������Ӿ�ʹ�ܶ������Ϊ��ʵ,����������������������
(��ͼ���ж�λ����)������ʶ��(������ʶ��Ϊ�ض�����)��
OpenCVʵ����һЩ��������ʶ����㷨���Ӱ�ȫ������,��Щ����
����ʵ�����ж���Ӧ�á�
���½���OpenCV��һЩ��������ʶ����,�������ض����͵�
�ɸ�������������ļ���������˵,���о�Haar����������,ͨ����
������ͼ������֮��ĶԱȶ�,ȷ������ͼ�����ͼ���Ƿ�����֪��
��ƥ�䡣��������������ڲ�νṹ����϶��Haar����������,��
����һ��������ʶ������(�����ǵ�Ŀ�����,��һ������),��
����������ʶ��������(�����۾�)��
���ǻ������ˡ����Ρ���������۵�ȴ����Ҫ�����塣ͨ����
�ơ����Ƽ���������ͼ������Ĵ�С,���ǿ��Զ����ڸ��ٵ�ͼ����
��ִ�мIJ�����
���½�������������:
������Haar������
���ҵ�OpenCV�Դ���Ԥѵ��Haar����,������һЩ�����������
������Haar������⾲̬ͼ�����Ƶ�е�������
���ɼ�ͼ��ѵ���Ͳ��������������
��ʹ�ö��ֲ�ͬ������ʶ���㷨:Eigenface��Fisherface�Լ��ֲ�
��ֵģʽֱ��ͼ(Local Binary Pattern Histogram,LBPH)��
�������������һ��ͼ���Ƶ���һ��ͼ��,���ɰ���Ҳ�ɲ���
����ģ��
��ʹ���������ͷ����������������ͱ�����
���ڽ���ʽӦ�ó����н��������˵�����
���½���ʱ,���ǽ��������ٺ;��β������ɵ�������ǰ������
�����Ľ���ʽӦ�ó���Cameo�С����,���ǽ�����һЩ������������
����!
5.1��?��������
����ʹ����Python��OpenCV�Լ�NumPy����ΪOpenCV��һ����,ʹ
���˿�ѡ��opencv_contribģ��,���а�������ʶ���ܡ����µ�ij
Щ����ʹ����OpenCV��OpenNI 2�Ŀ�ѡ֧�������������ͷ��ͼ
��װ˵������ĵ�1�¡�
���µ�������������ڱ����GitHub��
(https://github.com/PacktPublishing/Learning-OpenCV-4-
Computer-Vision-with-Python-Third-Edition)��chapter05�ļ���
���ҵ���ʾ��ͼ���ڱ���GitHub���images�ļ����С�
5.2��?Haar�����ĸ��
��̸���������岢������λ��ʱ,���ǵ�����Ҫ̽��ʲô��?��
������Ŀ�ʶ�ֵ���ʲô?
��ʹ������������ͷ����Ӱͼ��,Ҳ���ܰ����ܶ�������Ŀ��ϸ
�ڡ�����,��Ϊ���ߡ��ӽǡ��Ӿ����롢����ͷ���������������ı�
��,ͼ��ϸ���������ȶ�������,��ʹ����ϸ���ϵ���ʵ����Ҳ����
�ܻ��������ǶԷ������Ȥ��Լɪ��˹(��������֮һ)��ѧУ
ѧ��,��������,û����Ƭѩ����������һ���ġ����˵���,��Ϊ
һ�����ô�ĺ���,���Ѿ�ѧ���˲�����������ʶ��ѩ��,��Ϊѩ
���������ϵ�����֮�������ԡ�
���,����ͼ��ϸ�ڵ�һЩ���������ڲ����ȶ��ķ�����ٽ�
������Щ�����Ϊ����,��˵�Ǵ�ͼ�������г���ġ������κ�����
������Ӱ��������,��������Ӧ�ñ������١���һ��������ʾΪһ
������,���Ը���ͼ��Ķ�Ӧ��������֮��ľ�������������ͼ��֮
������Ƴ̶ȡ�
��Haar������Ӧ����ʵʱ�������ij�������֮һ��������
��Robust Real-Time Face Detection��(International Journal of
Computer Vision 57(2),137�C154,Kluwer Academic
Publishers,2001)��,����Paul Viola��Michael Jones�״ν���
Haar��������������⡣������
http://www.vision.caltech.edu/html-files/EE148-2005-
Spring/pprs/viola04ijcv.pdf���ҵ���ƪ���ĵĵ��Ӱ档ÿ����Haar
��������������ͼ������֮��ĶԱȶ�ģʽ������,�ߡ������ϸ��
��������һ����������Щ�����Ƕ��ص�,��Ϊ��Щ����ͨ��������ij
һ�����(������)��,��������������������ϡ�������Щ����
��֯��һ����νṹ,��Ϊ����,������߲����������������,ʹ
�������ܹ����پܾ�ȱ����Щ���������塣
�����������������,�������ܻ����ͼ���С�����������Ա�
�ȵ������С��������ͬ�����������Աȶȵ������С��Ϊ���ڴ�
С��ΪʹHaar�����������߶Ȳ���,���߶Գ߶ȱ仯����³����,��
�ڴ�СӦ���ֲ���,���ǽ�ͼ���������Ŷ��,�����ij�̶ֳ�����
��ʱ����(������)��С����ƥ�䴰�ڵĴ�С��ԭʼͼ�������ͼ��
һ���Ϊͼ�������,ͼ��������е�ÿ�������IJ㶼��һ����С��
��Сͼ��OpenCV�ṩ��һ���߶Ȳ���ķ�����,������һ���ض���
��ʽ��XML�ļ����ؼ�����������������������ڲ������������ͼ��
ת��Ϊͼ���������
��OpenCVʵ�ֵ�Haar��������������ת�ǶȻ�����ͼ�ı仯��
��³��������,��Ϊ������������������������һ��,��Ϊ���濴��
�������濴������һ����ͨ������ͼ��Ķ��ֱ任�Լ�������ڴ�
С,�����ӡ���Դ���ܼ���ʵ�ֿ�������Haar��������ת�Ƕȵ�³��
�ԡ�����,���ǽ�ֻ����OpenCV��ʵ�֡�
5.3��?��ȡHaar��������
OpenCV 4Դ������߰�װ��OpenCV 4Ԥ������,Ӧ�ð�����Ϊ
data/haarcascades�����ļ��С�������ҵ�����ļ���,��ص���
1�»�ȡOpenCV 4��Դ����˵����
data/haarcascades�ļ��а�����������Ϊ
cv2.CascadeClassifier��OpenCV����ص�XML�ļ��������ʵ���Ѹ�
����XML�ļ�����ΪHaar����,Ϊij�����͵�����(������)�ṩһ��
���ģ�͡�cv2.CascadeClassifier���Լ������ͼ���е��������͵�
���塣ͨ��,���ǿ��Դ��ļ��л�ȡ��̬ͼ��,���ߴ���Ƶ�ļ�����
Ƶ����ͷ��ȡһϵ��֡��
�ҵ�data/haarcascades��,�������ط�Ϊ��Ŀ����һ��Ŀ¼����
����ļ����д�����Ϊcascades�����ļ���,��������ļ���
data/haarcascades���Ƶ�cascades:

����˼��,��Щ���������������������۾��ġ�������Ҫ�ǹ۲�
�������桢ֱ������ͼ���Ժ�,�ڽ������������ʱ�����õ���Щ��
����
�������֪�����������Щ�����ļ�,�����Լɪ��˹
��OpenCV 4 for Secret Agents [1] (ԭ����2019����Packt���������)��
��3�¡�ֻҪ���㹻�����ĺ�һ̨ǿ��ļ����,��Ϳ����Լ�������
��,����Ը������͵Ķ���Դ����ļ�������ѵ����
[1] �����2������İ桶OpenCV��Ŀ����ʵս(ԭ���2��)(ISBN
978-7-111-65234-2)����2020���ɻ�е��ҵ��������档�����༭ע
5.4��?ʹ��OpenCV�����������
�������ھ�̬ͼ��������Ƶ�ش��ź��Ͻ����������,
cv2.CascadeClassifier����û���κ�������Ƶֻ�������ľ�̬ͼ
��:��Ƶ�е��������ֻ�ǽ��������Ӧ����ÿһ֡����Ȼ,���˸�
�Ƚ��ļ���,�Ϳ����ڶ�֡���������ټ�������,��ȷ��ÿһ֡
�е������Ƿ���ͬ������,���֪��������˳��Ҳ����Ч�ġ�
���������һЩ������
5.4.1��?�ھ�̬ͼ���Ͻ����������
�����������ĵ�һ��Ҳ��������ķ����Ǽ���һ��ͼ���
���е�������Ϊ��ʹ������Ӿ���������,���ǽ���ԭʼͼ���е���
����Χ���ƾ��Ρ����ס,��������������ֱ���������������
��,���ǽ�ʹ���ж���(��ľ��)վ��һ�ŵ�ͼ��,���Ǽ粢��վ
������Ծ�ͷ��
��Haar����XML�ļ����Ƶ������ļ��к�,���Ǵ������л����ű�
��ִ���������:?

���������һ��ǰ��Ĵ��롣����,ʹ�ñ�Ҫ��cv2����,����
��ÿ���ű�����������롣Ȼ��,����һ��face_cascade����,����
һ��CascadeClassifier����,���ڼ���������⼶��:?

Ȼ��,��cv2.imread����ͼ���ļ�,����ת���ɻҶ�ͼ��,��Ϊ
Cascade Classifier��Ҫ�Ҷ�ͼ����һ��,��
face_cascade.detectMultiScale����ʵ�ʵ��������:

detectMultiScale�IJ�������scaleFactor��minNeighbors��
scaleFactor����Ӧ�ô���1.0,ȷ��������������ÿ�ε���ʱͼ��
�Ľ��߶ȱ��ʡ�����5.2�ڽ��ܵ�,���ֽ��߶ȵ�Ŀ����ͨ���Ѳ�ͬ��
�����봰�ڴ�Сƥ��ʵ�ֳ߶Ȳ����ԡ�minNeighbors������Ϊ�˱���
���������Ҫ����С�ص���������ͨ��,�������������ڶ����
�������м�ij����,������ص����ʹ���Ǹ���ȷ�ż�����
����һ��������������
�Ӽ��������ص�ֵ��һ����ʾ�������ε�Ԫ���б���OpenCV��
cv2.rectangle��������������ָ�������괦���ƾ��Ρ�x��y�ֱ��ʾ
�������Ͷ�������,w��h�ֱ��ʾ�������εĿ��Ⱥ߶ȡ�ͨ��ѭ
������faces����,������������Χ������ɫ����,��ȷ��ʹ�õ���ԭ
ʼͼ��,�����ǻҶ�ͼ��:
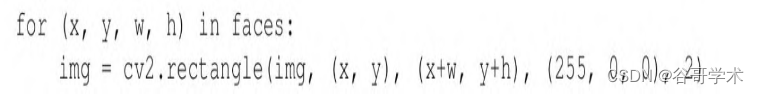
���,����cv2.imshow��ʾ�������ͼ��ͨ��,Ϊ�˷�ֹͼ��
�����Զ��ر�,����һ����waitKey�ĵ���,���û����������ʱ��
��:

����,������ͼ���м�һȺ��ľ��,��ͼ5-1��ʾ��?

��������е���Ƭ��л���ǡ������C���˹��(Sergey
Prokudin-Gorsky)(1863��1944)����Ʒ,�����C���˹���Dz�ɫ
��Ӱ��������ɳ������������������C���˹���������˹�۹�
������͵ص�,������Ϊһ���Ӵ�ļ�¼Ƭ��Ŀ��1909��,�����C
���˹���ڶ���˹��������˿ޱ���Ӹ�����������Щ��ľ���ˡ�
5.4.2��?����Ƶ�Ͻ����������
����,�����˽�������ھ�̬ͼ���Ͻ���������⡣��ǰ����,
���ǿ�������Ƶ(����ͷ�ش��źŻ���Ԥ��¼�Ƶ���Ƶ�ļ�)��ÿһ
֡���ظ��������Ĺ��̡�
��һ���ű�����һ������ͷ�ش��ź�,��ȡһ֡,����֡��
������,���ڼ���������ɨ���۾������,��������Χ������ɫ
�ľ���,���۾���Χ������ɫ�ľ��Ρ������������Ľű�:
?
?���ǽ���������ӷֽ�ɸ�С������������IJ���:
(1)������һ��,����cv2ģ�顣֮��,��ʼ������
CascadeClassifier����,һ����������,��һ�������۾�:

(2)������������ʽ�ű�һ��,��һ������ͷ�ش��ź�,��
ʼ����֡������,ֱ���û�����ij���������ɹ�����һ֡ʱ,����
ת��Ϊ�Ҷ���Ϊ�����ĵ�һ��:?

(3)���������������detectMultiScale�������������м�⡣
����֮ǰ����,����ʹ����scaleFactor��minNeighbors���������ǻ�
ʹ��minSize����ָ������������С�ߴ�,����Ϊ120��120,��˲���
����ȥ��������ߴ�С������(�����û���������ͷ����,������
���յ�˵,ͼ�����û�����������120��120���ء�)�����Ƕ�
detectMultiScale�ĵ���:

(4)����������������ԭʼ��ɫͼ���ÿ��������Χ����һ
����ɫ�߽硣Ȼ��,�ڻҶ�ͼ���ͬһ�����������ڽ����۾����:

�۾��������ȷ�ʱ����������Ҫ��һЩ������ܻῴ��
��Ӱ�����־��������������Ϊ���۾�����������Ϊ�˸��ƽ��,
���Գ��Խ�roi_gray����Ϊ������һ����С����,��Ϊ���Ǻ����ײ²�
���۾���ֱ�������е�λ�á�����������ʹ��maxSize������������Щ
̫�������۾���������,���Ե���minSize��maxSize,ʹ�ߴ�
��w��h(������������С)�ɱ�������Ϊһ����ϰ,���������
����������������������
(5)ѭ���������ɵ��۾�����,��������Χ������ɫ����:

(6)���,�ڴ�������ʾ���ɵ�֡:
���нű�����������������ȷ�Ľ��,����������κ�����
������ͷ����Ұ��,Ӧ�ûῴ��������Χ��һ����ɫ�ľ���,�۾���
Χ��һ����ɫ�ľ���,��ͼ5-2��ʾ��?
?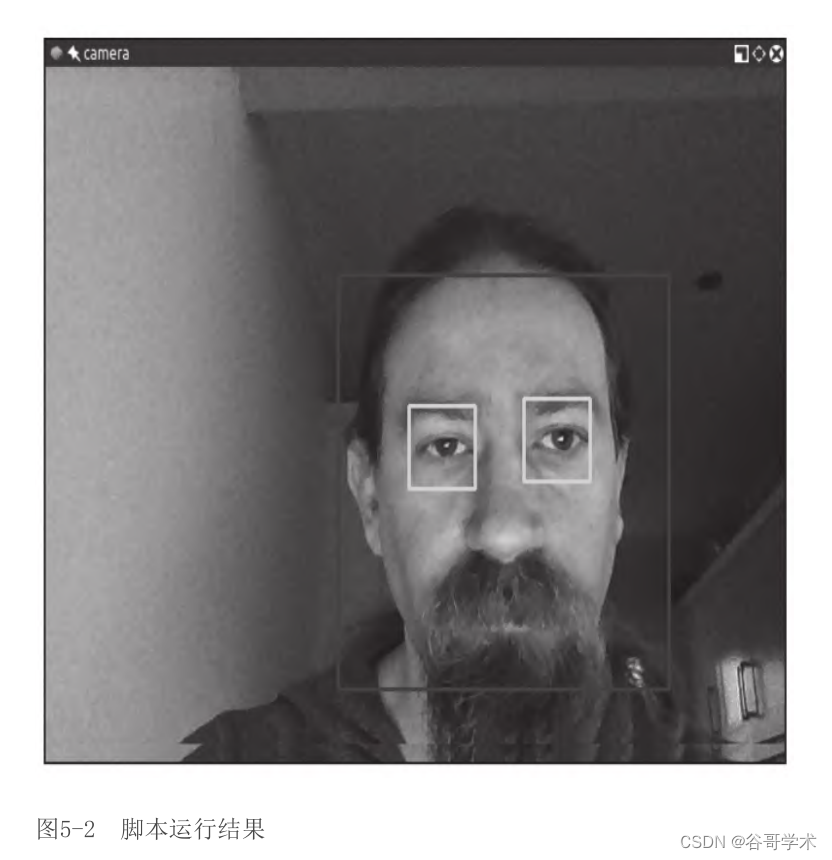
ͼ5-2��?�ű����н��
�ô˽ű�����ʵ��,�о��������۾�������ڲ�ͬ�����µı�
�֡������ڸ���������ķ�����С���������۾�,����ժ���۾���
����һ�Ρ������ڲ�ͬ�����Ͳ�ͬ�ı����½��С������ű��еļ��
����,������Щ�����Խ����Ӱ�졣����е�����ʱ,������������
��OpenCV�л�������Щʲô��
5.4.3��?��������ʶ��
���������OpenCV��һ���dz���������,Ҳ�ǹ��ɸ����IJ���
��������ʶ�𡪡��Ļ�����ʲô������ʶ��?����ʶ���dz����ڸ���
����������ͼ�����Ƶʱʶ����˵�������ʵ����һĿ��ķ���֮һ
(Ҳ��OpenCV�����õķ���)��ͨ��Ϊ�����ṩһ�����ͼƬ(����
���ݿ�)��ѵ������,Ȼ�������ЩͼƬ����������ʶ��
OpenCV����ʶ��ģ�����һ����Ҫ������,ÿ��ʶ����һ����
�Ŷ�,������������ʵ��Ӧ�ó�����������ֵ�����ƴ���ʶ��ķ���
�ʡ�
�����Ǵ�ͷ��ʼ��Ϊ�˽�������ʶ��,������Ҫ��ʶ���������
��������ͨ�����ַ�ʽ����ȡ:�Լ��ṩͼ�����ȡ��ѵ�������
�ݿ⡣��http://www.face-rec.org/databases/����һ�����������
�ݿ����߿��á����������м�������������:
��Ү³��ѧ�������ݿ�(Yalefaces),��ַΪ
http://vision.ucsd.edu/content/yale-face-database��
����չ��Ү³��ѧ�������ݿ�B,��ַΪ
http://vision.ucsd.edu/content/extended-yale-face-database-b-b��
���������ݿ�(���Խ���AT&Tʵ����),��ַΪ
http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html��
Ϊ�˶���Щ������������ʶ��,���DZ�������������˵�����
ͼ���������ʶ��������̿������н�ѧ�����,���ǿ��ܲ�����
�������Լ���ͼ�������������⡣���������Ӿ�ѧϰ����ͬ������
��:�Ƿ���Ա�дһ��������ʶ���Լ�����������һ�������Ŷȡ�
1.��������ʶ������
��������д������Щͼ��Ľű���������ͬ�����ͼ����������
����Ҫ��,����ѵ��ͼ������������ε�,���Ҵ�С��ͬ�����ǵ�ʾ
���ű�Ҫ��ͼ��Ĵ�СΪ200��200,���Ǵ������ѿ��õ����ݼ���
ͼ������ߴ�С��
�����ǽű�:


������,�������������յ��������Ƶ�м��������֪ʶ������
����ͼ�����Ǽ������,�ü��Ҷ�ת��֡����������,�����С��
��Ϊ200��200����,Ȼ��ΪPGM�ļ�,�����ض��ļ�����ָ������
(�ڱ�����Ϊjm,����һ����������������ĸ,�����ʹ���Լ�����
������ĸ)�������ര��Ӧ�ó���һ��,�����һֱ����,ֱ���û�
����ij������
֮���Գ���count��������Ϊ������Ҫͼ����ۼ����ơ����нű�
������,���ļ�����������,�����ű���ָ����Ŀ���ļ��С�����
�ű�������,�ı��沿���鼸��,������ڽű���ָ����Ŀ���ļ�
�С���ᷢ�ֺܶ��������ͼ��,���DZ�Ϊ�˻ҶȰ汾,�����˴�
С,����<count>.pgm��ʽ������
��output_folder����,ʹ�����������ƥ�䡣����,�����ѡ
��'../data/at/my_name'�����нű�,�ȴ���������֡(����20֡��
����)�м������,Ȼ��������˳�������,�ٴ���
output_folder����,ʹ��������Ҫʶ���һ�����ѵ�����ƥ�䡣��
��,�����ѡ��'../data/at/name_of_my_friend'�����ı��ļ��е�
��������(������Ϊ'../data/at'),��Ϊ�ں��桰��������ʶ���
ѵ�����ݡ�����,���ǽ���д�������������ļ��е��������ļ���
�м���ѵ��ͼ�������������������ͷǰ,�ٴ����нű�,������
����֡�м�������ѵ���,Ȼ���˳���������ʶ��������κ����ظ�
������̡�
����,���Ǽ�����������Ƶ�ش��ź���ʶ���û����������ܺ�
��!
2.ʶ������
OpenCV 4ʵ����3�ֲ�ͬ������ʶ���㷨:������
(Eigenface)��Fisherface�;ֲ���ֵģʽֱ��ͼ(Local Binary
Pattern Histogram,LBPH)����������Fisherface��Դ��һ����Ϊ��
�ɷַ���(Principal Component Analysis,PCA)��ͨ���㷨���й�
�㷨����ϸ����,��μ���������:
��PCA:Jonathon Shlens��http://arxiv.org/pdf/1404.1100v1.pdf����
����һ��ֱ�۵Ľ��ܡ����㷨���ɿ�����Ƥ��ɭ(Karl Pearson)��
1901�귢����,����ԭ�����ġ�On Lines and Planes of Closest Fit to
Systems of Points in Space����ַΪhttp://pca.narod.ru/pearson1901.pdf��
��Eigenface:�����ġ�Eigenfaces for Recognition��(1991)(����
��Matthew Turk��Alex Pentland),��ַΪ
http://www.cs.ucsb.edu/~mturk/Papers/jcn.pdf��
��Fisherface:���������ġ�The Use of Multiple Measurements in
Taxonomic Problems��(1936)(������R.A.Fisher),��ַΪ
http://onlinelibrary.wiley.com/doi/10.1111/j.1469-
1809.1936.tb02137.x/pdf��
���ֲ���ֵģʽ:���ܸ��㷨�ĵ�һƪ�����ǡ�Performance
evaluation of texture measures with classification based on Kullback
discrimination of distributions��(1994)(������T.Ojala��M.Pietikainen��
D.Harwood),��ַΪhttps://ieeexplore.ieee.org/document/576366��
�ͱ������,���Ƕ���Щ�㷨��һ������������,��Щ�㷨����
ѭһ�����ƵĹ���:����һ�����۲�(���ǵ��������ݿ�,ÿ����
��������������),�ڴ˻�����ѵ��һ��ģ��,������ͼ��(�����
��������ͼ�����Ƶ�м�����������)���з�����ȷ��������
��������������Լ��������������ȷ�����ĵĶ���������ͨ������
Ϊ���Ŷȡ�
�������㷨ִ�����ɷַ���(PCA),ʶ��ijһ��۲�����(ͬ��
���������ݿ�)�����ɷ�,���㵱ǰ�۲�ֵ(ͼ���֡�м�����
��)��������ݼ���ɢ��,������һ��ֵ����ֵԽС,�������ݿ���
��������֮��IJ����ԽС,���ֵΪ0��ʾ��ȷƥ�䡣
FisherfaceҲ�Ǵ����ɷַ���(PCA)������,��Ӧ���˸����ӵ�
������Ȼ������ܼ�,���Dz����Ľ���������������㷨��ȷ��
�෴,LBPH�����������ֳ�С��Ԫ��,��Ϊÿ����Ԫ����
һ��ֱ��ͼ,�����ڱȽϸ����������������ʱͼ��������Ƿ�����
�ӡ������Ԫ���ֱ��ͼ������ģ������Ӧ�ĵ�Ԫ����бȽ�,�Ӷ�
���������Զ�������OpenCV������ʶ������,LBPH��ʵ����Ψһ����
ģ�����������ͼ����������в�ͬ��״����ͬ��С������ʶ��
�������,���ܷ���,��������߷��ָ��㷨��ȷ��������������
�㷨��
3.��������ʶ���ѵ������
����ѡ��ʲô��������ʶ���㷨,���Ƕ�������ͬ���ķ�ʽ����
ѵ��ͼ����ǰ��ġ���������ʶ�����ݡ�������,����������ѵ��
ͼ��,�������DZ����ڸ�����������������ĸ������֯���ļ����С�
����,������ļ��нṹ��������������Joseph Howse(J.H.)��
Joe Minichino(J.M.)������ͼ������:?

���DZ�дһ���ű�������Щͼ��,����һ��OpenCV������ʶ����
�ܹ�����ķ�ʽ�����ǽ��б�ǩ��Ҫ�����ļ�ϵͳ������,���ǽ�ʹ
��Python�����osģ���Լ�cv2��numpyģ�顣���Ǵ���������
import��俪ͷ�Ľű�:

������������read_images����,�ú������Ա���Ŀ¼����Ŀ¼,
����ͼ��,����Щͼ�����Ϊָ���Ĵ�С,�����������ͼ�����һ
���б��С�ͬʱ,�ú��������������������б�:��һ������������
������ĸ�б�(�������ļ�������),�ڶ���������ص�ͼ�������
�ı�ǩ�б�������ID�б�������,jh��һ������,0�����Ǵ�jh���ļ�
�м��ص�����ͼ��ı�ǩ�����,�ú�����ͼ��ͱ�ǩ�б�ת��Ϊ
NumPy����,������3������:�����б���ͼ���NumPy����ͱ�ǩ��
NumPy���顣�����Ǹú�����ʵ��:?

ͨ���������´������read_images����:

�༭֮ǰ������е�path_to_training_images����,��ȷ���ñ�
����֮ǰ����������ʶ�����ݡ����ֵĴ����ж����output_folder����
�Ļ����ļ�����ƥ�䡣
��ĿǰΪֹ,�����Ѿ��������ø�ʽ��ѵ������,���ǻ�û�д�
������ʶ����,Ҳû�н����κ�ѵ�������ǽ��ڽ����������������
��Щ����,ͬʱ������ʵ��ͬһ�ű���
4.������������������ʶ��
��Ȼ����ѵ��ͼ�����鼰���ǩ����,ֻ�����д���Ϳ��Դ���
��ѵ��һ������ʶ����:

��������������ʲô?����ʹ��OpenCV��
cv2.EigenFaceRecognizer_create������������������ʶ����,ͨ��
����ͼ������ͱ�ǩ(����ID)����ѵ��ʶ���������ǻ�����ѡ��
�����������ݸ�cv2.EigenFaceRecognizer_create:?
��num_components:����PCA��Ҫ���������ɷ�������
��threshold:����һ������ֵ,ָ�����Ŷ���ֵ���������Ŷȵ���
��ֵ��������Ĭ�������,����ֵ�����ֵ,��˲��ᶪ���κ�
������
Ϊ�˲���ʶ����,����ʹ��һ�������������һ������ͷ�Ļش�
��Ƶ�źš�������ǰ��Ľű�������������,���ǿ���ʹ�����´���
����ʼ�����������:

����Ĵ����ʼ������ͷ�ش��ź�,����֡(ֱ���û���������
��)����ÿһ֡������������ʶ��:
 ?����������ǰ������������Ҫ�Ĺ��ܡ�����ÿ��������
?����������ǰ������������Ҫ�Ĺ��ܡ�����ÿ��������
��,���Ƕ�������ת�����������Ĵ�С,�Ա���ƥ��Ԥ�ڴ�С�Ļ�
�Ȱ汾(�ڱ�����,Ԥ�ڴ�С�ǡ���������ʶ���ѵ�����ݡ�С����
training_image_size���������200��200����)��Ȼ��,���������
�Ҷ��������ݸ�����ʶ������predict�������ú���������һ����ǩ��
���Ŷȡ����Dz��Ҷ�Ӧ�������������ֱ�ǩ��������(���ס,����
�ڡ���������ʶ���ѵ�����ݡ��д�����names���顣)������ʶ���
�����Ϸ�����ɫ�ı��������������Ŷȡ��ڱ������м�������֮
��,��ʾ��ע�͵�ͼ��
���Dz�����һ�ּķ���������������ʶ��,��Ŀ����
�����ܹ�����һ������Ӧ�ó���,������OpenCV 4�е�����ʶ���
�̡�Ҫ��Ľ�������ʹ�����³��,���Բ�ȡ��һ���IJ���,����,
��ȷ�ض�����ת���������Ӷ�����ȵ����ʶ��ȷ�ȡ�
���нű�,��Ӧ�ûῴ��������ͼ5-3��Ч����

������,���ǽ�������ε�����Щ�ű�,����������ʶ���㷨��
�滻��������
5.����Fisherface��������ʶ��
��λ���Fisherface��������ʶ��?����������������̲���
��仯,ֻ��Ҫʵ����һ����ͬ���㷨��ʹ��Ĭ�ϲ���,model������
��������:

cv2.face.FisherFaceRecognizer_create������
cv2.createEigenFace-Recognizer_create��ͬ��������ѡ����:Ҫ��
�������ɷ����������Ŷ���ֵ��
6.����LBPH��������ʶ��
���,���ǿ����˽�һ��LBPH�㷨��ͬ��,�ù���Ҳ����������
�̡�����,�㷨�����������¿�ѡ����(��˳��):
��radius:���ڼ��㵥Ԫ��ֱ��ͼ������֮������ؾ���(Ĭ��Ϊ
1)��
��neighbors:���ڼ��㵥Ԫ��ֱ��ͼ��������(Ĭ��Ϊ8)��
��grid_x:ˮƽ�ָ������ĵ�Ԫ������(Ĭ��Ϊ8)��
��grid_y:��ֱ�ָ������ĵ�Ԫ������(Ĭ��Ϊ8)��
��confidence:���Ŷ���ֵ(Ĭ�������,Ϊ���ܵ���߸���ֵ,
�����Ͳ��ᶪ���κν��)��
ʹ��Ĭ�ϲ���,model����������ʾ:

��ע��,ʹ��LBPH,���Dz���Ҫ����ͼ��Ĵ�С,��Ϊ����
Ϊ����������ÿ����Ԫ����ʶ���ģʽ���бȽϡ�
7.�������Ŷȶ������
predict��������һ��Ԫ��,���е�һ��Ԫ����ʶ�ĸ���ı�
ǩ,�ڶ���Ԫ�������Ŷȡ����е��㷨�������������Ŷ���ֵ��ѡ
��,����ֵ����ʶ��������ԭʼģ�͵�ƥ��̶�,���,��ֵΪ0
��ʾ��ȫƥ�䡣
��ijЩ�����,�������Ը�������е�ʶ����,��Ӧ�ý�һ��
�Ĵ���,������Ϳ�������Լ����㷨������ʶ���������Ŷȡ���
��,����㳢����ʶ����Ƶ�е���,�����ϣ���������֡�е�����
��,��ȷ���Ƿ�ʶ��ɹ��������������,����Բ鿴�㷨��õ���
�Ŷ�,���ó��Լ��Ľ��ۡ�
���Ŷȵ��͵�ȡֵ��Χȡ�����㷨����������Fishface������
ֵ�ķ�Χ(����)��0~20 000,����4000�����з�ֵ����ʾ��һ����
�������ĵ�ʶ����������LBPH,�õ�ʶ�����IJο�ֵ����50,��
�г���80��ֵ������Ϊ���������Ŷȡ�
������Զ��巽����,ֱ�����㹻��ľ��������������������
�ȵ�֡��ʱ,����ʶ��������Χ���ƾ���,��������ȫ����ʹ��
OpenCV������ʶ��ģ����������Ҫ����Ӧ�ó���
5.5��?�ں������»���
��������ʶ�������ڿɼ����ס��ڽ�����(Near-
Infrared,NIR)����ͷ�ͽ������Դ��,��ʹ�����ۿ�����ȫ�ڵij�
����,��������ʶ��Ҳ�ǿ��ܵġ���������ڰ�ȫ�ͼ���Ӧ�ó���
�зdz����á�
�ڵ�4����,�����о��˻�˶Xtion PRO�Ƚ������������ͷ�Ļ�
���÷���������չ�˽���ʽӦ�ó���Cameo�����������롣��������
������ͷ������һЩ���档�������,���ǽ�ÿһ֡�ָ��һ������
(���û�����)�������㡣������ͼ��Ϳ�ɺ�ɫ,�����ʹﵽ������
������Ч��,ʹ�ý�����Ƶ�ź���ֻ������(�û�����)��������Ļ
�ϡ�
����,������Cameo,��ϰ֮ǰ����ȷָ���Լ���������
�¼��ܡ��������������,��ͬһ֡�м�������������ʱ,����
��������,ʹһ���˵�ͷ��������һ���˵������ϡ����Dz��Ḵ�Ƽ�
������������е���������,����ֻ���Ƹþ�������Ȳ��һ����
���ء���Ӧ��ʵ���˻�����Ч��,������������Χ�ı������ء�
һ�������,Cameo���ܹ���������ͼ5-4�������

���ǿ���Լɪ��˹��������ĸ�������ء���˹(Janet
Howse)���������ˡ�����Cameo�ǴӾ�������������(��ǰ����,
��������ĵײ������ɼ�),һЩ��������û�н���,�������Dz���
�������еط����о��α�Ե��
�������https://github.com/PacktPublishing/Learning-
OpenCV-4-Computer-Vision-with-Python-Third-Edition���ҵ�����
���ж�CameoԴ�����������ظ���,�ر�����chapter05/cameo�ļ�
���е��ġ�Ϊ�����,���Dz����ڱ������������е���,����
���ڽ�����������С��������һЩ�ص����ݡ�
5.5.1��?��Ӧ�ó����ѭ��
Ϊ��֧�ֻ�������,Cameo��Ŀ��������ģ��,��Ϊrects��
trackers��rectsģ��������ڸ��ƺͽ������εĺ���,����һ����ѡ
����ģ,�ɽ����ƻ������������ض����ء�trackersģ�����һ
����ΪFaceTracker����,��ʹOpenCV������������Ӧ��������
��̷��
��Ϊ�����Ѿ��ڱ���ǰ�������OpenCV����������,������
����ǰ����½�����ʾ���������ı�̷��,�������ﲻ������
FaceTracker��ʵ�֡�������ڱ���Ŀ��в鿴FaceTracker��ʵ�֡�
��cameo.py,�����Ϳ��������Ӧ�ó����ȫ������:
(1)���ļ��Ķ���,��Ҫ�����µ�ģ��,�����д�����еĴ���
��ʾ:

(2)����,���ǰ�ע����ת���CameoDepth���__init__������
�ġ����º��Ӧ�ó���ʹ����һ��FaceTrackerʵ������Ϊ�书�ܵ�
һ����,FaceTracker�����ڼ���������Χ���ƾ��Ρ����Ǹ�
Cameo���û�һ��ѡ�������û�����������εĻ��ơ����ǽ�ͨ��һ��
�����������ٵ�ǰѡ���ѡ�����Ĵ������ʾ�˳�ʼ��
FaceTracker����Ͳ�����������ĸ���(�Դ�����ʾ):

������CameoDepth��run������ʹ����FaceTracker����,�÷���
��������ʹ���֡��Ӧ�ó�����ѭ����ÿ�ɹ�����һ֡,�͵���
FaceTracker�ķ������������������,����ȡ���¼���������
Ȼ��,����ÿ����,�����������ͷ�Ӳ�ͼ������ģ��(�ڵ�4����,
�����������ͼ����һ����������ģ,���������ÿ����������
������ģ��)Ȼ��,���ú���rects.swapRects��ִ���������ε���ģ
������(�Ժ�,���ǽ���5.5.2��������swapRects��ʵ�֡�)
(3)���ݵ�ǰѡ���ѡ��,���ǿ��ܻ���FaceTracker��������
Χ���ƾ��Ρ�������صĸ���������Ĵ�������Դ�����ʾ:


(4)���,��onKeypress�����Ա��û�����X����ʼ��ֹͣ
��ʾ����������Χ�ľ��Ρ�ͬ��,��صĸ���������Ĵ������
�Դ�����ʾ:?

?������,���������ڱ���ǰ�浼���rectsģ���ʵ�֡�
5.5.2��?��ģ���Ʋ���
rectsģ������rects.py��ʵ�ֵġ���5.5.1����,�����Ѿ�����
��rects.swapRects������һ�����á�����,�ڿ���swapRects��ʵ��
֮ǰ,����������Ҫһ����������copyRect������
�ص���2��,����ѧϰ�����ʹ��NumPy����Ƭ������ݴ�һ��
����Ȥ�ľ��������Ƶ���һ������Ȥ�ľ��������ڸ���Ȥ�ľ���
����֮��,Դ��Ŀ��ͼ����Ӱ�졣����,�������һ�����������
�Ʋ�����������Ҫʹ��һ����Դ������ͬ��С�ĸ�����ģ��
���ǽ�ֻ����Դ��������ģֵ��Ϊ�����Щ���ء���������Ӧ��
��Ŀ��ͼ���ԭʼֵ�����������һ������������������ܵ����
ֵ����,������numpy.where�������ر��
�μ����ַ���,����������copyRect������������һ��Դͼ���
Ŀ��ͼ��һ��Դ���κ�Ŀ�����,�Լ�һ����ģ��Ϊ���������߿�
����None,�����������,ֻ�����Դ���ε����ݴ�С��ƥ��Ŀ���
��,Ȼ����������ݷ����Ŀ����μ��ɡ�����,��������Ҫȷ
����ģ��ͼ������ͬ��ͨ������������ģ��һ��ͨ��,����ͼ�����
������ͨ��(BGR)�����ǿ���ʹ��numpy.array��repeat��reshape��
�����ظ�ͨ�����ӵ���ģ�С����,ʹ��numpy.whereִ�и��Ʋ�����
������ʵ������: