LSTM(long short term memory)
能够让你可以在序列中学习非常深的连接 ,LSTM 即长短时记忆网络,甚至比 GRU更加有效
GRU and LSTM
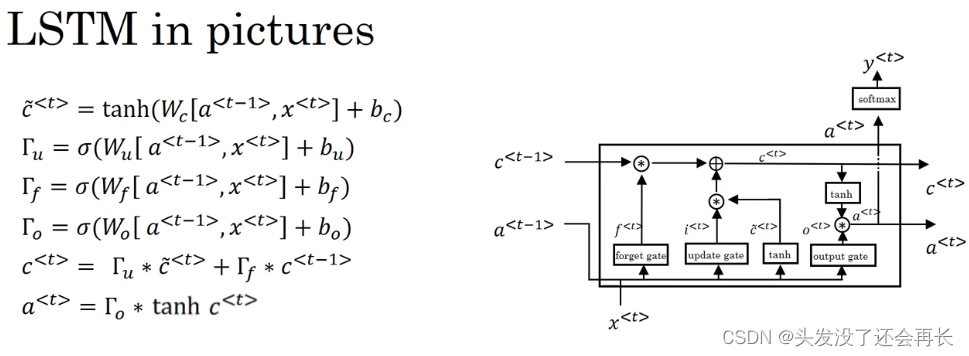
记忆细胞 c ,使用𝑐?<𝑡> = 𝑡𝑎𝑛?(𝑊𝑐[𝑎<𝑡?1>, 𝑥<𝑡>] + 𝑏𝑐来更新它的候选值𝑐?<𝑡>注意了,在LSTM 中我们不再有𝑎<𝑡> = 𝑐<𝑡>的情况,这是现在我们用的是类似于左边这个式子,但是有一些改变,现在我们专门使用𝑎<𝑡>或者𝑎<𝑡?1>,而不是用𝑐<𝑡?1>,我们也不用𝛤𝑟,即相关门。像以前那样有一个更新门𝛤𝑢和表示更新的参数𝑊𝑢,𝛤𝑢 = 𝜎(𝑊𝑢[𝑎<𝑡?1>, 𝑥<𝑡>] + 𝑏𝑢),用遗忘门(the forget gate),我们叫它𝛤𝑓,所以这个𝛤𝑓 = 𝜎(𝑊𝑓[𝑎<𝑡?1>, 𝑥<𝑡>] + 𝑏𝑓),新的输出门,𝛤𝑜 = 𝜎(𝑊𝑜[𝑎<𝑡?1>, 𝑥<𝑡>]+> 𝑏𝑜);于是记忆细胞的更新值𝑐<𝑡> = 𝛤𝑢 ? 𝑐?<𝑡> + 𝛤𝑓 ? 𝑐<𝑡?1>,这给了记忆细胞选择权去维持旧的值𝑐<𝑡?1>或者就加上新的值𝑐?<𝑡>,所以这里用了单独的更新门𝛤𝑢和遗忘门𝛤𝑓,最后𝑎<𝑡> = 𝑐<𝑡>的式子会变成𝑎<𝑡> = 𝛤𝑜 ? 𝑐<𝑡>.

LSTM
在这张图里是用𝑎<𝑡?1>, 𝑥<𝑡>一起来计算遗忘门𝛤𝑓的值,还有更新门𝛤𝑢以及输出门𝛤𝑜。然后它们也经过 tanh 函数来计算𝑐?<𝑡>,这些值被用复杂的方式组合在一起,比如说元素对应的乘积或者其他的方式来从之前的𝑐<𝑡?1>中获得𝑐<𝑡>.
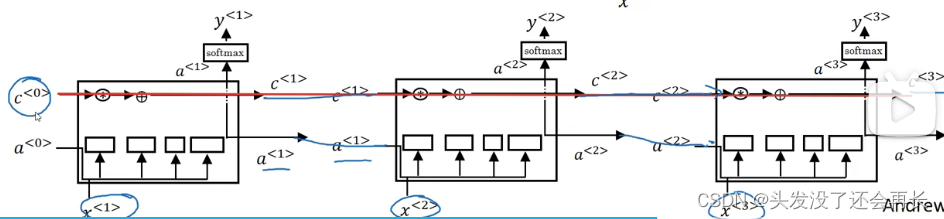
你在这一堆图中看到的,把他们连起来,就是把它们按时间次序连起来,输入𝑥<1>,然后𝑥<2>,𝑥<3>,然后你可以把这些单元依次连起来,这里输出了上一个时间的𝑎,𝑎会作为下一个时间步的输入,𝑐同理。你会注意到上面这里有条线,这条线显示了只要你正确地设置了遗忘门和更新门,LSTM 是相当容易把𝑐<0>的值一直往下传递到右边,比如𝑐<3> = 𝑐<0>。这就是为什么 LSTM 和 GRU 非常擅长于长时间记忆某个值,对于存在记忆细胞中的某个值,即使经过很长很长的时间步。
Q:GRU和LSTM选择哪个更好呢?
A:GRU 的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。
但是 LSTM 更加强大和灵活,因为它有三个门而不是两个。如果你想选一个使用,我认为 LSTM 在历史进程上是个更优先的选择,所以如果你必须选一个,我感觉今天大部分的人还是会把 LSTM 作为默认的选择来尝试。虽然我认为最近几年 GRU 获得了很多支持,而且我感觉越来越多的团队也正在使用 GRU,因为它更加简单,而且还效果还不错,它更容易适应规模更加大的问题。