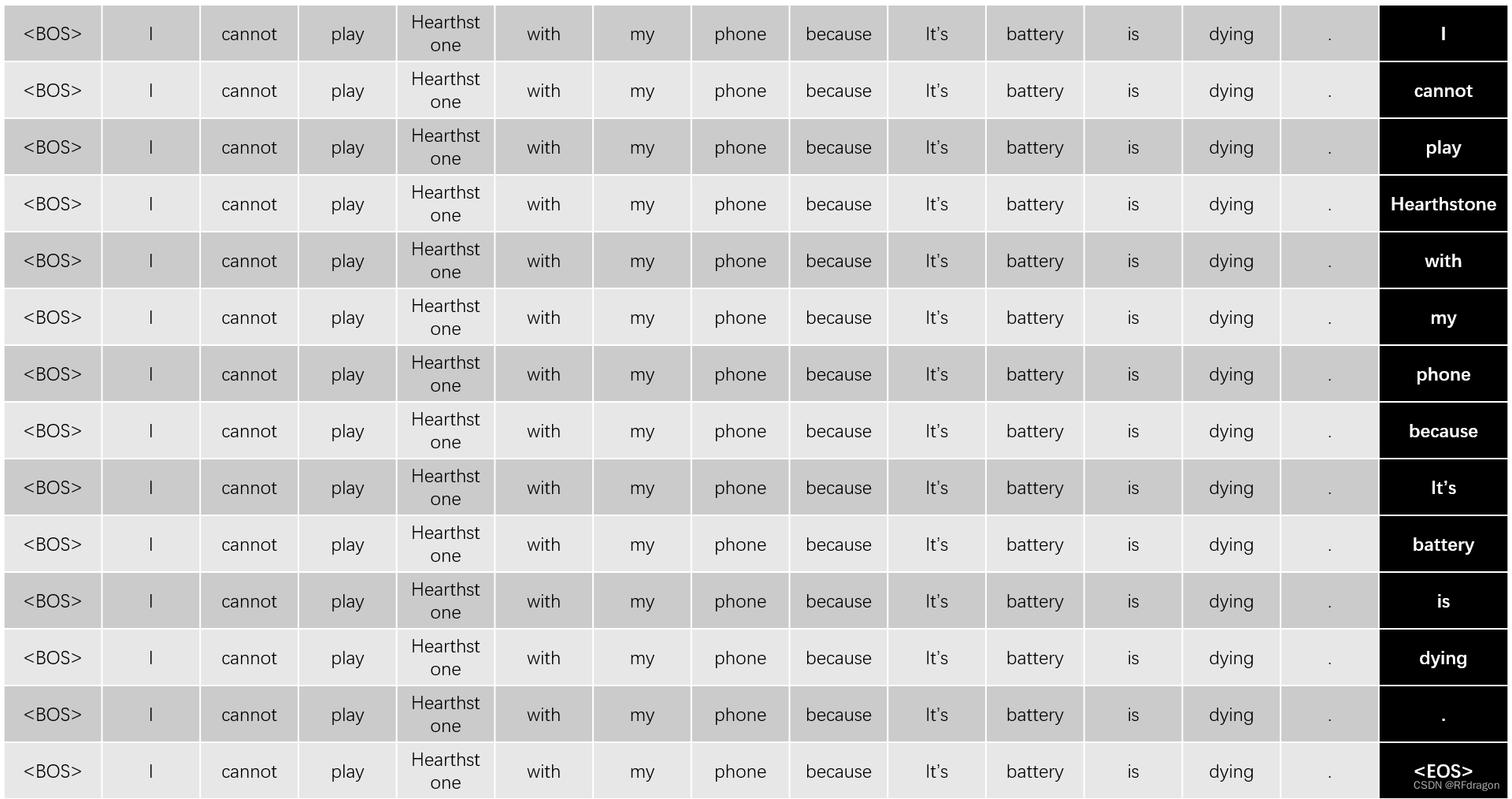
????????������������,�ڷ����һ����(Ҳ���ǡ�I��)��ʱ��,ģ��Ӧ��ֻ���ܵ���<BOS>����һ���ʵ���Ϣ,������ʵ�ʽ��յ����ǡ��������롱,����������˺ܶ�ģ���ڷ��롰I����ʱ��Ӧ�õõ�����Ϣ����ô����?
????????���Ҫ�����Mask������ˡ���ʵMask�����Ͼ�����decoder�е�Attentionע�ⲻ������Ӧ�õõ�����Ϣ����ôʵ�����������?��ʵ�ܼ�Attention�ﲻ���и�Softmax��,�����ȶ������ÿ���ʴ��,�����֮��ͨ��Softmax���ܵõ�����Ȩ�ء�������Ǹ����в�����ģ�Ϳ���������ĵ÷ּ��ϸ������,����Щ�÷�ͨ��Softmax֮��,�����Ȩ��Ӧ�û�������0������һ��,ģ�͵�Attention����ȫ����ע���Щ��,������Ҳ�Ͷ�ģ�͵����û��Ӱ���ˡ�����������������ν�ġ�Mask��:
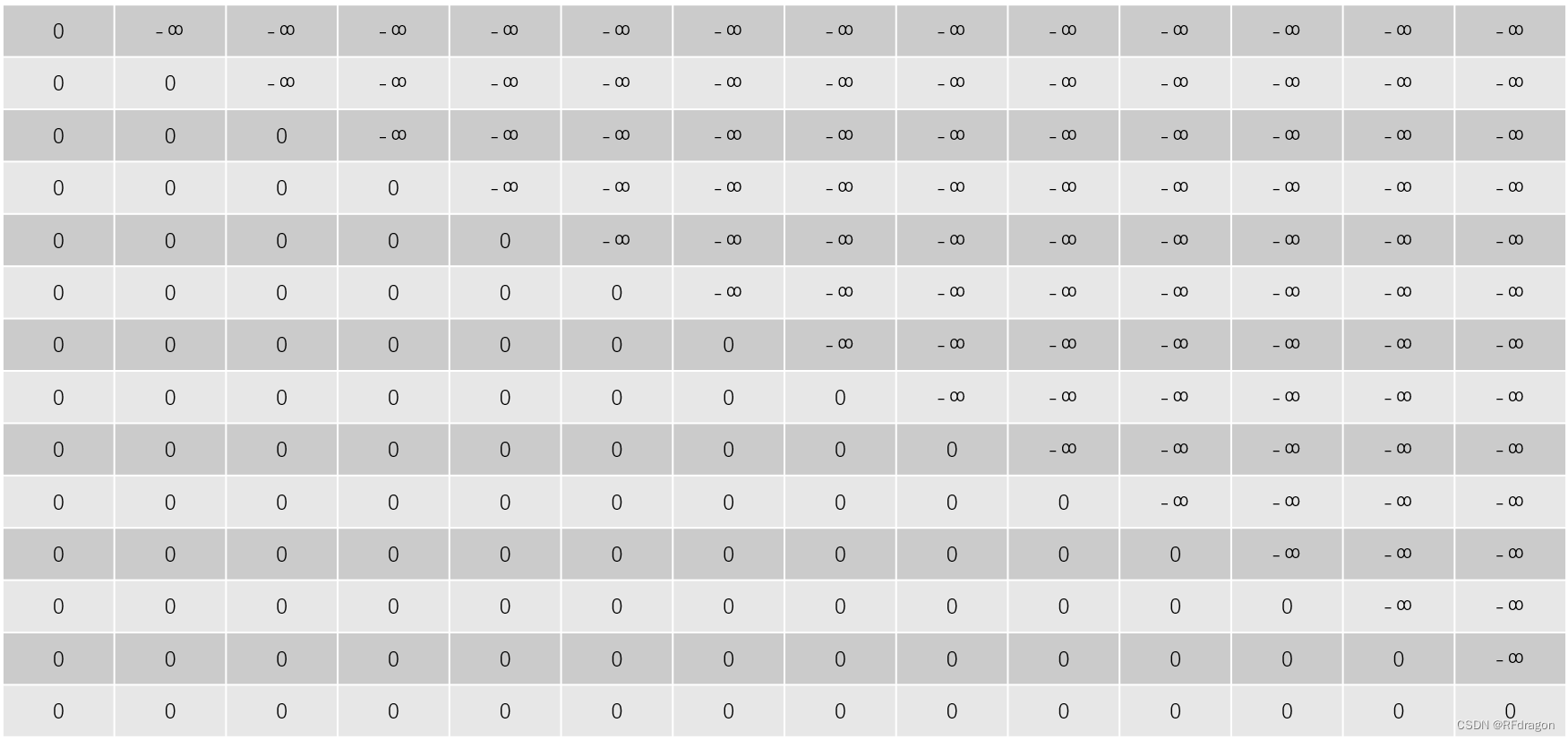
? ? ? ? ��������ÿһ�ж�Ӧbatch�е�����һ�����롣��Ȼ������ʮ�ּ�,�����������û��Ǻܴ��,��ΪֻҪ����������Attention�Ĵ�����,֮���ڹ�Softmax��ʱ��,��Щ���Dz�����ģ�Ϳ��������ݾͻᱻ�Զ����Ե�������,�������Mask����,���ǾͿ��Դ���ӿ�ģ�͵�ѵ������Ȼ,����֤�����Ժ�Ӧ�õ�ʱ�����Dz��������Mask,��Ϊ���Dz��ܸ�ģ���ṩ���յ���ȷ��,����ֻ�ܼ�����decoderһ����һ���ʵط��롣
2. Add & Norm
? ? ? ? Ϊ�˷����Ķ�,����������һ��Transformer�Ľṹͼ��
? ? ? ? ���ǿ��Է��ְ�,�������е�ģ��֮���һ����Add & Norm������ʲô��Add & Norm��?����˼��,Add���Ǽ�,��һ��ģ�������������ResNet����������,���������ݶȴ��������á�Norm����Normalization,��ǰ��Add��һ���õ��Ľ������һ����Ȼ��������ˡ�
3. Positional Encoding
????????���ǿ��Է���,Transformer��encoder��decoder���ֵ����붼����һ��Positional Encoding���е����ѿ��ܲ�֪��ʲô��Positional Encoding��,��ʵ���ǰ������һ���ֵ�λ���������롣����˵���Ҳ������ֻ���¯ʯ,��û���ˡ���仰,���ҡ��ǵ�һ����,���ҾͰ�1���������һЩ������������,�͵õ��ˡ��ҡ���Positional Encoding�����ھ�����ôencode,��ʵ�취Ҳ�кܶ�,����һ�ְ취���Dz�encode,ֱ��ʹ��һ���ֳ��ֵ�λ��,���ҡ�����1,����������2,�Դ����ơ���һ�ְ취���ǡ��ҡ���0,��β�ġ��ˡ���1,�����־��ȷֲ���0��1֮�䡣��Щ�취���ǿ��е�,����Ҳ���������⡣�������仰,һ����10����,һ����100����,����õ�һ�ַ���,�ǵ�һ������һ���ֵ�Encoding��10,�ڶ�����100,���˷dz��ࡣͬ�������һ����,��Ȼһ�����ӳ�,һ�����Ӷ�,�������ֵ�Encoding���Ӧ�ò���ô����?��Ȼ����,��Ϊ���ӵij��Ȳ�����˵�����仰�����һ����֮���ĺ�Զ�����ڶ��ַ�����������,�������ڵ��ֵ�Encoding֮���β��,��һ�仰������������֮�����0.1,���ڶ��仰ֻ��0.01,��Ҳ�Dz�������,��Ϊ���ӳ�������ζ�����ڵ�������֮��Ĺ�ϵ������
????????�ǽ���������ķ�������ʹ��һϵ�е����Һ����Һ�����������֪��,���Һ����Һ������������Ե�,�����Ա������,����ֵ����[-1, 1]�������,�����Ϳ����ڱ������ڵ���Encoding�IJ�ֵ������²������һ���ֵ�Encoding��ֵ̫����ʱ�������Ѿ�Ҫ����,���Һ�����������,Ҳ����˵��һ���֡����߸��֡���ʮ�ĸ��֡�����Encoding���ǽӽ���,�����Ǿ�û���ж�����ֵ��������˰�����ʵ��Ҳ��Ϊʲô������εĿ�ͷ�õĴ��ǡ�һϵ�С����������ǡ�һ�������������ǿ���ʹ�ö�����ڲ�ͬ�ĺ���,��������Щ����������ֻ��
��ô��,����Щ�����������仰��û����һ�����ڡ����ڶ̵ĺ����ܹ�����ذ���һ���ֺ���Χ�����ֵ����λ����Ϣ,�����ڳ��ĺ������Ա�ʾһ���������仰�еľ���λ����Ϣ������һ��,���Positional Encoding������͵õ��˽ϺõĽ����?�Ǿ�����Щ��������ô��Ƶ�������Ͳ���ϸ˵��,����Ȥ�������ǿ����Լ�ȥ��һ�¡�
4. ��������Transformer
????????����������������忴һ��Transformer�Ľṹ������,�Ȱ�������Embedding,��Embedding��Positional Encoding���,Ȼ������encoder��encoder�����IJ���:Multi-Head Attention��Add & Norm��Feed Forward Network����һ��Add & Norm��encoder�е�Attentionȫ����Self-Attention������Ҫע��,���IJ����ǿ��Ա��ظ��ܶ�ε�,Ҳ����˵�����ھ������һ��Add & Norm֮����Խ���һ���µİ������IJ��ֵ�encoderģ�顣ʹ�ö��encoderģ����������Ǹ�����ض�������б��롣�ṹͼ��д�ġ�N�������������˼��
? ? ? ? ���������,���Ƕ�decoder��������Embedding,Ȼ������Positional Encoding,����decoder�����з��롣����decoder��������ʲô���Կ�1.4��ڡ�decoderҲ�����ɺܶ�ģ�����,ÿ��ģ����������:Masked Multi-Head Attention��Add & Norm��Multi-Head Attention����һ��Add & Norm��Feed Forward Network�͵�����Add & Norm������Ҫע��һ��,ÿ��ģ���еĵ�һ��Attention�Ƕ�decoder��������Self-Attention,���ڶ���û��Mask��Attention��encoder��decoder֮���Attention������Self-Attention,Ҳ������1.1����������decoder��ߵ�һ������ȥ��encoder��ÿһ�����ȥ��֡���Ȩ�ء���Ҳ����Ϊʲô���Attention����Masked Attention��
? ? ? ? ����,�ڵõ�decoder�����֮��,����������ȥ��һ��Linear��,����һ��Softmax,�������һ�η��롣��Ȼ,Transformer��ֹӦ���ڷ���,�����к�ǿ��������,�ܹ�ʤ��AI��������ĸ�������,��ȷ��һ��������ʵ��ǿ��ģ�͡�
5. Transformer��CNN��RNN�������Ʒ���
? ? ? ? Transformer��Ȼ��ǿ,������Ҳ����ζ������������ȱ�ġ���ȫ����CNN��RNN�ṹ��һζ����Attention is All You Need����ע��Ҫ�������۵ġ�

????????��ô�Ŷ���,������ʲô��?���Dz����ȿ���CNN��RNN����ʲô�ŵ㡣
????????CNN���ŵ�����ܹ��dz��õ���ȡ�ֲ�����Ϣ,��Ϊÿ�ξ�������ֻ����ݺ�Сһ������Ϣ�ó��������Transformer�������CNN����һ�ŵ�,��ΪAttention��������ȫ�ַ�Χ��Ѱ����Ҫ��ע������ݡ���ʹ����������ȡ��Ч��Ϣ���Ѷȡ���֮���Conformerģ��Ҳ�Ƕ����ȱ�������˸Ľ�,��CNN�����ڽ�Transformer��,��Ҳȷʵ������ģ�͵����ܡ�
? ? ? ? ��RNN���ŵ���Ȼ�����ܹ���ȡ���������е�ʱ��˳�������Ϣ��Transformer��Ȼ���߱�����ŵ�,��ΪAttention�ڵ��������������RNN������Ϊ����Ĵʵ�ʱ��˳����ı䡣��ȷʵ������Ȼ������������е�һ����������ȱ�ݡ�Transformer���������Positional Encoding���Ի����������,���ǻ��Dz��ܴӱ����Ͻ������
? ? ? ? ����Transformer���ŵ�ȴ��ȫ�����ֲ���Щȱ��,��ΪMulti-Head Attention����������������̫������,�����Ǵ���ͼ������Ƶ���ܹ�����Ч����ȡ����Щֵ��ע�����Ϣ,����������Խϵ͵���Ϣ,�����ǿ��ģ�͵�������ȡ������