1.�ع�Ķ���:�ҵ�һ������,���һ������ֵ,�������ֵ��
��:�Թ�ȥ��������Ԥ��δ���ķ���,�������ʦ�ܹ�ȥ��Ŀ�ۿ�����Ԥ��δ���������Ŀ�ۿ�������
2.ģ�Ͳ���:
(1) ģ�ͼ���C����ģ��:yi=xi*w+b
����xΪfeatures,wΪweight,bΪbias;xi����Ϊ���feature.
(2)ģ�������C��ʧ����
��ģ��ѵ�����Ϻ�õ������ϵķֲ�,����ѧ�ĽǶ���ʵֵy^��y��Ĵ�ֱ��������С�������ж�ģ�͵ĺû�(ŷ�������),��ʧ��������:
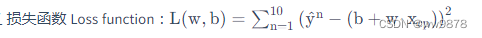
һ����˵,��ʧ����ԽСģ��Խ��,��������ԽС����ʧ����ģ�;�Խ�á�
3.���ģ��-�ݶ��½�
Ϊ���ҳ���õĺ���,������Ҫȷ��w��b��ֵ����w��b��ֵ��ֹһ����������Ҫʹ���ݶ��½��ķ�������ͣ����w��b��ֵ,���ҵ���õĺ�����
��w�ĸ���:
���ѡȡһ��w0,����������w0�ĵ���(б��)��������ǰ������
֮�����벽�� ��������,��(ѧϰ��:�˹����),�Ӷ��õ�w1�ĸ���(w2��wn,b1��bnͬ��)�ҵ���ǰ��Сֵ��:
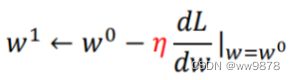
3.������Լ��Ż�:
ʹ��ʹ��ѵ�����Ͳ��Լ���ƽ���������֤ģ�͵ĺû� ,�����Լ���ƽ��������ѵ�������ʱ,�����������֡�(ѵ�����Ƚ�����,�����Լ�����ȴ�Ƚ����)
�Ż�����:
1.���������ģ�ͺϲ���һ������ģ����
2.������������xi,
�����������������w��ʹһЩ����Ȩ�ع���,��Ȼ�����
3.��������
(�������ﲻ���˽����ȥ��)
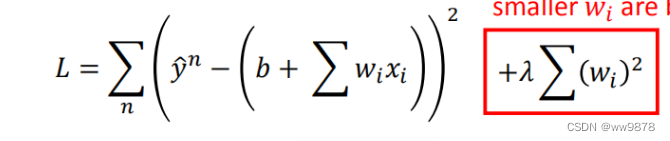
Ŀǰ��������:����ʧ����������һ��,��ô��ʵ�ݶ��½���Ҫ������ʧ�����Ĵ�С,�� �����������Ĵ�С,��ôҲ���ǻ����WȨ�صĴ�С��
ԽС��wiʹ����Խƽ��,��������ΪԽƽ���ĺ������������ȷ�ġ���b������0���ں�����ƽ���̶�û��Ӱ�졣