����Ŀ¼
ǰ��
ResNet��һ�־���������(CNN)�ܹ�,���˷��� "�ݶ���ʧ "����,ʹ�ù������ж����ǧ��������������Ϊ����,���������ڽ�dz�����硣
ͬʱ,������VGG16ʹ����ͬ�����ݼ�,����������������ҵ���һƪ����CV-Model��3��:VGG16��ͬ,���п������ĵط�,���Խ���һЩ�ο���
�й�ResNet�й����ĵķ������Բο��ҵ���һƪ����CV-Paper��1��:Deep Residual Learning for Image Recognition
1. ���û���
1.1. ��������Ŀ�
import numpy as np
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
import time
import matplotlib.pyplot as plt
RANDOM_SEED = 123
BATCH_SIZE = 256
NUM_EPOCHS = 50
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
DEVICE
1.2. �������ݼ�
1.2.1. ��ѵ��������֤��
def get_train_valid_loader(data_dir,
batch_size,
random_seed,
valid_size=0.1,
shuffle=True,
num_workers=0):
# ���ݼ���ÿ��ͨ�� (R, G, B) ��ƽ��ֵ�ͱ�ƫ�����������normalize��
normalize = transforms.Normalize(
mean=[0.4914, 0.4822, 0.4465],
std=[0.2023, 0.1994, 0.2010],
)
# ������֤����transforms
valid_transform = transforms.Compose([
# ����ͼƬ��С
transforms.Resize((120, 120)),
# ����ü�
transforms.RandomCrop((110, 110)),
transforms.ToTensor(),
normalize,
])
# ����ѵ������transforms
train_transform = transforms.Compose([
# ����ͼƬ��С
transforms.Resize((120, 120)),
# ����ü�
transforms.RandomCrop((110, 110)),
transforms.ToTensor(),
normalize,
])
# �������ݼ�
train_dataset = datasets.CIFAR10(
root=data_dir, train=True,
download=True, transform=train_transform,
)
valid_dataset = datasets.CIFAR10(
root=data_dir, train=True,
download=True, transform=valid_transform,
)
# ��ȡѵ�����ı�ǩ
num_train = len(train_dataset)
indices = list(range(num_train))
# �ҵ�ѵ��������֤�����ֵ�����
split = int(np.floor(valid_size * num_train))
# �������ݼ�,�����ж��ѵ��,ÿ��ѵ����õ����ݼ����в�ͬ
if shuffle:
np.random.seed(random_seed)
np.random.shuffle(indices)
# ����ѵ��������֤��
train_idx, valid_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, num_workers=num_workers, drop_last=True, sampler=train_sampler)
valid_loader = torch.utils.data.DataLoader(
valid_dataset, batch_size=batch_size, num_workers=num_workers, sampler=valid_sampler)
return train_loader, valid_loader
1.2.2. �����Լ�
def get_test_loader(data_dir,
batch_size,
shuffle=False,
num_workers=0):
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)
# ������Լ���transform
transform = transforms.Compose([
# ����ͼƬ��С
transforms.Resize((120, 120)),
# ����ü�
transforms.RandomCrop((110, 110)),
transforms.ToTensor(),
normalize,
])
dataset = datasets.CIFAR10(
root=data_dir, train=False,
download=True, transform=transform,
)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, num_workers=num_workers, shuffle=shuffle)
return data_loader
1.2.3. �������ݼ�
# CIFAR10 dataset
train_loader, valid_loader = get_train_valid_loader(data_dir = 'autodl-tmp/data/', batch_size = BATCH_SIZE, random_seed = RANDOM_SEED)
test_loader = get_test_loader(data_dir = 'autodl-tmp/data/', batch_size = BATCH_SIZE)
# ��֤���ݼ��е�����
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
2. �������
2.1. ������Ľṹ
Resnet(Deep residual network, ResNet),��Ȳв�������,������������ʷ�ھ��л�ʱ������������硣��Alexnet��VGG��ͬ����,����ṹ�Ͼ��кܴ�ĸı�,�ڴ��Ϊ����������������������ڲ�������������ȵ�ʱ��,��ҷ�������������ȵ�����,�����Ч�����Խ��Խ��,����������������˻�����,80��������30���Ч������,���������ڵ��ݶ���ʧ�ͱ�ը����Խ��Խ����,��ʹ��ѵ��һ����������ѧϰģ�ͱ�ø��Ӽ���,�����������,����ṹͼ
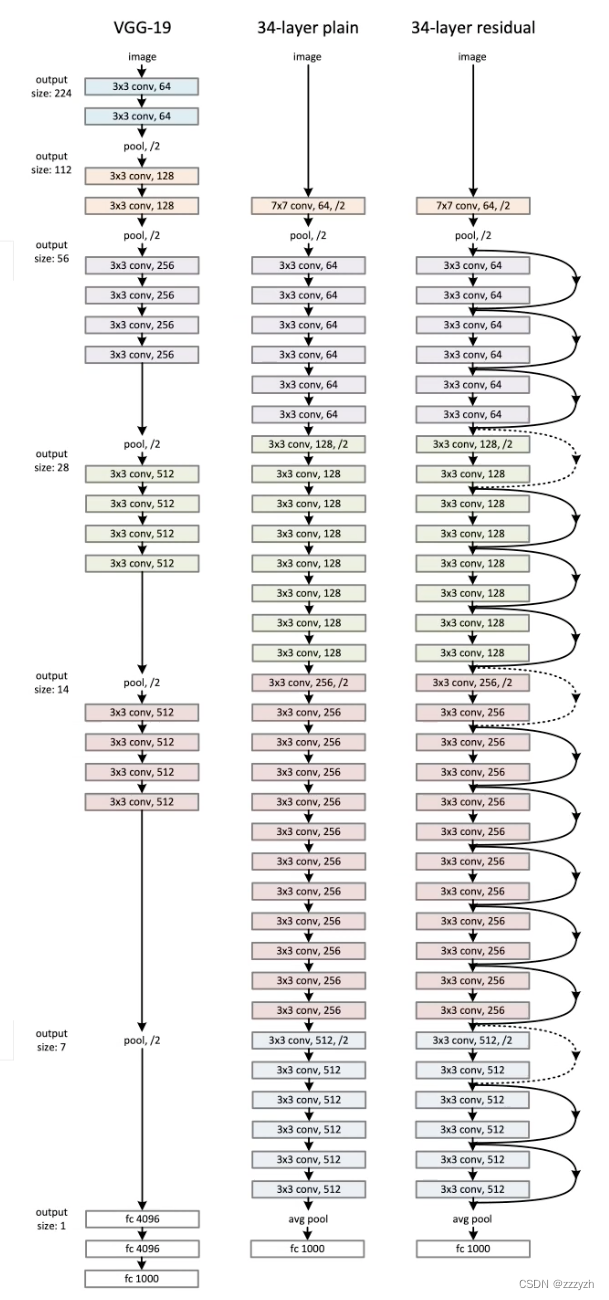
Ϊ�˽���������,����ʹ�ö���һ��IJο�������ijһ����������ResNet��,ǰһ������,��Ϊ�в�,�����ӵ���ǰ�������С���ͼֱ�۵�չʾ����һ����
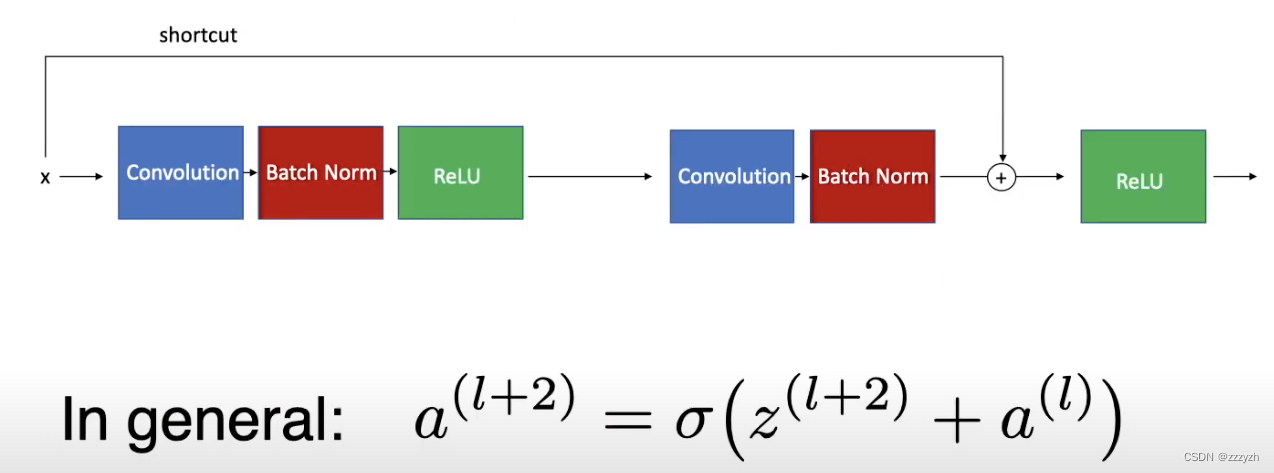
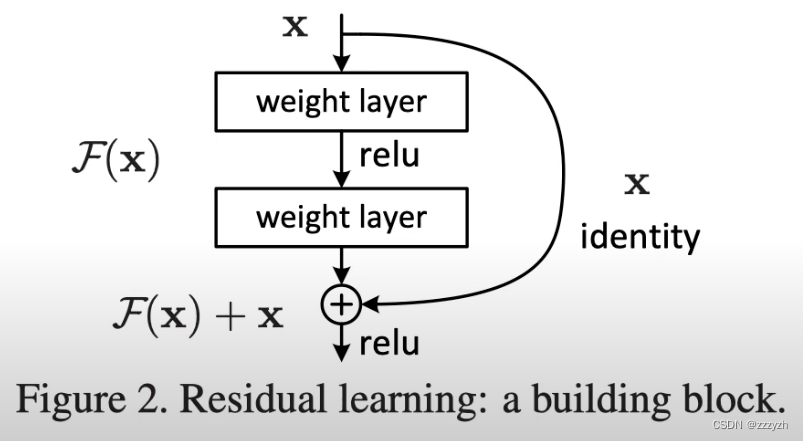
Residual Block
Residual Block��ResNet����Ļ��������顣Ϊ��ʹ�dz���ľ����ṹ��Ϊ����,ResNet��һ��������������������м����롣�������ӵ�Ŀ����������ƽ�����ݶ�����,��ȷ����Ҫ������һֱ���������һ�㡣���Dz�����������Ӽ��㸺�ɡ���ͼ˵����һ���в��,���С�
- x��ResNet�������Cǰ��������
- F(x)��һ���м����������С��������
2.2. ResNet
2.2.1. BasicBlock
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
return torch.nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
return torch.nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
"""ʵ��ResNet�Ļ�����"""
expansion: int = 1
def __init__(self, in_planes, planes, stride=1, down_sample=None,
groups=1, base_width=64, dilation=1, norm_layer=None):
"""
in_channels:�˿������ͨ����
planes:�����ͨ����
stride:�ڵ�һ��������IJ���
down_sample:�Ƿ�����²���
groups:�������
base_width:����
dilation:�ն�����
norm_layer:������
"""
super().__init__()
if norm_layer is None:
norm_layer = torch.nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# ������(stride)��Ϊ1ʱ,self.conv1 �� self.down_sample ����Ҫ����������²���
self.conv1 = conv3x3(in_planes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = torch.nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.down_sample = down_sample
self.stride = stride
def forward(self, x):
"""��������ǹ���в��Ļ����ṹ"""
# ���к��ӳ��
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# ��� down_sample ���ǿ�ֵ(��Ҫ�²���)�Ļ�
# ���ں����²�������Ӧ�IJ���,��Ϊ����������ģ�鲿���Ѿ�˵��,
# �����߲���,����Ϊͨ������һ��,Ҫ�����²�������,ʹ��ͨ����һ�¡�
if self.down_sample is not None:
identity = self.down_sample(x)
# ���˻����ṹ��������뱾�ṹ������һ���������е����γ����յ����
out += identity
out = self.relu(out)
# ���ش˽ṹ������ Ҳ������һ���в��Ļ����ṹ������
return out
- nn.ReLU(inplace=True)
inplaceΪTrue,������õ���ֱֵ�Ӹ���֮ǰ��ֵ- �����ļ�����������Ӱ�졣����in-place������Խ�ʡ��(��)��,ͬʱ������ʡȥ����������ͷ��ڴ��ʱ�䡣���ǻ��ԭ��������,ֻҪ������������á�
- ��˵�inplace=Trueʱ,���ǶԴ��ϲ�����nn.Conv2d�д���������tensorֱ�ӽ�����,�����ܹ���ʡ�����ڴ�,���ö�洢����������
- down_sample(�²���)
����һ��ͼ��I�ߴ�ΪM x N,�������s���²���,���õ�(M/s) * (N/s)�ߴ�ĵ÷ֱ���ͼ��,��ȻsӦ����M��N�Ĺ�Լ������,������ǵ��Ǿ�����ʽ��ͼ��,���ǰ�ԭʼͼ��s*s�����ڵ�ͼ����һ������,������ص��ֵ���Ǵ������������صľ�ֵ- ʹ�óػ� pooling(�ػ� / ������) �ļ����²���,Ŀ�ľ�����������������ά�Ȳ�������Ч��Ϣ,һ���̶��ϱ������ϡ�
- �������²����㷨
- farthest point sampling(FPS):������ֲ�����,ʱ�临�Ӷȸ�
- grid sampling(GS):������ֲ���Ϊ����,ʱ�临�Ӷ�һ��,������������в�ȷ����
- random sampling(RS):������ֲ����������,ʱ�临�Ӷȵ�
2.2.2. Bottleneck
# ��չResNet����Ӧ������ģ��
class Bottleneck(torch.nn.Module):
"""
ע��:ԭ������,�����߲в�ṹ������֧��,��һ��1x1�������stride��2,�ڶ���3x3������stride��1��
����pytorch�ٷ�ʵ�ֹ������ǵ�һ��1x1�������stride��1,�ڶ���3x3������stride��2,
��ô���ĺô����ܹ���top1���������0.5%��ȷ�ʡ�
"""
# ͨ�����仯��ϵ��
expansion = 4
def __init__(self, in_channels, planes, stride=1, down_sample=None,
groups=1, base_width=64, dilation=1, norm_layer=None):
"""
in_channels:�˿������ͨ����
channels:�����ͨ����
stride:�ڵ�һ��������IJ���
down_sample:�Ƿ�����²���
groups:�������
base_width:����
dilation:�ն�����
norm_layer:������
"""
super().__init__()
# �������ȹ�һ��
if norm_layer is None:
norm_layer = torch.nn.BatchNorm2d # ʹһ��feature map�����ֵΪ0,����Ϊ1�ķֲ�����
# resnext50_32x4d ��resnext101_32x8d ��ʹ��
width = int(planes * (base_width / 64.)) * groups
# ����������������
self.conv1 = conv1x1(in_channels, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = torch.nn.ReLU(inplace=True)
# �²���
self.down_sample = down_sample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity
out = self.relu(out)
return out
2.2.3. ResNet
class ResNet(torch.nn.Module):
def __init__(self, block, layers, num_classes, zero_init_residual=False, groups=1,
width_per_group=64, replace_stride_with_dilation=None, norm_layer=None):
"""
block:����ʵ����BasicBlock,������һ���ִ���Ļ�����
layers:��ĸ�����Ϊһ���б�,�б�����ΪResNet�Ŀ���
num_classes:��������
zero_init_residual:�в��ʼ��
groups:�������
width_per_group:
replace_stride_with_dilation:�滻���ų���
norm_layer:����һ��
"""
super().__init__()
if norm_layer is None:
norm_layer = torch.nn.BatchNorm2d
self._norm_layer = norm_layer
self.in_channels = 64
self.dilation = 1
# Ԫ���е�ÿ��Ԫ�ض���ʾ�����Ƿ�Ӧ�������ž���������2x2�IJ���
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = torch.nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.in_channels)
# �������,���ӷ����Ա���
self.relu = torch.nn.ReLU(inplace=True)
self.max_pool = torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# ����ResNet��4��block [3, 4, 6, 3]
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
# ����Ӧ��ƽ���ػ�
self.avg_pool = torch.nn.AdaptiveAvgPool2d((1, 1))
# ȫ���Ӳ�
self.fc = torch.nn.Linear(512 * block.expansion, num_classes)
# ����ÿһ��ģ�����ģ���Ȩ�صij�ʼ��
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (torch.nn.BatchNorm2d, torch.nn.GroupNorm)):
torch.nn.init.constant_(m.weight, 1)
torch.nn.init.constant_(m.bias, 0)
# ��ÿ��ʣ���֧�е����һ��BN����Zero-initialize
# ����,�в��֧���㿪ʼ,ÿ���в�����Ϊ����һ�����ݡ�
# �����ʹģ�����0.2~0.3%
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
torch.nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
torch.nn.init.constant_(m.bn2.weight, 0)
# �˺���Ϊ����ÿ��block�ĺ���
def _make_layer(self, block, planes, blocks,
stride=1, dilate=False):
norm_layer = self._norm_layer
down_sample = None
# ������Ϊ1,��Ϊ��Ҫdown_sample���ж��ڲ�ͬ�в��֮���ͳһ,��һ���в�������뱾�в���������߱���һ��
# ���������Ϊ1,Ҳ����ÿ���ֵĵ�һ��������ĵ�һ��������,��������ͨ����ͨ����ƥ��,Ҳ����ResNet���������ͨ���������仯
# ����ͨ������ƥ��,����Ҫ�����²���,ͳһͨ����
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.in_channels != planes * block.expansion:
down_sample = torch.nn.Sequential(
conv1x1(self.in_channels, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
# ����һ�����б�
layers = []
# ���ӻ�����
layers.append(block(self.in_channels, planes, stride, down_sample, self.groups,
self.base_width, previous_dilation, norm_layer))
# ע��,ֻ���ڲ�ͬblock������²Ž��д˲���,��Ϊ�ϸ�block���¸�block��channel��һ��
self.in_channels = planes * block.expansion
# ����ѭ��,ͨ��С�Ļ�����,����һ��block
for _ in range(1, blocks):
layers.append(block(self.in_channels, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return torch.nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
2.2.4. ��������ܹ�
## ���ڲ�ͬ���resnet���� ,������IJ����趨
def resnet34(num_classes=1000):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def resnet50(num_classes=1000):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def resnet101(num_classes=1000):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def resnext50_32x4d(num_classes=1000):
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000):
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
groups=groups,
width_per_group=width_per_group)
3. ѵ��ģ��
3.1. ʵ����ģ�Ͳ������Ż���
��ResNet-34��Ϊʾ��
# ResNet-34
model = ResNet(BasicBlock, layers=[3, 4, 6, 3], num_classes=10)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.1)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.1,
mode='max',
verbose=True)
3.2. �������ȷ�ȵĺ���
def compute_accuracy(model, data_loader, device):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.float().to(device)
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
num_examples += targets.size(0)
# �ۼ�ÿ���ε�Ԥ����ȷ��������,�Ի��һ���������ڵ�����Ԥ����ȷ��������
correct_pred += (predicted_labels == targets).sum().item()
return correct_pred/num_examples * 100
3.3. ѵ��ģ��
def train_model(model, num_epochs, train_loader,
valid_loader, test_loader, optimizer,
device, logging_interval=50,
scheduler=None,
scheduler_on='valid_acc'):
# ϵͳʱ�ӵ�ʱ���
start_time = time.time()
minibatch_loss_list, train_acc_list, valid_acc_list = [], [], []
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
# ǰ�������
logits = model(features)
loss = torch.nn.functional.cross_entropy(logits, targets)
optimizer.zero_grad()
loss.backward()
# ����ģ�Ͳ���
optimizer.step()
# ��ӡ��־
minibatch_loss_list.append(loss.item())
if not batch_idx % logging_interval:
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Batch {batch_idx:04d}/{len(train_loader):04d} '
f'| Loss: {loss:.4f}')
model.eval()
with torch.no_grad():
train_acc = compute_accuracy(model, train_loader, device=device)
valid_acc = compute_accuracy(model, valid_loader, device=device)
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Train: {train_acc :.2f}% '
f'| Validation: {valid_acc :.2f}%')
train_acc_list.append(train_acc)
valid_acc_list.append(valid_acc)
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
if scheduler is not None:
if scheduler_on == 'valid_acc':
scheduler.step(valid_acc_list[-1])
elif scheduler_on == 'minibatch_loss':
scheduler.step(minibatch_loss_list[-1])
else:
raise ValueError(f'Invalid `scheduler_on` choice.')
# ��������ʱ��
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')
test_acc = compute_accuracy(model, test_loader, device=device)
print(f'Test accuracy {test_acc :.2f}%')
return minibatch_loss_list, train_acc_list, valid_acc_list
# ѵ��ģ��
minibatch_loss_list, train_acc_list, valid_acc_list = train_model(
model=model,
num_epochs=NUM_EPOCHS,
train_loader=train_loader,
valid_loader=valid_loader,
test_loader=test_loader,
optimizer=optimizer,
device=DEVICE,
scheduler=scheduler,
scheduler_on='valid_acc',
logging_interval=100)
# ����ģ�Ͳ���
torch.save(model.state_dict(), 'model/VGG16/vgg_16_model.pth') # ֻ����ģ�͵IJ���,������ģ��
torch.save(optimizer.state_dict(), 'model/VGG16/vgg_16_optimizer.pth') # �����Ż����IJ���,��ѧϰ�ʵ�
3.4. ����ѵ����ʧ����
def plot_training_loss(minibatch_loss_list, num_epochs, iter_per_epoch, averaging_iterations=100):
plt.figure()
ax1 = plt.subplot(1, 1, 1)
ax1.plot(range(len(minibatch_loss_list)),
(minibatch_loss_list), label='Minibatch Loss')
if len(minibatch_loss_list) > 1000:
ax1.set_ylim([
0, np.max(minibatch_loss_list[1000:])*1.5
])
ax1.set_xlabel('Iterations')
ax1.set_ylabel('Loss')
ax1.plot(np.convolve(minibatch_loss_list,
np.ones(averaging_iterations,)/averaging_iterations,
mode='valid'),
label='Running Average')
ax1.legend()
# ����˫������
ax2 = ax1.twiny()
newlabel = list(range(num_epochs+1))
newpos = [e*iter_per_epoch for e in newlabel]
ax2.set_xticks(newpos[::10])
ax2.set_xticklabels(newlabel[::10])
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 45))
ax2.set_xlabel('Epochs')
ax2.set_xlim(ax1.get_xlim())
plt.tight_layout()
plt.savefig("model/VGG16/plot_training_loss.pdf")
plot_training_loss(minibatch_loss_list=minibatch_loss_list,
num_epochs=NUM_EPOCHS,
iter_per_epoch=len(train_loader),
averaging_iterations=200)
plt.show()
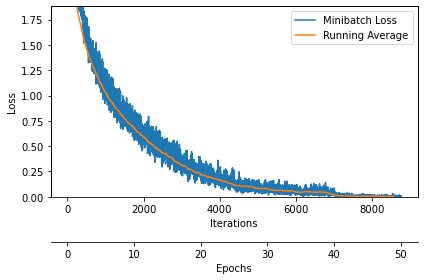
3.5. ����ȷ������
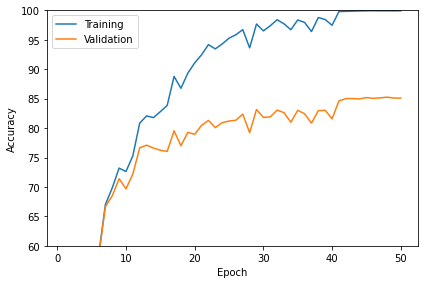
def plot_accuracy(train_acc_list, valid_acc_list):
num_epochs = len(train_acc_list)
plt.plot(np.arange(1, num_epochs+1),
train_acc_list, label='Training')
plt.plot(np.arange(1, num_epochs+1),
valid_acc_list, label='Validation')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig("model/VGG16/plot_acc_training_validation.pdf")
plot_accuracy(train_acc_list=train_acc_list,
valid_acc_list=valid_acc_list)
plt.ylim([60, 100])
plt.show()
4. Ԥ��
4.1. ʾ��
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
for t, m, s in zip(tensor, self.mean, self.std):
t.mul_(s).add_(m)
return tensor
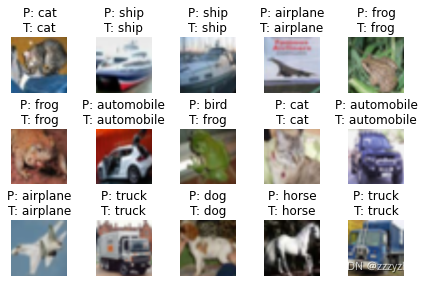
def show_examples(model, data_loader, unnormalizer=None, class_dict=None):
for batch_idx, (features, targets) in enumerate(data_loader):
with torch.no_grad():
features = features
targets = targets
logits = model(features)
predictions = torch.argmax(logits, dim=1)
break
fig, axes = plt.subplots(nrows=3, ncols=5,
sharex=True, sharey=True)
if unnormalizer is not None:
for idx in range(features.shape[0]):
features[idx] = unnormalizer(features[idx])
nhwc_img = np.transpose(features, axes=(0, 2, 3, 1))
if nhwc_img.shape[-1] == 1:
nhw_img = np.squeeze(nhwc_img.numpy(), axis=3)
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhw_img[idx], cmap='binary')
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
else:
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhwc_img[idx])
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
plt.tight_layout()
plt.show()
model.cpu()
unnormalizer = UnNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
class_dict = {0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'}
show_examples(model=model, data_loader=test_loader, unnormalizer=unnormalizer, class_dict=class_dict)
4.2. ��ӡ����
from itertools import product
def compute_confusion_matrix(model, data_loader, device):
all_targets, all_predictions = [], []
with torch.no_grad():
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
all_targets.extend(targets.to('cpu'))
all_predictions.extend(predicted_labels.to('cpu'))
all_predictions = all_predictions
all_predictions = np.array(all_predictions)
all_targets = np.array(all_targets)
class_labels = np.unique(np.concatenate((all_targets, all_predictions)))
if class_labels.shape[0] == 1:
if class_labels[0] != 0:
class_labels = np.array([0, class_labels[0]])
else:
class_labels = np.array([class_labels[0], 1])
n_labels = class_labels.shape[0]
lst = []
z = list(zip(all_targets, all_predictions))
for combi in product(class_labels, repeat=2):
lst.append(z.count(combi))
mat = np.asarray(lst)[:, None].reshape(n_labels, n_labels)
return mat
def plot_confusion_matrix(conf_mat,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=False,
show_absolute=True,
show_normed=False,
class_names=None):
if not (show_absolute or show_normed):
raise AssertionError('Both show_absolute and show_normed are False')
if class_names is not None and len(class_names) != len(conf_mat):
raise AssertionError('len(class_names) should be equal to number of'
'classes in the dataset')
total_samples = conf_mat.sum(axis=1)[:, np.newaxis]
normed_conf_mat = conf_mat.astype('float') / total_samples
fig, ax = plt.subplots(figsize=figsize)
ax.grid(False)
if cmap is None:
cmap = plt.cm.Blues
if figsize is None:
figsize = (len(conf_mat)*1.25, len(conf_mat)*1.25)
if show_normed:
matshow = ax.matshow(normed_conf_mat, cmap=cmap)
else:
matshow = ax.matshow(conf_mat, cmap=cmap)
if colorbar:
fig.colorbar(matshow)
for i in range(conf_mat.shape[0]):
for j in range(conf_mat.shape[1]):
cell_text = ""
if show_absolute:
cell_text += format(conf_mat[i, j], 'd')
if show_normed:
cell_text += "\n" + '('
cell_text += format(normed_conf_mat[i, j], '.2f') + ')'
else:
cell_text += format(normed_conf_mat[i, j], '.2f')
ax.text(x=j,
y=i,
s=cell_text,
va='center',
ha='center',
color="white" if normed_conf_mat[i, j] > 0.5 else "black")
if class_names is not None:
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=90)
plt.yticks(tick_marks, class_names)
if hide_spines:
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.yaxis.set_ticks_position('left')
ax.xaxis.set_ticks_position('bottom')
if hide_ticks:
ax.axes.get_yaxis().set_ticks([])
ax.axes.get_xaxis().set_ticks([])
plt.xlabel('predicted label')
plt.ylabel('true label')
return fig, ax
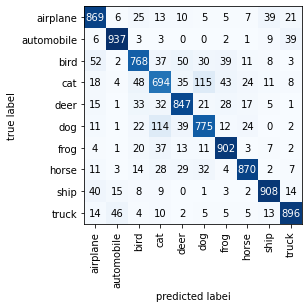
mat = compute_confusion_matrix(model=model, data_loader=test_loader, device=torch.device('cpu'))
plot_confusion_matrix(mat, class_names=class_dict.values())
plt.show()
�ܽ�
�ڷ��������л�����ݶ���ʧ������������ѵ���㷨��ͼ�ҵ�ʹ��ʧ�����ﵽ��Сֵ��Ȩ��ʱ,�����̫��IJ�,�ݶȾͻ��÷dz�С,ֱ����ʧ,�Ż�����������
ResNetʹ�� "���ݽݾ����� "�����������⡣���IJ�����Ϊ�����Ρ�
- �ڵ�һ����,ResNet�����˶�����δʹ�õIJ�,��������Щ��,����ʹ��֮ǰ��ļ������
- �ڵڶ�����,�����ٴ�����ѵ��,"���� "�����㱻��չ����ʹ��̽�������ռ���������ֳ�Ϊ����,����Щ������dz���������ṹ�лᱻ��©��