ShuffleNet V2 概述
论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design


shuffleNet v2这篇论文比较硬核,提出了不少新的思想,推荐大家可以看看论文原文。主要思想包括:
模型的计算复杂度不能只看FLOPs,还需要参考一些其他的指标作者提出了4条如何设计高效网络的准则基于该准则提出了新的block设置
FLOPS网上有两种:FLOPS和 FLOPs:
FLOPS:全大写,指每秒浮点运算次数,可以理解为计算的速度,是衡量硬件性能的一个指标 (硬件)FLOPs:s小写,指浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度,(模型)在论文中常用GFLOPs(1 GFLOPs = 10^9FLOPs)
ShuffleNet V2 论文观点
(1) FLOPS不能准确的评价模型的推力的时间,还有其他因素影响
在我们网络设计过程中,比如mobienet, shuffleNet v1我们经常使用FLOPs,FLOPs其实是衡量模型运算和复杂度的间接指标,它并不是一个直接的指标。因为我们在实际使用过程中,我们直接看的是模型的推理时间来看运算快慢,这是一个直接的指标。
- 在影响我们模型推理速度的众多因素之间,其实我们并不能光看
FLOPs,还有其他需要被考虑进来的因素,比如说memory access cost (MAC)(内存访问的时间成本),它占我们模型推理中占非常大的一个比率。

- 在上图中给的时间统计,前所说的
FLOPs其实主要还是计算关于卷积相关的参数指标,但是在ShuffleNet V1 GPU统计到,卷积操作其实只占时间消耗的50%,另外50%是用来处理其他任务,因此我们不能单独使FLOPs来评判我们模型的计算量和它的复杂度。 - 除了
内存访问时间成本MAC,作者还提到另外一个需要被考虑进来的因素叫做degree of parallelism(并行等级),在相同FLOPs下并行更高的模型,其实要比并行度低的模型速度快,这进一步说明了我们不能光看FLOPS。 - 接下来作者提到,相同的
FLOPs在不同的平台上(如GPU以及ARM平台上的CPU),他们的执行时间也是不一样的。从上图可以看出,对于ShuffleNet v1,在同样的FLOPS下,GPU上卷积运算占50%,在ARM上卷积运算占87%,所以在不同的平台上它的执行消耗时间也都是不一样的。 - 通过上图,我们可以发现其实
卷积占据了模型推理的绝大部分时间,其他的操作比如:Data I/O,data shuffle,element-wise等等,他们也占据了相当大的一部分推理时间。因此我们的FLOPS并不能正确的评判模型的推理时间。
如何设计高效网络的4条建议
作者提出了如何设计高效网络的4条建议:
G1:Equal channel width minimizes memory access cost (MAC)
当卷积层的输入特征矩阵与输出特征矩阵相等的时候,MAC最小(保持FLOPs不变时),这里针对1x1的卷积层

B
=
h
w
c
1
c
2
B=hwc_1c_2
B=hwc1?c2?
其中MAC值是如何计算得到的呢?,作者给出如下计算过程:

- M A C = h w ( c 1 + c 2 ) + c 1 ? c 2 MAC=hw(c_1+c_2)+c_1*c_2 MAC=hw(c1?+c2?)+c1??c2?, h w c 1 hwc_1 hwc1?代表输入特征矩阵的内存消耗, h w c 2 hwc_2 hwc2?代表输出特征矩阵的内存消耗。后面的 c 1 ? c 2 c1*c2 c1?c2表示卷积核的内存消耗
- 根据算数不等式:
c
1
+
c
2
2
≥
c
1
c
2
\frac{c_1+c_2}{2} ≥ \sqrt{c_1c_2}
2c1?+c2??≥c1?c2??,带入
MAC计算公式可得: M A C ≥ 2 h w c 1 c 2 + c 1 c 2 MAC ≥2hw\sqrt{c_1c_2}+c_1c_2 MAC≥2hwc1?c2??+c1?c2?,并且根据 B = h w c 1 c 2 B=hwc_1c_2 B=hwc1?c2?,最终可得到 M A C ≥ 2 h w B + B h w MAC ≥2\sqrt{hwB}+\frac{B}{hw} MAC≥2hwB?+hwB? ,不等式相当当 c 1 = c 2 c_1=c_2 c1?=c2?的时候,MAC最小
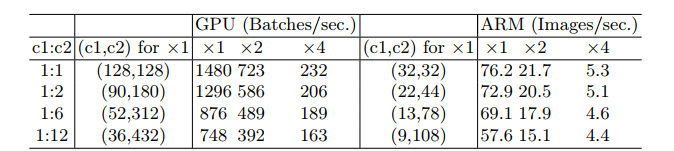
作者在FLOPs保持不变的情况下,探究了 c 1 c 2 \frac{c_1}{c_2} c2?c1?? 对我们推理速度的影响,这里看GPU x1 与CPU x1这块,后面几个都是一样的,我们只关注规律就可以。 - 当c1/c2=1:1的时候,我们在GPU上每秒能够推理1480个Batches;当c1/c2=1:2的时候每秒能够推理1296个Batches,可以看出随着c1,c2两者的比值相差越大,推理速度越慢,同样在CPU上也是一样的。
G2: Excessive group convolution incresses MAC
- 当
GConv的groups增大时(保持FLOPs不变时),MAC也会增大

其中 h w c 1 c 2 / g hwc_1c_2/g hwc1?c2?/g (FLOPs) ,由于当输入特征矩阵一定的时候 h w c 1 hw_c1 hwc?1是个常数想,FLOPs一定的时候B也是一个常数项。因此随着g越来越大,MAC值也越大。
作者针对第二点,也做了一系列的实验。

通过保持FLOPs一定的情况下,改变g的数值,以GPU x1 与CPU x1为例进行说明,当g=1的时候,每秒能推理2451个batches;当g=2,每秒能推理1725个batches;当g=8,每秒能推理634个batches;当g有1到8,它的推理速度下降到原来的1/4还是非常明显的。但在cpu上我们发现它下降的连一半都不到。
G3: Network fragmentation reduces degree of parallelism
网络设计的碎片化程度越高,速度越慢。这里所说的碎片化可以理解为网络的分支的程度,很多网络在设计的时候分支越来越多。
- 分支可以是串联,可以是并联,在googlenet inception模块,它就并行了有
3x3的卷积层,5x5的卷积层,还有池化层等等,他们就很喜欢采用多分支的结构来进行网络的搭建。论文当中提到虽然碎片化结构能提升我们的精确率,但是它会降低模型的效率。因为这种碎片化的结构,对于像GPU这种具有非常强的并行计算能力的设备是非常不友好的,并且在多分支的情况下,还有kernel的启动和同步的问题。

比如图e中,有4个并行的分支,对于每个卷积层都需要有kernel的启动,如果四个并行结构计算时间差不多的话,其实还好。如果相差很大的话,运算快的运算完之后就一直等着运算比较慢的,只有等到大家全部结束之后,我们才能进行下一步计算,所以这个效率是比较低的。
同样作者针对G3也做了一系列实验。

其中上图(a),(b),?对应的与1-fragement,2-fragement,3-fragement,他们是简单的串行,同样是保持FLOPs不变的情况下,我们的串行的层数越多,碎片化程度越高我们的推理速度也是越来越慢的。对于图d,图e,对应的是2-fragement,4-fragement,也同样是碎片化程度越高,推理速度越慢。但是在cpu上其实变化是不大的,GPU变化非常明显。
G4:Element-wise operations are non-negligible
Element-wise 操作带来的影响是不可忽视的。
Element-wise 包括哪些操作呢,论文中提到它包含有:激活函数比如Relu,比如AddTensor如ResNet网络中的捷径分支与主分支的输出进行Add操作,还有卷积过程中使用到AddBias等等这一系列。对于每一个元素型操作的都叫Element-wise operation,这些操作的特点都是它的FLOPs很小,但是他们的MAC很大。作者也说了向我们depthwise convolution也可以看做为element-wise operator.

作者也做了一系列的实验。比如我们采用short-cut链接和不采用short-cut链接,很明显我们不采用short-cut链接会更快。采用Relu和不采用Relu,肯定是不采用Relu会更快。
这里肯定会有人要说,不采用这些操作肯定会更快,这里作者想突出的,这些element-wise操作,它比我们想象当中要更耗时。作者提到如果把Relu和short-cut移除后再GPU或ARM CPU上能提升20%.如果我们仅仅通过FLOPs来进行对比的话,其实这些element-wise操作基本上是不会占用多少运算时间的。但是在实际使用过程中,其实它还是很耗时的。
论文对四点总结
- 要使用一个平衡的convolution,尽可能让输入特征矩阵channel与输出矩阵channel等于或接近1.
- 注意groups convolution的计算成本,不能一味的去增大groups数,但增大groups能降低参数以及FLOPs或许还能提高我们的Accuracy,但是它会增加我们的计算成本。
- 降低网络的碎片程度,如果你想要有一个非常高效的网络的话,不要涉及那么多分支结构
- 尽可能减少使用
element-wise operator
根据准则设计我们的ShuffleNet V2

其中图(a)和图(b)就是shuffleNet V1,其中a是我们DW卷积步距为1,b是DW卷积步距为2的时候。右边的图c和图d,就是我们shuffleNet V2中对应步距为1和2的block.
- 图e,对于每个Block单元,我们会对于输入的channels 进行split,划分为两个branches,一个是
c
′
c^{'}
c′,一个是
c
?
c
′
c-c^{'}
c?c′,根据G3我们要减少模型的碎片化程度,所以在左边的分支上是没有进行任何操作的。在另外一个分支上我们有3个卷积层
(1x1 GConv, 3X3 Dconv, 1x1 Conv)他们拥有相同的输入和输出channel,并且将GConv换回了普通卷积,这就是为了满足我们的G2就是尽快能降低GConv中分组g的数值。在卷积之后,两个分支是通过concat进行拼接的这就能够满足输入channel和输出channel是一样的,因为我们在输入的时候在channel进行了split,所以只有concat的凭借才能保证channel是一样的。 - 在shuffleNet v2相比于v1没有在add之后,进行Relu,改为在右边分支进行Relu.就相当于原来来个分支都有Relu操作,改为只在右边分支有Relu操作
- 对于三个连续的
element-wise操作,Concat,Channel Shuffle以及下一个block的Channel Split,这三个操作可以合并为一个element-wise operation,又变相的减少了element-wise操作的个数,这就满足G4准则。 - 对于下采样为2,对应
图e的情况,channel split操作就不存在了,因此输出特征矩阵的channel就翻倍了
ShuffleNet V2 网络结构

- 作者提到,shuffleNet v1 v2,它的框架基本上都一样的。都有
Conv1 Maxpoo Stage 2~5 Global pool FC,这里唯一的不同就是v2比v1多了一个1x1Conv5,提供了shuffleNet v2 0.5x,shuffleNet v2 1x,shuffleNet v2 1.5x,shuffleNet v2 2x四个不同的版本。 - 对于每个stage,它的第一个block是需要进行翻倍的,步距strip都是等于2的。
shuffleNet v1和v2对比
- shuffleNet v2相对于shuffleNet v1在stride=1的情况下,首先通过一个channel split的操作,将输入特征矩阵划分为2部分,1部分是我们的捷径分支,另一部分就对应于我们主分支。
- 对于主分支而言我们两个1x1的卷积层,又有v1的GConv变成了原来普通的卷积了。由于是普通卷积,主分支没有channel shuffle了,将它移到concat之后了。
- 对于v1的add操作,变为了v2的concat操作了。
- 并将v1中经过add,然后relu。v2将relu放到了右边的分支上了。
- 对于stride为2的情况下,对于v1的分支上用过3x3的平均池化,但V2版本中通过一个3x3DW卷积+1x1的普通卷积。

性能指标
`
- 首先看下ShuffleNet v2 0.5x这个版本,在这里对标了
MobileNet v1 0.25,MobileNet v2 0.4版本,还有MobileNet v2 0.15版本,这些版本你能够发现其实,他们的Flops其实是差不多的,但准确率方面我们可以看到shuffleNet v2 0.5x是最高的。但在速度方面我们可以看到MobileNet v1 0.25速度是最快的,但准确率和shuffleNet v2 0.5x比起来,相差太远了。 - ShuffleNet V2 1x的版本,它对标
MobileNet v1 0.5版本,还有MobileNet v2 0.75版本,以及MobileNet v2 0.6版本。可以看到他们的Flops其实也是差不多的。但是错误率上shuffleNet v2 1x是最小的,也就是最有效的。在速度方面,cpu上还是mobilleNet v1 0.5版本是最快的,但是它的错误率明显要高出很多,但是在我们的arm cpu上依旧是我们shuffleNet v2 1x是最快的 - 最后作者也将ShuffleNet v2 2x 加上了注意力机制SE,恨他对标的几个网络,在FLOPs相同的情况下,错误率最低,GPU以及CPU上推理速度也都是最快的。