前言
昨天的R-GCN是对GCN的一种改进,因为考虑了关系,那么今天的GAT也是对GCN的一种改进,就算使用注意力机制来确定每个节点更新特征时,邻居节点传来的特征的比例,就相当于使用注意力机制来计算特征权重,而不是GCN简单通过度来计算特征权重。
GAT
如果知道注意力机制应该会比较快理解GAT,目前注意力机制很常见,LSTM、CNN加上注意力机制一般效果都会提升,Transformer就是一个完完全全的多头自注意力机制架构并且再NLP和CV领域取得非常好的效果,放在图神经网络中同样也能够取得比较好的效果。
传播公式
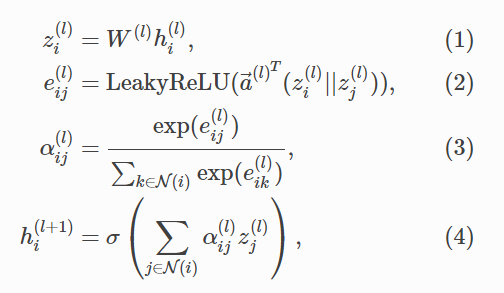
其中
hi(l)是当前节点的特征,hi(l+1) 是节点更新后的特征。
W(l)是转换特征维度的一个共享参数,能够用来学习
zi(l) 则是线性变换之后的特征
LeakyReLU()是一个激活函数
||是两个矩阵拼接的意思
a
?
\vec{a}
a(l)T 也是一个共享参数,能够使得
a
?
\vec{a}
a(l)T(zi(l) ||zj(l))算出来最终得出一个数值即eij(l)
然后eij(l) 经过softmax也就是公式3,能够得出对应的节点特征的权重αij(l)
最后权重 * 转换后的特征值再经过激活函数就得到了更新之后的节点特征值了。
其实基本套路是一样的,就算根据两两特征比较先算出类似一个相似度的值(eij(l)),然后因为数值本身其实并不能代表什么,还需要通过比较来得出这个值的实际意义,经过softmax就能够很好的将这个值进行比较转换为一个权重了,得到了权重之后,那么特征该取多少过来更新节点就明白了。
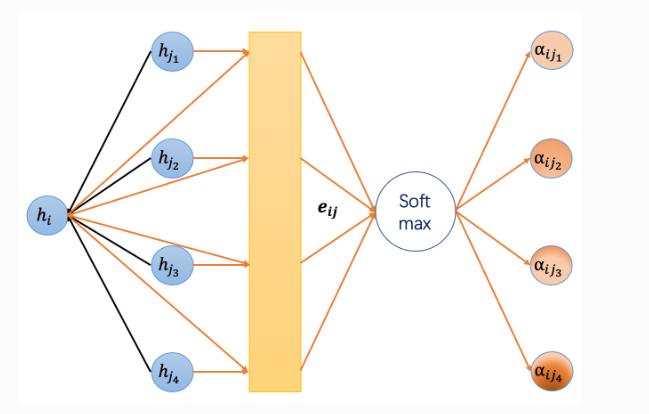
计算权重的过程就如上图所示,来自DGL官网,还是比较清晰明了的。
多头注意力机制
GAT中为了使得模型更加稳定,融入也融入了多头注意力机制,实验证明确实有不错的效果。
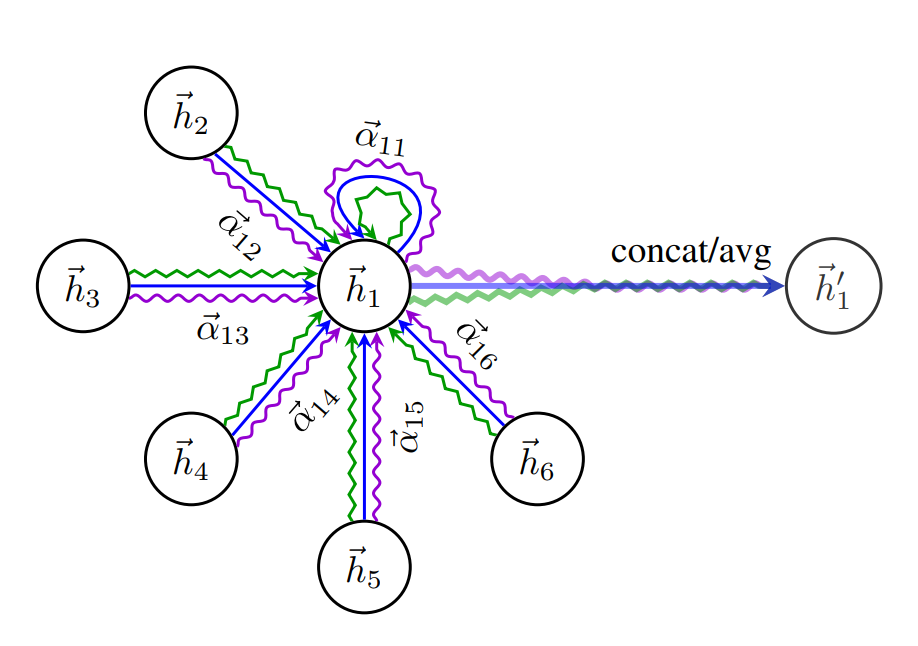
如图,这就是多头注意力机制的示意图。
原文中的公式以及解释如下:

最后就是通过拼接的方式来表示最终的特征。
可能一眼会看不懂,可能一眼就看懂了。
看不懂没关系,我们可以回到上面的传播公式,看看里面有哪几个参数需要学习:
一套注意力机制需要学习的参数有W、
a
?
\vec{a}
a ,虽然公式看起来好像很多,但是需要学习的好像只有两个。
那么如果是多头注意力机制的话,就是有三套W和 a ? \vec{a} a,能够分别计算出三个更新之后的特征,假设我们计算hi1(l+1),hi2(l+1) ,hi3(l+1) ,那么此时获得最终节点的更新特征就为它们拼接后的结果,即hi1(l+1)||hi2(l+1) ||hi3(l+1) = h ? \vec{h} hi’ ,这样应该就很好懂了。
当然论文中还提到,如果直接用注意力层来做分类的话,直接求平均再接个softmax什么的会比较好。

DGL中的GAT实例
DGL官网给的例子是一个分类任务,因此他就是最后取平均接softmax分类,只不过他没算准确率,可能看不太出效果,就这样吧,千言万语都在注释里了,能跑通就行了。
from dgl.nn.pytorch import GATConv
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义GAT神经层
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
# 数据
self.g = g
# 对应公式中1的 W,用于特征的线性变换
self.fc = nn.Linear(in_dim, out_dim, bias=False)
# 对应公式2中的 a, 输入拼接的zi和zj(2 * out_dim),输出eij(一个数值)
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
# 初始化参数
self.reset_parameters()
def reset_parameters(self):
# 随机初始化需要学习的参数
gain = nn.init.calculate_gain('relu')
nn.init.xavier_normal_(self.fc.weight, gain=gain)
nn.init.xavier_normal_(self.attn_fc.weight, gain=gain)
def edge_attention(self, edges):
# 对应公式2中的拼接操作,即zi || zj
z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
# 拼接之后对应公式2中激活函数里的计算操作,即a(zi || zj)
a = self.attn_fc(z2)
# 算出来的值经过leakyReLU激活得到eij,保存在e变量中
return {'e': F.leaky_relu(a)}
def message_func(self, edges):
# 汇聚信息,传递之前计算好的z(对应节点的特征) 和 e
return {'z': edges.src['z'], 'e': edges.data['e']}
def reduce_func(self, nodes):
# 对应公式3,eij们经过softmax即可得到特征的权重αij
alpha = F.softmax(nodes.mailbox['e'], dim=1)
# 计算出权重之后即可通过 权重αij * 变换后的特征zj 求和计算出节点更新后的特征
# 不过激活函数并不在这里,代码后面有用到ELU激活函数
h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
return {'h': h}
# 正向传播方式
def forward(self, h):
# 对应公式1,先转换特征
z = self.fc(h)
# 将转换好的特征保存在z
self.g.ndata['z'] = z
# 对应公式2,得出e
self.g.apply_edges(self.edge_attention)
# 对应公式3、4计算出注意力权重α并且得出最后的hi
self.g.update_all(self.message_func, self.reduce_func)
# 返回并清除hi
return self.g.ndata.pop('h')
# 定义多头注意力机制的GAT层
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
super(MultiHeadGATLayer, self).__init__()
# 多头注意力机制的头数(注意力机制的数量)
self.heads = nn.ModuleList()
# 添加对应的注意力机制层,即GAT神经层
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge # 使用拼接的方法,否则取平均
def forward(self, h):
# 获取每套注意力机制得到的hi
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == 'cat':
# 每套的hi拼接
return torch.cat(head_outs, dim=1)
else:
# 所有的hi对应元素求平均
return torch.mean(torch.stack(head_outs))
# 定义GAT模型
class GAT(nn.Module):
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
# 这里需要注意的是,因为第一层多头注意力机制层layer1选择的是拼接
# 那么传入第二层的参数应该是第一层的 输出维度 * 头数
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h)
# ELU激活函数
h = F.elu(h)
h = self.layer2(h)
return h
from dgl import DGLGraph
from dgl.data import citation_graph as citegrh
import networkx as nx
# 加载数据
def load_cora_data():
data = citegrh.load_cora()
# 节点的特征
features = torch.FloatTensor(data.features)
# 节点的标签
labels = torch.LongTensor(data.labels)
# mask
mask = torch.BoolTensor(data.train_mask)
# 数据
g = DGLGraph(data.graph)
print(data)
return g, features, labels, mask
import time
import numpy as np
g, features, labels, mask = load_cora_data()
# 创建模型,有两个头,隐藏层神经元为8个,输出为7类,因为是分类任务
# 直接用求平均然后接softmax得出分类结果
net = GAT(g,
in_dim=features.size()[1],
hidden_dim=8,
out_dim=7,
num_heads=2)
# 创建优化器
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
# 训练
dur = []
for epoch in range(30):
if epoch >= 3:
t0 = time.time()
print(features.shape)
logits = net(features)
print(logits.shape)
logp = F.log_softmax(logits, 1)
loss = F.nll_loss(logp[mask], labels[mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch >= 3:
dur.append(time.time() - t0)
print("Epoch {:05d} | Loss {:.4f} | Time(s) {:.4f}".format(
epoch, loss.item(), np.mean(dur)))
运行结果:
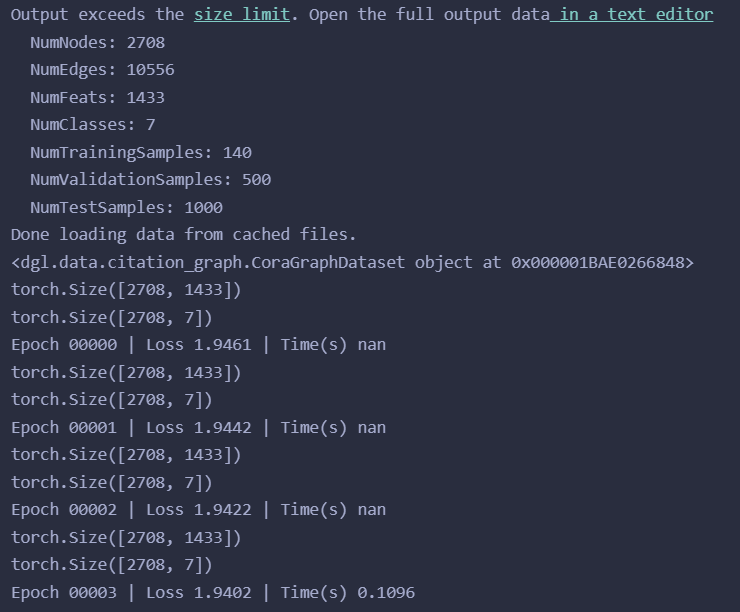
这个模型的代码还是比较好理解的,可以看到模型的损失在下降,模型有效!
参考
https://docs.dgl.ai/tutorials/models/1_gnn/9_gat.html#sphx-glr-tutorials-models-1-gnn-9-gat-py