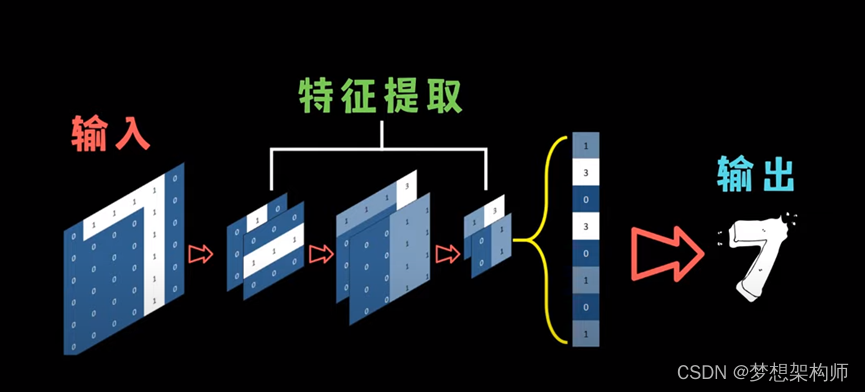
CNN步骤:
- Paddssing处理
- 提取特征
- 最大池化
- 扁平化处理
- 全链接网络隐藏层
Paddssing处理
Padding处理主要将图片像素矩阵扩充成4的倍数的矩阵
比如:6262 扩充成6464
特征提取
特征提取就是图片(M*N矩阵)通过卷积核,提取图像中特征,通过不同的的卷积核,可提取不同的特征

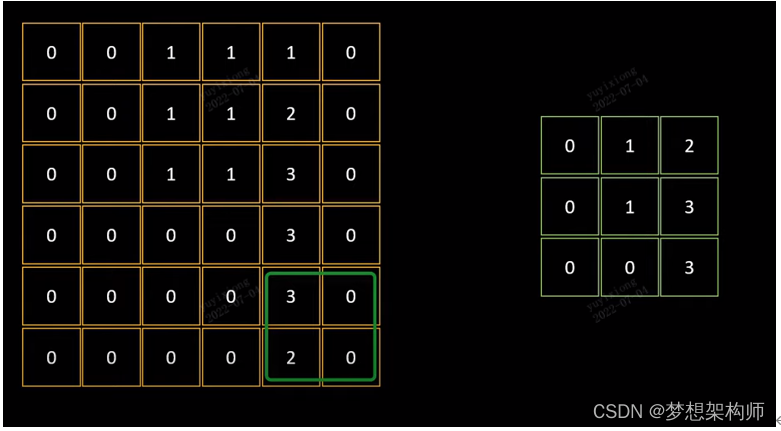
最大池化
仅反应最突出的部分
池化,也叫下采样,本质上其实就是对数据进行一个缩小。因为我们知道,比如人脸识别,通过卷积操作得到成千上万个feature map,每个feature map也有很多的像素点,这些对于后续的运算的时间会变得很长。
池化其实就是对每个feature map进一步提炼的过程。如图7所示,原来4X4的feature map经过池化操作之后就变成了更小的2*2的矩阵。池化的方法包括max pooling,即取最大值,以及average pooling,即取平均值
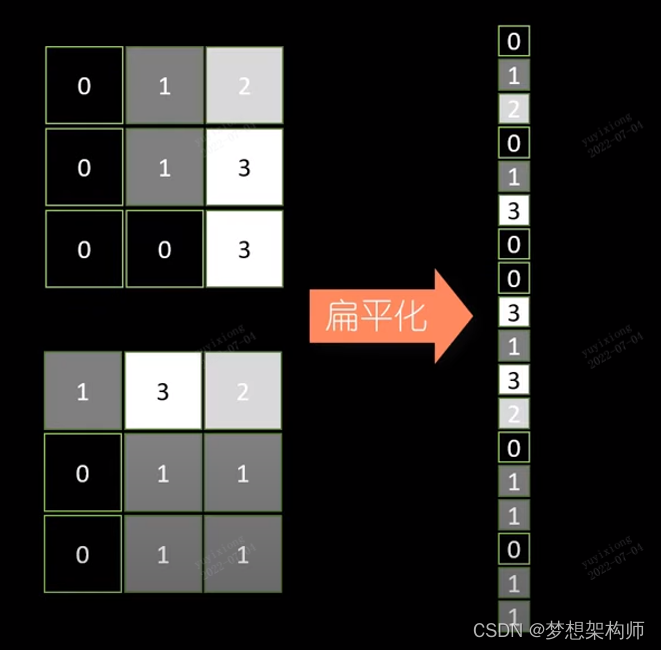
扁平化处理
扁平化处理,即把图像提取的所有特征,最大池化后(仅反应最突出的部分),将所有特征进行(矩阵)进行铺开,
铺开成一个N*1的单体矩阵(扁平化处理)。然后将该矩阵送入网络隐藏层
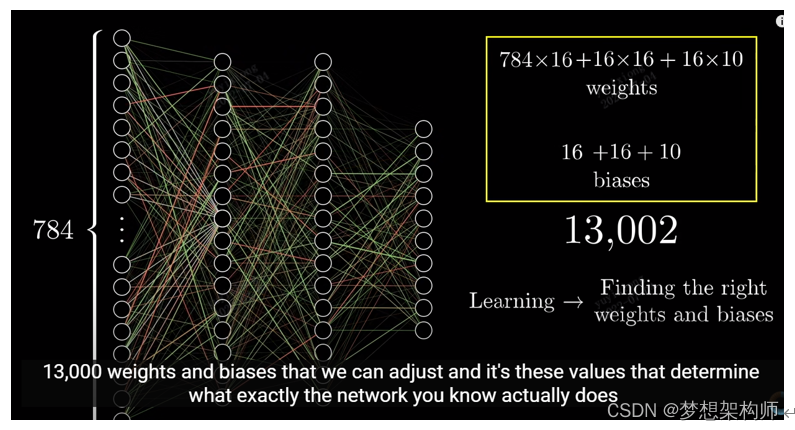
全链路隐藏层
将扁平化处理后的数据,输入到全连接网络层,输出结果,如下图所示:
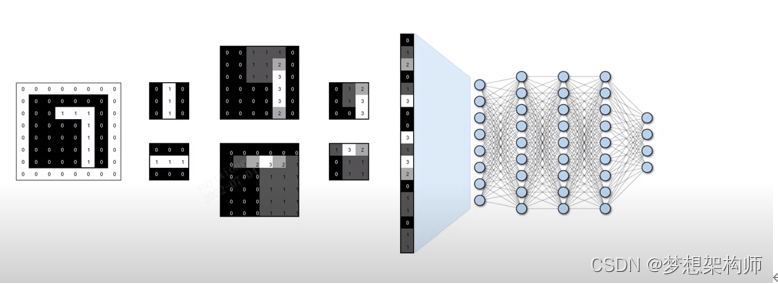
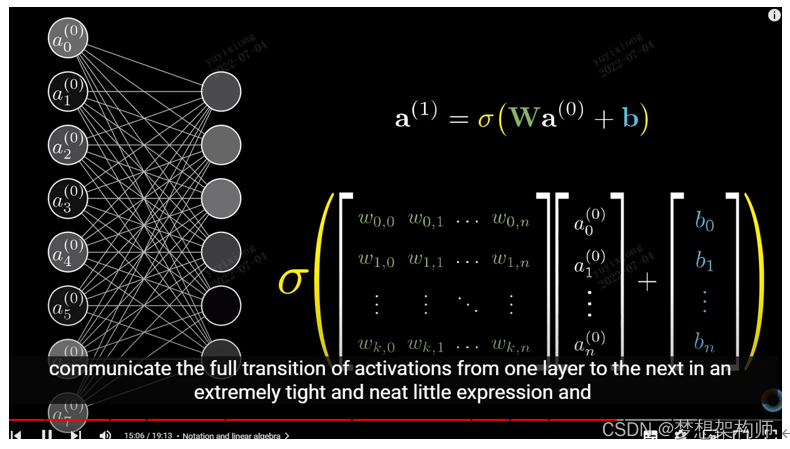
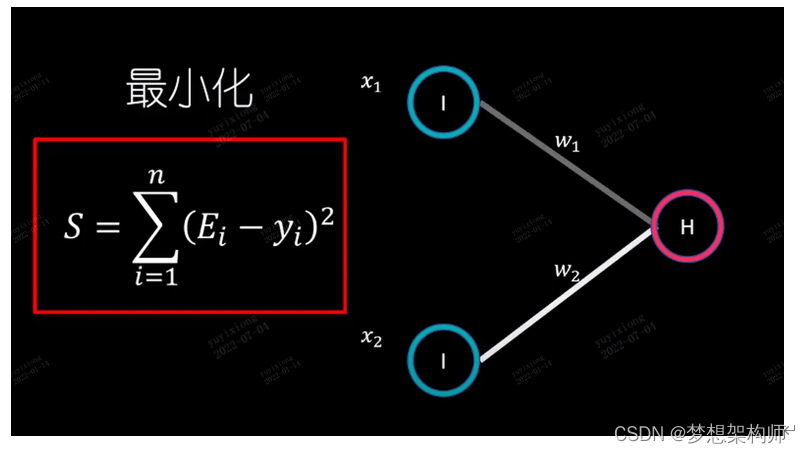
全链接隐藏层输入的是图像中所有的明显特征(特征数据),训练时,根据已标注的结果,训练出具有一定规律的数据关系,方式就是通过多层卷积计算,动态调整卷积核(通过梯度下降算法来动态调整,使调整的权重矩阵更加逼近事实),计算出所有同类图像中的共同特征,学习的过程就是对每张图片的特征进行权重计算, 通过大量的同类样品,算出各个特征的权重,
卷积核
卷积操作通过卷积核是可以分别提取到图片的特征的,但是如何提前知道卷积核呢?像上文的例子,很容易可以找到3个卷积核,但是假如是人脸识别这样成千上万个特征的图片,就没办法提前知道什么是合适的卷积核。其实也没必要知道,因为选择什么样的卷积核,完全可以通过训练不断优化。初始时只需要随机设置一些卷积核,通过训练,模型其实自己可以学习到合适的卷积核,这也是卷积神经网络模型强大的地方

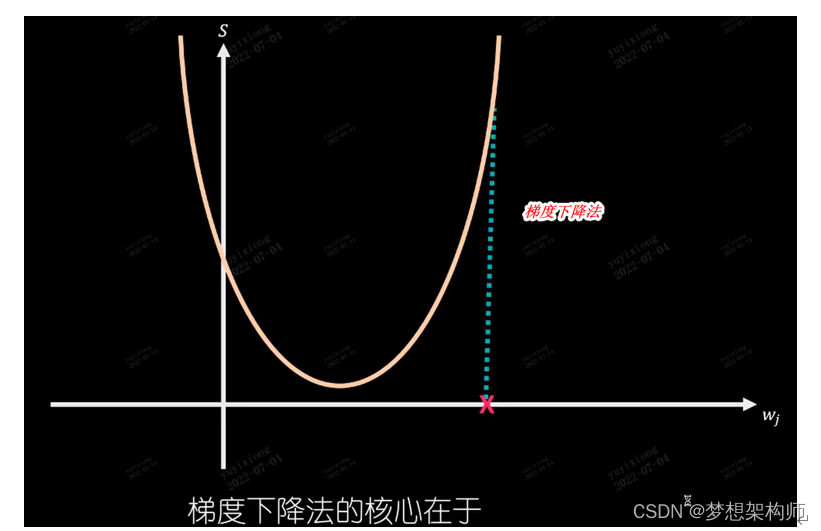
梯度下降算法
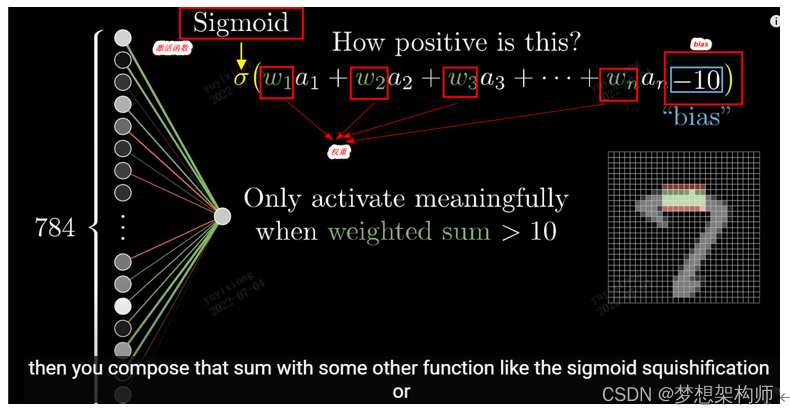
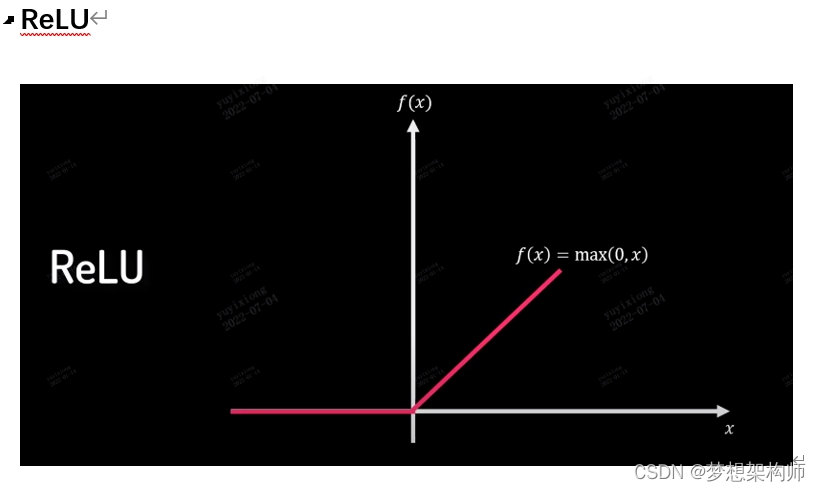
激活函数
Steps of Machine Learning