(1) 用Java语言或其他常用语言实现教材《Introduction to Information Retrieval》第13章中介绍的两种特征选择方法:13.5.1节中描述的基于互信息(Mutual Information)的特征选择方法和13.5.2节中描述的基于X^2的特征选择方法。
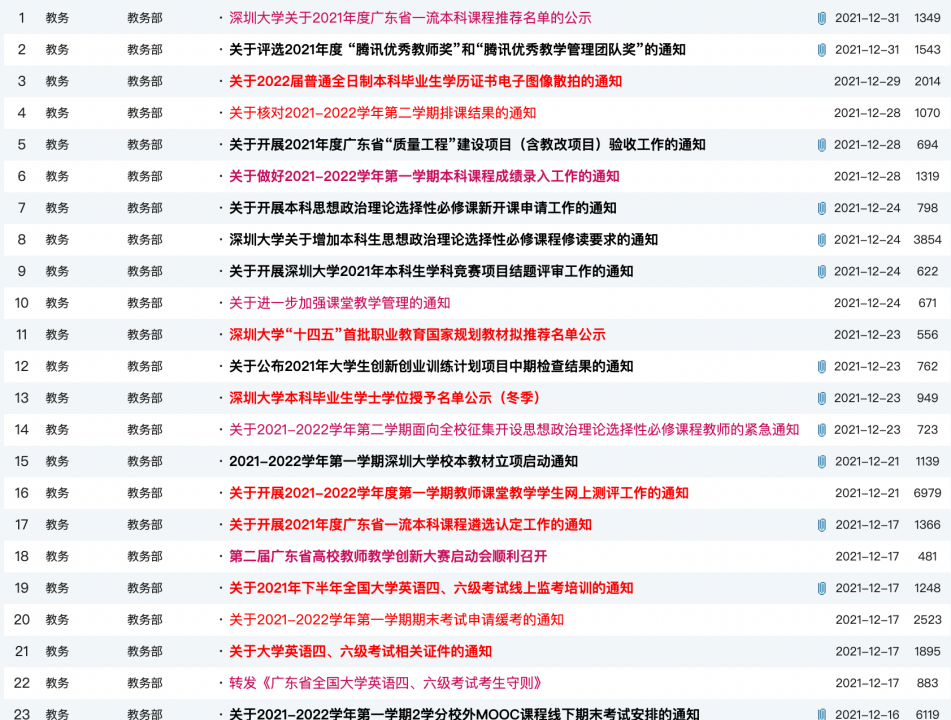
请自行从学校公文通获取2021年的新闻文档(爬取或手动下载),要求包括以下150篇新闻文档:
“党政办公室”发布的最新的30篇新闻文档,
“教务部”发布的最新的30篇新闻文档,
“招生办公室”发布的最新的30篇新闻文档,
“研究生院”发布的最新的30篇新闻文档,
“科学技术部”发布的最新的30篇新闻文档。
将“党政办公室”、“教务部”、“招生办公室”、“研究生院”和“科学技术部”作为5个class,并通过互信息和X^2为每个class选出最相关的15个特征(包含特征名称和相应的值,小数点后保留2位),并对结果作简要分析。
代码截图、运行结果截图和详细的文字说明:
第一步:爬虫
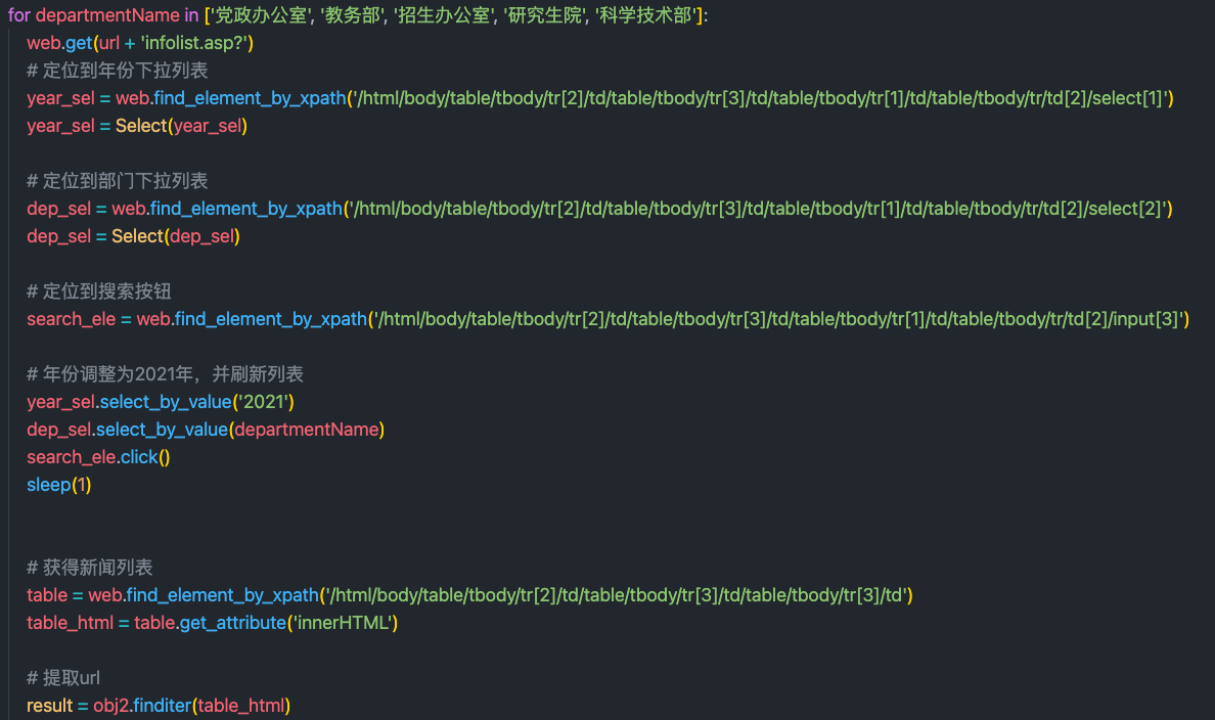
使用python selenium自动化工具从公文通上进行文本的爬取,并且提取正文整理成文件存储。具体实现流程大致为使用chrome自动化工具自动切换至2021年各个部门的界面,然后爬虫获取前30篇新闻的链接并使用定位到相应div进行文本读取。具体实现如下:
自动化页面切换:
获取文本信息:
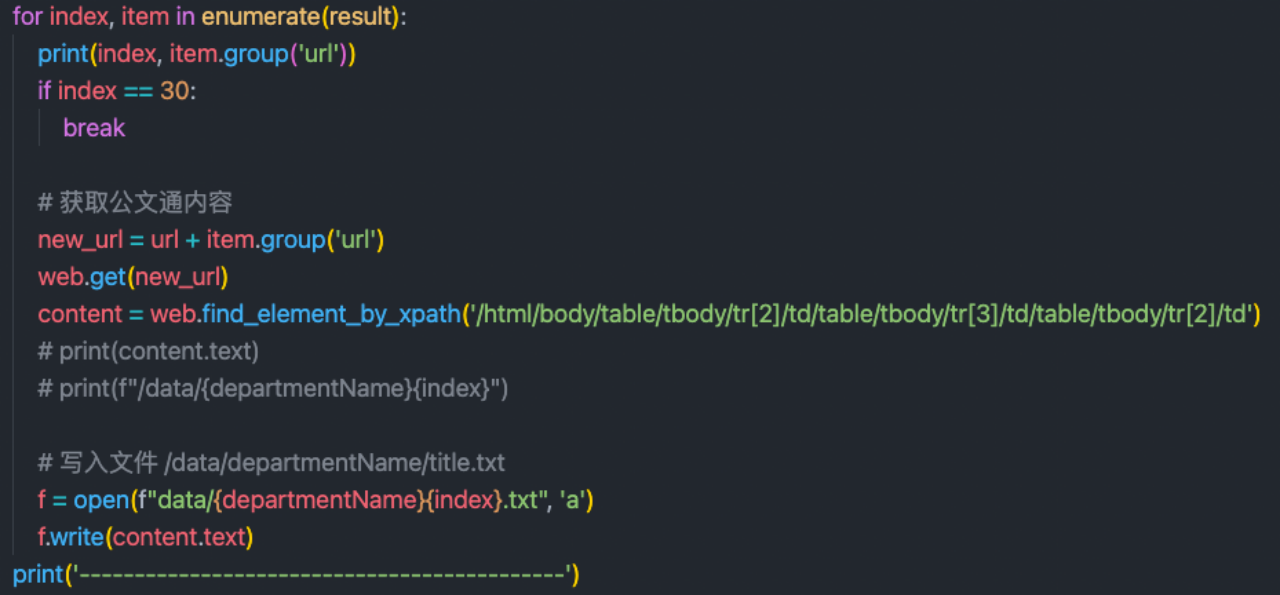
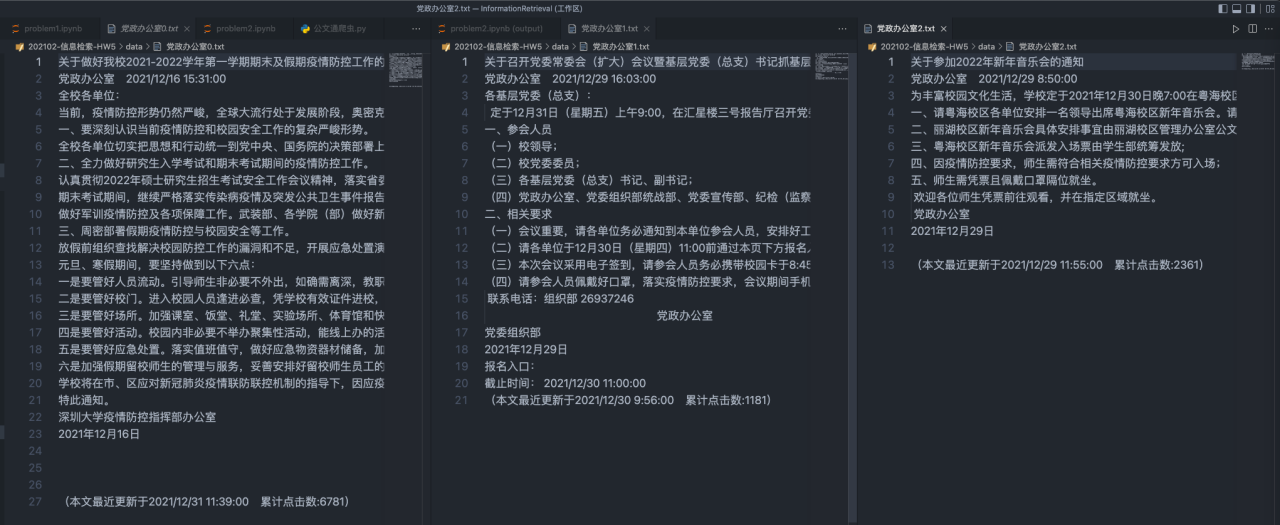
第二步就是进行文本信息处理
1. 读取文档,根据文件名进行分类
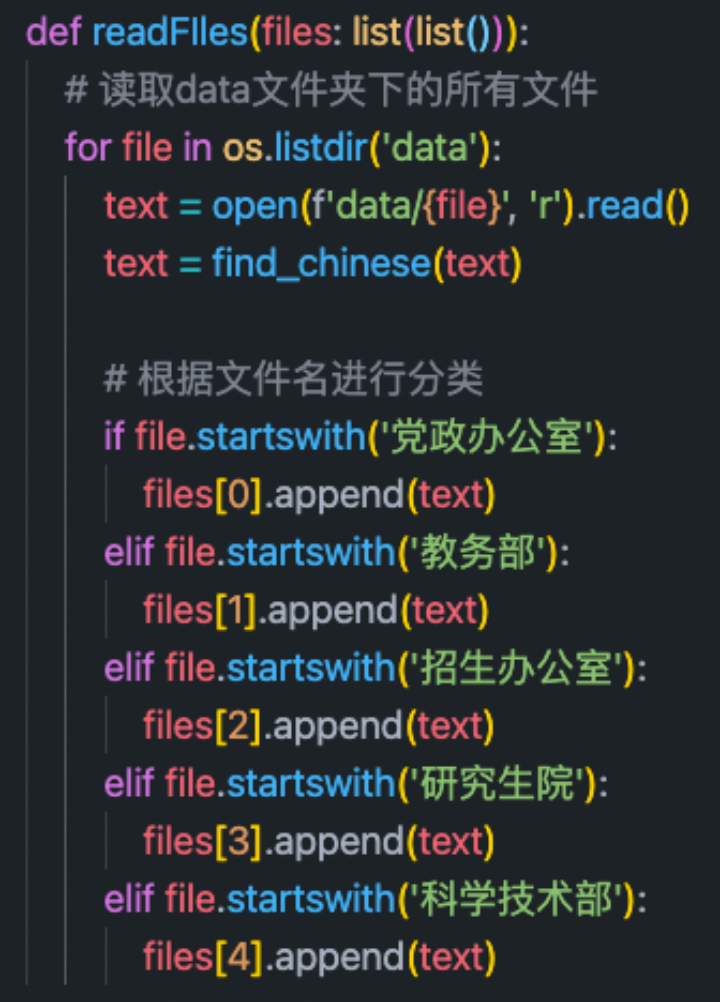
其中file[0-5]依次为五个类别的文章
2.使用jieba进行分词处理,并生成词袋。
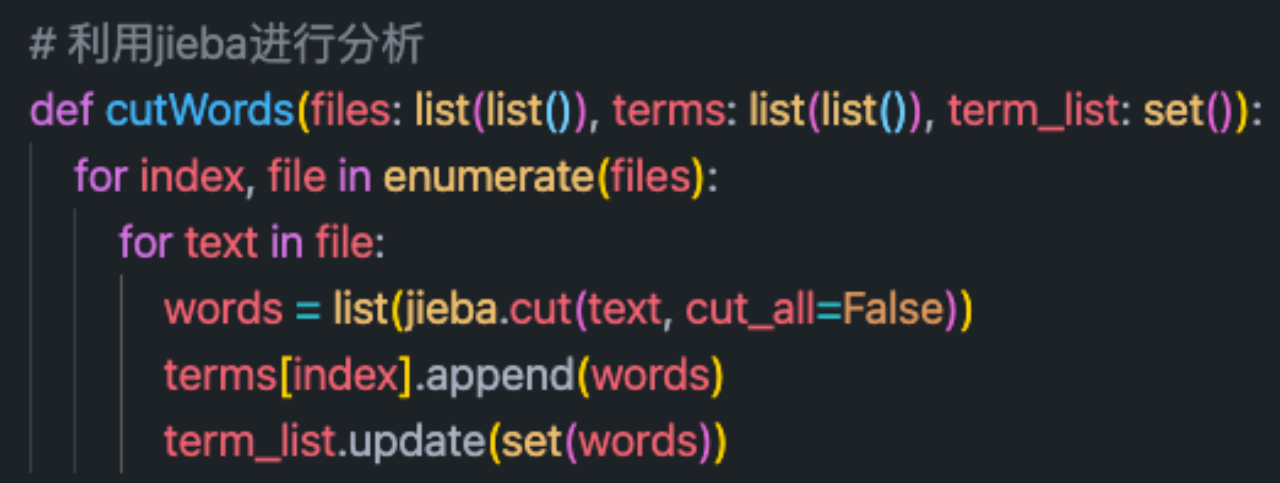
分词结果:
词袋:
注:由于爬虫下来的文章会有\u3000等多余字符,所以需要进行额外处理

第三步是进行特征选择:
MI计算公式如下所示:

所以为了减少重复计算工作,我首先对于每个词项在不同类别中的出现情况进行了统计。对于每个单词,我首先统计成了以下表格形式:
| Word / Category | 出现次数 | 未出现次数 |
|---|---|---|
| Category 1 | 1 | 29 |
| Category 2 | 3 | 27 |
| Category 3 | 5 | 25 |
| Category 4 | 7 | 23 |
| Category 5 | 9 | 21 |

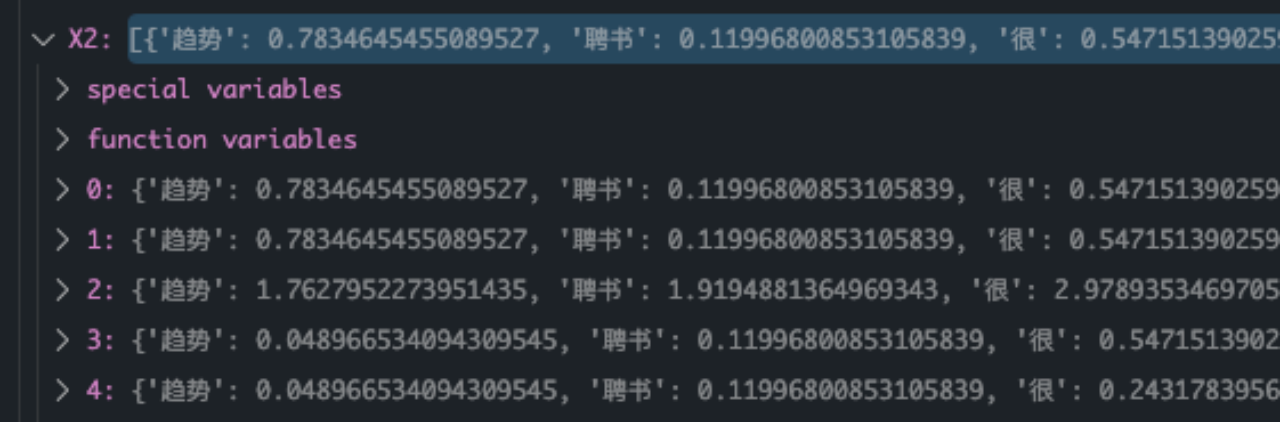
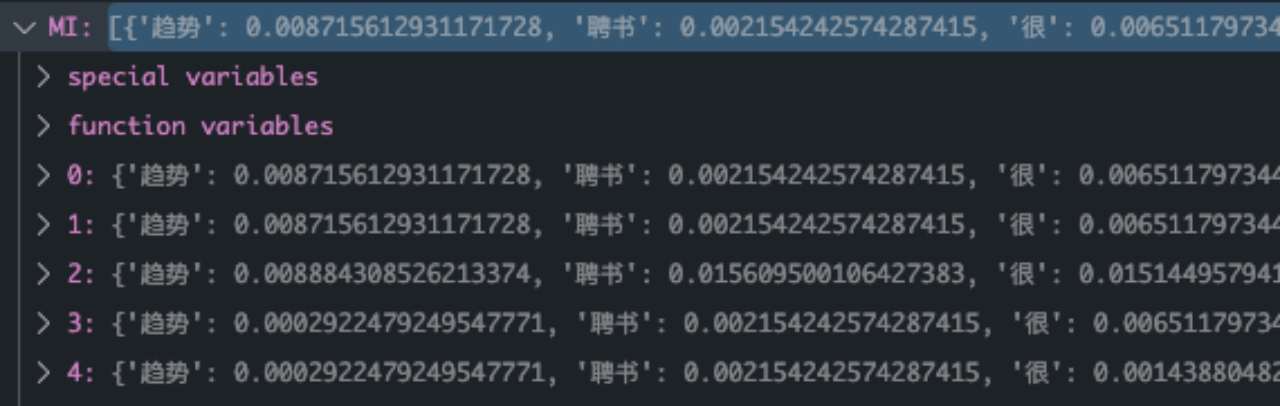
有了以上表格,就可以快速的计算出每个类别下N11,N10,N01,N00的四个值了,并且根据MI,X^2的计算公式得到相应结果



最终计算结果如下所示:
第四步就是进行排序了。
由于题目只需要获得前15大的特征值,因此此处选择了基于小顶堆的TopK算法:
首先编写一个小顶堆重建算法:

然后是TopK排序算法:首先用前K个元素建立小顶堆,如果后续元素大于堆顶元素,则替换,并重建小顶堆。最后使用堆排序算法,对K个元素进行排序。

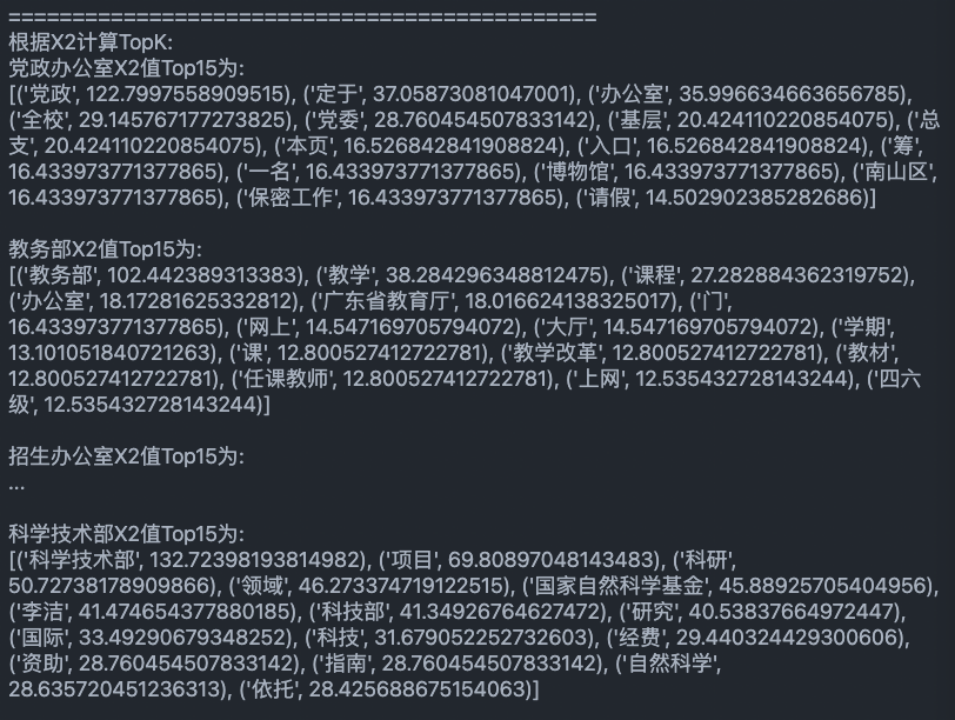
最终得到如下结果:

对使用的中文分词工具作简要介绍:
调用jieba.cut函数进行分词
jieba分词0.4版本以上支持四种分词模式:
1.精确模式:试图将句子最精确地切开,适合文本分析;
2.全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
3.搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
4.paddle模式:利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
可以看出,全模式的切词是最粗糙的,将所有的词汇都进行了返回。主要有以下几个问题:
1.未结合语境,容易有歧义:协同过滤----> 协同+同过+过滤
2.不了解词汇:鲁棒----> 鲁+棒
精确模式与搜索引擎模式可以结合具体需求进行选择。
通过互信息为每个class选出的最相关的15个特征:
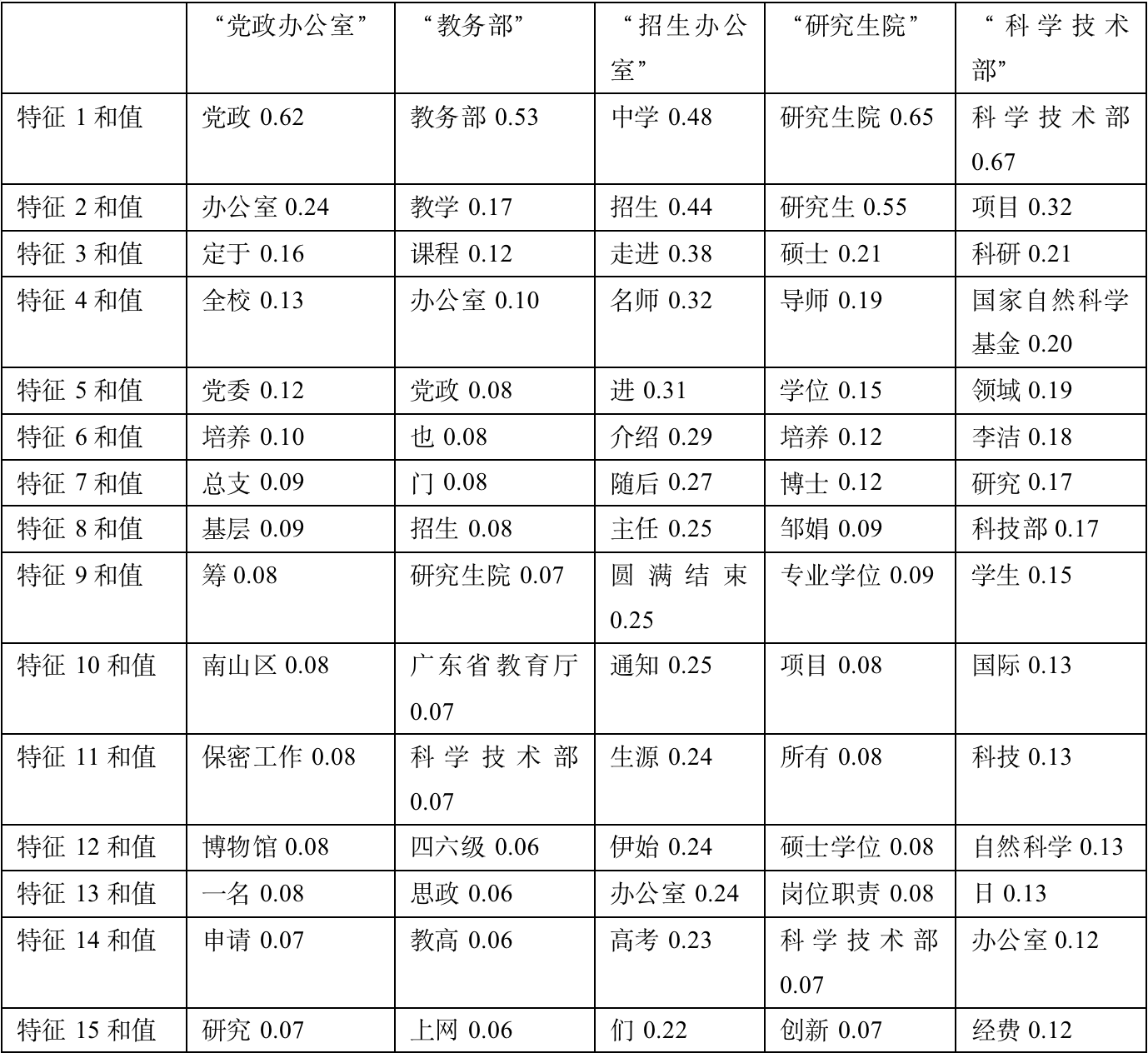
对通过互信息为每个class选出的最相关的15个特征作简要分析:
1、党政办公室:筛选出的信息比较符合,党政、党委、基层等词项很符合。
2、教务部:筛选的文章大多集中于12月份,当时大部分文章都在于总结年度工作。经过对比,可以大致概括出当月的主要工作内容。
3、招生办公室:比较符合。可以很明显看出当时发布了许多走进高中宣传深大的咨询。经验证,发现确实发布了大量主题为《名师进中学》的系列文章。
4、研究生院:筛选出的信息比较符合,硕士、导师、博士等词项很符合。
5、科学技术部:筛选出的信息比较符合,国家自然科学基金、自然科学、经费等词项很符合。
通过X^2为每个class选出的最相关的15个特征:
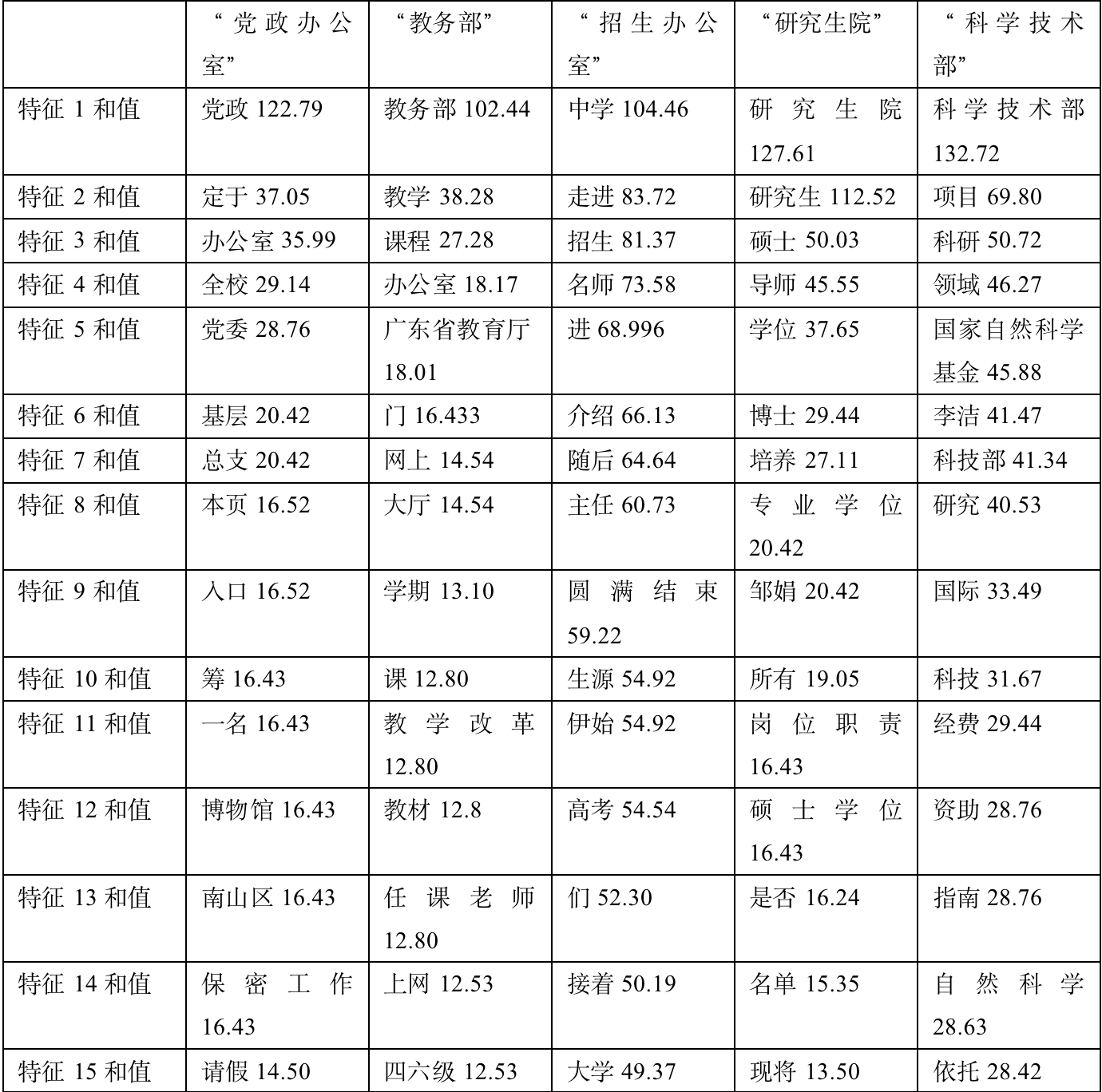
对通过X^2为每个class选出的最相关的15个特征作简要分析:
1、党政办公室:筛选出的信息比较符合,党政、党委、基层等词项很符合。
2、教务部:筛选的文章大多集中于12月份,当时大部分文章都在于总结年度工作。经过对比,可以大致概括出当月的主要工作内容。
3、招生办公室:比较符合。可以很明显看出当时发布了许多走进高中宣传深大的咨询。经验证,发现确实发布了大量主题为《名师进中学》的系列文章。
4、研究生院:筛选出的信息比较符合,硕士、导师、博士等词项很符合。
5、科学技术部:筛选出的信息比较符合,国家自然科学基金、自然科学、经费等词项很符合。
对通过互信息和X^2为每个class选出的最相关的15个特征作简要的对比分析:
因为爬虫的关系,在所有文章中都会出现类似(本文最近更新于2021/12/29 19:05:00 累计点击数:877)的语句。但是两种算法都可以很好的过滤掉这种在所有类别中都重复出现的信息,原因是这种语句中term的N11和N10都很高,可以较好的进行过滤。
另外两种计算方法,前几个特征的选择及排序都相对一致。后面几个特征会有不同的侧重,这是因为X^2基于显著统计性进行选择,因此他会比MI选择出更多的罕见项,而这些词项对于分类是不太可靠的。当然,MI也不一定就能选出是的分类精度最大化的词项。因此我认为加大样本量才是更好的方法。
(2) 用Java语言或其他常用语言实现一个基于朴素贝叶斯分类算法(Naive Bayes algorithm)的文档分类简易系统(判断某个公文通的通知是不是“党政办公室”、“教务部”、“招生办公室”、“研究生院”和“科学技术部”方面的信息,即从5个类别中选择最相关的一个)。
要对使用特征选择和不使用特征选择的分类效果进行对比和分析。用题(1)中的文档进行训练和测试,每个类别中的20篇用作训练,10篇用作测试。
请在报告中附上系统整体设计、代码截图(不要复制源代码,请用截图的方式)、运行结果截图和详细的文字说明。程序要有详细注释。对使用的中文分词工具作简要介绍。(20分)
系统整体设计:
整体设计:
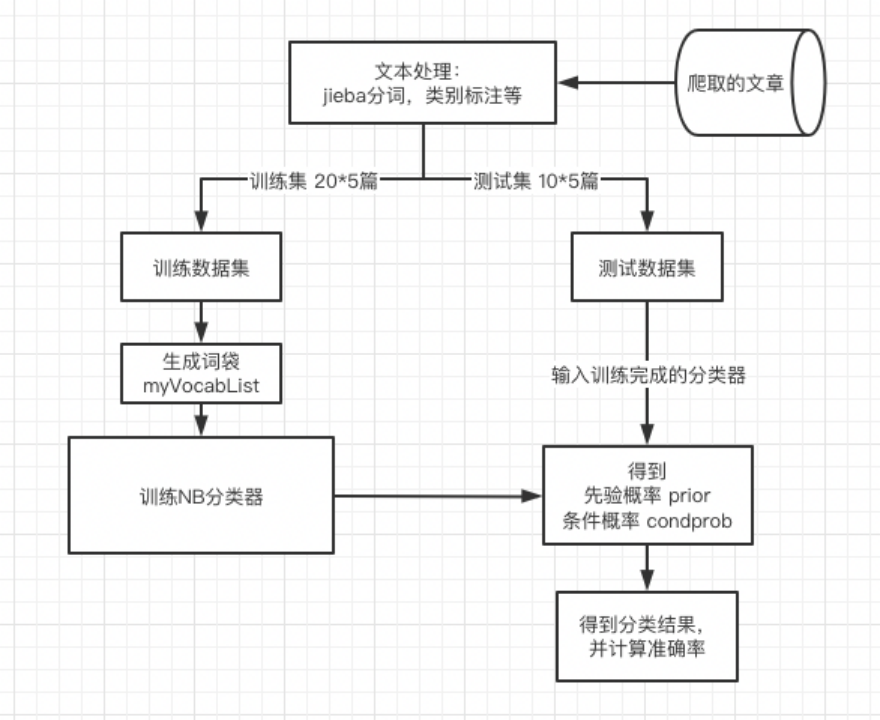
代码截图、运行结果截图和详细的文字说明:
第一步:读取文章数据集

读取过程中,需要读文本进行处理。其中包括由于爬虫下来的文章会有\u3000等多余字符,所以需要进行额外处理。然后利用jieba分词生成文章列表。postingList和classVec一一对应,为文本与标记的正确分类。
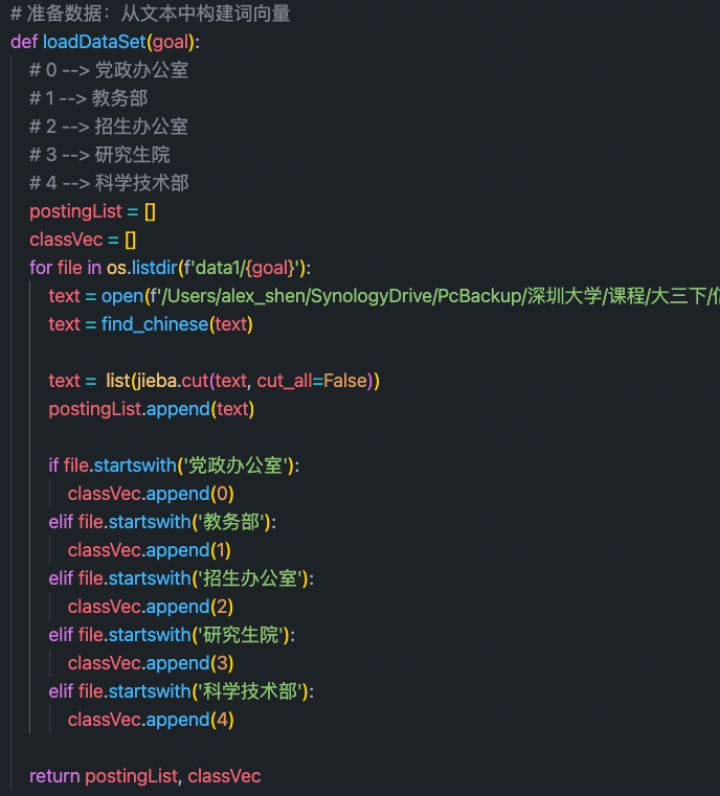
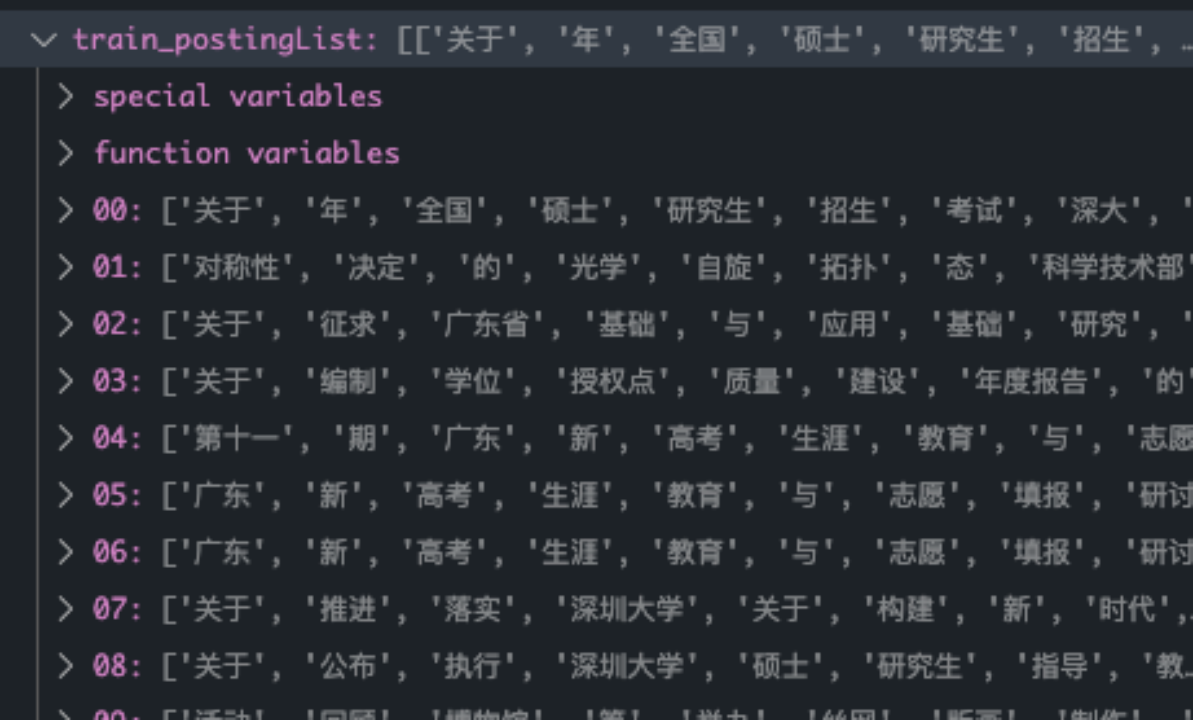
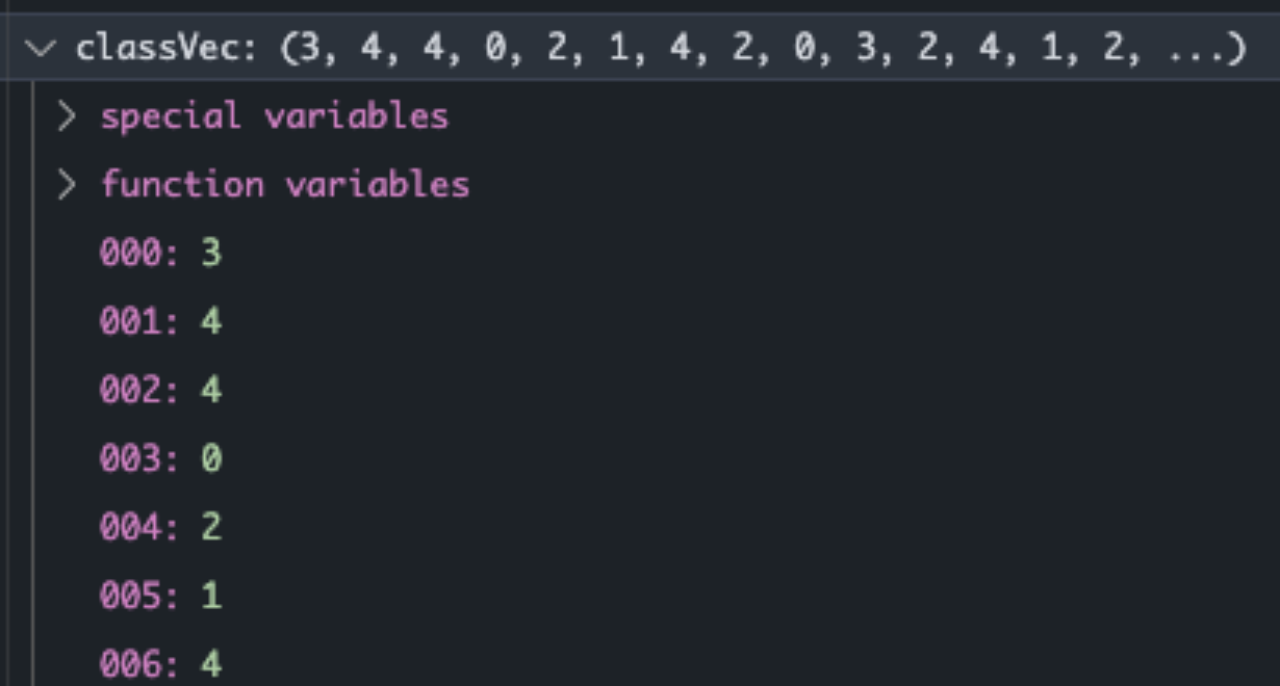
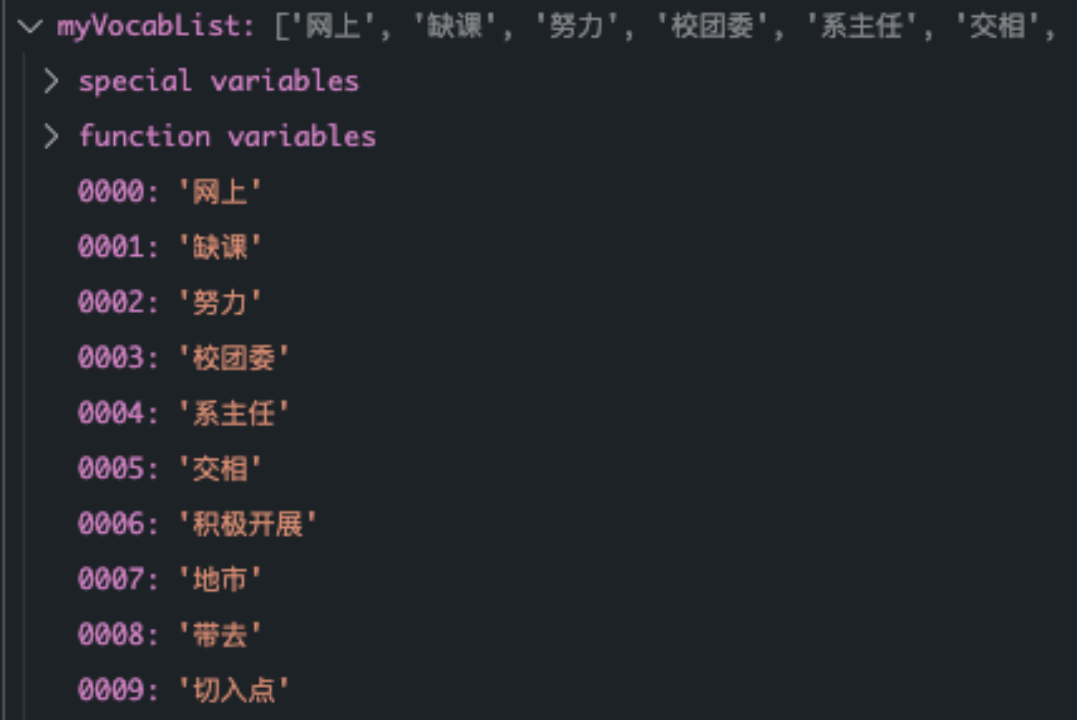
根据文章列表生成词袋
接下来就是训练NB分类器的过程了

朴素贝叶斯计算公式如下:

具体为如下训练伪代码:

具体实现如下:

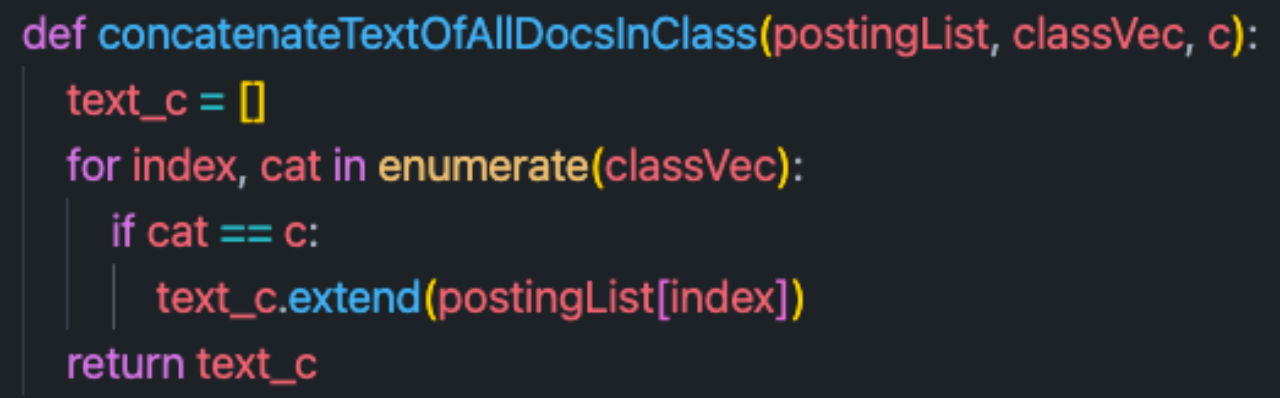
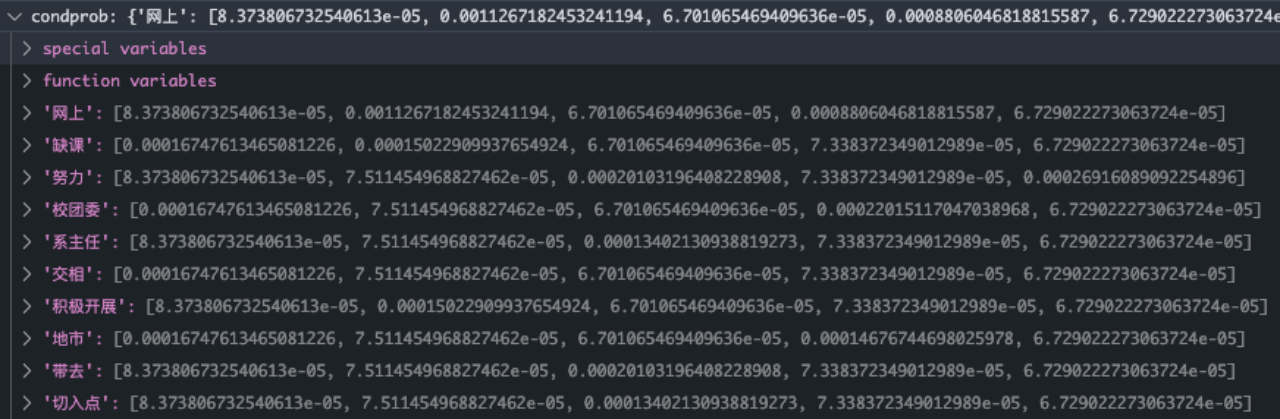
最终可以得到每个词项的条件概率
condprob[term][c]代表term在类别c中的条件概率
朴素贝叶斯算法应用:
计算公式如下所示:可以加上log函数解决小数丢失问题
具体为如下训练伪代码:

applyMultinomialNB会返回概率最大的文档类别。


使用特征选择时的分类效果:
整体正确率94%

不使用特征选择时的分类效果:
整体正确率86%

使用特征选择和不使用特征选择的分类效果进行对比和分析:
可以看到,在使用了特征选择后的分类效果更佳。这是因为使用了特征选择后,可以更准确的对类别进行关键词区分,而未使用的过程中,则会有更多冗余词项进行干扰。
另外两种方法下,对于教务部的分类准确率都不太理想。结合具体文章来看,我觉得可能原因是整理的文章类型太多,数据量太少没有很好的符合规律。因此会导致分类准确度的下降。我猜测的一个可行的方法是增加样本容量,丰富相应的词项。