基于长短期记忆网络(LSTM)的意见领袖对舆论风向的研究、网络暴力研究、LSTM情感分分类、意见领袖的影响力、神经网络实战、数据分析实战、蔡徐坤潘长江网络暴力事件、数据可视化实战、舆情研究
文章目录
摘要
随着互联网的高速发展,网络暴力是其中难以避免的一个问题,频频爆发的网络暴力事件,不但是对公民隐私权的侵犯,还是造成各种恶性事件发生的重要诱因,本文通过对微博热点事件“潘长江不认识蔡徐坤”的评论情感分析,试图探究在网络暴力事件当中,意见领袖对舆论风向的影响,探寻不同的意见领袖对其粉丝群体的评论情感的影响。本次实验使用 Pandas对数据进行预处理,使用Matplotlib,Seaborn,Pyecharts这三种绘图库对数据进行可视化展现,使用Keras,PyTorch等机器学习高级API库的LSTM长短期记忆网络以及其他的机器学习工具,利用随机抽取的5000条数据,对LSTM神经网络进行训练通过训练的模型,对评论数据进行情感预测。并且对用户的属性与评论进行相关性分析和对评论性质进行识别与检测,探究用户的各个属性与评论之间的相关性。
关键字:意见领袖,微博,数据可视化,长短期记忆网络(LSTM)
第一章 绪论
1.1 研究背景及意义
2019年蔡潘事件一度成为网络舆情的热点之一,由于潘长江在节目中不认识当红明星蔡徐坤的表现,导致他在接下来的时间里,被其部分粉丝群体以及水军所攻击和辱骂,这件事情的发生一度让潘长江在接下来的一段时间里,频繁地受到了网络暴力的侵害,并且引起了网友们的广泛关注。在这次时间中, 网络舆情, 尤其是在信息传递和人际互动中能够对他人施加影响的意见领袖的观点不尽相同, 这也一定程度影响了用户评论的风向, 因而有效识别意见领袖的评论对于普通用户大众的评论导向较为关键。
微博作为网络舆情的主要载体之一, 一方面因为其是实名制, 能够反映用户特征;另一方面, 可以反映博客内容、被转次数、被评论次数、粉丝数等量化的指标, 在阅读量、言论自由等方面也强于其他类型媒体, 进而可以刻画出意见领袖的特征。基于此, 本文拟通过神经网络的方法, 通过文献的参考以及模型对数据的预测结果,分析微博中意见领袖的评论对普通用户大众的信息影响力。
基于这些背景,我们认为探寻意见领袖对舆论、网络暴力等事件的情感走向的影响是有很大的必要性的,对于高影响力的人物,是否真如我们所认知的那样,其言语,对某些事情的看法,无论是支持他人还是反对、攻击他人,追随他的粉丝群体以及不明真相的大众们也会随着意见领袖的言行举止表现出相同的情感倾向,还是说对于不正确的,有明显言语攻击倾向的意见领袖,追随他的粉丝群体和大众不随波逐流,会有更理性的判断。基于以上的问题,我们做出了以下的研究。
1.2 主要工作任务
本次工作的目标是:研究意见领袖评论对评论的影响,会不会激发大众的情绪?因为做评论的情感分析时是非常主观的,不同的人认为评论的情感不同,有的人认为这是支持态度的,有的人会认为这是暗讽,这对于人工区分都是十分困难的,如果没有足够的数据训练,单靠一个模型很难学到特征,且网络用语不规范,特征很难学习,若出现网暴词汇就认定为出现网暴倾向,便无法反应评论的人的真实情感。所以我们决定人工定义网暴词汇,找明确网暴词汇,做第二次筛选,若评论为中性不存在网暴问题,根据意见领袖发表评论的评论偏向,若积极则倾向积极。
将标签0作为支持或者中立,标签1很明确网暴倾向,训练情感二分类模型,主要是为了探究在意见领袖的回复评论中,对这件事情表示反对,有明显网络暴力倾向的人数比例,作为该意见领袖的一个反对率,再观察意见领袖对此事的评论情感对其粉丝群体反对率的影响变化,以此来确定意见领袖对事情的情感走势是否存在影响。
第二章 模型基本概述
2.1 LSTM模型的理论概述
长短期记忆神经网络(long shortterm memory networks,LSTM)是一种时间递归神经网络,是循环神经网络的一种变体,适合处理和预测时间序列中间隔和延迟相对较长的重要事件,这一技术特征与股票预测问题有着很高的契合度,将普通循环网络中的隐藏节点设计为自循环形式,记忆单元维持一个误差流,进而可以记忆长时期的有效信息,避免梯度爆炸和梯度消失。LSTM 在文本预测、情感分析和股票预测等领域都有着非常优异的表现,结合股票特性将基础数据转换为相关的技术指标。它还改善了RNN中存在的长期依赖问题;LSTM的表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好;作为非线性模型,LSTM可作为复杂的非线性单元用于构造更大型深度神经网络。但是仍然存在缺陷,就是RNN的梯度问题在LSTM及其变种里面得到了一定程度的解决,但还是不够。它可以处理100个量级的序列,而对于1000个量级,或者更长的序列则依然会显得很棘手;另一个缺点是每一个LSTM的cell里面都意味着有4个全连接层(MLP),如果LSTM的时间跨度很大,并且网络又很深,这个计算量会很大且很耗时。
2.2 LSTM的三个主要结构
1 遗忘门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为遗忘门层完成
2 输入门
输入门是决定让多少新的信息加入到cell状态中来。实现这个需要包括两个 步骤:首先,需要sigmoid层决定哪些信息需要更新;tanh 层生成一个向量,也就是备选的用来更新的内容。在下一步,我们把这两部分联合起来,对cell的状态进行一个更新。
3 输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,sigmoid层来确定细胞状态的哪个部分将被输出。接着,细胞通过 tanh 进行处理状态并将它和sigmoid层的输出相乘,最终会输出我们确定输出的那部分内容。
2.3 改进模型
LSTM模型有非常强大的功能,本文只是使用了相对简单的单步单特征的预测,更深入研究的话可以发现,LSTM还可以进行多步单特征,单步多特征,多步多特征等更强大的预测工作。除此之外,模型进行改进的地方还可以从模型的网络结构,训练模型的选项,网络层的激活函数等进行调整改进。
第三章 数据处理
3.1 数据抓取
对于微博数据的爬取工作,首先打开微博网页与控制台,抓取网页打开时的请求,通过多个手机号的登录cookie信息,爬取每页的数据,将爬取的数据存入到队列当中,与此同时开启第二条线程,在这一条线程当中负责处理队列中所爬取的数据,格式化数据后,将数据存入到数据库中,最后启动递归调用,这样就能不断地进行微博数据的抓取工作。
3.2 数据可视化
3.2.1 评论用户的性别分布
数据选取了六万多条样本数据作为对整体数据的预测和分析,发掘爬取数据之间的关系,有助于研究用户评论与用户其他性质之间的关系。
评论用户的性别情况
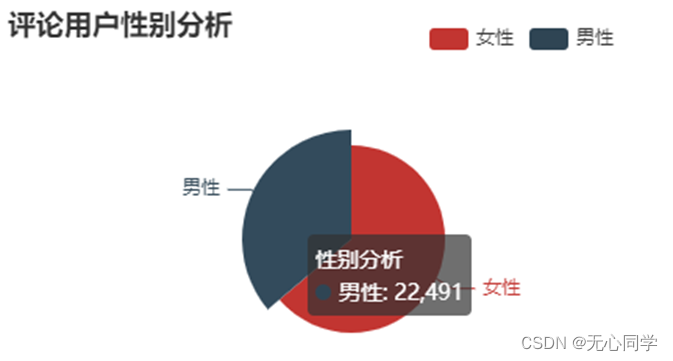
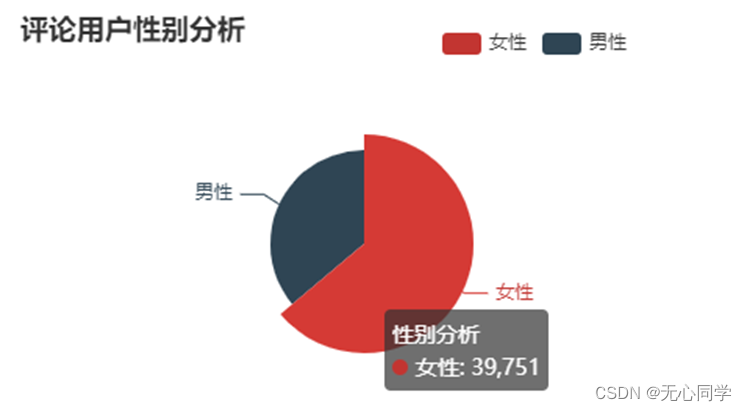
第一张图为所有用户的性别情况。这确实也符合蔡徐坤的粉丝群体,女性较多,相比与男性,更加感性的女性也会更关注这次的事件,发表自己的言论。
3.2.2 评论用户关注数分布
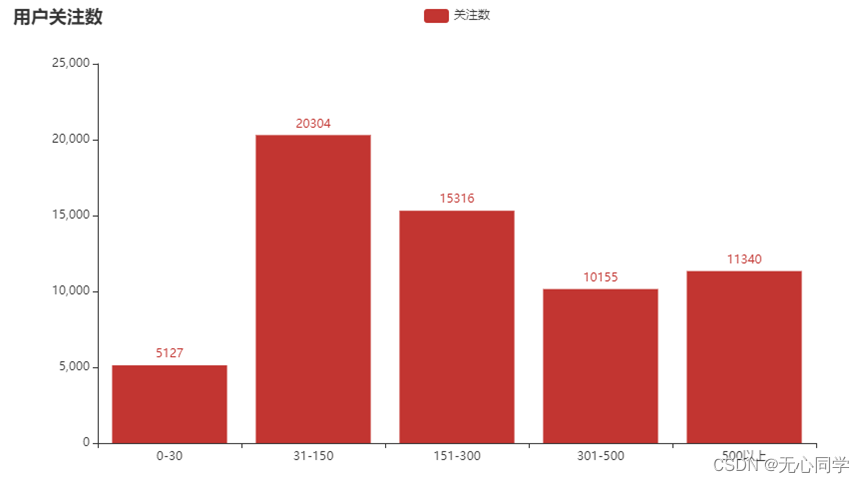
从柱状图中可以看出在这件事件的评论用户当中,主要的评论对象的关注数都比较高,说明这件事情受更多的活跃用户的关注,发表评论的用户都是微博的忠实用户,或者大多数是不同意见领袖的粉丝。
3.2.3 评论用户发帖数分布
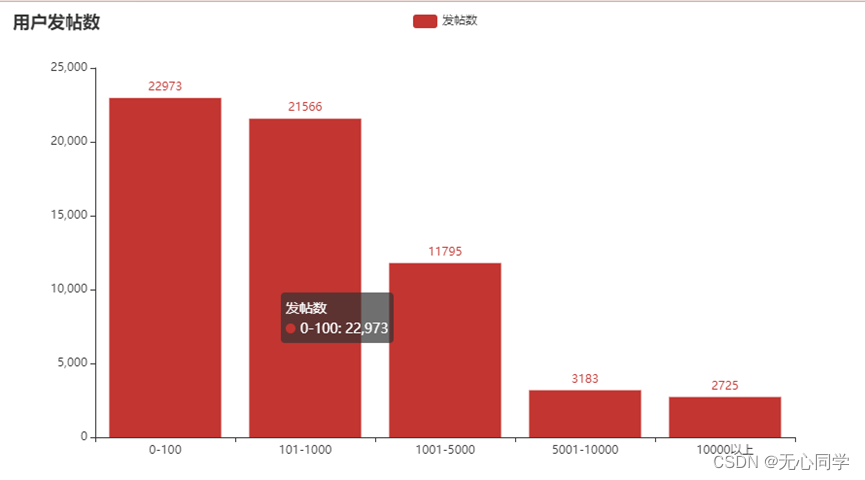
整体上符合常态,可以看出微博用户对于热点事件的关心程度还是较高的,说明了参与评论的用户都比较积极,平时也会投入较多时间在微博的使用上,但大部分人的发帖数并不多,可能是只抱着吃瓜的态度,而一些积极的用户遇到热点事件也会发表自己的观点并且进行转发。
3.2.4 用户粉丝数
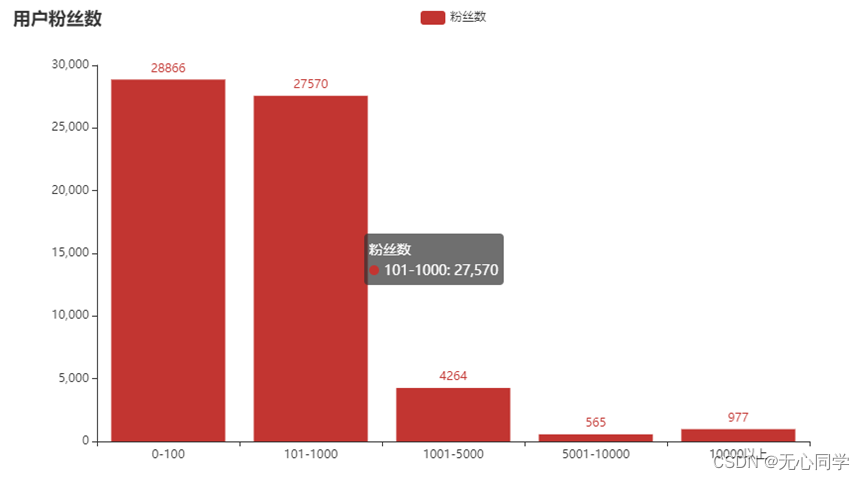
可以看出,参与事件讨论的大部分人的粉丝数都不高,这也是为微博这个软件的正常现象,粉丝多的人只有少部分,大多数人只是微博的使用者,而不是内容的创作者或者分享者,这也是粉丝数不高的原因。参与事件讨论的也不乏粉丝数多的人,有可能是抱着蹭热度的心态。
3.2.5 评论词云图

在图中能够很好的看出这次事件的两个主角,以及出现的关键词,从词云图中可以看出来,总体的事件就是围绕蔡徐坤以及潘长江关于网络暴力所展开的事件,其中的高频词也反映出了大家对这次事件的看法,高频词在整体上表现出解释和安慰的情绪更多,一定程度上反映了粉丝以及大众看待事情的理性。
3.2.6 时间热度分析
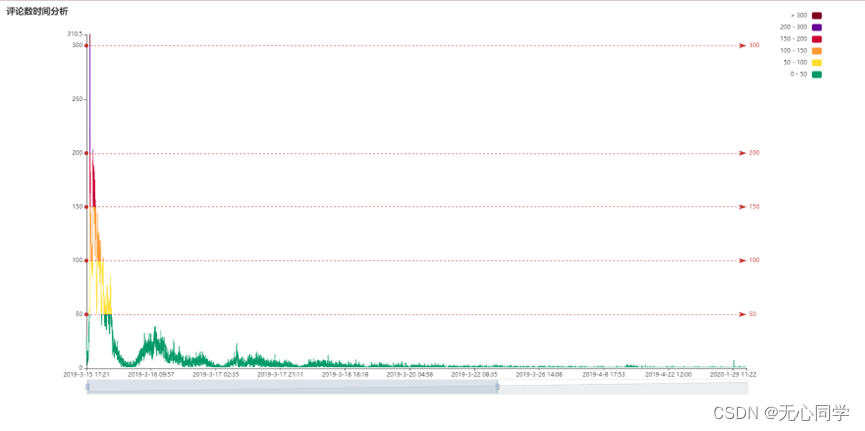
从图中可以看出,微博内容刚刚发布时,立马获取了很多人的关注,关注的时间主要集中在2019年3月15日左右,特别在下班晚饭的时间段,评论数达到了高峰。
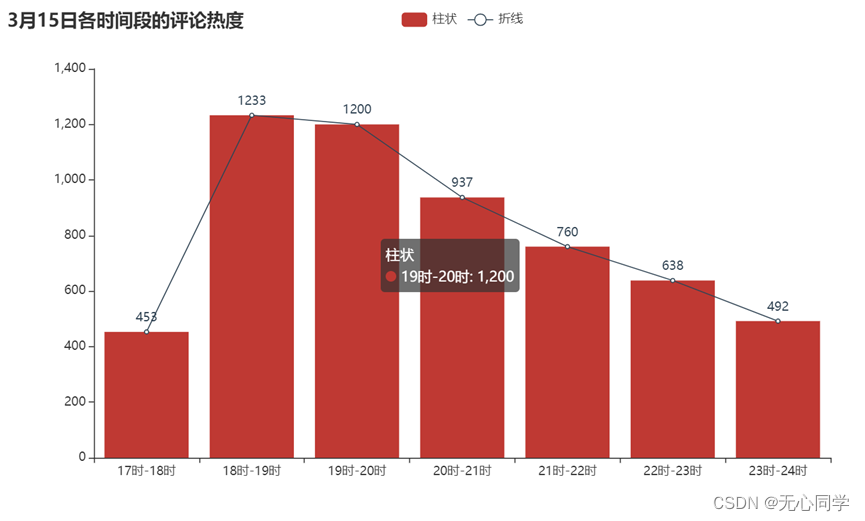
从以上的柱状折线堆叠图可以看出来,评论热度每小时都在慢慢减少,到了15号晚上以及16号就已经大幅度减少,这可能与微博管理人员删除了部分评论或者是蔡徐坤的工作室做了一些公关处理有关,但总体来说,作为一个热点,热度随着时间流逝而下降是很正常的。
3.2.7 相关性分析
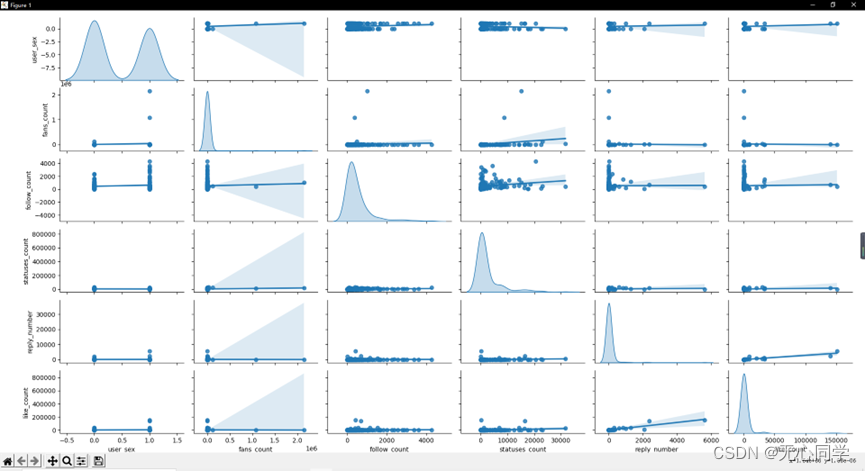
将数据进行相关性分析,从中可以看出,性别和粉丝数,发帖数,等没有太大关系,而用户的关注数和发帖数,评论的点赞数和回复数这几个指标相关性比较大。
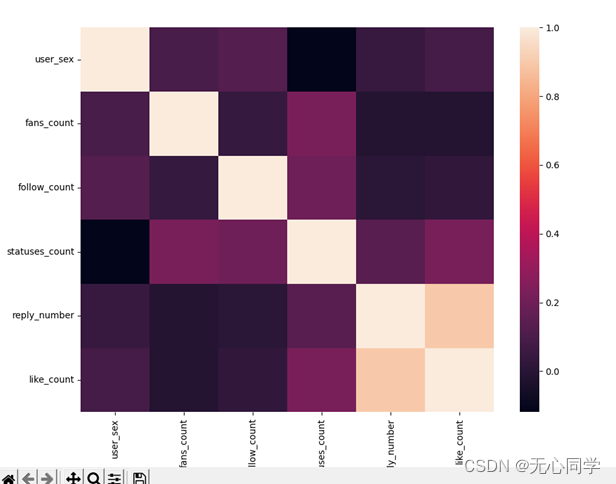
从皮尔逊相关系数热力图中也可以看出来,相关性较强的是用户的关注数和发帖数,评论的点赞数和回复数这几个指标。
3.3 训练模型
1 抽取数据进行分类
由于在网络暴力事件中,不能笼统地使用如飞桨提供的情感分类api以及SnowNLP这类库进行简单的正负面情感分类,由于经常会有站在受害者角度但是情绪较为激烈的言语,这类情感如果使用上述简单的方式进行分类,只会把这类情感归为消极的语言,但是这并不符合常理。所以我们打算先随机抽取部分数据,再通过人工进行打标签处理,将数据最终分为反对倾向以及非反对倾向两类,这样分的原因是因为情感中除了支持和反对的言语,还有部分不易分类的数据,并且我们的最终目标是为了计算反对率,所以将数据分为有明显的反对倾向和非反对倾向的即可。
部分已分类的数据如图所示:

2 导入所需模块
本次实验用到了常用的机器学习库,其中最重要的是keras,tensorflow,torch,wandb等等,其中使用的机器学习的模型是LSTM长短期记忆模型,这是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,且LSTM在情感分类,时序预测,语音识别中都有很好的预测效果,相比于普通的RNN,LSTM能够在更长的序列中有更好的表现。
3 获取数据
接下来我们需要使用pandas模块,读取存放数据的csv格式的文件,并将获取的两个Series进行concat合并,记录好两种分类的长度。
4 数据预处理
首先,对获取的数据进行分词处理,并且加载自定义的常见词语的用户字典,将分词后的数据存放在列表中,并形成单独的word列。
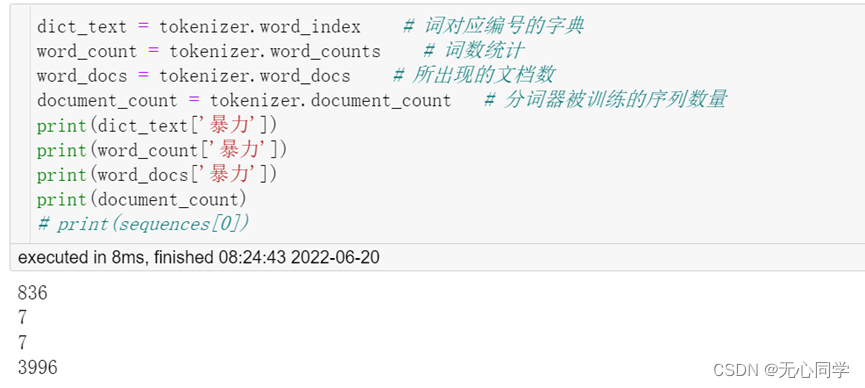
紧接着,将分词后的数据再使用空格进行分隔,并实例化分词器,设置字典中最大词汇数是30000,传入的数据用空格分隔,传入重新用空格连接好的句子,建立自定义的字典,并且将词转换成序列,列表中每个序列对应于一段输入文本,采用pad_sequences序列填充,序列最大长度为1000,超过这个长度将被截断,否则就在前面填充0,最后再将填充好的序列转换成ndarray
5 定义标签,切分数据集
先根据之前获取到的两个分类的数据长度,生成独热化的标签数据,按照合并数据的方式合并标签数据,紧接着,设置随机种子生成一个随机的下标索引列表,然后按照给定列表生成一个打乱后的随机列表,也就是生成随机序列数组以及随机标签数组。根据所生成的数据,按照定义好的变量,以90%的数据作为训练数据,以10%的数据作为检验数据。并且需要定义好torch的数据读取器。
6 定义LSTM神经网络模型
定义基于栈式 LSTM 的序列分类,首先需要添加一个Sequential序列层用作后续的序列调用,紧接着使用Embedding嵌入层,将所有索引标号映射到致密的低维向量中,以此来达到数据降维以及稠密表示,减少参数总量以及计算量。紧接着,添加一个包含20个神经元的LSTM层,并且定义好返回序列,然后就添加Dropout以50%的概率随机删除神经元,并使用Flatten层展开成1维数据,然后添加一个包含16个神经元,relu激活的Dense全连接层,最后添加包含两个神经元,softmax激活的Dense全连接层进行二分类。
模型摘要如图所示:

7 定义训练参数
首先配置模型的训练参数,选择Adam为优化器,初始学习率为0.001,采用
0.8为衰减率的ExponentialDecay指数衰减,损失函数选用适用于多分类损失函数计算的categorical_crossentropy分类交叉熵,计算accuracy准确率。定义好以上训练参数后,就可以准备好数据加载器加载数据,然后按照每个批次来进行大概8个epochs的训练。
训练过程大概如图所示:

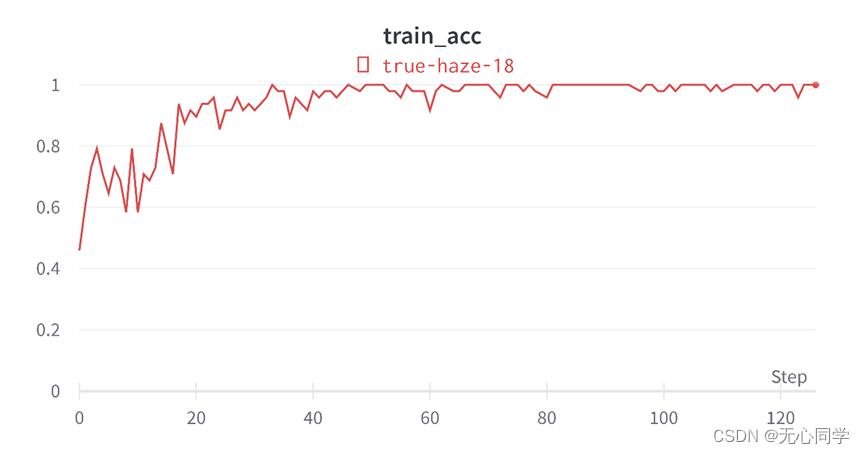
训练的精度变化图如图所示:
训练的损失函数变化图如图所示:
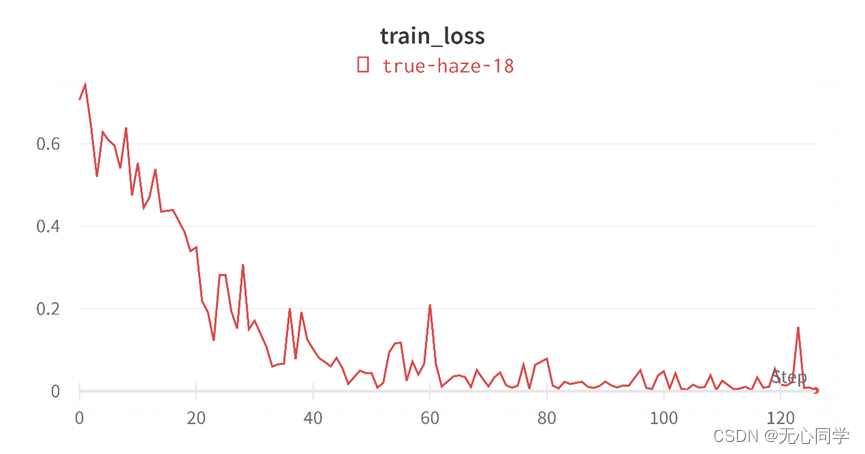
从以上的图可以看到,经过8个轮次的训练过后,损失函数已经下降到了一个相对较低的程度,训练的精度也在100%附近来回波动。
8 评估训练模型
在训练完模型之后,对训练的模型进行评估是必不可少的一步,我们可以由此来判断出是否存在过拟合、欠拟合等情况。接下来我们先用数据加载器对之前分割的10%的数据进行读取,按照每32个批次进行一次评估,最后对所有的评估数据进行平均化处理,得到最后的平均损失函数以及平均准确率,并将最后的平均数据添加到列表的末尾。
评估过程大概如图所示:

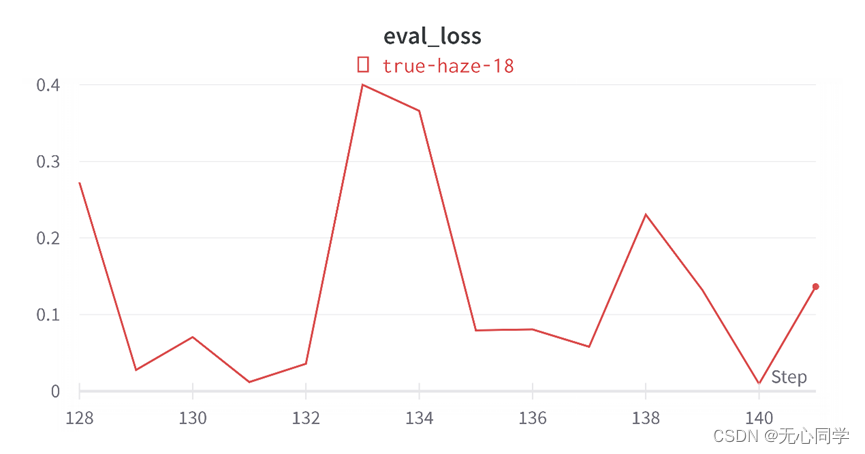
评估的精确度变化如图所示:
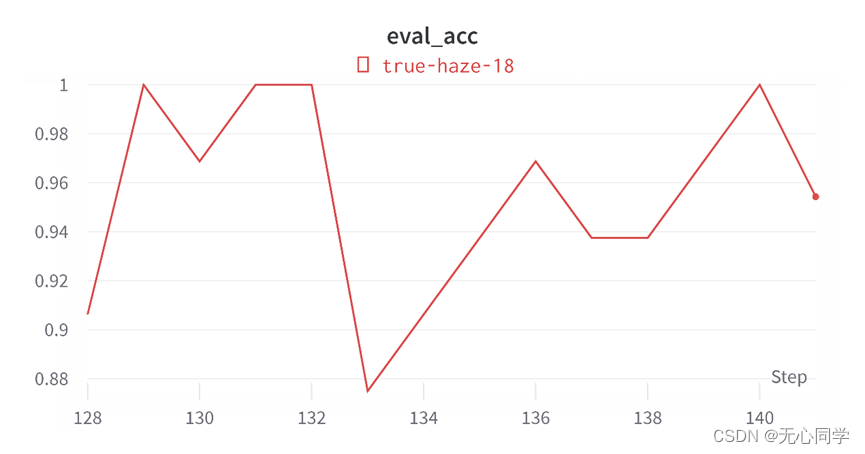
评估的损失函数变化如图所示:
整体的训练摘要图如图所示:
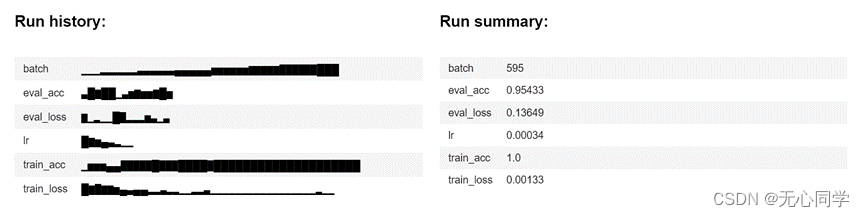
从以上的数据可以很清楚地看到,我们的训练效果还是很不错的,过拟合存在但是影响不大,所以接下来我们就需要用训练好的模型,来对其余的数据进行数据预测。
3.4 情感预测
1 数据预处理
首先我们需要把数据库中的数据转存到excel文件中,这样会更方便我们读取数据。输出DataFrame的摘要信息发现,fans_count这一列数据,是object类型。
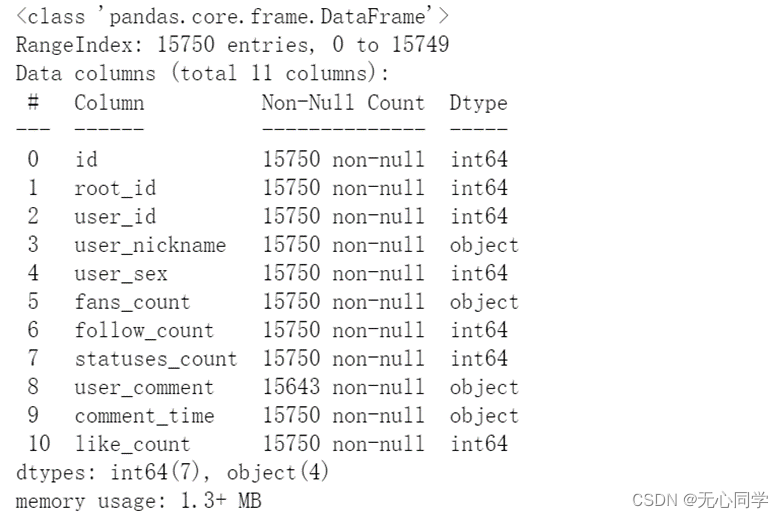
我们的期望是int64或者float32类型的数据,通过我们观察数据发现,在爬取数据的时候,这个数据是一个大致的缩小了一万倍的数据,包括了很多xxx万这一类数据,所以我们需要把万字去掉并在原来的基础上扩大一万倍。
2 筛选出意见领袖
根据前人的研究,我们使用如下的权重模型,从评论用户进行筛选

运用上述指标模型,可对每位博主进行信息影响力的评价计算,并将影响力大于一定阈值的博主选出,作为高影响力博主。
3 预测博主的评论情感
对于每位高影响力博主,如果是真正的意见领袖,则其发表事件相关博文时,其博文文本含有较强烈的主观色彩,所以我们通过已经训练好的LSTM情感分类模型,对意见领袖的评论进行情感预测,并将其分成消极和积极的,紧接着获取到意见领袖的id,根据意见领袖的id,筛选出回复意见领袖的评论数据,并对这部分的回复数据进行情感预测,获取到预测概率,情感类别,评论类型三个指标。
4 计算意见领袖的回复反对率
根据上面所预测的数据,计算在意见领袖的回复评论中,持消极反对的人数占总回复人数的比例,并根据意见领袖的评论情感,探究意见领袖的评论情感是否对部分网民的情感倾向造成影响。
最终,形成如下的表格

可以看到,在统计的前18个意见领袖的数据中,持积极支持态度的意见领袖是占大多数的,也可以看到积极意见领袖的回复评论中,反对率会更低一些,而在消极的意见领袖的回复评论中,反对率会相对更高一下。
结论
从以上的分析中可以看到,影响因子越高的意见领袖,往往不会去公开否定或者是攻击某一人物或者事件,而是会发表一些更偏向于客观或者是正面的评论和看法。在这些数据中可以看到,积极的意见领袖,在他的回复评论中,除去某些水军或者是捣乱故意抹黑他人的网民外,往往存在较大比例的网民,受其认可的意见领袖的情感状态的影响,发表较为正面积极的评论,所以对于积极的意见领袖而言,其底下回复的反对率是会相对较低的。而对于消极的意见领袖,在其底下的回复评论中,往往消极反对的评论比例会更大,虽然存在一部分更为理性的网民,但是也会因此带偏很多不明真相的群众,将不好的风评散播到社会上,挑起争端的同时会让更多的人遭受到网络暴力的侵害。这也说明了,意见领袖对某些人或事情的评论看法会影响大众的情绪与对这些人或事的看法,所以对于有高影响力的意见领袖而言,规范自己的言行举止是有很大的必要的,如果对某件事发表了过激的不正确的言论或看法,往往会误导大众发表一些不正确不健康的言论,情节严重甚至可能会造成一定程度的社会恐慌。所以对于意见领袖而言,不能发表过于包含自己主观色彩且片面的言论,而对于监管部门而言,制定一套规范发言的规章制度,控制不当言论的传播是有很大的必要性的。
而本研究的局限性在于:网络舆情的传播方式和传播途径多种多样,本文只是分析了微博这一平台中的数据。同时,由于微博中部分博主存在筛选评论和事后删除微博的行为,并且微博的审核管理员也会删除很大一部分的负面评论,以防止事件造成恶劣的影响,所以会导致爬取到的数据不全面,对最终结果的准确性有一定的影响。
参考文献
[1]胡若涵,张慧明.中兴通讯案:中美科技贸易摩擦的意见领袖识别研究[J].中国经贸导刊(中),2018(23):11-13.
[2]刘高勇,谭依雯,艾丹祥,黄靖钊.基于观点挖掘的突发事件微博意见领袖识别方法[J].广东工业大学学报,2021,38(04):41-51.
[3]向承才,王彬彬.网络暴力:言论自由下的新隐忧[J].传媒论坛,2022,5(3):10-1226
[4]关鹏飞,李宝安,吕学强,周建设.注意力增强的双向LSTM情感分析[J].中文信息学报,2019,0(2):105-111
[5]陈凌,宋衍欣.基于公众情绪上下文的LSTM情感分析研究――以台风“利奇马”为例[J].现代情报,2020,40(6):98-105
声明
本文章全部由本人独创完成,未经允许禁止转发与私自盗用,仅供学习交流使用,欢迎指出其中的不足
如需代码以及数据,请私信交流