基于深度学习的语音活动检
语音活动检测
????能看到我这篇博客的同志们想必就是冲着用深度学习的方法来实现语音活动检测这一项任务来的。这里就不过多解释有关语音活动检测的概念了,下面简单的说一下概念以及比较有名的一些检测方法,重点还是方法项目实践上。
背景
????语音活动检测指的是在存有噪音信号的情况下,能够正确找出音频说话的开 始与终止位置的一项技术。在日常生活中并不是所有的声音信号都是“干净”的, 通常来说,一段经典语音中的有声部分和无声部分比例约为 4:6。在使用音频 数据时,有近一半的语音信号实际上对人们来说都是无用的,使用语音活动检测 技术,对待使用的语音信号进行预先处理,找出其语音部分的位置,再利用相关 的语音分离手段,提取出“干净”的语音信号供我们后续使用。这样做,不仅能 有效提高信道利用率,同时对语音增强、语音识别、语音编码等技术具有重 要作用。
????起初,由于硬件条件的限制,使得通信信号传输效率很低,一段传输信号中,绝大部分的信号对人们来说是无用的,假设信道传输的信号都是人们想要的,这样的传输效率会提高很多。于是乎,语音活动检测就诞生了,目的就是识别并去除语音信号中非语音那一部分对资源的占用。后来,硬件水平大幅提升,语音信号中非语音部分对信道资源的占用已经几乎可以忽略不及了,但这时候,语音识别,语音增强等等领域的发展使得语音活动检测这一项技术一直没有落伍,反而在不断融合新方法提升效果。
传统检测方法
????传统经典的语音活动检测方法主要包括:
?????1、能量阈值法
?????2、零交叉率法
?????3、最小二乘周期估计法
?????4、几何自适应能量阈值法
?????5、基于统计模型的方法
目前主流检测方法
????目前语音活动检测最流行的方法就是WebRTC提出的vad方法,该方法在信噪比较高的情况下效果非常好,能够很好的区分出语音和非语音,实时性也非常好,但是在信噪比较高的情况下,这种方法效果就大大折扣了,亲身体检,语音中的轻微电流音可能会被误判为语音信号。最近几年流行起来的还有一类方法,就是利用机器学习、深度学习的方法来训练语音活动检测模型,用模型来进行结果预测,这种方法得到的效果很好,而且只要数据集比较好的话,原理上就会解决传统方法在信噪比较低的情况下检测效果不理想的问题,但是这种方法也带来了一个问题 - 实时性可能比较差,不容易做成实时的语音活动检测效果。
项目实践
????最近几年,深度学习非常流行,一般情况下机器学习能做的,深度学习就一定能做,而且最终效果可能也还更好。用深度学习的角度来看,机器学习就相当于浅层神经网络来训练模型,一般的可以看做一两层左右,而深度学习却不一样,他可以有很多层,可根据项目任务的特点来构建适当层数的神经网络,这也就说明,深度学习有着更好的特征提取能力,还有,相对于机器学习来说,深度学习特征提取是全自动的,相当于端到端的那种感觉。(以上都是个人理解,若有错误欢迎指正!)。
????本文使用深度学习的方法来完成语音活动检测任务。主要使用工具及环境如下:
?????1、SAM语料库(电影字幕自动对齐语料库)
?????2、PyTorch深度学习框架
?????3、二维卷积神经网络
?????4、Python及相关计算、绘图库等
?????5、Kaldi开源语音识别工具
?????6、Ubuntu18.04-GPU服务器、Windows10(RTX3060-6G显卡)
获取数据集
????SAM 数据集[8]是南加州大学,信号分析与解释实验室, Krishna Somandepalli 和 Shrikanth Narayanan 两位研究者开源提供的。SAM 数据 集是由 2014 到 2018 年之间 95 部电影中的语音片段组成。SAM 数据集最主要的特点是使用了自动生成字幕的方式,得到了一段对话 的近似还是时间和结束时间的时间戳列表。也正是由于这个特点使得该语料库数据的准确性无法达到非常准确的程度,不过对于实验是够用了。
数据预处理
????由于这里下载的数据是特征数据集,是已经完成数据预处理的语料库。因此不用专门对数据进行预处理了。不过可以说一下对于一般数据来说,我们应该怎么预处理来适应这个模型的训练。
????一、重采样、转格式
??????利用FFmpeg工具将音频文件已16kHz的采样率进行采样,采样完成后,以.wav格式来存储。
????二、分窗、加帧、预加重
??????以0.64s的时间间隔来进行分帧,这样做是便于后续64×64维度的卷积神经网络的输入。
????三、计算能量谱
????四、获得Mel滤波系数
????五、对Mel滤波系数取对数,得到FBank特征。
以上步骤全部利用kaldi工具来完成。

构建神经网络
????根据传统的卷积神经网络原理以及 SAM 数据集特点,构建了本文中的网络结构,如下图:

????主要包括7层卷积,3层最大池化以及1层平均池化,主要使用了relu激活函数以及softmax激活函数,整体如上图所示。利用上述网络来进行模型训练。
???? 前向传播部分代码:
class VADModel(nn.Module):
def __init__(self, ):
super(VADModel, self).__init__()
self.convmpblock1 = ConvMPBlock(num_convs=2,
in_channels=1,
out_channels=32)
self.convmpblock2 = ConvMPBlock(num_convs=2,
in_channels=32,
out_channels=64)
self.convmpblock3 = ConvMPBlock(num_convs=3,
in_channels=64,
out_channels=128)
self.linear = nn.Linear(128, 256)
self.activation = nn.ReLU()
self.gap = nn.AdaptiveAvgPool2d(1)
self.linear_stack = nn.Sequential(nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 2))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.convmpblock1(x) # B, C, H, W
x = self.convmpblock2(x) # B, C, H, W
x = self.convmpblock3(x) # B, C, H, W
x = x.permute(0, 2, 3, 1).contiguous() # B, H, W, C
x = self.activation(self.linear(x)) # B, H, W, C
x = x.permute(0, 3, 1, 2).contiguous() # B, C, H, W
x = self.gap(x) # B, C, 1, 1
x = x.squeeze() # B, C
x = self.linear_stack(x) # B, 2
x = self.softmax(x) # B, 2
return x
训练模型
????训练得过程就不说了,其实差不多每个项目的训练过程都大同小异,最终迭代调优得到一个效果好的权重参数,即模型。
测试预评估模型
????经过个epoch的训练,其中训练损失、验证损失、正确率趋势图如下:
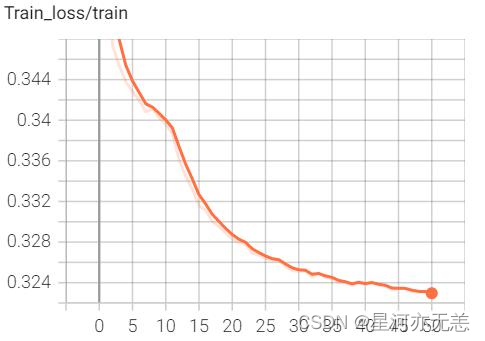
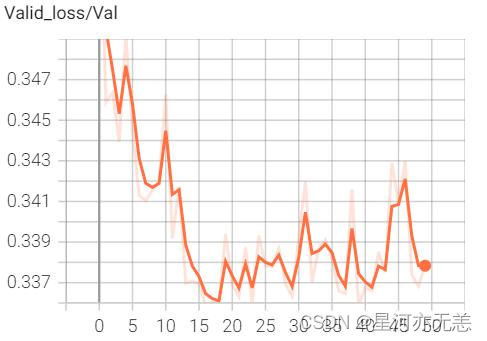
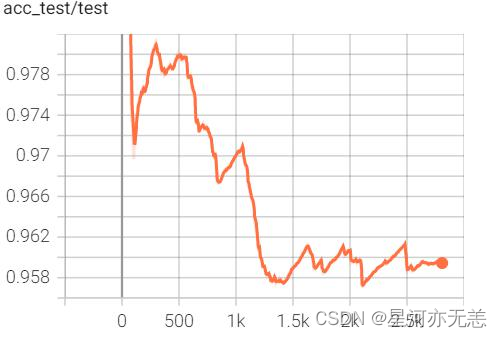
????其中模型评估数据如下:
| Accuracy | Precise | Recall | F1-source |
|---|---|---|---|
| 96.36% | 94.75% | 95.99% | 0.95 |
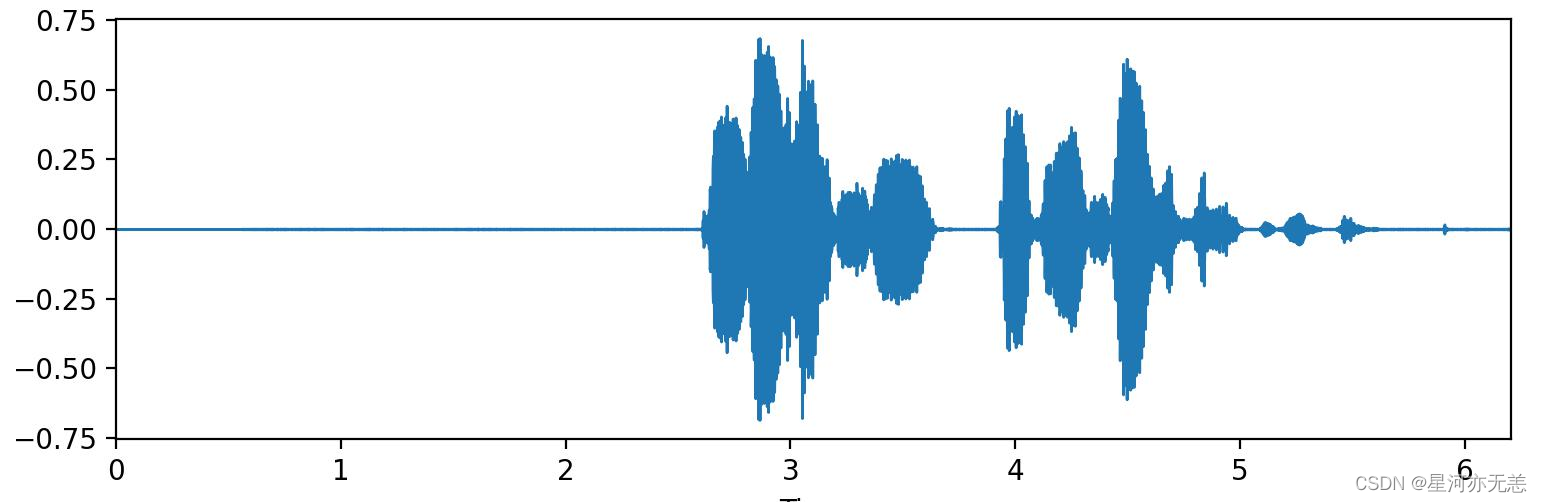
????选取了一段蜘蛛侠3-英雄无归的音频文件进行预测。(选自蜘蛛侠与章鱼博士在桥上对战的片段,以hello,Peter结尾)结果可视化如下图:
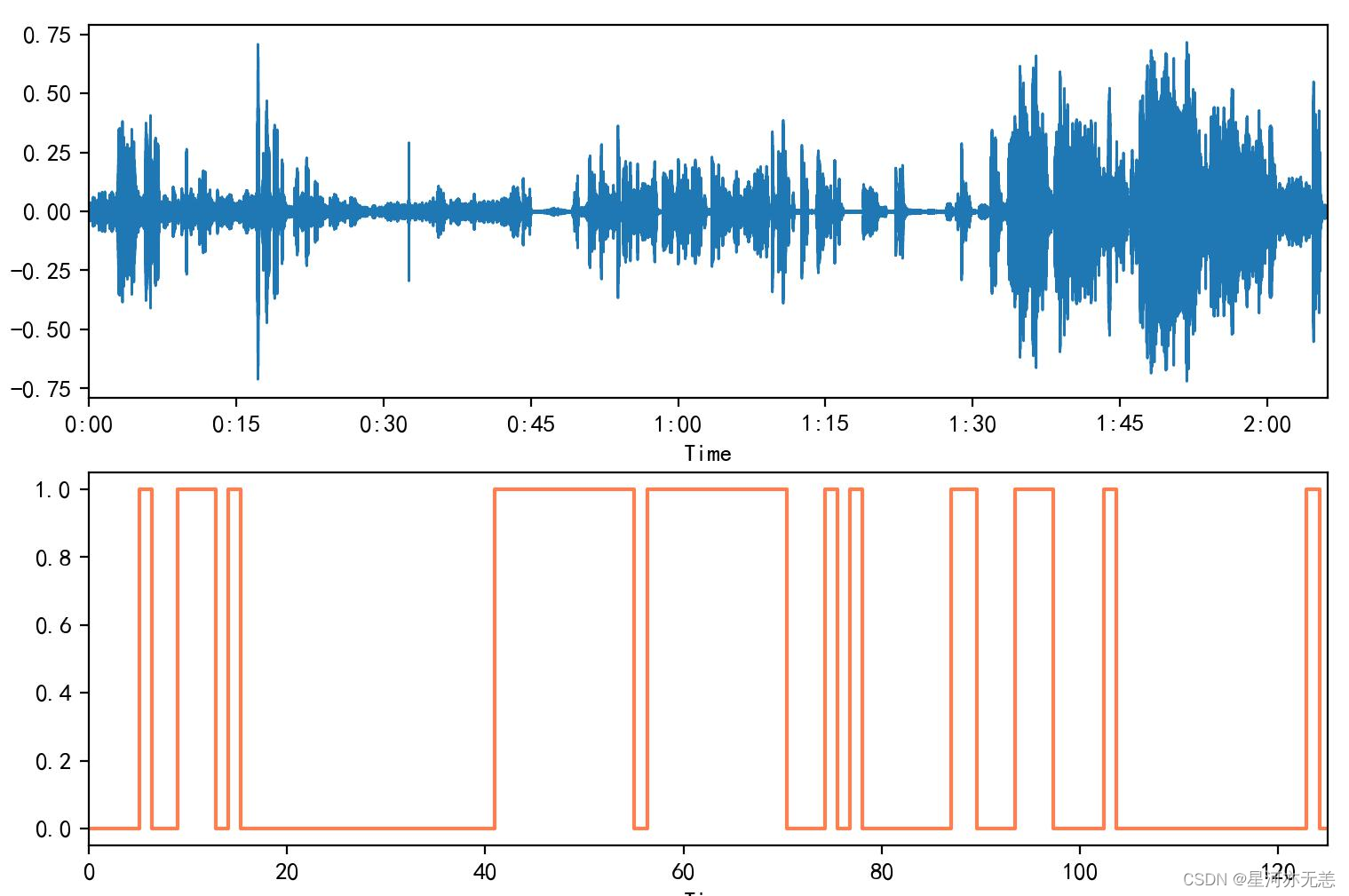
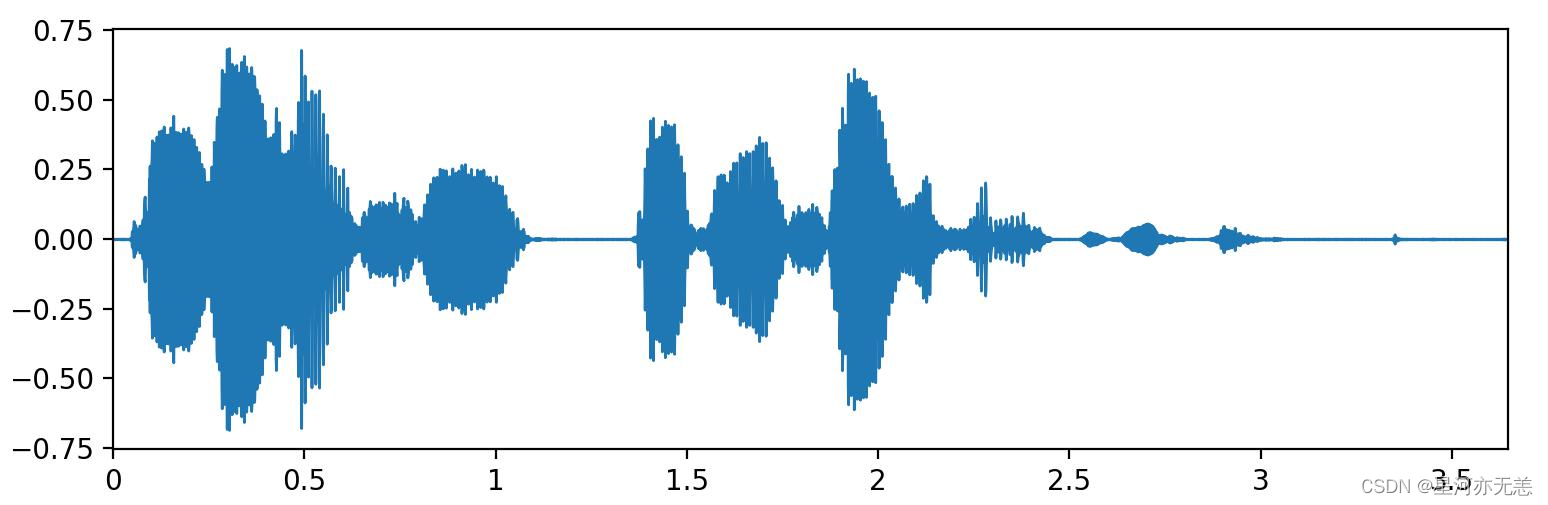
????后续,(为了方便我录制了一小段话,内容是“你好”)我通过预测出来的有效语音时间戳将语音数据提取出来,结果如下图:
总结
????利用深度学习的方法来实现语音活动检测是完全可行的且效果也比较好,经过实验发现,这种方法在低信噪比下效果要远远好于传统的能量阈值的方法,比如上述预测蜘蛛侠语音片段那部分,效果还是可以的。不过存在一个问题就是,模型不算小,预测起来不是很方便,另外一点就是实时性不好,可能还需要优化才能完成实时的语音活动检测。
????这里就简单的介绍了一下我做过得这个项目,没有讲其中的代码,尤其是神经网络构建以及模型训练那一块代码。如果大家有什么问题欢迎留言,同时要是有什么错误,也欢迎大家指正!谢谢!