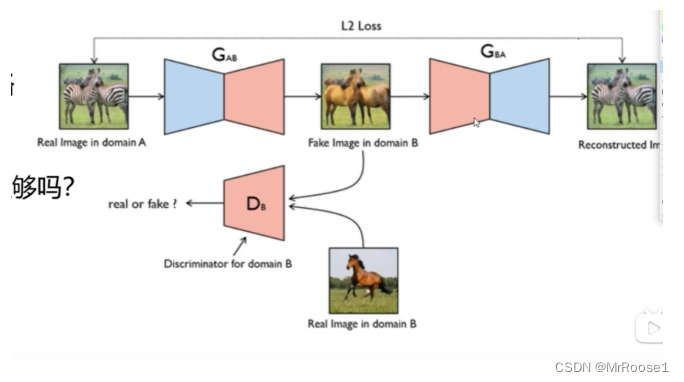
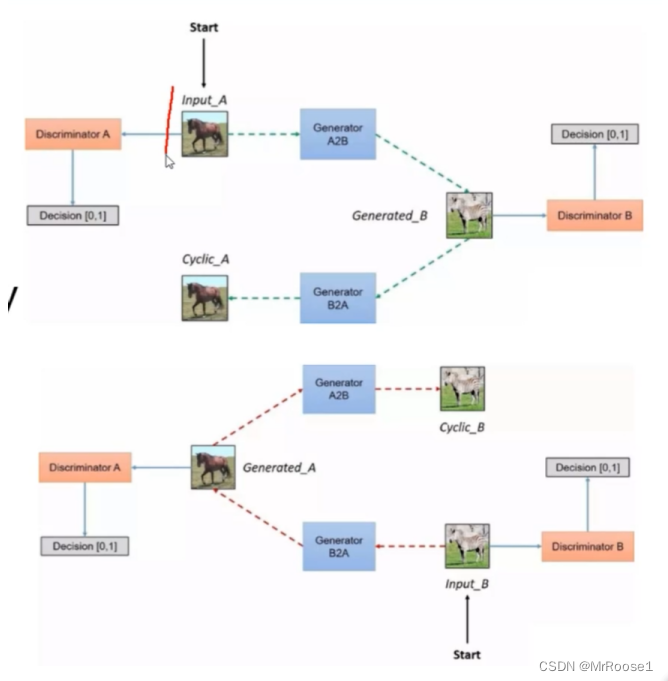
学习CycleGAN的路线:
1)先看09 基于CycleGan开源项目实战图像合成_哔哩哔哩_bilibili中的整体网络架构,PatchGAN判别网络原理。
2)再看【 深度学习李宏毅 】CycleGAN (中文)_哔哩哔哩_bilibili,以及?CycleGAN(五)loss解析及更改与实验_祥瑞Coding的博客-CSDN博客_adversarial loss中讲解的loss函数。
3)再看下文。
4)看完下文再看基于CycleGAN的风格迁移【一】环境搭建及运行代码_MrRoose1的博客-CSDN博客_cyclegan图像风格迁移进行环境搭配安装
5)安装完看基于CycleGAN的风格迁移【二】CycleGAN源码解读_MrRoose1的博客-CSDN博客_cyclegan风格迁移中的代码讲解。
Abstract
图像到图像的翻译是一类视觉和图形问题,其目标是使用对齐的图像对训练集来学习输入图像和输出图像之间的映射。然而,对于许多任务,成对的训练数据是不可利用的。我们提供了一种在没有配对示例的情况下学习将图像从源域X转换为目标域Y的方法。我们的目标是学习映射G,使得来自G(X)的图像的分布与Y的分布使用对抗损失是无法区分的。因为这个映射是欠约束的,所以我们将它与一个逆映射F:Y?->X耦合,并引入一个循环一致性损失来强制执行F(G(X))≈??X(反之亦然)。定性的结果是在不存在配对训练数据的几个任务上,包括集合样式转移(style transfer)、对象变形(object transfiguration)、季节转移(season transfer)、照片增强等。
Introduction
在本文中,我们提出了一种可以学习的方法:捕获一个图像集合的特殊特征,并找出如何将这些特征转换为另一个图像集合,而无需任何成对的训练示例。例如,转换的方式可以有:灰度到颜色,图像到语义标签,边缘映射到照片。然而,获得成对的训练数据可能是困难和昂贵的。由于所需的输出高度复杂(通常需要艺术创作),因此获取图形任务(如艺术风格)的输入输出对可能会更加困难。
Generative Adversarial Networks (GANs)成功的关键是采用一种对抗损失,这种损失迫使生成的图像在无法与原始图像进行区分。
本篇论文的出发点和pix2pix的不同在于:
①pix2pix网络要求提供 image pairs,也即是要提供x和y,整个思路为:从噪声z,根据条件x,生成和真实图片y相近的y’。条件x和图像y是具有一定关联性的!
②而本篇cycleGAN不要求提供pairs,如题目中所说:Unpaired。因为成对的图像数据集其实并不多。这里的X和Y不要求有什么较好的关联性,可以是毫不相干的两幅图像。
与现有的一些方法不同,我们的公式不依赖于输入和输出之间任何特定于任务的预定义相似函数,也不假设输入和输出必须位于相同的低维嵌入空间。这使得我们的方法成为许多视觉和图形任务的通用解决方案。
我们假设源域与目标域之间存在一些潜在的关系,例如,它们是同一个潜在场景的两个不同渲染,并试图学习这种关系。尽管我们缺乏成对示例形式的监督,但是我们可以在集合级别上利用监督:
我们主要训练一种映射关系![]()
使得对抗训练得到的输出??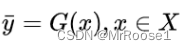 无法与原始图像?y区分开。G随机的。最优G从而将源域X转换为目标域Y。然而,这样的变换并不能保证输入x和输出y以有意义的方式配对,因为有无限多个映射G将在?上导致相同的分布。
无法与原始图像?y区分开。G随机的。最优G从而将源域X转换为目标域Y。然而,这样的变换并不能保证输入x和输出y以有意义的方式配对,因为有无限多个映射G将在?上导致相同的分布。
 ?主要有两种映射关系:
?主要有两种映射关系:
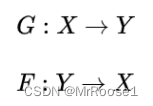
两种对抗判别器adversarial discriminators:

我们的目标包含两种类型的术语:对抗损失,用于将生成的图像的分布与目标域中的数据分布进行匹配; 以及循环一致性损失,以防止学习到的映射G和F相互矛盾。
Adversarial Loss

损失函数的计算
辨别器对假数据的损失原理相同,最终达到的目标是对于所有的真实图片,输出为1;对于所有的假图片,输出为0。
生成器的目标是愚弄辨别器蒙混过关,需要达到的目标是对于生成的图片,输出为1(正好和鉴别器相反).

G尽量使得生成的图像![]() 看起来更接近于Y,而
看起来更接近于Y,而![]() 主要是区分变换的样本?与真实的样本Y。
主要是区分变换的样本?与真实的样本Y。
用一个形象的例子解释就是:GAN就好比是一个大的网络,在这个网络中有两个小的网络,一个是生成网络,可以当做是制作假钞的人, 而另一个是鉴别网络,也就是鉴别假钞的人。对于生成网络的目标就是去欺骗鉴别器,而鉴别器是为了不被生成器所欺骗。模型经过交替的优化训练,都能得到提升,理论证明,最后生成模型最好的效果是能够让鉴别器真假难分,也就是真假概率五五开。
鉴别器接受真实样本和生成器生成的虚假样本,然后判断出真假结果。
生成器接受噪声,生成出虚假样本。
GAN的目标函数公式:
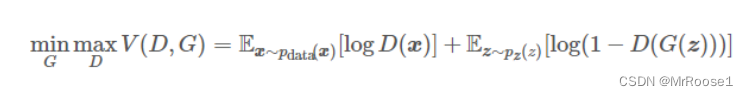
从目标函数可以看出,整个代价函数是最小化生成器,最大化鉴别器,那么在处理这个最优化问题的时候,我们可以先固定住G,然后先最大化D,然后再最小化G得到最优解。其中,在给定G的时候,最大化 V(D,G) 评估了P_G和P_data之间的差异或距离。
首先,在固定G之后,最优化D的情况就可以表述为:
最优化G的问题就可以表述为:
Cycle Consistency Loss
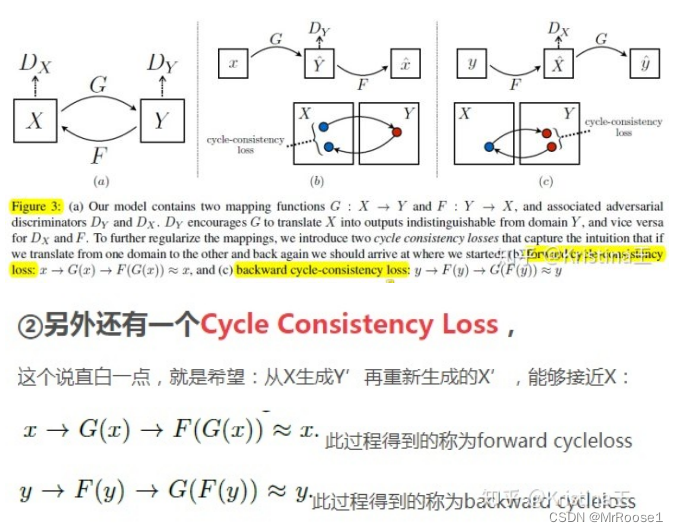
使用循环一致性损失(cycle consistency loss)作为使用传递性来监督CNN训练。?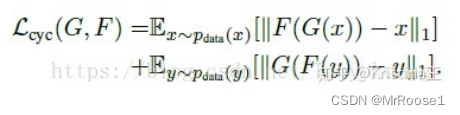
(L1损失函数也被称为最小绝对值偏差(LAD),绝对值损失函数(LAE)。总的说来,它是把目标值![]() 与估计值
与估计值![]() 的绝对差值的总和最小化。
的绝对差值的总和最小化。
?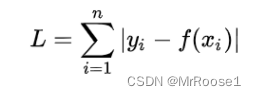 )
)
因此,仅使用对抗损失就不能保证学习函数可以将单个输入![]() 映射到所需的输出?
映射到所需的输出?![]() 。?
。?
为了进一步减少可能的映射函数的空间,我们认为学习的映射函数应该是循环一致的(cycle-consistent)。
前向循环一致性:forward cycle consistency
后向循环一致性:backward cycle consistency

补充【反卷积的作用】:
反卷积,顾名思义是卷积操作的逆向操作。
为了方便理解,假设卷积前为图片,卷积后为图片的特征。
卷积,输入图片,输出图片的特征,理论依据是统计不变性中的平移不变性(translation invariance),起到降维的作用。
反卷积,输入图片的特征,输出图片,起到还原的作用。
用GANs生成图片,其中的generator和discriminator均采用深度学习,generator生成图片过程中采用的就是反卷积操作

(当然discriminator采用卷积对generator生成的图片判别真伪)。?
反卷积(转置卷积)通常用来两个方面:
1. CNN可视化,通过反卷积将卷积得到的feature map还原到像素空间,来观察feature map对哪些pattern相应最大,即可视化哪些特征是卷积操作提取出来的;
2. FCN全卷积网络中,由于要对图像进行像素级的分割,需要将图像尺寸还原到原来的大小,类似upsampling的操作,所以需要采用反卷积;
3. GAN对抗式生成网络中,由于需要从输入图像到生成图像,自然需要将提取的特征图还原到和原图同样尺寸的大小,即也需要反卷积操作。