语音助手已经成为生活中必不可少的小帮手。但是有的时候在室内用着得心应手的语音小助手换到更室外可能就变成“傻憨憨”了。就如同我们人类一般,小萌新―语音小助手到了新的环境,也会慌乱无措。就如同中国人听印度人说英语,自认为自己英语听力、口语都很棒的人,在第一次听带着咖喱味的印度英语时,也会怀疑自己听到的真的是英语吗?人类天生拥有适应环境的能力尚且如此,更遑论人工智能算法了。语音小助手对周遭环境敏感,是对域的不适应。迁移学习一直以来是语音识别、语音合成、说话人识别等各个语音领域的难题。
语音助手内部的人工智能算法往往是从大量数据学习得到,有时数据无法覆盖全部的应用场景,这就导致面对一些新场景,如弧形的会议厅、开阔的广场等场景下,语音识别的准确度大大降低。亦或者,对于大量录音棚录制的语音对话数据训练的模型,无法直接在一些专业领域被运用,如电商客服、金融智能客服、智能医疗领域等垂域。由于缺乏域内知识,导致模型效果在新的场景下,效果不尽人意。如何将模型自适应到各个垂域,一般会从两个方面考虑。
迁移学习算法
迁移学习指的是我们在A场景数据训练的模型,可以适应迁移学习算法,将这个模型应用到其他场景下,尽可能的保持这个模型的性能不受环境域的改变而受到影响。迁移学习放松了训练数据必须与测试数据独立且同分布(i.i.d)的假设,激励我们利用迁移学习来解决训练数据不足的问题。在迁移学习中,训练数据和测试数据不需要是i.i.d。不需要对目标域内的模型进行从零开始的训练,可以显著降低对目标域内训练数据和训练时间的需求。据文献《S. J. Pan and Q. Yang, “A survey on transfer learning” 》总结,迁移学习算法根据不同情况可以分为以下几类:
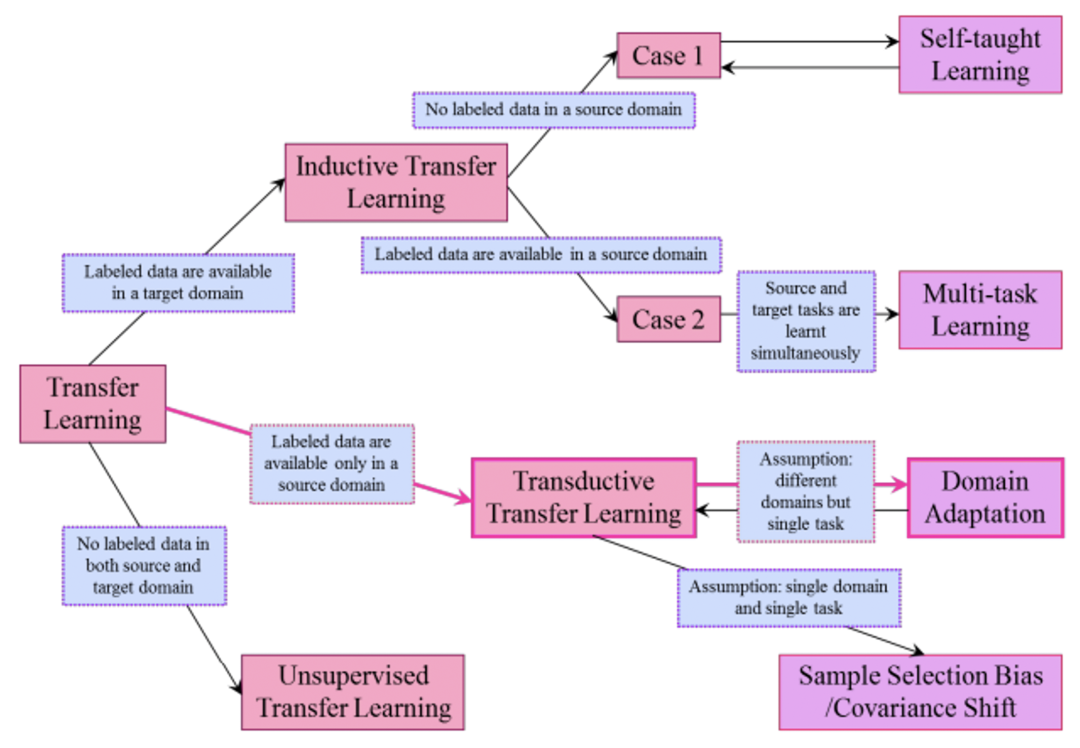
纵然上述迁移学习算法众多,但是算法的执行依然离不开域内数据的支撑。如果没有域内数据,上述的算法几乎都无法实施。
域内数据自适应
最简单有效的迁移学习方法,就是用少量的域内数据fine-tune已有模型。使得已有模型自适应到当前数据场景。上述迁移学习算法也离不开域内数据的支撑。而语音助手要想在应用于各个垂域,离不开在各个垂域数据上学习。这就需要Magic Data这样的AI数据解决方案提供商为众多工业界和高校研究者提供垂域的数据,以支撑上述迁移学习算法的研究和语音助手应用于各个领域。Magic Data拥有各个领域、各种语言、多种场景的语音对话数据。