论文:《ViT-YOLO:Transformer-Based YOLO for Object Detection》
代码:
摘要:
存在的问题:无人集捕获的图像具有巨大尺度变化,复杂的背景,灵活的视角等特点,对普通基于CNN的目标检测算法是巨大的挑战。如图1所示。
本文解决思路:设计新的主干网络?MHSA-Darknet(作用:保留足够的全局信息和提取更多有区别度的特征,MHSA:mult-head self-attention)。Neak:BiFPN。测试时:TTA(time-test augmentation)+WBF(weighted boxes fusion)。
本文提出的算法:ViT-YOLO
数据集:VisDrone-DET 2021 challenge
效果:sota,39.41 mAP for test- challenge data set,?41 mAP for the test-dev data set
1. 介绍
卷积神经网络在计算机视觉的各个领域已经实现了巨大的突破。ResNet被应用到最先进的目标检测网络中作为backbone,比如Faster RCNN,RetinaNet,YOLO系列等。

?如今transformer除了在nlp上获取很好地效果外,在视觉领域也是大放异彩。vision transformer 处理图像是把图像作为 a sequence of patches。transformer 通过mult-head self-attention捕获图像patches特征间的依赖关系和能够保留足够的空间信息。
解决多视角变化:目标检测器增强域适应能力和动态接收域。研究表明 vision transformer对occlusions,perturbations and domain shifts都比CNN具有更强的鲁棒性。因此,最直观的增强检测器性能的方式就是把transformer层嵌入到纯粹的CNN backbone中,带来更多的上下文信息和学习更多具有区分度的特征表示。
解决巨大尺度变化:无人机捕获的目标尺度变化巨大。本文介绍一个可学习的权重来学习不同输入特征的重要程度,重复使用top-down和down-up的多尺度特征融合。
本文算法:ViT-YOLO,CSP-Darknet+mult-head self-attention + biFPN + YOLOV3 coupled head + TTA + WBF
本文贡献:
1. CSP-Darknet中加入multi-head self-attention,带来更多的文本信息和学习根据区分度的特征。
2. 本文提出简单高效的BiFPN,实现有效地跨尺度特征融合。
3. 本文应用有效的策略,包括:TTA,WBF。
2. 相关工作
General object detection: xxxxx,,,,,选着YOLOv4作为baseline model的原因。(yolov4和yolov3的anchor based是一样的)
Vision Transformer: transformer已经在nlp,文本分类,document summarization等方向成功应用。Part of this success comes from the Trans- former’s ability to learn complex dependencies between in- put sequences via self-attention。所以vision transformer第一次把transformer框架直接应用到图像识别任务上。DETR第一次成功把transformer应用到目标检测任务上。DETR增加了transformer的encode和decode在标准CNN模型的前面,使用了匹配的损失函数。
Muti-scale feature fusion: 目标检测的主要问题是如何有效地表示和处理多尺度特征。多尺度特征学习的发展,FPN(top-down),PANet(bottom-up),EfficientDet(BiFPN),来学习不同输入特征之间的重要度。
3. 本文方法
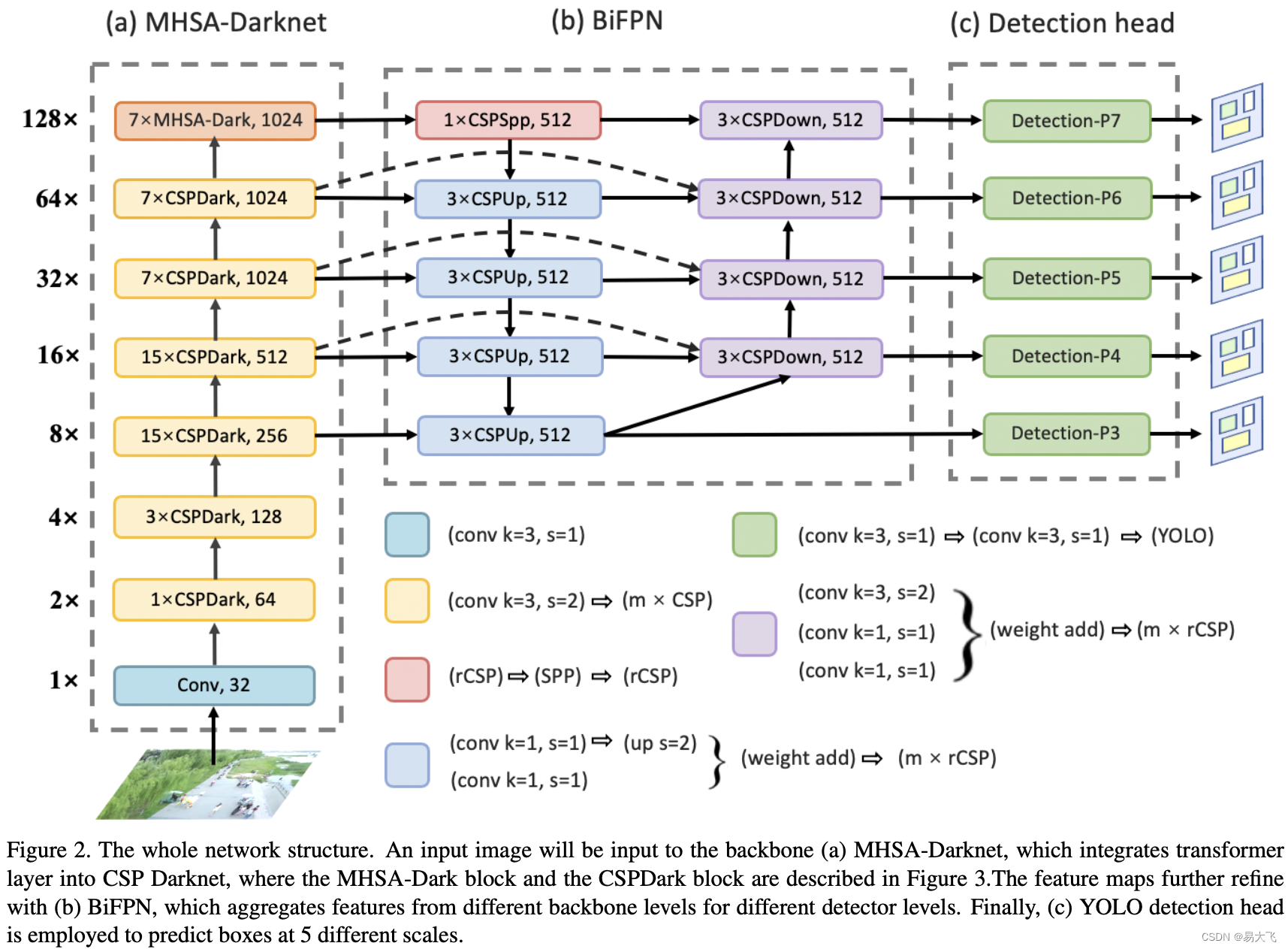
ViT-YOLO就是一个混合模型:CNN(base YOLOV4-P7)+self-attention。如图2,ViT-YOLO被划分为三个部分:1. MHSA-Darknet as backbone,整合multi-head self-attention到CSP-Darknet中,提取更多具有区分度的特征。2. BiFPN as neck 替换了原来的PANet,能从backbone的不同层提取不同的检测器。3. general YOLO 检测 heads,在5个不同的尺寸做预测框。
为进一步实现更好的准确率和鲁棒性。应用了TTA和WBF等技术。
3.1 MHSA-Darknet
局部卷积操作限制了捕获全局上下文信息的能力,与之对应,transformer的multi-head self-attention 能够聚焦 image feature pathes 和保留足够空间信息。另一方面无人机捕获的图像在视角多变上是最大的挑战,这要求检测器有足够的域适应能力和动态接收能力。论文[22]表明vision transformer比CNN有更加强的鲁棒性,在遮挡、抖动和域变化上。
MHSA-Darknet:把multi-head self-attention层嵌入到CSPDarknet网络中,在整个2D特征图上应用全局自注意力机制。MHSA-Darknet框架如表1所示,MHSA层如图4所示。
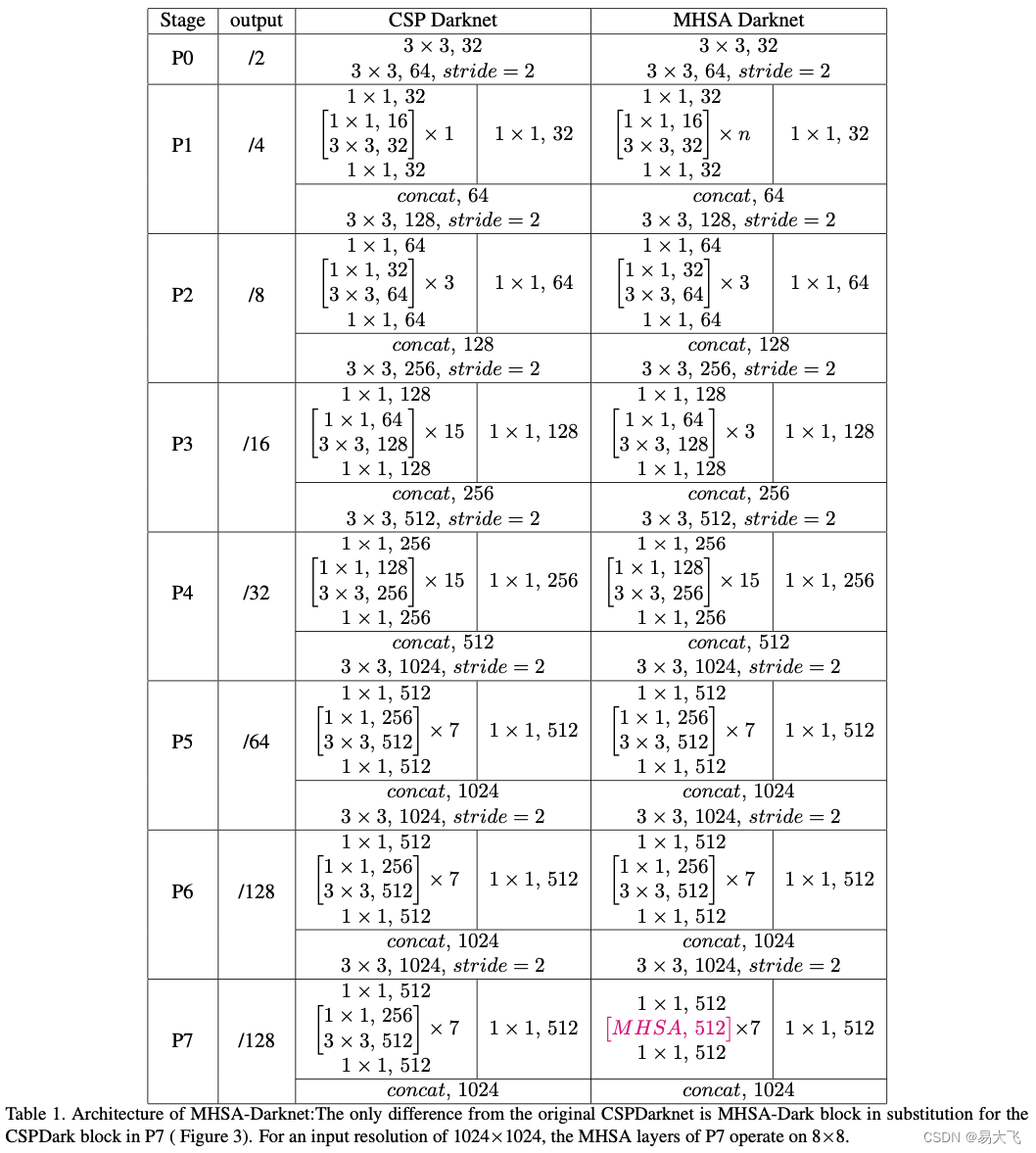
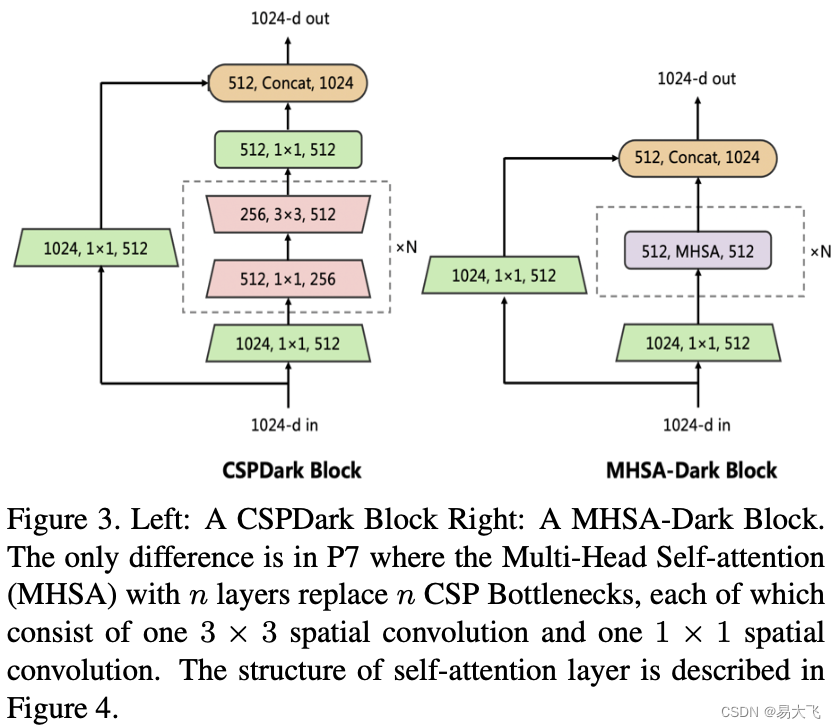
?本文仅将MHSA应用到了P7层,因为作者认为过早的应用transformer层,来回归边框,将会导致一些有效的上下文信息的丢失(网络越浅,特征图越大)。如图3所示。
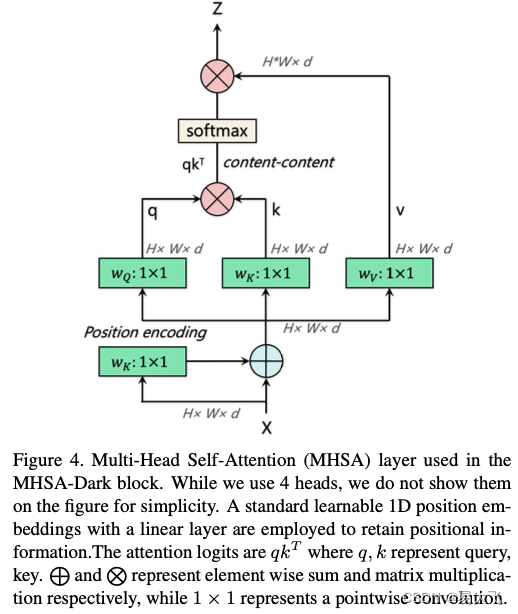
?下面这段挺重要,用的是文章原文:主要如何把(h,w,d)转化为self-attention能够接收的维度(h*w,d),并且增加一维的位置编码。
3.2 BiFPN
使用BiFPN的原因是,来自无人机捕获图像的目标,尺度变化剧烈,CNN的单一层限制了表示能力。然后介绍top-down的FPN单向信息流有内在限制。为了解决FPN问题,提出了PANet,额外增加了一层bottom-up的path aggregation network。本文在PANet的基础上使用了简单有效的权重双向特征金字塔(BiFPN)。如图5(b)所示。为了跨尺度连接实现了两个优化:1. 在同层下增加了额外从输入到输出节点的边(目的:在没有增加更多花销的情况下,融合更多的信息)。2. 联合低层和高层信息。
BiFPN是一个可学习的权重,去学习不同输入特征之间的重要程度,而不是简单求和或concatenating。

?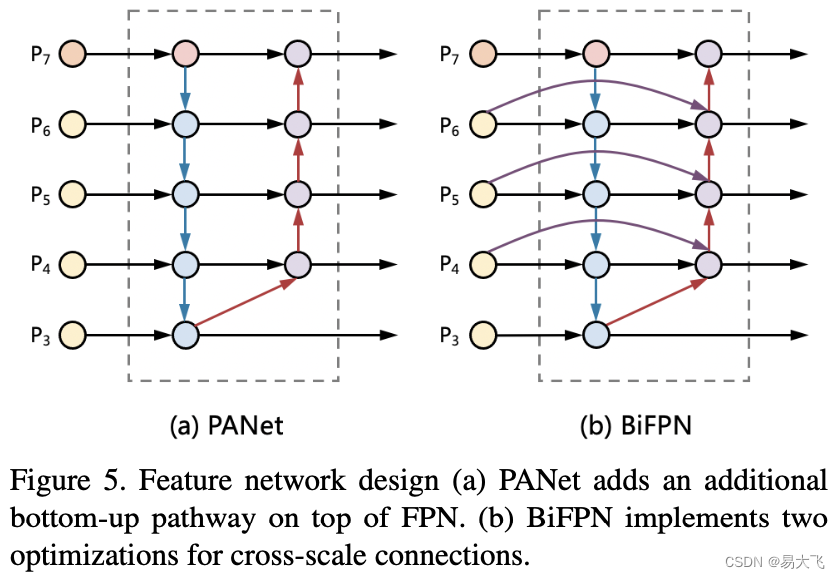
?基于图5,以level 6 来看,就可以看出PANet的网络形式为:

?BiFPN的网络形式 为:

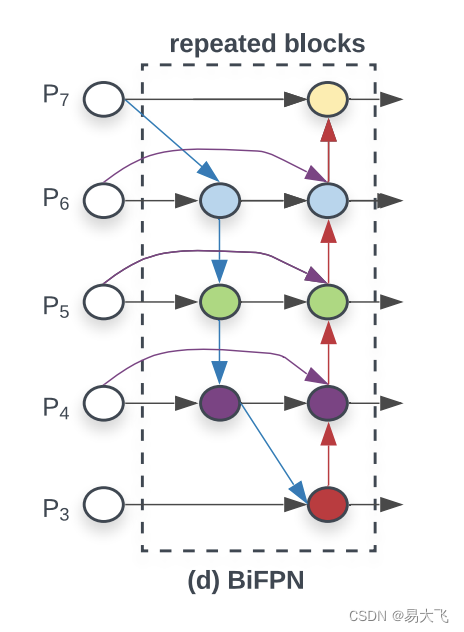
?此处的BiFPN和efficientDet中的BiFPN是不一样的。efficientDet中的BiFPN如下图所示:
4. 实验
4.1 数据集
数据集:VisDrone2019-Det,共10209张静态图像。6741张训练集,548张验证集,1610张测试集,1580张具有挑战的测试集。
4.2 评估指标
评估指标:AP,AP50,AP75,AR1,AR10,AR100,AR500。(漏检和误检)
4.3 应用细节
数据集:VisDrone2021 challenge
backbone:MHSA-Darknet
neck:BiFPN?
head:YOLOv3 head (anchor based)
本文算法名称:ViT-YOLO
optimizer:SGD,weight decay:0.0005,momentum:0.937,learning rate:cosine annealing function,initial learning rate:0.02,total epochs:300
warm-up:3 epoch(SGD momentum:0.8,learning rate:one-dimensional linear interpolation)
4.4 实验结果
表2显示 本文在VisDrone2019 test-dev dataset上的评估结果。
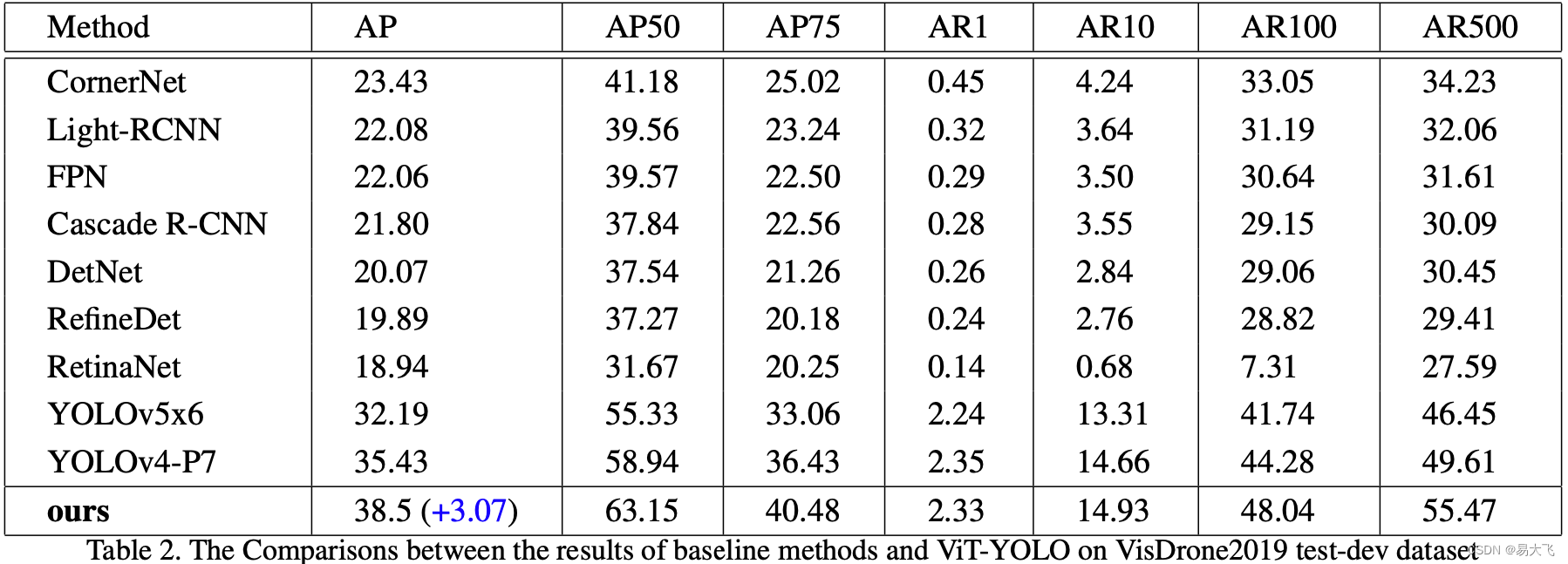
表2中可以看成yolo家族系列,始终保持着杰出的性能。本文修改yolov4-P7最为baseline,修改的内容如图2所示,在没有TTA和multi-model fusion,mAP 38.5超过baseline3.07个点。
4.5 消融实验
在VisDrone2019 test-dev dataset 上进行消融实验,验证本文算法。如表4所示,本文算法backbone:MHSA-Darknet,就是把multi-head self-attention 融入到CSP-Darknet中,并采用简单且高效的BiFPN作为neck,替换原来的PANet。其他技巧包括:TTA,WBF。
4.5.1 MHSA-Darknet
如表3和表4所示,
一方面:MHSA-Darknet中的mutil-head self-attention能够有效的捕获全局上下文信息,有利于在小目标上的检测。
另一方面:通过AP对别,baseline(YOLOv4-P7)无法有限识别行人还是摩托车等上面的人(如图6),但是增加mult-head self-attention之后能够明确识别。表明mult-head self-attention 能够提高baockbone (MHSA-Darknet)提取不同特征的能力,展示了更强的语义区分度去减弱类别混淆。

?4.5.2 Test-Time Augmentation
在VisDrone2021 challenge dataset,使用TTA提高模型效果。图像做多类型增强,不同增强的图像送模型出预测结果,集成这些预测结果返回最终结果。详细可看论文。
4.5.3 Muilt-model fusion
说白了,在4.5.2(单个模型,多个预测结果)的基础上,多个模型的预测结果联合起来。这种多应用在不要求实时的系统上。能够比单一模型实现更高的准确率。模型融合方法是WBF(weighted boxes fusion)。本文使用yolov5,yolov4,ViT-YOLO在VisDrone数据集上训练得到的模型去预测boxes,然后使用WBF,联合这些结果。最终结果如表4所示(test-dev dataset),性能超过了mAP41。
5. 总结
巴拉巴拉小魔仙,就是本文算法的好处。最终本文在ICCV VisDrone2021 object detection Challange上达到了mAP39.41的sota结果。