理解Seperable Convolution
常规卷积
假设输入图像的shape 为 12 x 12 x 3 , 如果使用shape 为 5 x 5 x 3 的普通卷积核,将得到 shape 8 x 8 x 1 的feature map.
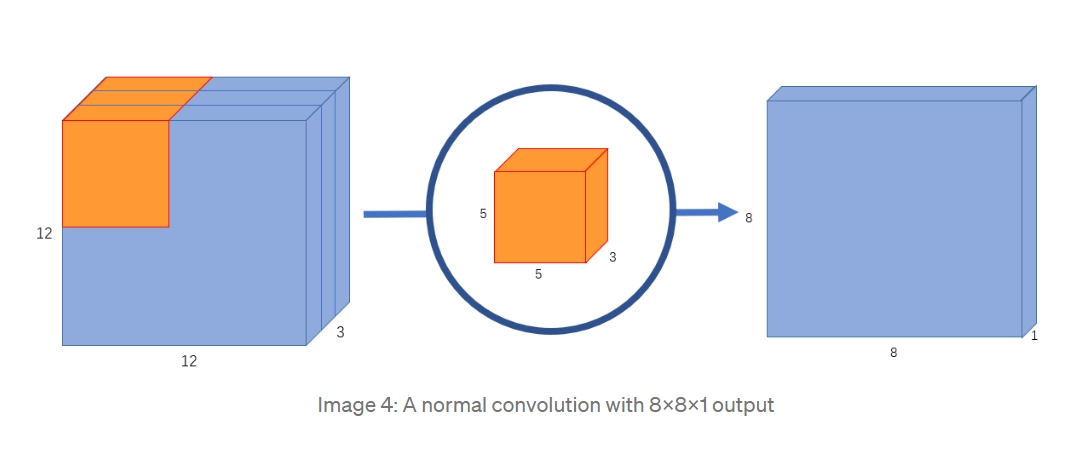
总所周知,卷积计算其实就是卷积核的每个通道的元素与输入图像对应位置元素的element-wise乘积再相加的过程(例如上图中,卷积核的三个通道和输入图像的三个通道的对应位置元素相乘再相加后,将得到三个通道的加权值,然后再将这三个通道的加权值相加,就得到了feature map的上一个点,滑动卷积核,即可进行下一次卷积计算)。
如果卷积核的数量为256,也就是重复上述过程256次,将得到 shape 为 8 x 8 x 256 的feature map.
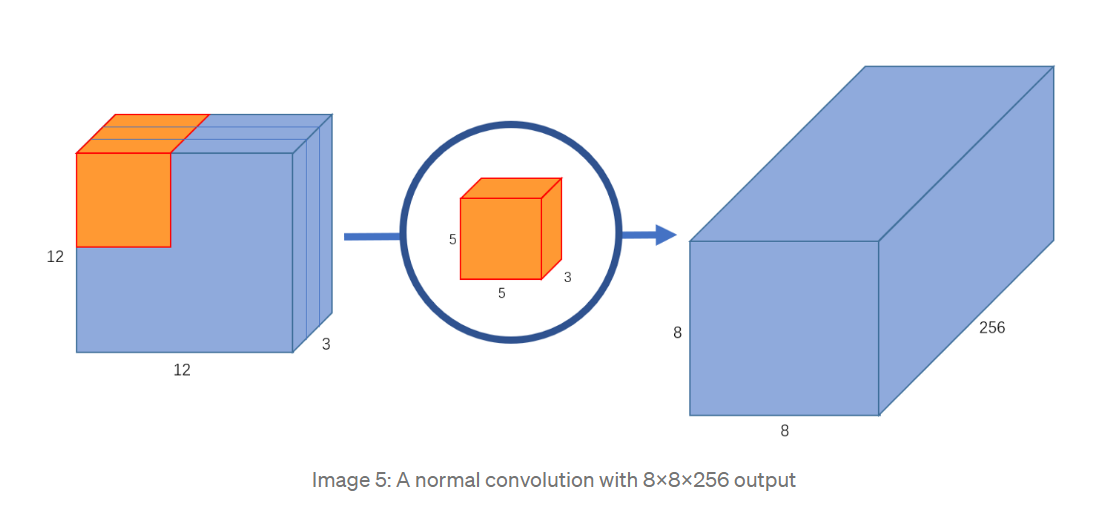
在这个过程中,总共做了 5 x 5 x 3 x 256 x 8 x 8 = 1228800次乘法(一次卷积只得到feature map 上的一个点)
卷积核训练的参数量为 5 x 5 x 3 x 256 = 19200.
Seperable Convolution
Seperable Convolution 把卷积过程分为了DepthWise Convolution 和 PointWise Convolution 两个步骤来完成。
DepthWise Convolution
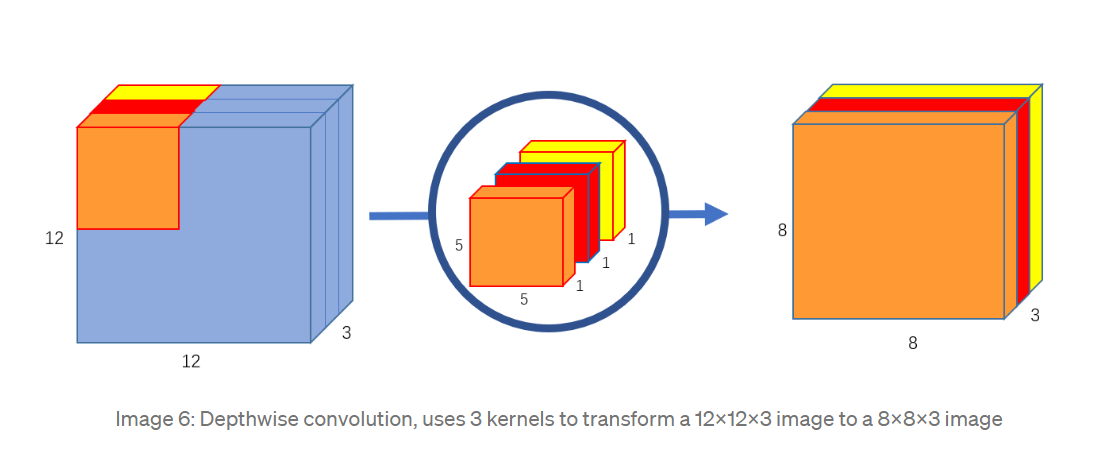
DepthWise Convolution 对输入图像的每个通道单独进行卷积,最后将得到的feature map 在通道方向上做堆叠。 DepthWise Convolution的卷积核大小相当于原来的1/3,每个卷积核只有单独的1个通道,因此这个过程中总共计算了 5 x 5 x 1 x 3 x 8 x 8 = 4800 , 卷积核的可训练参数大小为 5 x 5 x 3 x 1= 75
这个过程其实相当于普通卷积的计算时的第一步,分别求每个通道的加权值,但是不相加,而是仅在通道方向上堆叠。
PointWise Convolution
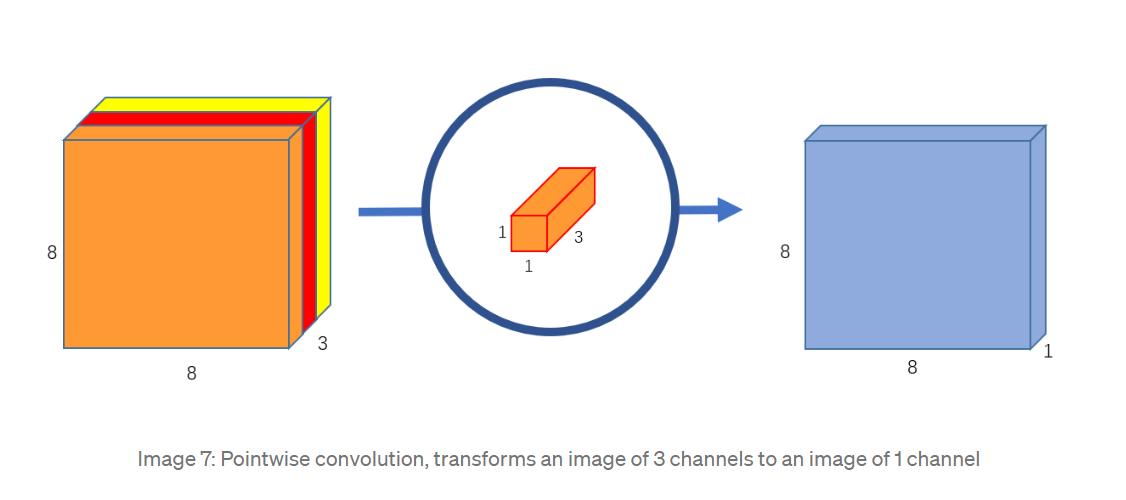
第二步,使用1 x 1 的卷积核把Depthwise输出的feature map “加” 起来变成一个feature map。用同样大小的卷积核256个,就能得到 shape 为8 x 8 x 256 的feature map。这个过程类似于普通卷积将三个通道的加权值相加合成为feature map上的一个点的那一步,但是却并非完全一样,普通卷积是直接相加三个通道的加权值,这里因为还是一个卷积过程,所以又进行了一次element-wise相乘再相加的操作,准确来说是再次加权然后相加各通道的加权值)。
这个过程中总共计算了1 x 1 x 3 x 256 x 8 x 8 = 49152次乘法,卷积核的可训练参数为 1 x 1 x 3 x 256 = 768 。把两次过程的计算量相加 4800 + 49152 = 53952 仅为普通卷积计算量1228800 的4.39%! 极大地降低了模型的计算量,因此广泛应用于轻量级的模型例如 MobileNet等。
总结
普通Convolution layer 的一次卷积过程:
- 卷积核的各通道元素分别与输入图像对应位置的元素进行element-wise的相乘再相加操作得到输入图像各通道的加权值
- 将得到的各通道加权值直接相加,合成为feature map 上的一个点。
Seperable Convolution layer 的一次卷积过程:
- 卷积核的各通道元素分别与输入图像对应位置的元素进行element-wise的相乘再相加操作得到输入图像的各通道加权值,但是不相加,而是仅在通道方向上堆叠 (DepthWise Convolution)
- 把DepthWise Convolution 过程得到的输入图像的各通道加权值进行再次加权后相加合成为feature map上的一个点 (PointWise Convolution)
普通Convolution layer 会构造输入图像的各通道加权值 N 次 得到N 维的feature map 输出 (卷积核的数量,也就是输出的feature map的维度) ;而Seperable Convolution layer 只构造输入图像各通道加权值1 次 (Depwise Convolution),然后用不同的比例 (权值) 构造feature map N次 得到N 维的feature map 输出 (PointWise Convolution)
文中图片来自均来自于
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728