一、时间模式注意力机制的BiLSTM预测
1 BiLSTM原理结构
LSTM于1997年被提出,用于处理长时间序列问题,典型LSTM结构如图2所示。
图2中,xt表示时间序列的当前输入;Ct表示当前LSTM单元的细胞状态,通常只在LSTM内部流动,是LSTM的内部记忆;ht代表当前的编码隐藏状态向量;ft表示遗忘信息的程度;it表示输入信息的保留程度;C t表示当前状态的处理信息。ot表述输出信息的保留程度;tanh表示双曲正切函数。下标t-1代表上一个时刻的LSTM单元所对应的状态量。
LSTM单元有3道门,分别是遗忘门、输入门和输出门。遗忘门可以忘记一定比例的过去信息;输入门将部分当前时刻的输入信息记录进细胞状态;输出门将编码隐藏状态向量和细胞状态有选择性地作为下一个时刻LSTM单元的输入。
当前时刻的输出可能不仅与过去的信息有关,而且还与未来的信息有关。但LSTM无法编码从后向前的信息,而BiLSTM通过将时间序列反向,由正反向LSTM组成,可以更好地捕获双向序列的影响。BiL STM输出表达式为
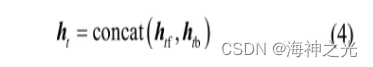
式中:ht表示BiLSTM的隐藏状态向量;concat表示在输出维度进行拼接操作;htf,htb分别表示前向和后向LSTM的隐藏状态向量。
BiLSTM结构示意图如图3所示。通过将正向序列反向后作为后向LSTM的输入,可以同时训练两个神经网络。前向LSTM利用过去的信息预测未来的信息,后向LSTM利用未来的信息预测过去的信息,输出结果由这两个网络的输出共同决定。BiLSTM对于同时依赖前后信息的时间序列有着更好的预测效果,因此本文采用BiLSTM神经网络结合风电功率进行双向信息预测。
2 TPA机制
注意力机制模仿人脑,更加注重重要信息,而忽略相对无用的信息,已被广泛应用于自然语言处理、图像及语音识别中,近年来也被广泛应用于各类预测问题。传统注意力机制注重不同时间点的权重分布,在每个时间步只含有一个变量时有较好的效果。但对于区域内的多风电机组功率预测,每个时间步都含有多个变量,各个变量之间可能存在复杂的非线性内在联系,且每个变量序列都有自己的特征和周期,难以单独选取某个时间步作为注意重点。而TPA则由多个一维CNN滤波器从BiLSTM隐藏状态行向量抽取特征,使得模型能够从不同时间步学习多变量之间的互相依赖关系。TPA结构示意图如图4所示。
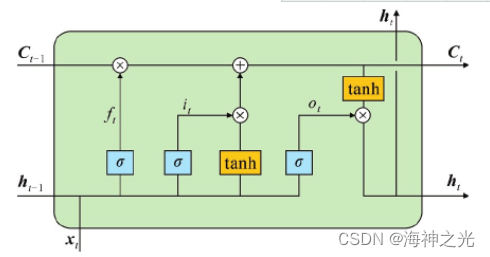
图2 典型LSTM结构
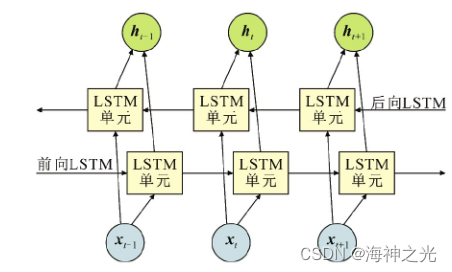
图3 BiL STM结构示意图
对原始时间序列用BiLSTM处理,得到的ht-w―ht表示BiL STM对应不同时间输入得到的隐藏状态向量,w为时间序列长度。定义隐状态矩阵H=(ht-w,ht-w+1,…,ht-1),该隐状态列向量表示同一时间步下BiLSTM内部门神经元参数构成的变量,行向量表示单个变量在所有时间步下的状态。
图4中隐状态矩阵H上的方框表示不同的一维卷积核,利用一维卷积沿着H的m个特征卷积,提取可变信号模型的时间模式矩阵HC
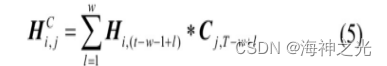
式中:Cj表示第j个长度为T的滤波器;T表示需要注意的最大长度,通常可取为w;*表示卷积运算。一维滤波器的卷积核有k个,每个卷积核都沿着隐状态矩阵的行向量卷积。该时间模式矩阵包含着不同序列的复杂内在联系以及时序关系,是不同序列复杂非线性关系的高维体现。
定义如下注意力机制函数来计算相关性:
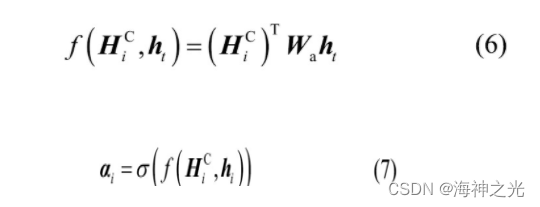
式中:HiC是HC的行向量;Wa为m×k的权重矩阵;αi为注意力权重;σ表示Sigmoid函数。利用得到的注意力权重αi与HC加权求和,获得注意力向量vt

式中,n表示输入变量x的特征数。
将vt与ht线性映射后相加获得最终预测值
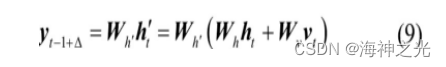
式中:yt-1+△表示最终预测值;h′为用于生成最终值的中间变量;Δ表示不同预测任务的预测时间尺度;Wh′,Wh和Wv为对应变量的不同权重矩阵。
传统注意力机制直接对原始数据的时间序列利用CNN进行特征抽取,只能对单一序列的时间特征进行提取,无法兼顾不同序列之间的关联性。而BiLSTM隐状态矩阵的变量则包含了不同时间步下不同序列之间的复杂关系,利用CNN对隐状态矩阵的行向量进行特征抽取,能同时提取时间序列关系与不同变量之间的复杂联系。且注意力向量vt是包含时间信息的时间模式矩阵行向量加权和,因此模型能够从不同时间步选择相关信息。在处理多风机超短期功率预测这类时间步与不同序列存在复杂和非线性的互相依赖问题时,TPA的先进性能展现出了独特的优势。
二、部分源代码
% 数据集 列为特征,行为样本数目
% 数据集 列为特征,行为样本数目
%% 清除命令行窗口和工作区变量
clc
clear
close all
%% 路径设置
addpath('./')
%% 数据导入及处理
load('./Train.mat')
Train.weekend = dummyvar(Train.weekend);
Train.month = dummyvar(Train.month);
Train = movevars(Train,{'weekend','month'},'After','demandLag');
Train.ts = [];
% Train.hour = dummyvar(Train.hour);
%自己主动观察右侧工作区变量格式,对前面数据进行更改替换
Train(1,:) =[];
y = Train.demand;
x = Train{:,2:5};
[xnorm,xopt] = mapminmax(x',0,1);
[ynorm,yopt] = mapminmax(y',0,1);
%
% xnorm = [xnorm;Train.weekend';Train.month'];
%%
% x = x';
xnorm = xnorm(:,1:1000);
ynorm = ynorm(1:1000);
k = 24; % 滞后长度
% 转换成2-D image
for i = 1:length(ynorm)-k
Train_xNorm(:,i,:) = xnorm(:,i:i+k-1);
Train_yNorm(i) = ynorm(i+k-1);
Train_y(i) = y(i+k-1);
end
Train_yNorm= Train_yNorm';
ytest = Train.demand(1001:1170);
xtest = Train{1001:1170,2:5};
[xtestnorm] = mapminmax('apply', xtest',xopt);
[ytestnorm] = mapminmax('apply',ytest',yopt);
% xtestnorm = [xtestnorm; Train.weekend(1001:1170,:)'; Train.month(1001:1170,:)'];
xtest = xtest';
for i = 1:length(ytestnorm)-k
Test_xNorm(:,i,:) = xtestnorm(:,i:i+k-1);
Test_yNorm(i) = ytestnorm(i+k-1);
Test_y(i) = ytest(i+k-1);
end
Test_yNorm = Test_yNorm';
clear k i x y
%
Train_xNorm = dlarray(Train_xNorm,'CBT');
Train_yNorm = dlarray(Train_yNorm,'BC');
Test_xNorm = dlarray(Test_xNorm,'CBT');
Test_yNorm = dlarray(Test_yNorm,'BC');
%% 训练集和验证集划分
TrainSampleLength = length(Train_yNorm);
validatasize = floor(TrainSampleLength * 0.1);
Validata_xNorm = Train_xNorm(:,end - validatasize:end,:);
Validata_yNorm = Train_yNorm(:,TrainSampleLength-validatasize:end);
Validata_y = Train_y(TrainSampleLength-validatasize:end);
Train_xNorm = Train_xNorm(:,1:end-validatasize,:);
Train_yNorm = Train_yNorm(:,1:end-validatasize);
Train_y = Train_y(1:end-validatasize);
%%
%参数设置
inputSize = size(Train_xNorm,1); %数据输入x的特征维度
outputSize = 1; %数据输出y的维度
numhidden_units1=50;
[params,~] = paramsInit(numhidden_units1,inputSize,outputSize); % 导入初始化参数
[~,validatastate] = paramsInit(numhidden_units1,inputSize,outputSize); % 导入初始化参数
[~,TestState] = paramsInit(numhidden_units1,inputSize,outputSize); % 导入初始化参数
% 训练相关参数
TrainOptions;
numIterationsPerEpoch = floor((TrainSampleLength-validatasize)/minibatchsize);
LearnRate = 0.01;
%% Loop over epochs.
figure
start = tic;
lineLossTrain = animatedline('color','r');
validationLoss = animatedline('color',[0 0 0]./255,'Marker','o','MarkerFaceColor',[150 150 150]./255);
xlabel('Iteration')
ylabel('Loss')
% epoch 更新
iteration = 0;
for epoch = 1 : numEpochs
[~,state] = paramsInit(numhidden_units1,inputSize,outputSize); % 每轮epoch,state初始化
disp(['Epoch: ', int2str(epoch)])
% batch 更新
for i = 1 : numIterationsPerEpoch
iteration = iteration + 1;
disp(['Iteration: ', int2str(iteration)])
idx = (i-1)*minibatchsize+1:i*minibatchsize;
dlX = gpuArray(Train_xNorm(:,idx,:));
dlY = gpuArray(Train_yNorm(idx));
[gradients,loss,state] = dlfeval(@TPAModel,dlX,dlY,params,state);
% L2正则化
% L2regulationFactor = 0.000011;
% gradients = dlupdate( @(g,parameters) L2Regulation(g,parameters,L2regulationFactor),gradients,params);
% gradients = dlupdate(@(g) thresholdL2Norm(g, gradientThreshold),gradients);
[params,averageGrad,averageSqGrad] = adamupdate(params,gradients,averageGrad,averageSqGrad,iteration,LearnRate);
% 验证集测试
if iteration == 1 || mod(iteration,validationFrequency) == 0
output_Ynorm = TPAModelPredict(gpuArray(Validata_xNorm),params,validatastate);
lossValidation = mse(output_Ynorm, gpuArray(Validata_yNorm));
end
三、运行结果




四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 王渝红,史云翔.基于时间模式注意力机制的BiLSTM多风电机组超短期功率预测[J].高电压技术. 2022,48(05)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除