项目学习来源:
零基础入门NLP - 新闻文本分类赛题与数据-天池大赛-阿里云天池
目录
一、实验数据分析
见大赛数据说明文档
二、实验原理―BERT文本分类
1、BERT的结构
????? BERT模型在2018年Google AI 发表的论文中首次被提出,并在11个NLP任务表现上刷新了记录。

??????? BERT基于Transformer encoder,该结构可实现一次性读取整个文本,以进行双向的语言表征,实现预测任务。输入的Embedding通过一层层的Encoder进行编码转换,再连接到不同的下游任务。
2、BERT的输入
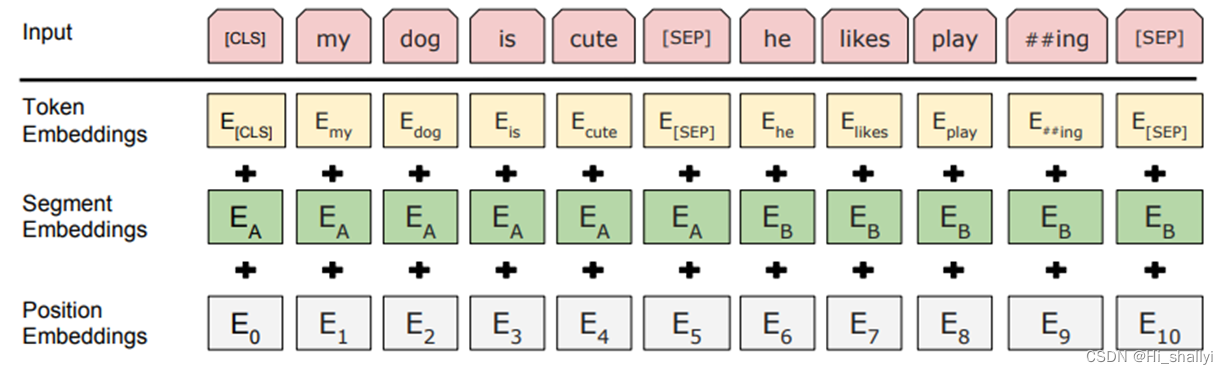
粉色块--输入的字符块token,其特点:
(1)在每个序列开头插入[CLS]分类token,用于分类相关任务;
(2)在每句结束后插入[sep]分割token,用以分开不同句子。
token对应向量,其特点:
? (1) Token Embedding--标定对应的token;
? (2) Segment Embedding--对句子的分割,用以表征token属于句子A还是句子B;
? (3) Position Embedding--表征token在序列中的位置。
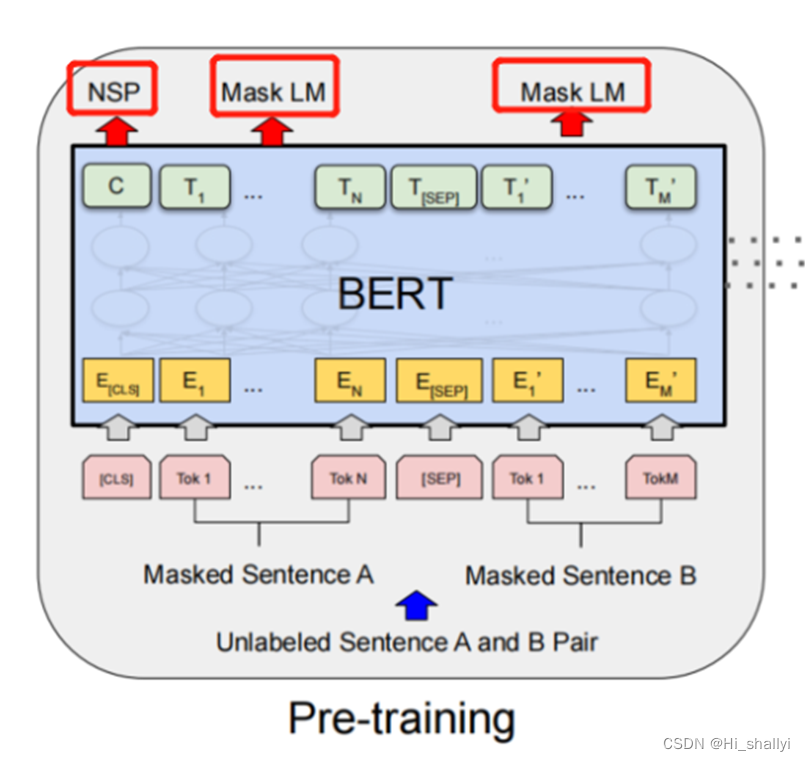
3、BERT的两大预训练任务
1.Masked Language Model(MLM)
(1)以15%的概率用mask token ([MASK])随机地对每一个训练序 列中的token进行替换;
(2)预测出[MASK]位置原有的单词;
(3)用该位置对应的输出预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
2.Next Sentence Prediction(NSP)
?????? 当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子(IsNext),也有50%的可能是随机句子(NotNext),将训练样例输入到BERT模型中,用[CLS]对应的C信息,就是分类信息,进行分类预测。
4、BERT的输出

?因为BERT是只有encoder的transformer构成的,transformer能实现有多少输入就有多少输出
图中C为分类token[CLS]对应的输出,Ti表示对应输入token的输出
三、实验设计
1、实验框架
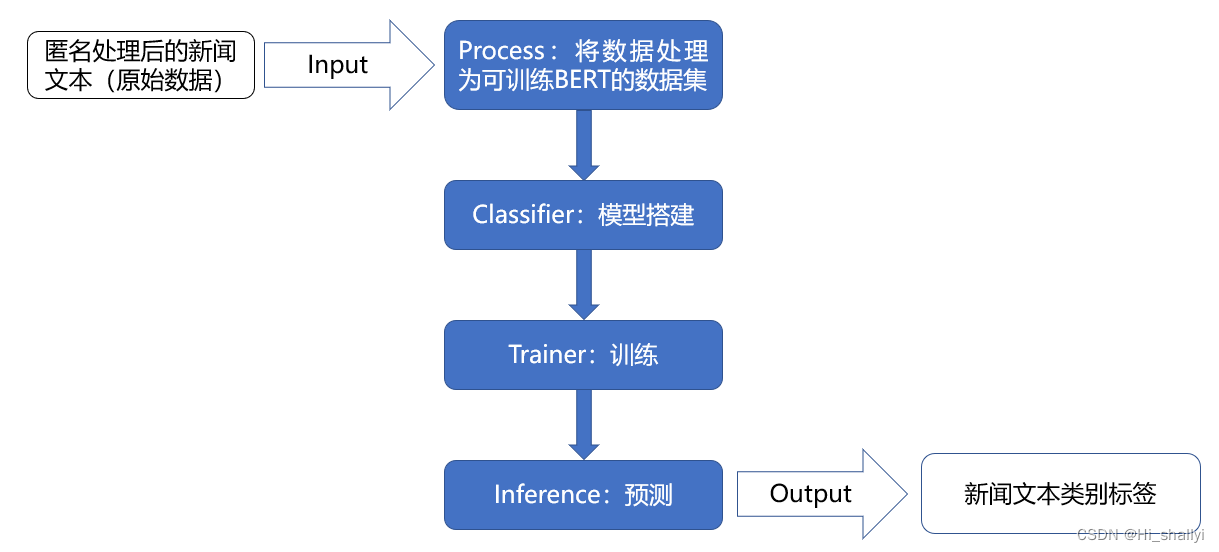
2、数据处理――将数据处理为能够训练BERT的样式
样本长度不一,处理方式:
填充词元:?
对于每条输入样本:
[CLS]作为一种特殊标记添加在每一条输入样本之前
[SEP]则作为一种特殊的分隔符用来分割句子对,例如<question, answer>。
transformer层输出和输入长度相同的词嵌入向量,在分类时,只需要得到第一个词向量并进行分类即可。?
代码层面实现:
加载分词器tokenizer,使用类方法from_pretrained加载预训练模型:
tokenizer =??transformers.AutoTokenizer.from_pretrained('bert-base-uncased')
bert-base-uncased是bert最基础的模型,也是基于transformer的神经网络,其网络细节:
| 参数 | 大小 |
| layer | 12 |
| hidden_size | 768 |
| num_attention_heads | 12 |
| parameters | 110M |
?3、模型搭建
首先,初始化模型,用bert-base-uncased作为预训练模型,选用bertforsequencecalssificationz作为函数调用接口。
接着定义:前向传播forward()函数,将处理好的数据使用Pytorch的DataLoader模块导入模型中
然后,配置优化器,主要优化两方面:
模型参数的优化:调用Adam优化器,Adam优化器对于学习率没有那么敏感,简便易用
学习率的动态衰减:采用指数衰减策略,参数gamma为衰减的底数,可以通过改变gamma来改变学习率衰减的幅度
训练过程:给定批量数据(小批量梯度下降),利用前向传播函数计算loss值并返回
4、训练模型
分类器classifier参数:
batch_size = 8? ? ? ? ? ? ? learning_rate=3e-5(因为数据量很大,需要把学习率设置小一点)
衰减底数gamma=0.8? ??
训练器trainer超参数:
gpu数量=8? ? ? ? ? ? ? ? ? ? ?max_epoch=3
log_every_n_step=0.8
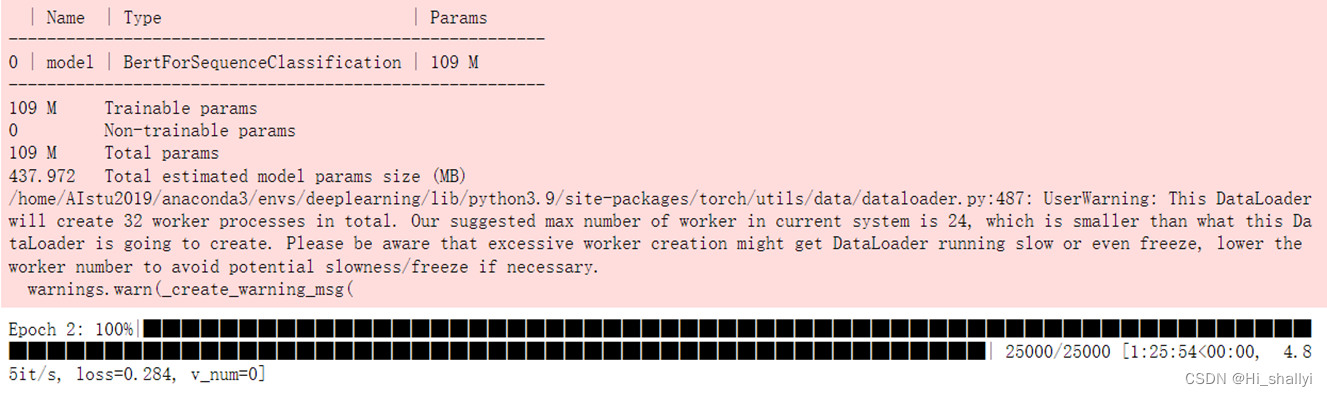
训练过程(历经四个多小时):
?四、实验结果
F1指数为0.85,只能说预测的还行,不算很好,但也不差