- �������ԡ�Python���ݷ��������ŵ���ͨ��-���տƼ�����
- ����ѧϰ����˼������û���(�����)ģ������ѧϰ,��Ч��߹���Ч�ʡ�Python�ṩ�ĵ�������Scikit-Learn�����˴�������ѧģ���㷨,ʹ�����ݷ���������ѧϰ��ü�Ч��
- ���ڱ��������ݴ��������ݷ���Ϊ��,���ǻ���ѧϰ,���Զ���Scikit-Learn����ؼ���ֻ������,��Ҫ����Scikit-Learn��顢��װ,�Լ����õ����Իع�ģ����С���˷��ع顢��ع顢֧���������;��ࡣ
10.1 Scikit-Learn���
- Scikit-Learn(���SKlearn)��Python�ĵ�����ģ��,���ǻ���ѧϰ������֪����Pythonģ��֮һ,���Գ��õĻ���ѧϰ�㷨�����˷�װ,�����ع�(Regression)����ά(Dimensionality Reduction)������(Classfication)�;���(Clustering)�Ĵ����ѧϰ�㷨��Scikit-Learn���������ص㡣
- ��Ч�������ھ�����ݷ������ߡ�
- ��ÿ�����ܹ��ڸ��ӻ������ظ�ʹ�á�
- Scikit-Learn��Scipyģ�����չ,�ǽ�����NumPy��Matplotlibģ��Ļ����ϵġ������⼸��ģ�������,���Դ�������ѧϰ��Ч�ʡ�
- ��Դ,����BSDЭ��,��������ҵ��
10.2 ��װScikit-Learn
- Scikit-Learn��װҪ������:
- Python�汾:����2.7
- NumPy�汾:����1.10.2
- Scipy�汾:����0.13.3
- ����Ѿ���װNumPy��Scipy,��ô��װScikit-Learn�������ʹ��pip���߰�װ����װ��������:
pip install -U scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simpl
- ������Ҫע��:����ѡ��װ0.21.2�汾,�������г�����ܳ�����Ϊģ��汾���ʺ϶����³�����ִ�����ʾ�������Ҳ���ֻ����ģ�顱��
10.3 ����ģ��
- Scikit-Learn�Ѿ�Ϊ������ƺ�������ģ��(sklearn.linear_model),�ڳ�����ֱ�ӵ��ü���,�����д�������Ϳ�������ʵ�����Իع�����������˽�һ�����Իع������
- �����Իع���,ֻ����һ���Ա�����һ�������,�Ҷ��ߵĹ�ϵ����һ��ֱ�߽��Ʊ�ʾ,���ֻع������ΪһԪ���Իع����;������Իع�����а����������������ϵ��Ա���,����������Ա���֮�������Թ�ϵ,���Ϊ��Ԫ���Իع顣
- ��Python��,�������ᷱ�������Իع������ѧ����,ֱ��ʹ��Scikit-Learn��linear_modelģ��Ϳ���ʵ�����Իع������linear_modelģ���ṩ�˺ܶ�����ģ��,������С���˷��ع顢��ع顢Lasso����Ҷ˹�ع�ȡ�������Ҫ������С���˷���u��i����ع顣
- ���ȵ���linear_modelģ��,�����������:
from sklearn import linear_model
- ����linear_modelģ���,�ڳ����оͿ���ʹ����غ���ʵ�����Իع������
10.3.1 ��С���˷��ع�
- ���Իع��������ھ��еĻ����㷨֮һ,���Իع��˼����ʵ���ǽ�һ�鷽��,�õ��ع�ϵ��,�����ڳ�ϯ�������֮��,���̵Ľⷨ�ʹ����˸ı�,һ������С���˷����м���,��ν�����ˡ�����ƽ������˼,��С���˷�Ҳ����Сƽ����,��Ŀ����ͨ����С������ƽ����,ʹ��Ԥ��ֵ����ֵ���ӽ���
- linear_modelģ���LinearRegression()��������ʵ����С���˷��ع顣LinearRegression()�������һ�����лع�ϵ��������ģ��,ʹ����ʵ���ݺ�Ԥ������(����ֵ)֮��IJв�ƽ������С,����ʵ�������ӽ���LinearRegression()���������:
linear_model.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=None)
- fit_intercept:������ֵ,�Ƿ���Ҫ����ؾ�,Ĭ��ֵΪTrue
- normalize:������ֵ,�Ƿ���Ҫ����,Ĭ��ֵΪFalse,�����fit_intercept�йء���fit_intercept����ֵΪFalseʱ,�����Ըò���;��fit_intercept����ֵΪTrueʱ,��ع�ǰ�Իع���X���й�һ��(����)����,ȡ��ֵ���,�ٳ���L2����(L2������ָ������Ԫ�ص�ƽ����Ȼ��)��
- copy_X:������ֵ,ѡ���Ƿ���X����,Ĭ��ֵΪTrue,���ֵΪFalse,��X���ݡ�
- n_jobs:����,����CPU����Ч�ʵĺ���,Ĭ��ֵΪ1,-1��ʾ��CPU����һ�¡�coef_:�������״,��ʾ���Իع�����Ļع�ϵ����intercept_:����,��ʾ�ؾࡣ
- ��Ҫ����:
- fit(X,y,sample_weight=None):�������ģ�͡�
- predict(X):ʹ������ģ�ͷ���Ԥ�����ݡ�
- score(X,y,sample_weight=None):����Ԥ���ȷ��ϵ��R^2
- LinearRegression()��������fit()�������������X��y,���ҽ�����ģ�͵Ļع�ϵ���洢�����Ա����coef_�����С�
����Ԥ�ⷿ��(01)
- ����Ԥ�ⷿ��,����ij�ط�������ͼ۸��������ͼ10.2��ʾ,����ʹ��LinearRegression()����Ԥ�����Ϊ170ƽ���ķ��ݵĵ��ۡ�
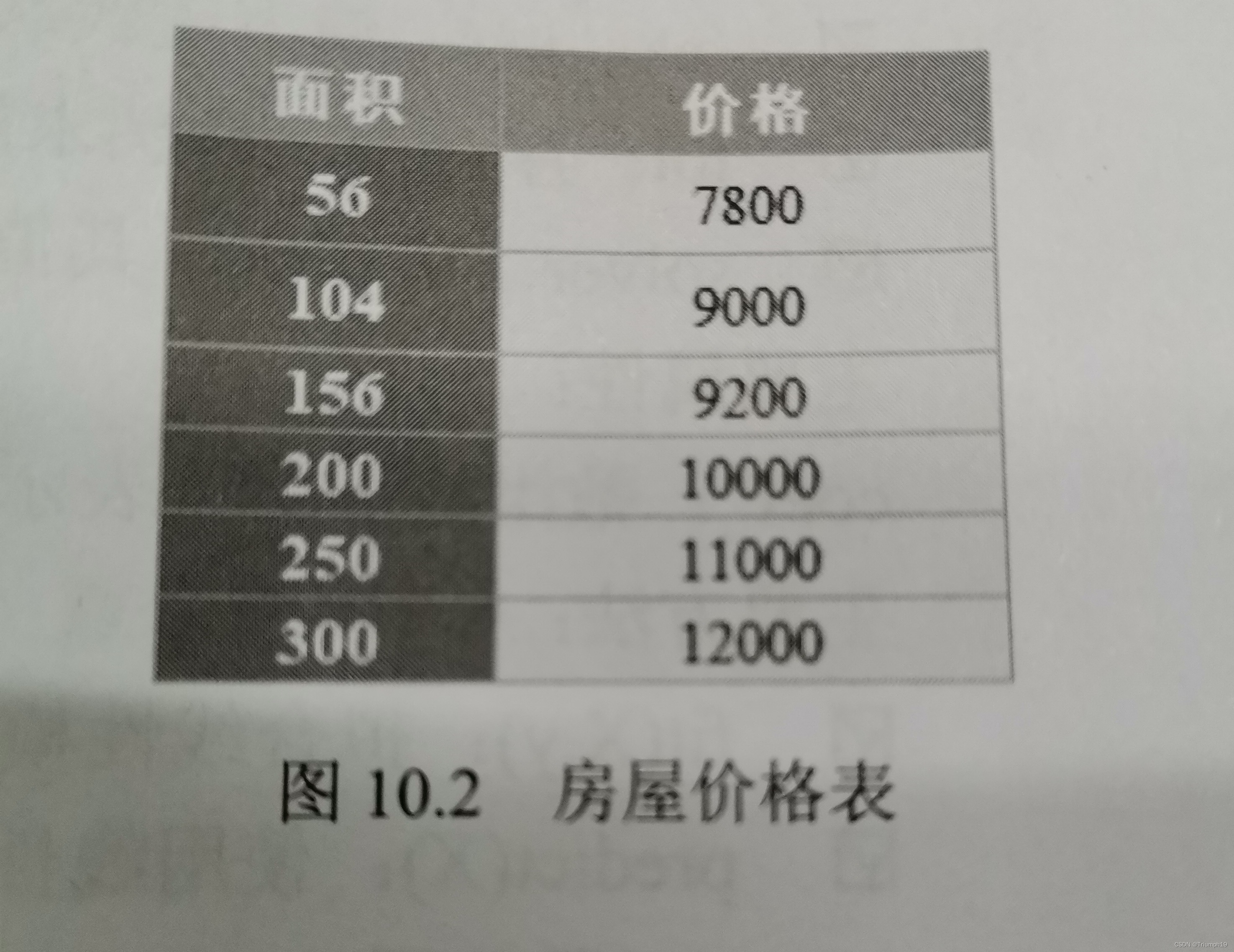
- �����������:
from sklearn import linear_model
import numpy as np
x=np.array([[1,56],[2,104],[3,156],[4,200],[5,250],[6,300]])
y=np.array([7800,9000,9200,10000,11000,12000])
clf = linear_model.LinearRegression()
clf.fit (x,y) #�������ģ��
k=clf.coef_ #�ع�ϵ��
b=clf.intercept_ #�ؾ�
x0=np.array([[7,170]])
#ͨ��������x0Ԥ��y0,y0=�ؾ�+Xֵ*�ع�ϵ��
y0=clf.predict(x0) #Ԥ��ֵ
print('�ع�ϵ��:',k)
print('�ؾ�:',b)
print('Ԥ��ֵ:',y0)
�ع�ϵ��: [1853.37423313 -21.7791411 ]
�ؾ�: 7215.950920245396
Ԥ��ֵ: [16487.11656442]
10.3.2 ��ع�
- ��ع�������С���˷��ع������,�����˶Ա�ʾ�ع�ϵ����L2
����Լ������ع�����������һ��,����ڶԻع�ϵ���Ĵ�Сʩ�������ơ���ع���Ҫʹ��linear_modelģ���Ridge()����ʵ�֡������:
linear_model.Ridge(alpha=1.0, fit_intercept=True,normalize=False,copy_X=True,max_iter=None,tol=0.001,solver="auto",random_state=None)
- alpha:Ȩ�ء�
- fit_intercept:������ֵ,�Ƿ���Ҫ����ؾ�,Ĭ��ֵΪTrue��
- normalize:���������������һ��,Ĭ��ֵΪFalse��
- copy_X:���ƻ�����д��
- max_iter:������������
- tol:������,�������ľ��ȡ�
- solver:�����,��ֵ����auto��svd��cholesky��sparse_cg��lsqr,Ĭ��ֵΪauto
- coef_:�������״,��ʾ���Իع�����Ļع�����
- ��Ҫ����
- fit(X,y):�������ģ�͡�
- predict(X):ʹ������ģ�ͷ���Ԥ�����ݡ�
- Ridg()����ʹ��fit()���������Իع�ģ�͵Ļع�ϵ���洢�����Ա����coef_�����С�
ʹ����ع麯��ʵ������Ԥ�ⷿ��(02)
- ʹ��Ridg()ʵ������Ԥ�ⷿ��,�����������:
from sklearn.linear_model import Ridge
import numpy as np
x=np.array([[1,56],[2,104],[3,156],[4,200],[5,250],[6,300]])
y=np.array([7800,9000,9200,10000,11000,12000])
clf = Ridge(alpha=1.0)
clf.fit(x, y)
k=clf.coef_ #�ع�ϵ��
b=clf.intercept_ #�ؾ�
x0=np.array([[7,170]])
#ͨ��������x0Ԥ��y0,y0=�ؾ�+Xֵ*б��
y0=clf.predict(x0) #Ԥ��ֵ
print('�ع�ϵ��:',k)
print('�ؾ�:',b)
print('Ԥ��ֵ:',y0)
�ع�ϵ��: [10.00932795 16.11613094]
�ؾ�: 6935.001421210872
Ԥ��ֵ: [9744.80897725]
10.4 ֧��������
- ֧��������(SVM)�����ڼලѧϰ�㷨,��Ҫ�������ࡢ�ع���쳣��⡣֧����������ķ������Ա���չ��������ع�����,�����������Ϊ֧�������ع顣
- ���ڽ���֧�������ع麯������LinearSVR()������LinearSVR()����һ��֧�������ع�ĺ���,֧�������ع鲻������������ģ��,���������ڶ����ݺ�����֮��ķ����Թ�ϵ���о���������ع���������,�Ӷ���߹㷺������,�����ά����,�����:
sklearn.svm.LinearSVR(epsilon=0.0,tol=0.0001,C=1.0,loss='epsilon_insensitive',fit_intercept=True,intercept_scaling=1.0,dual=True,verbose=0,random_state=None,max_iter=1000)
- epsilon:float����ֵ,Ĭ��ֵΪ0.0
- tol:float����ֵ,��ֹ�����ı�ֵ,Ĭ��ֵΪ0.0001
- C:float����ֵ,�������,�ò���Խ��,ʹ�õ�����Խ��,Ĭ��ֵΪ1.0
- loss:string����ֵ,��ʧ����,�ò�������������ѡ��:epsilon_insensitive:Ĭ��ֵ,��������ʧ(��SVR)��L1��ʧ��squared_epsilon_insensitive:ƽ����������ʧ��L2��ʧ��
- fit_intercept:boolean����ֵ,�Ƿ�����ģ�͵Ľؾࡣ�������ֵΪFalse,���ڼ�����ʹ�ýؾ�(������Ԥ���Ѿ�����)��Ĭ��ֵΪTrue��
- intercept_scaling:float����ֵ,��fit_interceptΪTrueʱ,ʵ������x��Ϊ[x,self.intercept_scaling]����ʱ�൱��������һ������,��������������ʵ�����dz���ֵ��
- dual:boolean����ֵ,ѡ���㷨�Խ����ż��ԭʼ�Ż����⡣������ֵΪTrueʱ,�ɽ����ż����;������ֵΪFalseʱ,�ɽ��ԭʼ���⡣Ĭ��ֵΪTrue��
- verbose:int����ֵ,�Ƿ���verbose���,Ĭ��ֵΪ0
- random_state:int����ֵ,�����������������,������������ϴʱʹ�á�Ĭ��ֵΪNone��
- max_iter:int����ֵ,Ҫ���õ�������������Ĭ��ֵΪ0
- ������Ҫ������:
�C coef_:����������Ȩ��,����array�������͡�
�C intercept_:���ߺ����еij���,����array�������͡�
��ʿ�ٷ���Ԥ��
- ͨ��Scikit-Learn�Դ������ݼ�����ʿ�ٷ��ۡ�,ʵ�ַ���Ԥ��,�����������:
from sklearn.svm import LinearSVR # �������Իع���
from sklearn.datasets import load_boston # ������ز�ʿ�����ݼ�
from pandas import DataFrame # ����DataFrame
boston = load_boston() # �������ز�ʿ�����ݶ���
# ����ʿ�ٷ������ݴ���ΪDataFrame����
df = DataFrame(boston.data, columns=boston.feature_names)
df
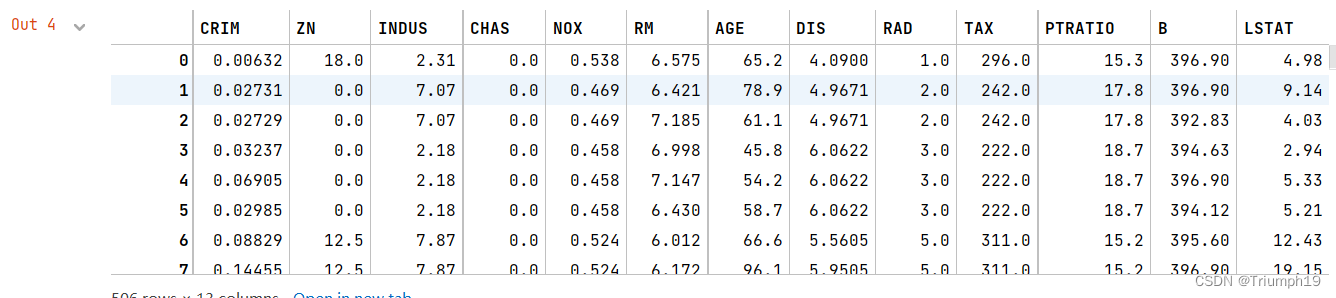
df.insert(0,'target',boston.target) # ���۸�������DataFrame������
df
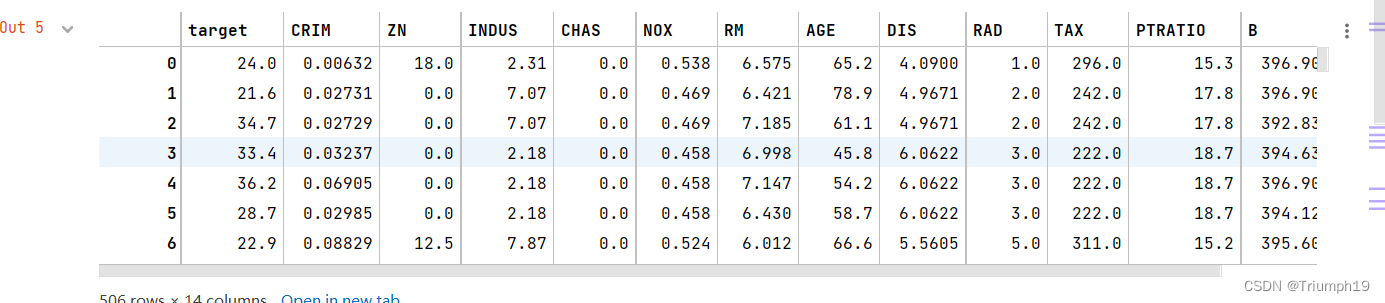
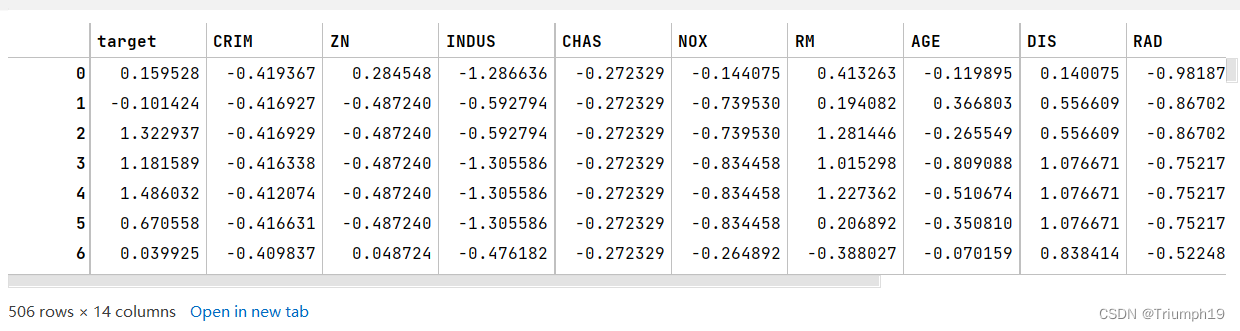
data_mean = df.mean() # ��ȡÿһ�е�ƽ��ֵ
data_std = df.std() # ��ȡ��ƫ��
data_train = (df - data_mean) / data_std # ���ݱ���
data_train
x_train = data_train[boston.feature_names].values # ��������,feature_names������ͼ�г���target��֮��������е���ֵ
y_train = data_train['target'].values # Ŀ������
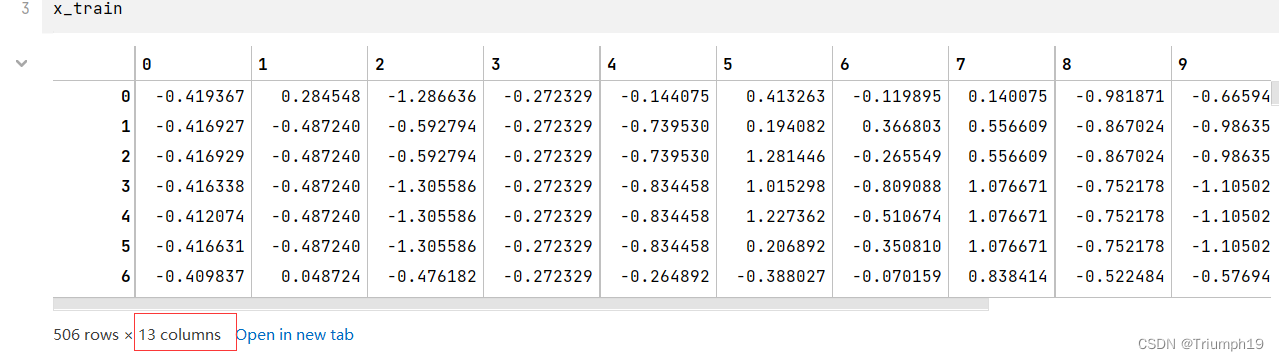
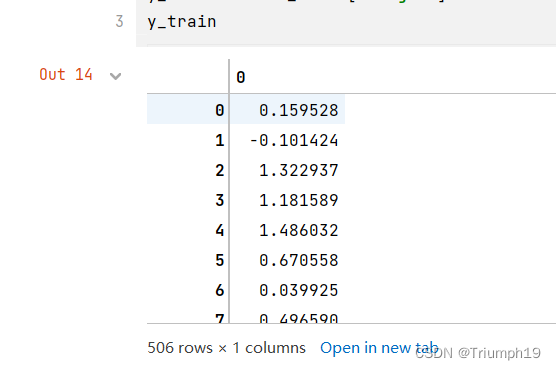
Ҳ��ʹ���б��ķ�ʽֱ����ȡ�����е���ֵ,����data_train[[��target��,��ZN��]]��values���ǻ�ȡtarget�к�ZN�е�����;data_train[[��target��:��ZN��]]��values�ǻ�ȡ��targer��ZNһ���������ݡ�
#%%
linearsvr = LinearSVR(C=0.1) # ����LinearSVR()����
linearsvr.fit(x_train, y_train) # ѵ��ģ��
# Ԥ��,����ԭ���
x = ((df[boston.feature_names] - data_mean[boston.feature_names]) / data_std[boston.feature_names]).values
x
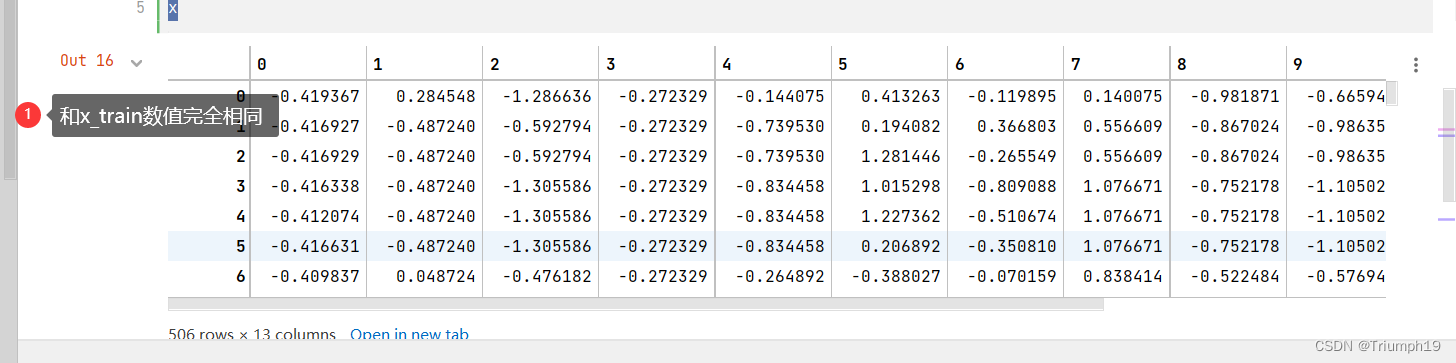
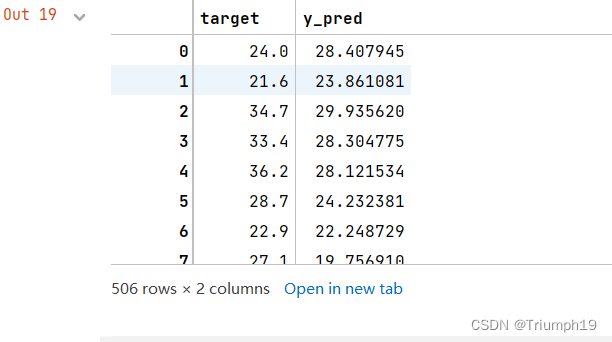
# ����Ԥ�ⷿ�۵���Ϣ��
df[u'y_pred'] = linearsvr.predict(x) * data_std['target'] + data_mean['target'] #���ǻ�ԭ����Ĵ���
df[['target','y_pred']] #��ȡ�����Ǽ۸��Ԥ��۸�
10.5 ����
10.5.1 ʲô�Ǿ���
- ���������ڷ���,��ͬ���Ǿ�����Ҫ�ֵ�����δ֪��,Ҳ����˵��֪��Ӧ����������,����ͨ��һ�����㷨�Զ����ࡣ��ʵ��Ӧ����,������һ������ijЩ�������Ƶ����ݽ��з�����֯�Ĺ���(��˵���ǽ��������ݾ���һ��),��ʾ��ͼ��ͼ10.3��ͼ10.4��ʾ��
- ������ҪӦ���������¡�
- ��ҵ:����������������ֲ�ͬ�Ŀͻ�Ⱥ,����ͨ������ģʽ�̻���ͬ�ͻ�Ⱥ��������
- ����:��������������Զ�ֲ�����ͶԻ�����з���,��ȡ����Ⱥ���нṹ����ʶ��
- ������ҵ:�������ͨ��һ���ߵ�ƽ���������������յ������ߵķ���,ͬʱ����סլ���͡���ֵ�͵���λ�����ж�һ�����еķ������顣
- ������:������������������Ͻ����ĵ����ࡣ
- ��������:��������ڵ���������վ�����ھ���Ҳ�Ǻ���Ҫ��һ������,ͨ�����������������������Ϊ�Ŀͻ�,�������ͻ��Ĺ�ͬ����,���Ը��õذ��������˽��Լ��Ŀͻ�,��ͻ��ṩ�����ʵķ���
10.5.2 �����㷨
- k-means�㷨��һ�־����㷨,����һ���ලѧϰ�㷨,Ŀ���ǽ����ƵĶ���鵽һ�����С����ڵĶ���Խ����,�����Ч��Խ�á�
- ��ͳ�ľ���������ַ�������η����������ܶȷ��������������ͻ���ģ�ͷ�����������Ҫ����k-means�����㷨,���ǻ��ַ����нϵ��͵�һ��,Ҳ���Գ�Ϊk��ֵ�����㷨���������ʲô��k��ֵ�����Լ�����㷨��
1.k-means����
- k-means����Ҳ��Ϊk��ֵ����,�������Ļ��־�����㷨,���ڼ���Чʹ������Ϊ���о����㷨��Ӧ����㷺��һ�֡�k��ֵ�����Ǹ���һ�����ݵ㼯�Ϻ���Ҫ�ľ�����Ŀk,k���û�ָ��,k��ֵ�㷨����ij�����뺯�����������ݷ���k�������С�
2.�㷨
- ���ѡȡk������Ϊ��ʼ����(���ļ��������е������),Ȼ�����ݼ��е�ÿ������䵽һ������,��������,Ϊÿ�����Ҿ������������,��������������������Ӧ�Ĵء���һ�����֮��,��ÿ���ص����ĸ���Ϊ�ô����е��ƽ��ֵ��������̽������ظ�ֱ������ij����ֹ��������ֹ���������������κ�һ����
- û��(����С��Ŀ)�������·������ͬ�ľ��ࡣ
- û��(����С��Ŀ)���������ٷ����仯��
- ���ƽ���;ֲ���С��
- ���:
"""
����k������Ϊ��ʼ����,�������ѡ��(λ�����ݱ߽���)
���κ�һ����Ĵط����������仯ʱ(��ʼ��ΪTrue)
�����ݼ���ÿ�����ݵ�,���·�������
��ÿ������
�������ĺ����ݵ�֮��ľ���
�����ݵ���䵽��������Ĵ�
��ÿһ����,����������е�ľ�ֵ������ֵ��Ϊ�µ�����
"""
- ͨ�����ϴ���������Ŷ��߶�k-means�����㷨�Ѿ����˳�������ʶ,����Python��Ӧ�ø��㷨�����ֶ���д����,��ΪPython������ģ��Scikit-Learn�Ѿ�������д����,�����ܺ��ȶ����ϱ��Լ�д�ĺõö�,ֻ���ڳ����е��ü���,û��Ҫ�Լ������ӡ�
10.5.3 ����ģ��
- Scikit-Learn��clusterģ�����ھ������,��ģ���ṩ�˺ܶ�����㷨,������Ҫ����KMeans����,�÷���ͨ��k-means�����㷨ʵ�־��������
- ���ȵ���sklearn-clusterģ���KMeans����,�����������:
from sklearn.cluster import KMeans
- ������,�ڳ����оͿ���ʹ��KMeans()�����ˡ�KMeans()�����������:
KMeans(n_clusters=8,init='k-means++',n_init=10,max_iter=300,tol=1e-4,precompute_distances='auto',verbose=0,random_state=None,copy_x=True,n����jobs=None,algorithm='auto')
- n_cluster:����,Ĭ��ֵΪ8,�����ɵľ�����,������������(centroid)����
- init:����ֵΪk-means++��random���ߴ���һ����ֵ������Ĭ��ֵΪk-means++��
�C k-means++:��һ������ķ���ѡ����ʼ���ĴӶ����ٵ������̵�������
�C random:�����ѵ��������ѡȡ��ʼ���ġ����������������,��Ӧ����shape(n_clusters,n_features)����ʽ,��������ʼ���ġ� - n_init:����,Ĭ��ֵΪ10,�ò�ͬ�����ij�ʼ��ֵ�����㷨�Ĵ�����
- max_iter:����,Ĭ��ֵΪ300,ÿִ��һ��k-means�㷨��������������
- tol:������,Ĭ��ֵΪ1e-4(��ѧ������,��1��10��-4�η�),�������ľ��ȡ�
- precompute_distances:����ֵΪauto��True����False������Ԥ�ȼ������,�����ٶȸ��쵱ռ�ø����ڴ档
�C auto:������������Ծ���������12e6(��12��10��6�η�),��Ԥ�ȼ�����롣
�C True:����Ԥ�ȼ�����롣
�C False:��Զ��Ԥ�ȹ��ƾ��롣 - verbose:����,Ĭ��ֵΪ0,�߳���ģʽ��
- random_state:���ͻ�����������͡����ڳ�ʼ�����ĵ�������(generator)�����ֵΪһ������,��ȷ��һ������(seed)��Ĭ��ֵΪNumPy���������������
- copy_x:������,Ĭ��ֵΪTrue�����ֵΪTrue,��ԭʼ���ݲ���ı�;���ֵΪFalse,���ֱ����ԭʼ����������,���ں�������ʱ���仹ԭ�������ڼ�������������ж����ݵľ�ֵ�ļӼ�����,�������ݷ��غ�,ԭʼ����ͬ�������ݿ��ܻ���ϸС���
- n_jobs:����,ָ���������õĽ����������ֵΪ-1,�������е�CPU��������;���ֵΪ1,���в��м���,�����������;���ֵС��-1,���õ���CPU��Ϊ(n_cpus+1+n_jobs),����n_jobs=-2,���õ���CPU��Ϊ��CPU����1��
- algorithm:��ʾk-means�㷨����,����ֵΪauto��full��elkan,Ĭ��ֵΪauto��
- ��Ҫ����:
- cluster_centers_:��������,��ʾ����صľ�ֵ������
- labels_:��������,��ʾÿ��������������������ǡ�
- inertia_:��������,��ʾÿ���������ݾ������Ǹ�������ص�����֮�͡�
- fit(X[,y]):����k-means���ࡣ
- fit_predict(X[,y]):��������IJ���ÿ����������Ԥ�����
- predict(X):��ÿ������������ӽ��Ĵء�
- score(X[,y]):���������
��һ�����ݾ��ࡣ
import numpy as np
from sklearn.cluster import KMeans
X=np.array([[1,10],[1,11],[1,12],[3,20],[3,23],[3,21],[3,25]])
kmodel = KMeans(n_clusters = 2) #����KMeans����ʵ�־���(����)
y_pred=kmodel.fit_predict(X) #Ԥ�����
print('Ԥ�����:',y_pred)
print('����صľ�ֵ����:','\n',kmodel.cluster_centers_)
print('�����:',kmodel.labels_)
Ԥ�����: [1 1 1 0 0 0 0]
����صľ�ֵ����:
[[ 3. 22.25]
[ 1. 11. ]]
�����: [1 1 1 0 0 0 0]
10.5.4 ��������������
- 10.5.3���о���һ���ľ���ʾ��,���Ǿ���Ч���������ԡ�����������ר�ŵľ����㷨�IJ�������,���Ը��õ�ڹ�;����㷨,չʾ����Ч����
- Scikit-Learn��make_blobs()�����������ɾ����㷨�IJ�������,ֱ�۵�˵,make_blobs()�������Ը����û�ָ�����������������ĵ���������Χ�����ɼ�������,��Щ���ݿ����ڲ��Ծ����㷨��Ч����
- make_blobs()�����������:
sklearn.datasets.make_blobs(n_samples=100,n_features=2,centers=3,cluster_std=1.0,center_box=(-10.0,10.0),shuffle=True,random_state=None)
- n_samples:�����ɵ�������������
- n_features:ÿ����������������
- centers:�������
- cluter_std:ÿ�����ķ���,����,������������,����һ�����һ����и���ķ���,���Խ�cluster_std����Ϊ[1.0,3.0]��
�������ھ���IJ�������
- �������ھ��������(500������,ÿ����������������),�����������:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
x,y = make_blobs(n_samples=500, n_features=2, centers=3)
- ������,ͨ��KMeans()�����Բ������ݽ��о���,�����������:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=4, random_state=9).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
- �����,������:
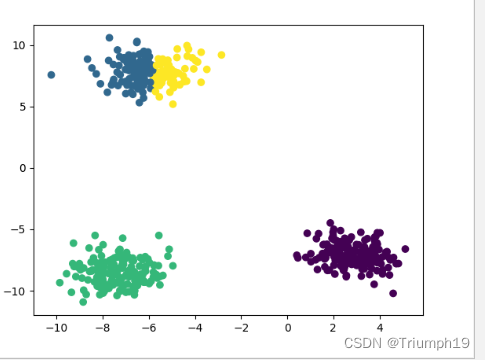
- �ӷ��������֪:���Ƶ����ݾ���һ��,�ֳ���4��,Ҳ����4��,������ɫ��ʾ,����ȥ����ֱ�ۡ�
10.6 ��
- ͨ�����µ�ѧϰ,�ܹ��˽����ѧϰScikit-Learnģ��,��ģ������������㷨ģ��,���½������˼�������ģ�Ͳ���Ͽ���ʾ��,����ʹ�����ܹ���������,�����������ģ�͵��÷�,��Ϊ����ѧϰ���ݷ�����Ԥ����Ŀ�������õĻ�����