
老早就想看了,何凯明大神今年的作品,看这阵容,已经迫不及待了。
- 主要是提出了一种自监督训练的方法和一个适用于这种方法训练的不对称Encoder-decoder网络结构:

- 这种训练方法能加快训练,同时提高了网络的泛化性。
- 其实masked autoencoder早就在NLP的BERT和GPT取得成功,在CV领域也有人尝试然而并没有NLP中那么好的效果,那么为什么这个机制在NLP中 work 而在CV中 wor 得并不是很 k 呢,大神提出了疑问,并给出了回答。
- 网络结构不同。适用矩阵数据的卷积没有办法使用"indicator"这种t适用于token序列数据的机制。然而最近ViT的结构已经不存在这样的问题了。
- 信息密度不同。语言是人类创造的符号,具有高度的语义性和信息密集性。而图像是自然符号,具有高度的空间冗余。因此,当句子中的单词丢失时,为了复原出单词,模型必须学得复杂的语义理解;而图像块丢失时,模型可以简单地从相邻图像块借鉴,而只需要简单地了解部分与整体、目标与背景、景色风格即可。为了解决这个问题,很简单,mask掉大部分的patch,只留下一小部分,如下图,这样就足够逼迫模型去学得复杂的理解:

- decoder预测的对象不同。NLP的decoder需要预测单词,这是高度语义化的;而CV的decoder只需要预测图像,这甚至比CV的其它高层视觉任务如识别等具有更弱的语义性。解决方法是为CV设计特别的decoder。BERT的decoder可以随便,比如一层全连接,对性能的影响并不大,但CV的decoder对学得特征的语义性特别重要。
- 非对称encoder-decoder:文章设计了一个轻量的decoder,并且把mask token部分交由decoder来处理,而encoder只需要处理没有被mask掉的patch(25%),从而极大地降低了encoder的参数量,从而预训练特别快,内存消耗也更小,从而可以使用更大的encoder模型,得到更高的性能。
- encoder就是正常的ViT,带正常的position embedding,但是删掉了75%的随机token。
- decoder的输入是encoder输出的token,而mask掉的patch用可学习的token代替,这些patch用的是共享参数的token。此外还需要为这些token(encoder的输出以及mask掉的token)加上position embedding。decoder的结构用了不到encoder 10%的参数量,是很小的结构,decoder的最后一层是一个全连接层,把每个token的size映射为拉长的patch size,reshape后直接就是复原的图片。loss的计算仅对mask掉的pathc做,就是和原图片做MSE损失。decoder仅在预训练的时候用到,训练完只取encoder即可。
- 文中提到了 linear probing 和 finetuning 两种结果,其中 linear probing 是指只训练最后一层,fine-tuning是指全部训练。值得注意的是,即使用这种方法预训练后采用linear probing训练最后一层,仍然能在图像分类测试集上达到73.5%的准确率。
- 如果是finetuning,decoder的深度从1到8对最终的测试集准确率没有太大影响,但如果是linear probing,深的decoder能带来更好的效果,这是因为decoder越深,预训练的时候encoder输出的embedding离最后的输出的图像就越远,这些embedding就越语义化和抽象化,而更加抽象的语义更适合作为在linear probing的时候最后一层linear的输入,因为最终输出的是分类值。
- 是否进行数据增强影响也不大,最好的效果是随机size的随机剪切,比什么都不增强提高了0.9%的准确率(其实说大也大,因为比其它的方法大概也就是高1%到3%的准确率)。
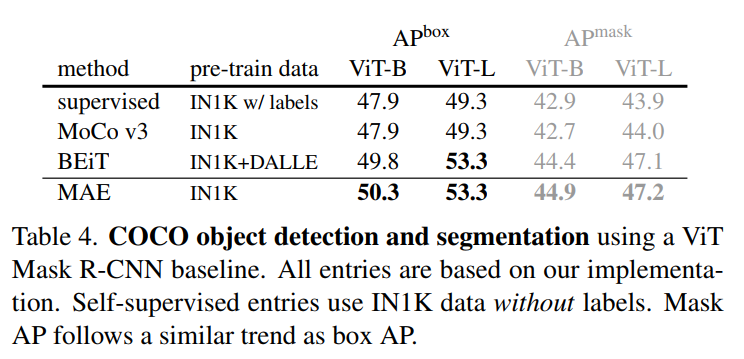
- 在目标检测、图像分类、实例分割等任务上,使用本文的方法预训练的模型都具有性能上的提高:

- 此外还提到了文章中的不足之处,图像生成任务会反映数据中的偏见,其中一些包含负面影响;模型会生成不存在的内容,等问题
总结
- 使用这种方式预训练的encoder迁移到图像分类、目标检测、语义分割、实例分割等任务上都取得了比有监督方法预训练更好的效果,并且具有更好的泛化性。这具有很重大的意义。之前的几乎所有用在高层视觉任务上的transformer,都是要预训练的。transformer特别容易过拟合。所以transformer用到计算机视觉的高级任务上,比如分类、目标检测什么的。都会先在ImageNet上做大规模的预训练。这些模型如果你想在自己的数据集上训练,不load预训练的参数效果会比较差。现在相当于,所有的模型有了个更好的预训练的方式。都不用改什么,只是把预训练的权重换成它预训练的权重,重新训练一遍,就能有效果上的提升。而且原先在ImageNet上预训练,是分类任务的。而本文完全自监督,不需要label。由于特殊的设计,预训练的速度更快,内存消耗也更小。一篇工作能提高许多领域的SOTA,只能说,不愧是大神。