文章目录
前言
提示:这里可以添加本文要记录的大概内容:
在目前的自然语言处理中,如何应用transformer?我们一般将应用分为两部分:上游任务和下游任务。
- 上游任务一般是指训练一个预训练模型。
- 下游任务一般是指在自然语言处理中实际完成的任务:情感分析,文本分类,机器翻译等。
比如一个刚入学的学生我们想把他培养成作家,我们不能直接教他写作,而是要先教他识字。
一、transformer模型的直觉,建立直观认识;
transformer与lstm的区别:lstm是迭代的,是类似于一个for循环的过程,每一个字必须等上一个字计算完毕后才能进行当前字的计算,而transformer的计算是并行的,可以同时处理一个句子中的所有字,从而大大提高了运算效率。
那么,transformer是如何知道句子中字的前后顺序的呢.?(transformer不像lstm,天生具有时间的先后顺序)原论文中引入了位置编码,通过位置嵌入使模型获得时间序列的关系。
transfomer是一种编码器-解码器的结构。
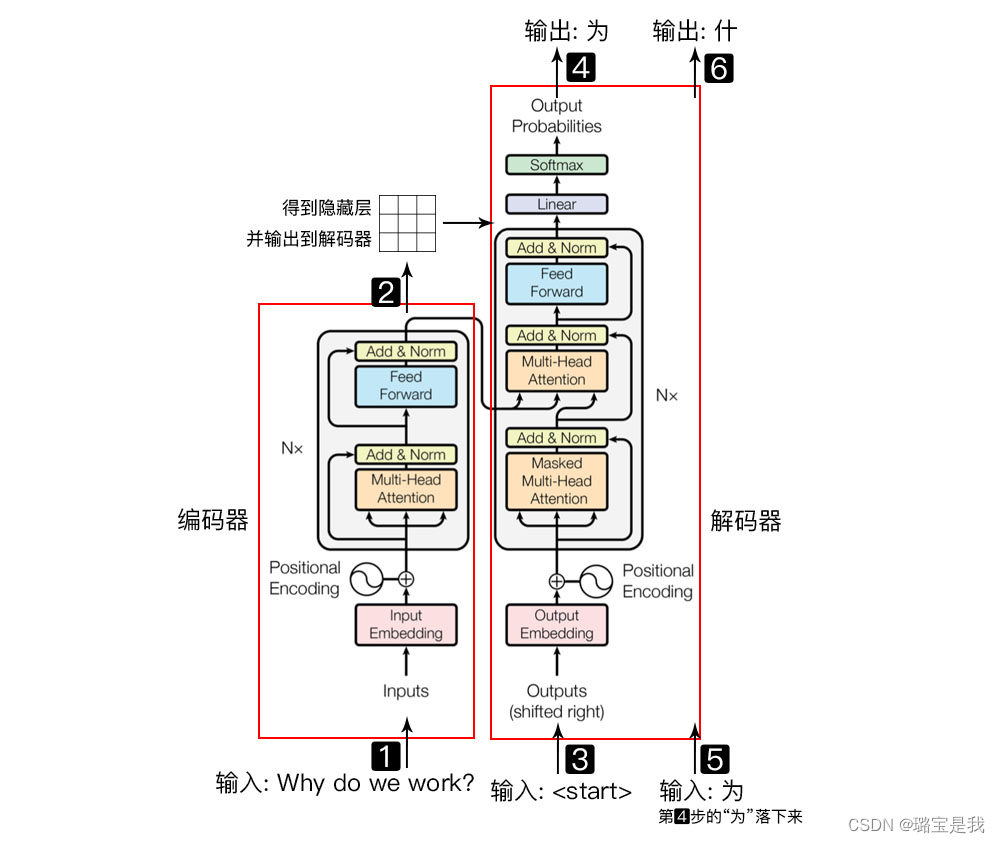
自然语言序列通过编码器,获得隐藏层,把隐藏层输出到解码器,如上图所示。
bert的预训练模型只用到了编码器的部分,也就是先用编码器训练一个语言模型,然后在把他适配给其他五花八门的任务。
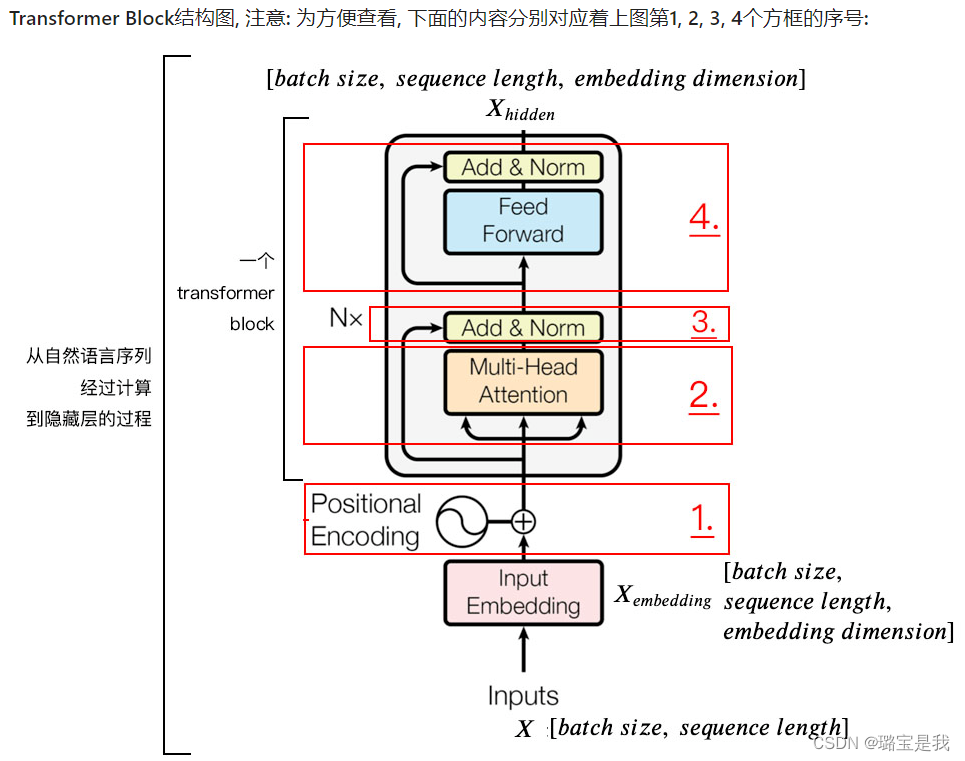
- batch_size:句子个数,因为我们通常要一次性计算很多个句子。
- sequence_length:句子的长度
首先在input embedding层中,从词向量表中找到对应字的词向量表达,每一个向量的维度为embedding dimension。X_embedding也称为字嵌入的维度。
1.positional encoding位置嵌入
位置嵌入的维度为[max_sequence_length,embedding dimension]嵌入的维度同词向量的维度。

如果词向量维度为256,那么i的取值为0~255;d_model即为256.
2.self attention mechanism自注意力机制
我们现在有了词向量矩阵和位置嵌入矩阵,假如我们现在有一些句子X,X的维度是[batch_size, sequence_length] 首先我们在词向量表中查询到相应位置的嵌入,然后与位置嵌入相加,得到最终embedding的维度是:[batch_size, sequence_length, embedding_dimension]之后我们对得到的字向量矩阵X_embedding做三次线性映射,也就是分配三个权重WQ,WK,WV,他们的维度均为[embedding_dimension,embedding_dimension]线性映射后得到三个矩阵QKV,和线性变换之前的字向量矩阵是相同的。
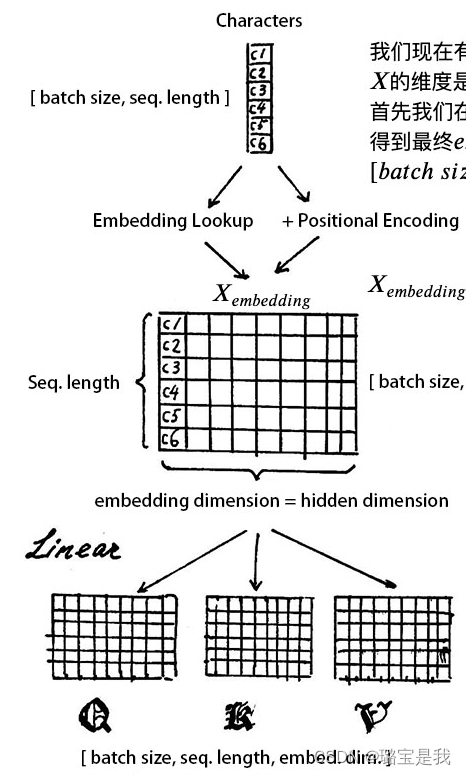
然后我们准备进行多头注意力机制。首先定义一个超参数h也就是head的数量。
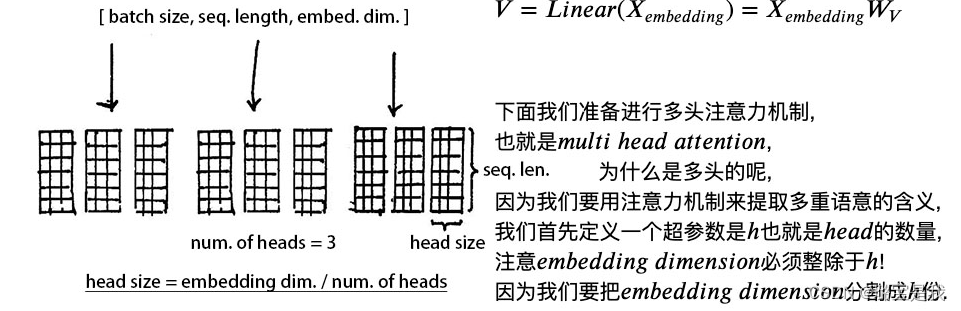
注意embedding_dimension必须整除于h,因为我们要把embedding_dimension分为h份。
分割之后的QKV的维度为[batch_size, sequence_length, h, embedding_dimension/h]
之后我们把QKV的维度进行一下转置,为了方便后续的计算,转置之后的QKV维度为:[batch_size, h, sequence_length, embedding_dimension/h]
我们用一组heads,也就是一组分割后的QKV,他们的维度都是[sequence_length, dimension/h]
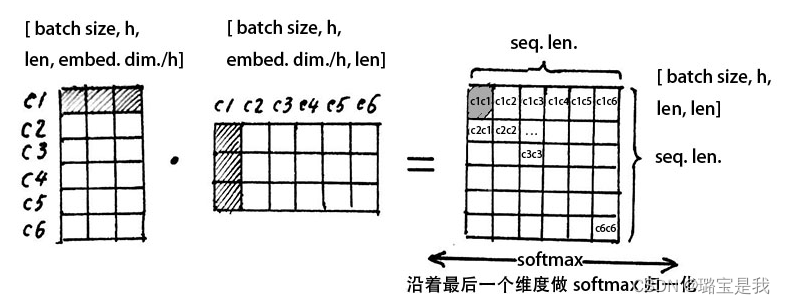
我们首先用代表第一个字的c1行与c1列相乘,得到一个数值,也就是位于注意力机制矩阵第一行第一列的c1c1,这里的含义是指第一个字与第一个字的注意力机制,然后以此向后求得c1c3,c1c3…
注意力矩阵的第一行就是指第一个字与这六个字的哪几个比较相关,下面同理。
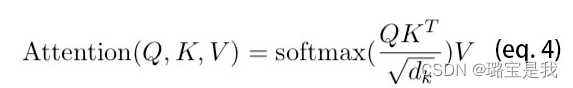
我们得到注意力矩阵后,使用softmax归一化,使每个字跟其他所有字的注意力权重的和为1,注意力矩阵的作用就是一个注意力权重的概率分布,我们要用注意力矩阵的权重给V进行加权。
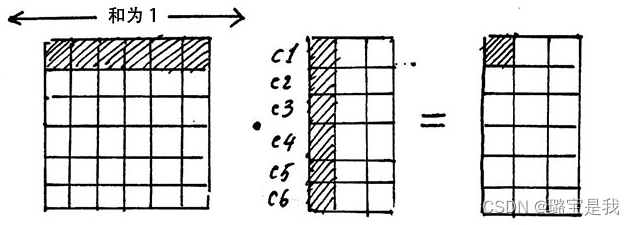
矩阵V的每一行代表着每个字向量的数学表达。我们上面的操作正是用注意力权重进行这些数学表达的加权线性组合,从而使每个字向量都含有当前句子内所有字向量的信息,进行点积运算之后,V的维度没有变化。
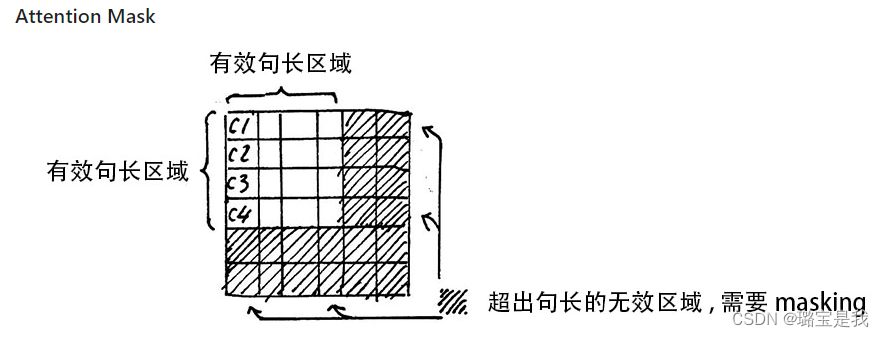
3.add&norm

二、总结
1.整体流程
2.小结
通过对transformer编码器的整体理解,有助于我们对模型进行预训练以及完成各种下游任务,比如情感分类或者文本分类,经过自注意力机制,一句话中每个字都含有这句话中其他所有字的信息,那么我们就可以添加一个特殊的字符到句子最前面,然后这样这句话中的所有信息都可以向这个特殊字符的维度进行汇总,之后我们只要取出这个特殊字符对应的维度,我们就可以得到这一句话的完整表达,相当于一句话用一个向量来表达,之后再将这个向量映射成分类。