Ŀ¼
1 ժҪ
????????�����ʼ��������Ѿ���Ϊ�����罻�����һ����в,���ǵĶ�����Ϊ,�����������Ϣ��Ӱ������ƽ̨��ʵ�����ǵĶ�����
????????����ʱ�������,�����ʼ��������Ѿ����Խ��Խ�Ƚ�,����ʶ������˵��㷨��Ȼ��һ����������ս��
????????ѧϰͼ�ṹ�������ڵ�ĵ�άǶ���ѱ�֤���ڸ������������õ���
????????�ڱ�����,���������һ������ͼ����������(GCNN)�����������˼��ģ�������ǵļ�����,Ϊ�˸��õؼ�������ʼ�������,��������һ����������,�����뿼�ǵ����ͼ��
????????GCNN�ܹ�ͬʱ����һ���ڵ��������һ���ڵ���ھӵ����������ǽ����ǵķ��������ֽ�����������ͼ�Ľṹ�Ϲ����ķ������бȽϡ���������֪,��������������ʼ������˼����ʹ��ͼ������������״γ�����
2 CCS CONCEPTS
????????��Ϣϵͳ���������; -��ȫ����˽��������簲ȫ����˽; -���㷽����������;
3 �ؼ���
????????���ý�����,�����˼��,ͼǶ��,ͼ����������
4 ����
????????�����罻����(OSN)Ϊ�����ṩ��һ��ͨ���ֶ�,ʹ���ܹ������ɺͼķ�ʽ������Ϣ�ͱ��������
????????���ء�����������罻ý����վ�Ѿ��ı��������������ź�������ķ�ʽ����Щƽ̨����Ҫ���õ������漯����ͼӰ���û�,��ȡ���ǵ�ע����,�����ոı乫�������
????????�罻���������ɼ��������������Զ����û��ʻ�,�ó���ģ��������Ϊ,Ŀ���������罻ý��ƽ̨ ��
????????���ǵĶ�����Ϊͨ������թƭ URL ���������ʼ��������ض������ǩ������������Ϣ��Ӱ��ѡ��,��Ȼ�ѳ�Ϊ�����罻�������в��
????????�о����Ѿ�����˼��ֻ����˼�ⷽ������Щ�����IJ���ȡ�����������ʻ��Ķ��塢�����ʻ�����ѡ���ܼ��Լ��������������ʻ�����ͨ�û��ʻ�����Ļ���ѧϰ�㷨;
????????Ȼ��,���ڼ���ԭ��,�����ʼ������˼����Ȼ��һ�����ŵ���ս:
????????��һ��ԭ�������ڻ������ʻ��Ķ���,��Ϊû�е�һ�Ķ������Ծ�ȷ�ؽ��ʻ�ȷ��Ϊ�������ʻ�������һ����Ҫ������,�ر��Ƕ��ڽ���һ��ground truth���ݼ�;
??????? ��һ��������,�������ڱ�����������ļ�ⷽ�������ø����Ƚ����ӡ���ʵ��,������һֱ������ʱ������ƶ���չ�� �罻�������ܹ��������ʻ����н���,������ͬ���������,��������һ����ʾ���ƵĻ��
??????? ���,���ͼ�ṹ���ݵ����ѧϰ�Ľ�չ������һ���µı�ʾѧϰ����,��ͼ��������(Graph Conolution Networks,GCNs)��GCNs����Ҫ˼��������һ���ڵ�������������ڽڵ���������������������ռ��б�ʾ�ýڵ���GCNs���ŵ���,������ץס�ڵ������,����ץסͼ�Ľṹ,�Ӷ�ѧϰ���ڵ�ĵ�ά��ʾ��
????????���������,���������һ�ֻ����û������ļ��������罻����ͼ�Ļ����˼��Ĺ��ɱ�ʾѧϰ���������������Ҫ�����ܽ�����:
????????������������ʹ�õ�������֪�������ʼ����������ݼ��ϲ�����ͼ���������硣;
??????? ����ͨ�� MLP �����������ǵķ����������㷨���бȽ�,�������ݼ���Ӧ�������;
????????���DZ���,�����ǵķ�����ʹ��ͼ�ṹ�������ʼ�����л���˸��õ�����;
????????���ĵ����ಿ�ֵĽṹ���¡�����,���ǽ��������ʼ������˼���ͼ���������緽�����ع������� 3 ����ϸ������ʹ�õ����ݼ����ڵ� 4 ����,���Ǹ��������ǵķ����������ڵ� 5 ����˵���˽��,�����������ǹ����ľ����ԺͶ�δ�������Ľ��������,�����ڵ� 6 �ڽ������ġ�
5 ��ع���
????????����һ����,�������Ȼع��˹��������ʼ���������,��ͨ�����Ƕ������ʼ��Ķ��塢ʹ�õ����������Dz��õķ����㷨���Ƚ�ÿ�����������,���ǿ�һ��ͼ�������硣
?? 5.1 �����ʼ������ع��� ???
????????����(Kyumin Lee, Brian David Eoff, and James Caverlee. 2011. Seven months with the devils: a long-term study of content polluters on Twitter. In In AAAI Inta??l Conference on Weblogs and Social Media (ICWSM))�����һ����Ϊ�������˻����۹�����ķ��������Ǵ�����60��twitter�˻�,����ʼ�����������������,��Щ���Ķ�������˵������Ȥ����������,���ǻ����ܹ�����һЩ�˻���ע��������ע���Ǵ������˻�������Щ�˻�����ϸ��������,����ʵ��������ͼ�������ע�����Ļ������˻���
??????? ����(Chao Yang, Robert Harkreader, and Guofei Gu. 2013. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Transactions on Information Forensics and Security (2013). | Chao Yang, Robert Harkreader, Jialong Zhang, Seungwon Shin, and Guofei Gu. 2012. Analyzing Spammers�� Social Networks for Fun and Profit: A Case Study of Cyber Criminal Ecosystem on Twitter. In Proceedings of the 21st International Conference on World Wide Web (WWW ��12). ACM, New York, NY, USA, 71�C80. https://doi.org/10.1145/2187836.2187)�Խ�ʬ�˻�ʹ����һ�����صĶ���,��ֻ���Ƿ������ӵ��������ݵ�URL���˻������ǻ���BayesNet�����������벢�����˼���ǿ���������Ԥ�������ʼ��˻�����͵��˵����˻�����Ϊ���ⱻTwitter���ֶ���ȡ�IJ�ͬ���������ǵ��о��������,������������ͨ���������ߺͷ��������������������˻���������
??????? ����(S. Cresci, R. Di Pietro, M. Petrocchi, A. Spognardi, and M. Tesconi. 2016. DNA-Inspired Online Behavioral Modeling and Its Application to Spambot Detection.IEEE Intelligent Systems 31, 5 (Sept 2016), 58�C64. https://doi.org/10.1109/MIS.2016.29)������һ���� DNA �����ļ���,�ü�����ÿ���ʻ���ģΪ��Ϊ��Ϣ����,�������������м�������ʼ������������ǽ�ÿ���û������ķ���Ϊ��ͬ������,�����������Ƿ���� URL�������ǩ��ͼƬ��,Ϊ����䲻ͬ���ַ����ʻ������������� DNA ��������Ĺ����Ӵ���������
????????BotOrNot(Clayton Allen Davis, Onur Varol, Emilio Ferrara, Alessandro Flammini, and Filippo Menczer. 2016. BotOrNot: A System to Evaluate Social Bots. In Proceedings of the 25th International Conference Companion on World Wide Web (WWW ��16 Companion). International World Wide Web Conferences Steering Committee, 273�C274. https://doi.org/10.1145/2872518.2889)��1000���������ʹ�����ɭ�ַ������㷨��������������Щ��������Ϊ6��:����(�̶ȷֲ�,����ϵ��, ......),�û����˻���Ϣ,����(��˿����,��ע��, ......),ʱ��(������, ......),����(��Ȼ���Դ���, ......)�����������BotOrNot��ȱ����,������Ӣ��������ѵ����,����������Ӣ������������������ĵĻ������ϵı��ֻ��½���
????????DeBot (N. Chavoshi, H. Hamooni, and A. Mueen. 2016. DeBot: Twitter Bot Detection via Warped Correlation. In 2016 IEEE 16th International Conference on Data Mining (ICDM). 817�C822. https://doi.org/10.1109/ICDM.2016.0096 | Nikan Chavoshi, Hossein Hamooni, and Abdullah Mueen. 2017. Temporal Patterns in Bot Activities. In Proceedings of the 26th International Conference on World
Wide Web Companion (WWW ��17 Companion). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Switzerland, 1601�C1606. https://doi.org/10.1145/3041021.30)��һ���ල�Ļ����˼��ϵͳ�����ǵĹ���������뷨��,�����ǵĻ(���ġ�ת�ơ���)�о��и߶�����Ե��ʻ����п��ܳ�Ϊ�����ˡ�DeBot����˻����ض�ʱ�ڵĻ,��Ϊÿ���˻�����һ��ʱ��������Ȼ��,�������˻���ʱ�����е�������,ʹ���ͺ����е�ɢ�з������˻����о��������,DeBot�����и�����Ե��˻�����Ϊ�����ˡ�
??????? ����(Real-time Detection of Content Polluters in Partially Observable Twitter Networks)�������ʼ������˶���Ϊ�������λ���ԭ����ͼ�ӹ����۵�������Ⱦ�ߡ����ǵķ������Ǹ����������������ˡ�����û�й�ע���Ѻ���������,���Ǵ�����һ���¼�����,���нڵ����û�,���ǻ����û���ͬһ�¼������ġ����ǻ�����һ�������ᵽ��URL�ͱ�ǩ���������Ķ����ԡ����ǵĹ����������,�����ʼ���������Ϊһ��Ⱥ������,������ͬһʱ�䷢�ơ�
5.2 ͼ������������ع���
??????? ͼ��������ר����������ͼ���ݵ�������ܹ�,����ͼ���ٽ�����Լ�ÿ���ڵ������,���������������ͼ�ϵ�ӳ��,�Ӷ��õ�ÿ���ڵ���һ�������,�ٽ����A����������H��ÿһ���ڵ�ۺ��������Լ����ھӽڵ������,�����õ��������ı�ʾ(�������罻������,��Ҫ֪���û���ƫ��,����Ҫ֪�����Լ�������,ҲҪ֪������ѵ�ƫ��,���û��Լ��������Ҫ�ο���ֵ);
??????? ͼ����������ӳ�亯�����:, ����������ͼ��˵(���Ի������ر�),
, �൱�ڸ�ÿ���ڵ�����һ���Ի� ,
D��ʾֻ�жԽ����з���Ԫ��,�Խ���Ԫ��ֵ������ڵ�Ķ� �� ���ӳ�亯�����Ƕ�ͼ���ٽ����������һ���Ի�,Ȼ�����˶Գƹ�һ��,�õõ��ľ���������������оۺ�,ÿ���ڵ�õ��Լ��Լ��ھӽڵ�ļ�Ȩ�����Ϣ��
????????ͼ�ṹ���������������Ӧ����,���罻���硢�Ƽ�ϵͳ�ȡ�ͼ�ṹ����ս������������ڻ���ѧϰ�㷨��ʹ��������
????????��һ��������Ĺ���������ͼ��ͳ������,���ڵ�Ķ��������ĶȺͼ���ϵ����Ϊѵ��ģ�͵����������仰˵,������Ϊͼ�Ľṹ����ȡ�ṹ��Ϣ��һ��Ԥ�������������,��Щ������ѧϰ�β�ʹ��ͼ�ṹ����Щ��������һ��ȱ����,����ͼ��ͳ�����ݾ��кܸߵĸ�����,�������������δ������������
????????���ž��������� (CNN) �����½�չ,����һֱ��Ŭ�����������е����ѧϰģ����������ͼ�ṹ��
????????��ʹ��������Ҫ������ͼ�ṹǶ�뵽ά�ռ��С���Щ����֮�������������ζ������������
????????��һ�ַ���ּ�ڲ���ͼ�ṹ�Ĺ̶����Ƚڵ�����,��ֱ����ŷ��������й�����ԭʼ CNN ģ����ʹ����������,����������ͼ�ṹ��ģΪ��ŷ�������
??????? ����(Thomas N. Kipf and Max Welling. 2016. Semi-Supervised Classification with Graph Convolutional Networks. CoRR abs/1609.02907 (2016). arXiv:1609.02907 http://arxiv.org/abs/1609.02)�����ͼ��������(GCN);����ͼ�ṹ�ϵ�������ʹ�þ��������������Ϊ�ڵ��������Ϊ�����ı�ʾ�����ǵķ������Ա���Ϊ��ͼ��ල��������ij�ʼ������Ȼ��,���ǵķ�����ȱ��������Ҫ����������ͼ������˹����,����ÿһ���нڵ�����Ƕ������������ǰһ��������ھ���
??????? �������(Inductive Representation Learning on Large Graphs.)������ GraphSage;һ�ֽڵ�Ƕ���㷨,��ʹ����������ѧϰͼ�ṹ�нڵ��Ƕ�������ǵ���Ҫ�����ǽ������������,��չʾ����ξۺ����Խڵ��������Ϣ�����ǵķ�������������Ҫ��:
????????(1) �������ͼ��ѵ�������硣һ���ڵ������ṹ����������ѵ��������ļ���ͼ��Ŀ���ǽ���������,ȷ��������Ľڵ������Ƶ�Ƕ��,���Զ��Ľڵ��в�ͬ��Ƕ��;
??????? (2)��������ÿ���ڵ�,���ھӵ���Ϣ���ۺϲ�ͨ����һ��ѵ������������
6 ���ݼ�
????????�м������������ݼ����ɲ�ͬ�����������ռ���,ר������Twitter�ϵĻ����˼�⡣
????????Lee�����ṩ��һ������۹����ݼ�,���а�����Լ22000��������Ⱦ�ߡ������Ѿ��ռ����˻���Ԫ���ݺ�ÿ���˻������ġ�Ȼ��,�����Ƿ��������ݼ���,���Ƕ�Twitter�˻���ID�������������������,�ռ���һ������Ϣ�Dz����ܵ�;
????????Cresci���������о��˲�ͬ��Twitter���ݼ�,ͨ��ʹ��һ���ڰ�ƽ̨,���ǶԲ�ͬ���͵��˻������˱�ע�����������Ǽ��������ʼ��˻���Twitter ID;
????????����ˡ� 2013 ���ռ��� Twitter �����ʼ������������ݼ�����ÿ���ʻ��Ĺ�ע�ߺͷ�˿����������֪,�������Ƿ��ֵ�Ϊ Twitter �ʻ��ռ�����Ϣ�����ݼ����ù����������Ѿ����������ǵ����ݼ�,�����ڱ�����ʹ���˸����ݼ������ݼ����� 11000 ���ڵ������֮��� 2342816 ���ߡ�
????????�� 1 ��ʾ�˱���ʹ�õ����ݼ���ͳ�����ݡ����䡢���ĺ��ھ�����ʾÿ���ƽ��������������������Ϊ��λ������ʻ���ƽ������,��ͨ���������һ������Ϊ��һ����б������ڵ�֮��Ĵ���������û����û������ӡ�Ȼ��,��Լ 5.4% �ı�Ե��ϵ�����������ʻ���
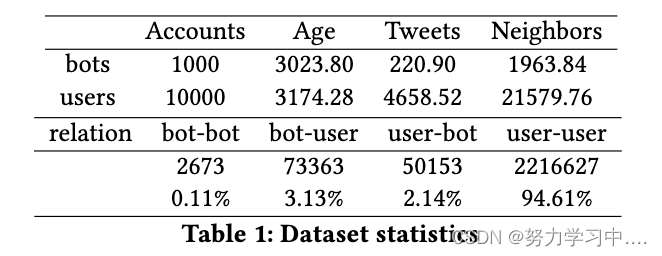
?????????ͼ 1 ��ʾ�����ݼ����˻��Ķ����ֲ���������ʻ��Ĺ�ע�ߺ�������������,�����ʻ����丽��ӵ�г��� 1000 ���ʻ�;
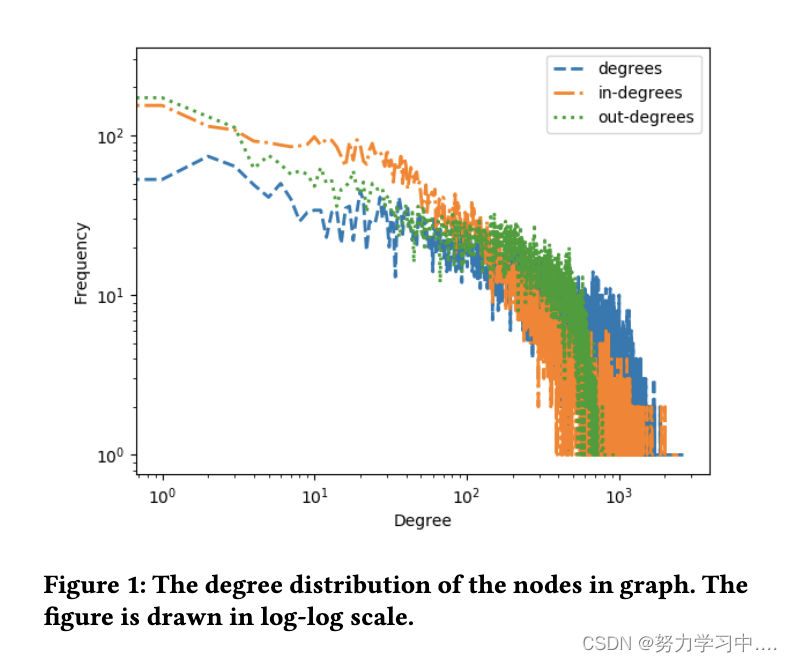
?????????ͼ 2.a ��ʾ�˻����˺��û��ʻ����û��ʻ����Ƶ�����ͳ�������ͼ 2.b ��ʾ,����֮ǰ�Ĺ����б���,�������ʻ��������С,����ζ�����û��ʻ����,��������������ġ�
?7 ����
????????����ʹ��������(Inductive Representation Learning on Large Graphs. | Representation Learning on Graphs: Methods and Applications. )�Ĺ��ɱ�ʾѧϰ��������� twitter bot �ʻ���
7.1 ���ⶨ��
????????�� G =(V ,E) ��һ��ͼ,���ж���ÿ�� v �� V ����һ���������� ��һ����֮��صĶ����Ʊ�ǩ y �� {0,1}��Ŀ����Ϊÿ���ڵ� v ��V �ҵ�һ��Ƕ������
,ʹ��
Ԥ��ͼ�нڵ�ı�ǩ.
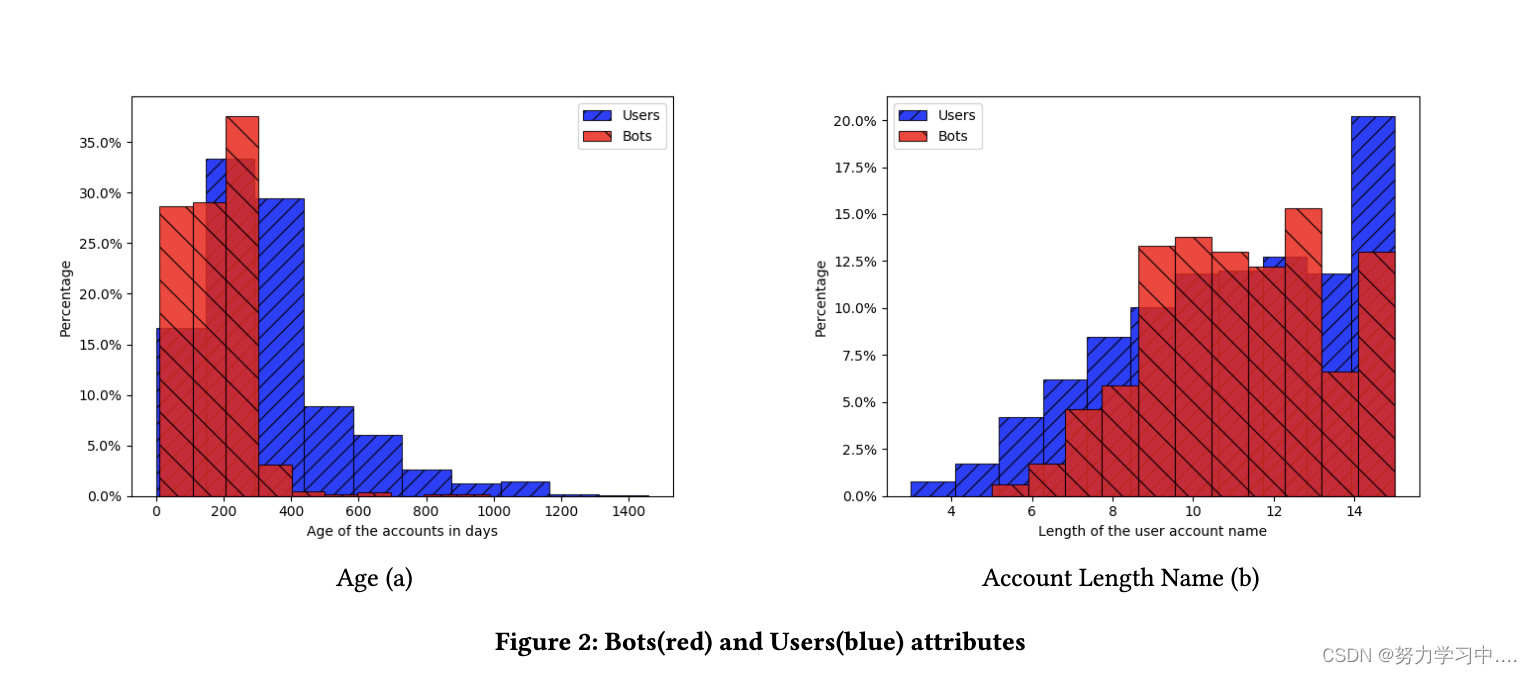
????????��ͼ�����еľ����˲�������,ͼ�������罫�ڵ��ھӵ�������Ϊ�ýڵ�ı�ʾ�������ǽ� k ����Ϊ���оۺ���Ϣ�Ľڵ���ھӵ���ȡ���� k=1,��ֻ�����������Լ��ھ�??����Ϣ������ k=2,��ϢҲ�Ǵ����ھӵ��ھ����ռ���,�������ơ�ÿ����ȵ���� ��������:

?????????���� ������ v ���ھӵ�Ƕ��������ƽ��ֵ��
????????��������ڽ�������ʧ���������Ż�:
????????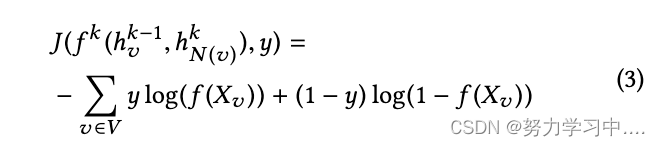
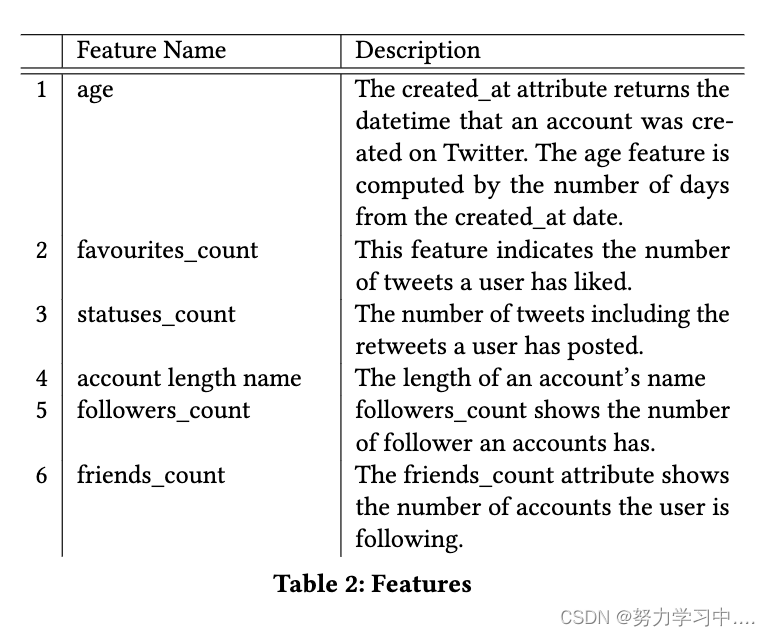
?7.2 Features
????????ÿ���û��ij�ʼ����()�ɿ���ֱ�Ӵ�Twitter API������������ɡ���������������
?8 ����
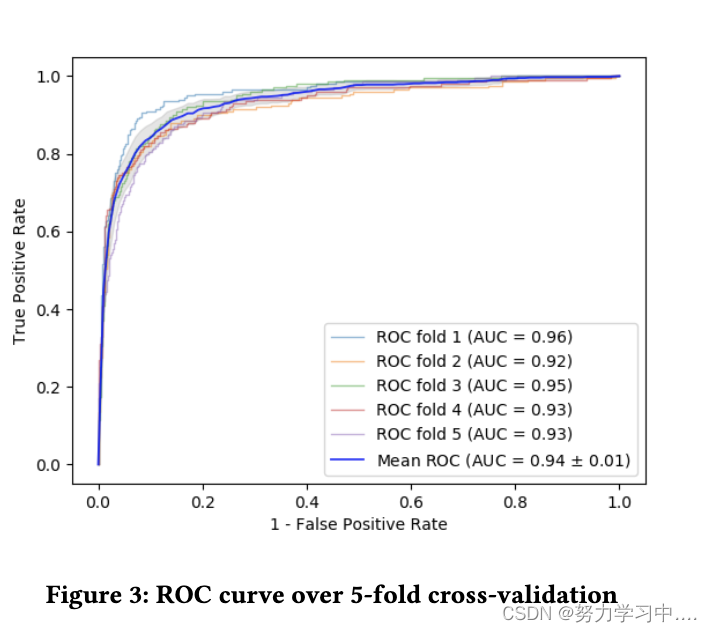
????????�ڱ�����,�����������Ƿ��������ܡ����Ƕ����ݼ������� 5 �۽�����֤,������ģ�͵�ȷ�ԡ�ͼ 3 ��ʾ��ÿ���۵��������������ƽ������,GCNN ���� 0.94 ��ȷ��,�� roc �����µ����������
?
????????���Dz�����ȷ�ʡ��ٻ��ʺ� f1 ָ��,��� 5 ��ʾ����������Ϊ��������ѡ��һ�������������ָ�����Ҫ������,����ʹ�õ�ʽ 4 �ж�������ȶ���������ģ�͵������������������,����ֵ���ڲ��������ǩ������¶��������ݽ��м���ġ�
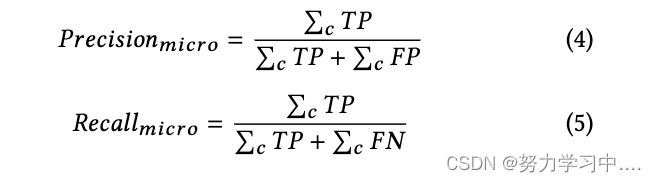
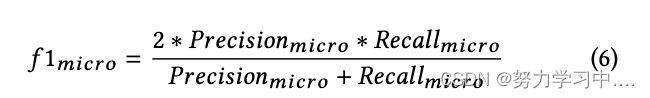
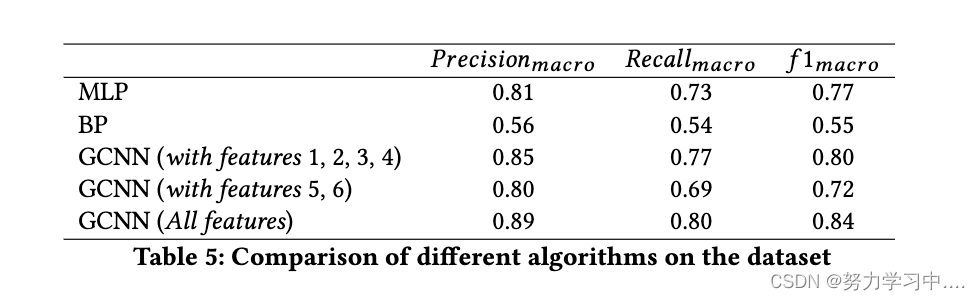
?????????Ȼ��,�����������ǩ����һ��������ݼ����������,��ʹģ��û����ȷ����һ��ı�ǩ,���ȵ÷���Ȼ�ܸߡ����,Ϊ�˸��õ�����ģ��,�����ֱ����ÿ�����ȷ�ʡ��ٻ��ʡ�f1 ����,�������������ƽ������������ scikit-learn python ����Ҳ��Ϊ�����:

?8.1 �� MLP ��������ıȽ�
????????����ͨ�����������ַ������бȽ�,��һ�����������ǵķ�����
????????����ͼ����������ͬʱ��������������ͼ�ṹ,����ͨ��������֪��(MLP)�������(BP)�ıȽ���֤���÷��������ܡ�
????????MLP�������Ǹ������������ж��������������ѵ���ġ�����㽫ÿ���˻�������������һ��Ϊ0��1֮���ֵ�����ز����������,�ֱ���25����10����Ԫ,ʹ�����������Ե�Ԫ��Ϊ���ݺ�����������ʧ����ʹ������ݶ��½��������Ż�,ѧϰ��Ϊ0.0001��
??????? ��һ����,������㷨ֻ��ͼ�Ľṹ�������������(BP)�㷨�����Judea Pearl(Probabilistic reasoning in intelligent systems: networks of plausible inference. r)���,ͨ����ͼ�����нڵ��֮�䷴��������Ϣ,�ӹ���һ���ڵ�������ڽ��ڵ��һЩ����֪ʶ���ƶϳ��ýڵ�ı�ǩ�����͵���Ϣ�����ڵ�����ھӵ�״̬�����
??????? �ڱ�ʵ����,���Dz����˱�3�ͱ�4��ʾ��ԭʼBP��ڵ�ͱ�Եָ�ꡣ����,���ǽ�����7�ε�����ʵ��,��Ϊ��7�ε���֮��,�ڵ�䴫�ݵ���Ϣû�����Եı仯��

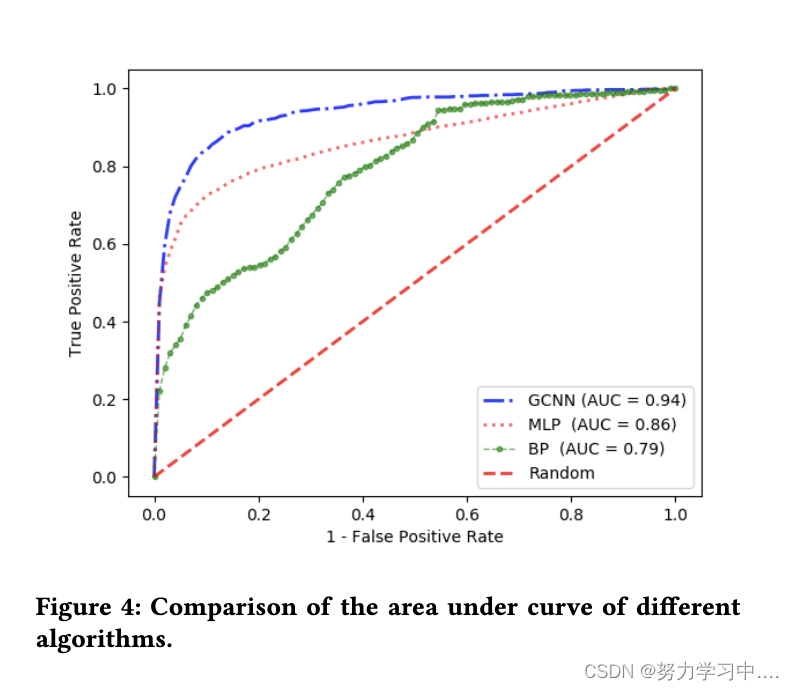
?????????���ǻ����˲�ͬģ�͵Ľ��ղ�������(ROC),��ͼ4��ʾ��
?
????????���ǹ۲쵽,GCNN������ROC�����µ����Ϊ94%,��MLP��BP�����ֱ�߳�8%��16%����Ȼ�������ڸ������������õı���,�����漰������Ϊʲô��������������ʱ,������������Ϊ�Ǻ��䡣
????????���������ÿ����Ŀ�����ɵ�Ƕ��������������Ȼ�ǿ��ŵ�����,Ҳ��δ���о��Ŀ��⡣
9 ���ۺ�δ���Ĺ���
????????�ڱ�����,�����о���һ��ʹ��ͼ���������� Twitter �ϵĶ����˻����罻�����˵��·��������Ƿ�������Ҫ˼�������� Twitter �ʻ���ͼ�νṹ��ϵ���ʻ����з�����ÿ���ʻ�����������ۺ�������Ϣ��
??????? ��������ǰ��һ�������Ļ����˼�����ݼ��Ͻ�������֤�������ʾ,���ǵķ����������Ƚ��ķ����㷨,�����������ȷ�������8%������Twitter API��ÿ15����ÿ���������ƴ���15�����������,�����˻������ߺ����ѹ�ϵ����Twitterͼ�ṹ������һ�������¡�����֪������ܱ���Ϊ�Ƕ����Ƿ��������ơ����,���Խ�������û��˻���ת��ͼ������ͼ�ṹ�����,δ��������һ��������չ����Twitter����ý��API��ʵʱ�����������,�Խ��������ʼ������