
Author: Chun Yang, Shicai Fan
Motivation:
在推荐系统中,Pointwise Loss (MSE、BCE等)和 Pairwise Loss(BPR、CML)被广泛使用,但是他们都是有缺点的。
对于Pointwise Loss,优化目标是观测到的交互数据和真实的label,但是优化过程不包括ranking信息,不利于生成推荐list。
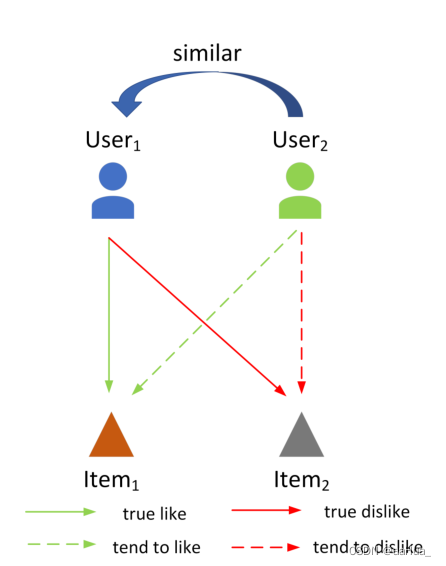
对于Pairwise Loss,通常挑选三元组<user,positive item,negative item>作为样本做优化,但是没有充分利用先验信息(在本文中指用户的相似用户),不能充分表达用户和物品之间的关联性。
以上loss function仅仅是对观测到的交互数据做了建模,并没有建模用户和物品的相关性。
也就是直接对观察到的隐性互动进行建模的传统损失函数实际上是对实际的点击率进行建模,而不是对用户和项目之间的相关性进行建模,因为用户和项目之间有互动意味着用户在观察项目的同时对项目感兴趣。当用户和物品之间没有互动时,并不意味着用户对该物品不感兴趣。
本文就是对Pairwise Loss中的BPR做的优化。不但考虑了用户和物品的交互,还考虑了用户和用户的关系。
Contribute:
1.提出SPR,充分利用了原始数据中的先验知识,提高了性能。
2.通过提出的SPR和利用类似BPR的动态采样,也加速了模型的收敛速度。
3.大量实验表明,对比之前的Loss function,SPR拥有好的性能和快的收敛。
Method:
BPR <user,positive item,negative item>
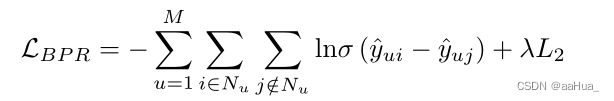
SPR <user,similar user,positive item,negative item>
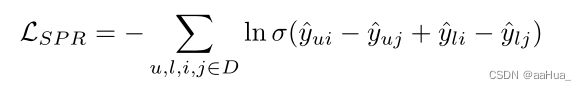
similar user指的是在交互矩阵中拥有相似交互的用户。
相似度计算就是对于交互矩阵做矩阵乘法,在S中对于每个用户取top k%作为相似用户。
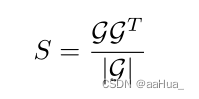
对于构造四元组是通过和BPR类似的动态采样,如下图:

文章中详细介绍了实验构成和结果,SPR的性能表明显著优于之前的loss function,并且减少了训练时长。