�ٸ�����:����һ��ͼƬ�Ĵ���
��������
��������һ��ͼ������,��С��64 * 64������һ�����ؾ���һ����ɫ��,һ����ɫ���ɺ���������ֵ����ʾ,����,������Ϊ255,255,255,��ô�����ɫ����ǰ�ɫ)��
���ȼ��������ͼ����������������ֱ�洢R G B��
Ϊ�˸��ӷ������Ĵ���,����һ���������3������ת����1������x(�������������1 * n��n * 1������,ǰ��Ϊ������,����Ϊ������,)����ô�������x����ά������64 * 64 * 3,�����12288�����˹�����������,ÿһ�����뵽����������ݶ�������һ������,��ô���������ͼ���о���12288�����������12288ά������Ҳ������������������������������������x��Ϊ����,������Ԥ��,Ȼ�������Ӧ�Ľ����
���ڲ�ͬ��Ӧ��,��Ҫʶ��Ķ���ͬ,��Щ��������Щ��ͼ����Щ�Ǵ���������,���������ڼ�����ж��ж�Ӧ�����ֱ�ʾ��ʽ,ͨ�����ǻ������ת����һ����������,Ȼ�������뵽�������С�
Ԥ��
���������Ѿ�֪������ν��������뵽�������С���ô����������θ�����Щ���ݽ���Ԥ�����?���ǽ�һ��ͼƬ���뵽��������,�����������Ԥ������ͼ���Ƿ���è����??
���Ԥ��Ĺ�����ʵֻ�ǻ���һ���Ĺ�ʽ:z = dot(w,x) + b��
���湫ʽ�е�x������������������,����ֻ��3������,��ôx�Ϳ�����(x1,x2,x3)����ʾ������ͼ��ʾ��w��ʾȨ��,����Ӧ��ÿ����������,������ÿ����������Ҫ�̶ȡ�b��ʾ��ֵ[y�� zh��],����Ӱ��Ԥ������z����Ԥ��������ʽ�е�dot()������ʾ��w��x����������ˡ�

����Ĺ�ʽչ����ͱ����z = (x1 * w1 + x2 * w2 + x3 * w3) + b��
��ô�����絽����������������ʽ������Ԥ�����?�پٸ�����
������ĩ��������,����˵����ij��н�����һ�����ֽڡ�����ҪԤ�����Ƿ�����ȥ�μӡ����ֽ������ͦԶ,��������լ�ڼ������Ϸ,��������Ԥ��˵���ֽ����������ر�á�Ҳ����˵��3�����ػ�Ӱ����ľ���,��3�����ؾͿ��Կ�����3���������������㵽���ȥ��?��ĸ���ϲ�á����������3�����ص����ӳ̶ȡ�����Ӱ����ľ�������3�����ӳ̶Ⱦ���3��Ȩ�ء�
�������õ���Զ������ν,�����Ѿ���̫�����Ϸ��,�������ϲ���������,��ô���ǽ�Ԥ�����ȥ���ֽڡ����Ԥ����̿��������ǵĹ�ʽ����ʾ�����Ǽ�����z����0�Ļ��ͱ�ʾ��ȥ,С��0��ʾ��ȥ��������ֵb��-5������3������(x1,x2,x3)Ϊ(0,0,1),���һ����1,�������˺���������������Ȩ��(w1,w2,w3)��(2,2,7),���һ����7��ʾ���ϲ������������ô����z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 2 + 1 * 7) + (-5) = 2��Ԥ����z��2,2����0,����Ԥ�����ȥ���ֽڡ�
���������dz������Ϸ,���Ҷ������������ز�������,��ô����Ԥ���㽫����ȥ���ֽڡ���ͬ�����������ǵĹ�ʽ����ʾ��������Ȩ��(w1,w2,w3)��(2,7,2),w2��7��ʾ���������ߵ���������ô����z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 7 + 1 * 2) + (-5) = -3��Ԥ����z��-3,-3С��0,����Ԥ���㲻��ȥ,����ڼ��������ߡ�
Ԥ��ͼƬ����û��èҲ��ͨ������Ĺ�ʽ������ѵ�����������õ�һ����è��ص�Ȩ�ء������ǰ�һ��ͼƬ���뵽��������,ͼƬ���ݻ�������Ȩ���Լ���ֵ��������,�������0������è,С��0����û��è��
�����Ǹ�����Ԥ��Ĺ�ʽ���dz�֮Ϊ���ع���
���������һ�¼��������ʵ�ʵ���������,���Dz���ֱ�������ع顣����Ҫ�����ع�����������һ������������������Ǿͳ���Ϊ�������������dz��dz���Ҫ,���û����,��ô�������������Զ�߲�������
�������һ�ֽ���sigmoid�ļ���������Ĺ�ʽ��ͼ�����¡�
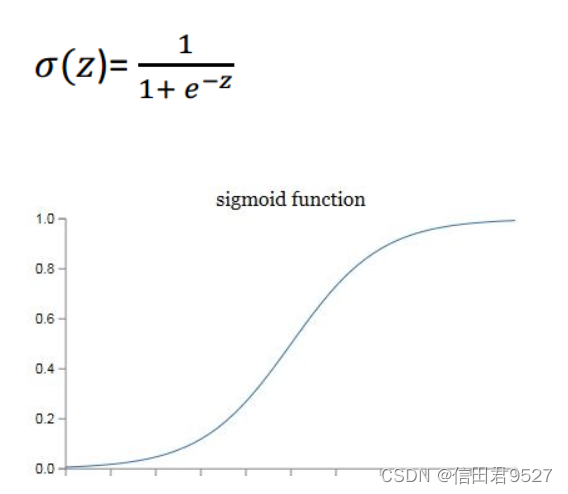
?�������һ����;������zӳ�䵽[0,1]֮�䡣��ͼ�еĺ�������z,������������y������ʾ,y���ʹ������������յ�Ԥ��������ͼ����Կ���,zԽ����ôy����Խ����1,zԽС��ôy����Խ����0����ΪʲôҪ��Ԥ����ӳ�䵽[0,1]֮����?��Ϊ��������������������м���,Ҳ������������������⡣������Ԥ���Ƿ���è��������,���y����0.8,��˵����80%�ĸ�������è�ġ�
�����֤
Ҫ��֤ѧϰ�ɹ�,����Ҫ�ж�Ԥ�����Ƿ�ȷ,���Ҫ����ʧ�����ˡ�
����ͨ������һ��Ŀ�꺯��,��ϣ���Ż�������͵㡣 ��ΪԽ��Խ��,������Щ������ʱ����Ϊ��ʧ����(loss function,��cost function)��
Ŭ��ʹ��ʧ������ֵԽС����Ŭ����Ԥ��Ľ��Խȷ����ʧ���������þ��Ǻ���ģ��Ԥ��ĺû���ͨ����ʧ�����Ǹ���ģ�Ͳ��������,��ȡ�������ݼ��� ��һ�����ݼ���,����ͨ����С������ʧ��ѧϰģ�Ͳ��������ֵ�� �����ݼ���һЩΪѵ�����ռ����������,��Ϊѵ�����ݼ�(training dataset,���Ϊѵ����(training set))�� Ȼ��,��ѵ�������ϱ������õ�ģ��,����һ���ڡ������ݼ�������ͬ����Ч��,����ġ������ݼ���ͨ����Ϊ�������ݼ�(test dataset,���Ϊ���Լ�(test set))��
�㷨�Ż�
һ�����ǻ����һЩ����Դ�����ʾ��һ��ģ�ͺ�һ�����ʵ���ʧ����,���ǽ���������Ҫһ���㷨,���ܹ���������Ѳ���,����С����ʧ������ ������е��Ż��㷨ͨ������һ�ֻ��������C�ݶ��½�(gradient descent)�� �����֮,��ÿ��������,�ݶ��½���������ÿ������,�����������Ըò������������䶯,ѵ������ʧ�ᳯ�ĸ������ƶ��� Ȼ��,���ڿ��Լ�����ʧ�ķ������Ż��������ݶ��½���һ�����ĸı�w��b��ֵ,�Ӷ�����ʧ��������������С��
����˵����ѧϰ��ѧϰ����˵ѵ��������,�����ҵ�һ��w��b,����ʧ������С,Ҳ����Ԥ������ȷ��