提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
Libtorch是pytorch的C++版本,现在的很多大型项目都是用C++写的,想使用训练好的模型,需要通过caffe等方式去集成,比较麻烦。 这里pytorch官方提出了Libtorch,我们就可以把pytorch训练好的模型,打包起来,直接在C++工程中去用就好了,相比较caffe等,非常方便!
提示:以下是本篇文章正文内容,下面案例可供参考
一、环境配置
本机配置:cuda11.1、pytorch1.8.2、cudnn8.2、vs2019、opencv4.5.3
环境下载
vs2019下载链接:下载vs2019
opencv下载链接:下载opencv
libtorch下载链接:下载libtorch
cuda和cudnn下载链接:下载cuda11.1.1下载cudnn8.2
安装pytorch

安装libtorch,下载放到文件里即可
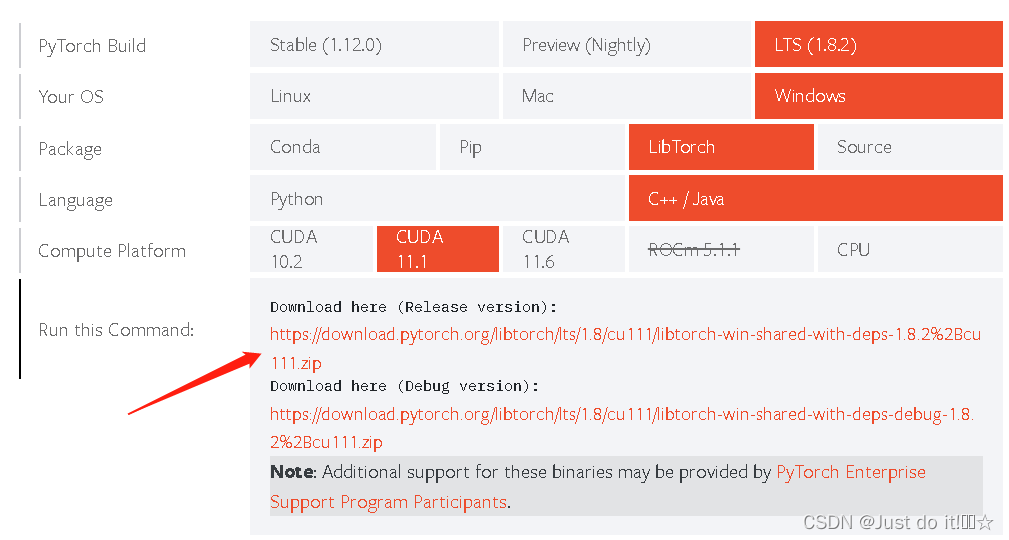
安装成功
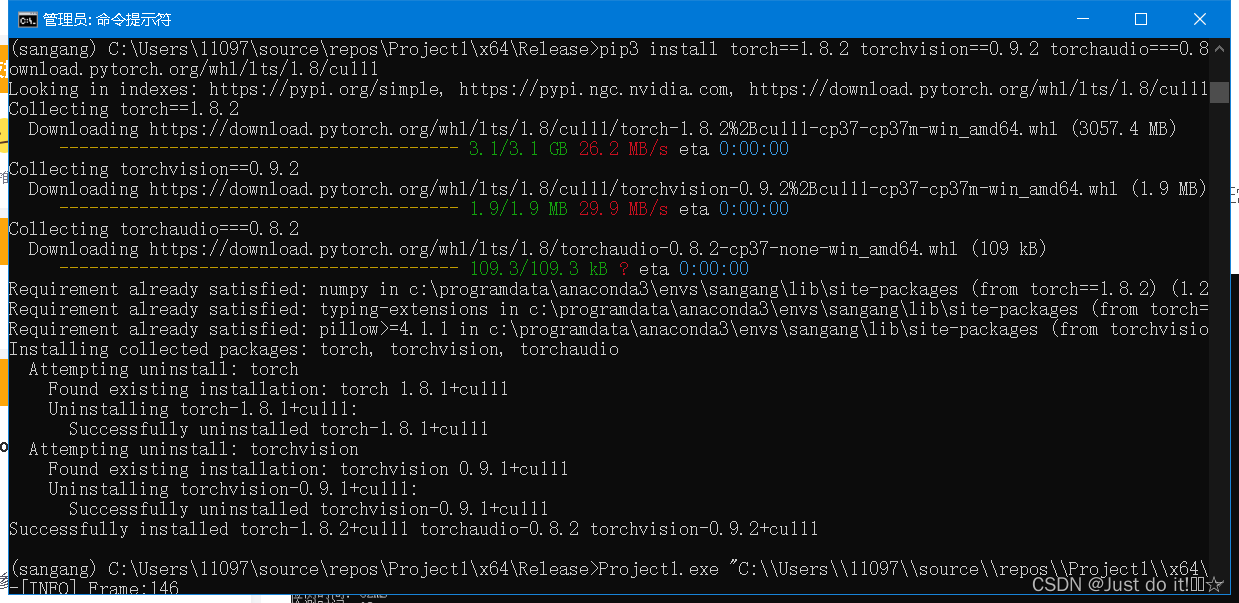
测试代码,在vs2019中新建工程、空项目。
#include "torch/torch.h"
#include "torch/script.h"
int main()
{
torch::Tensor output = torch::randn({ 3,2 });
std::cout << output;
return 0;
}
二、环境变量的配置
参考博文
1。打开项目-配置属性-调试-环境,输入libtorch的地址
PATH=D:\Myproject\libtorch-win-shared-with-deps-1.8.1+cu111\libtorch\lib;%CUDA_PATH%;%PATH%$(LocalDebuggerEnvironment)
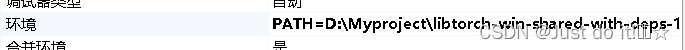 2。更改VC++目录-包含目录
2。更改VC++目录-包含目录
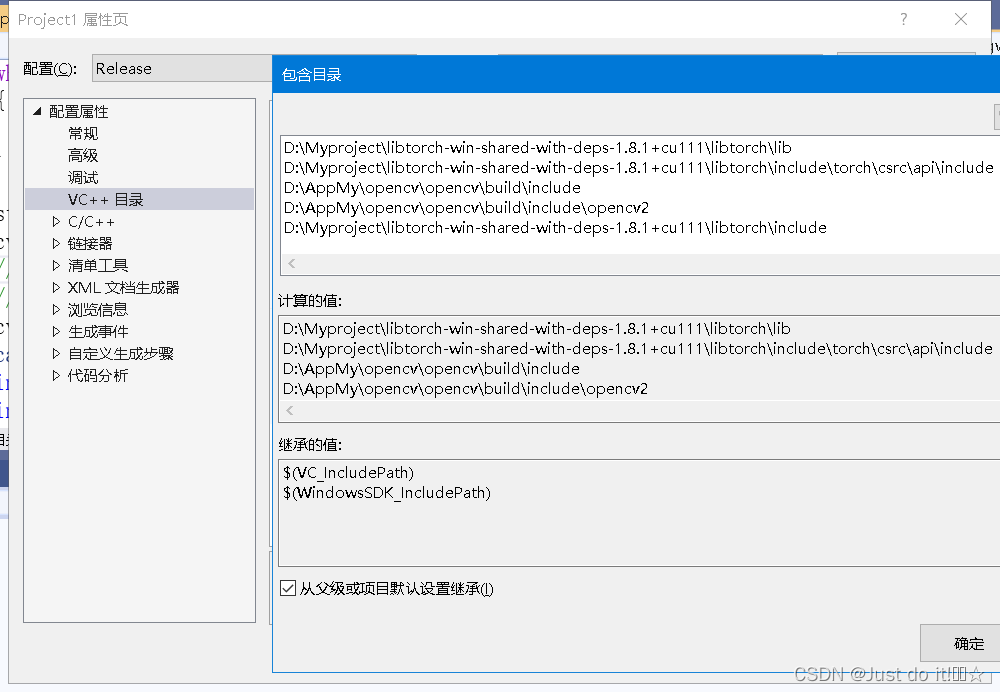
更改外部包含目录

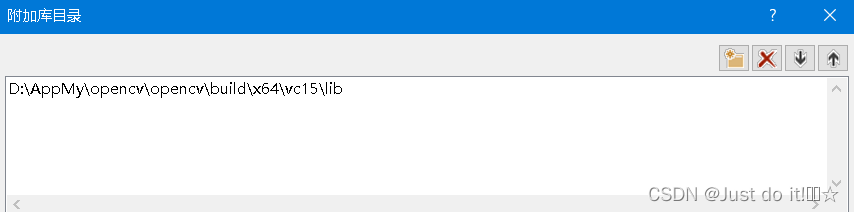
更改库目录,添加opencv、libtorch、cuda地址
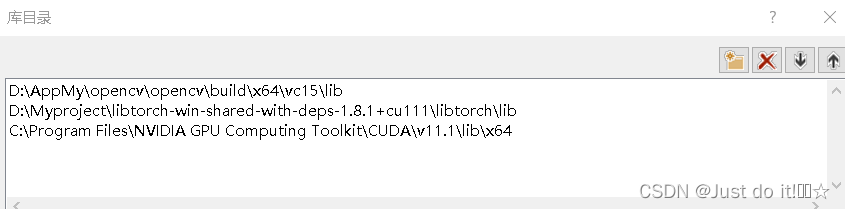
3.更改C/C++ - 常规-附加包含目录
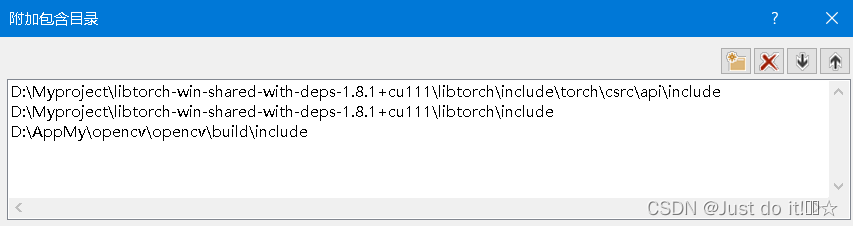
语言-符合模式改为否
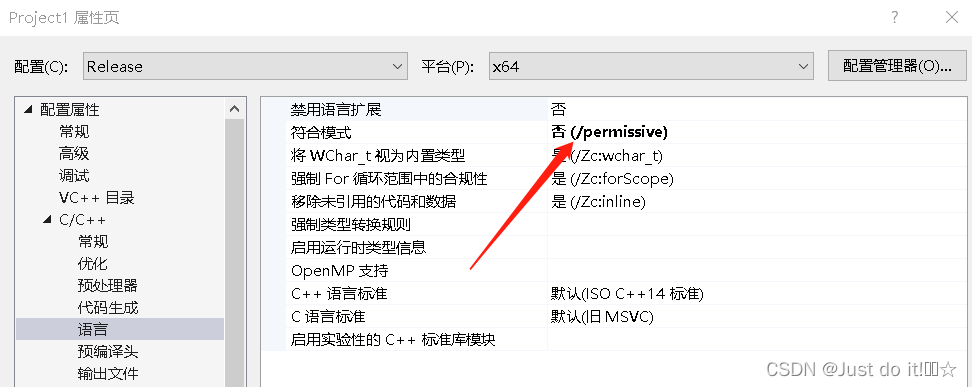
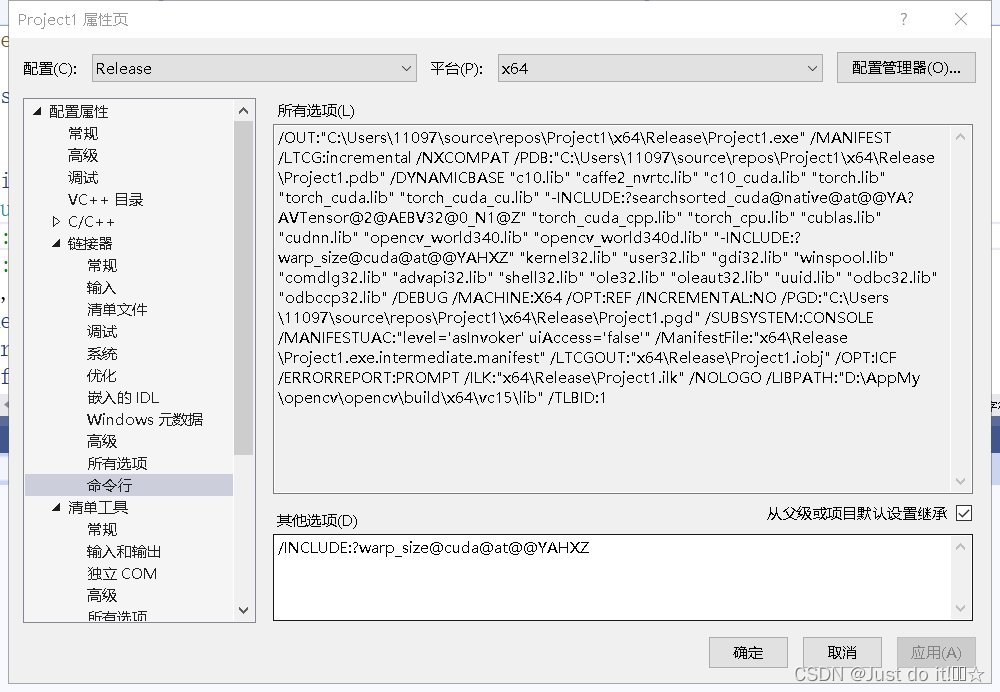
3。更改链接器-常规-附加库目录
更改输入-附加依赖项
c10.lib
caffe2_nvrtc.lib
c10_cuda.lib
torch.lib
torch_cuda.lib
torch_cuda_cu.lib
-INCLUDE:?searchsorted_cuda@native@at@@YA?AVTensor@2@AEBV32@0_N1@Z
torch_cuda_cpp.lib
torch_cpu.lib
cublas.lib
cudnn.lib
opencv_world340.lib
opencv_world340d.lib
-INCLUDE:?warp_size@cuda@at@@YAHXZ
更改命令行,加入/INCLUDE:?warp_size@cuda@at@@YAHXZ ,否则可能无法调用cuda
三.模型在libtorch上的部署
参考的博文代码:链接我用的是yolov56.0版本,目前还没有试最新的版本。
这里有我在使用orchscript模型时遇到问题需要解决,留一下坑:
问题1.我在使用yolov5官方代码expor.py转换的模型时会出现报错,目前猜测是模型不匹配的结果原因,所以后续是否可以用官方代码进行转换的模型使用?
!!!如果出现module.forward(inputs)C++ 异常: std::runtime_error,位于内存位置的错误就是模型不匹配的结果,
转换模型代码
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=r'D:\project_process\Completed_projects\yolo-deploy\yolov5-6.0\weights\yolov5n.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
model = attempt_load(opt.weights, map_location=torch.device('cuda')) # load FP32 model
labels = model.names
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input
img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device='cuda')
# image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
#model.model[-1].export = True # set Detect() layer export=True
model.model[-1].export = False
y = model(img) # dry run
# TorchScript export
try:
print('\nStarting TorchScript export with torch %s...' % torch.__version__)
f = opt.weights.replace('.pt', '.torchscript.pt') # filename
ts = torch.jit.trace(model, img)
ts.save(f)
print('TorchScript export success, saved as %s' % f)
except Exception as e:
print('TorchScript export failure: %s' % e)
# ONNX export
try:
import onnx
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'])
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
print('ONNX export success, saved as %s' % f)
except Exception as e:
print('ONNX export failure: %s' % e)
# CoreML export
try:
import coremltools as ct
print('\nStarting CoreML export with coremltools %s...' % ct.__version__)
# convert model from torchscript and apply pixel scaling as per detect.py
model = ct.convert(ts, inputs=[ct.ImageType(name='image', shape=img.shape, scale=1 / 255.0, bias=[0, 0, 0])])
f = opt.weights.replace('.pt', '.mlmodel') # filename
model.save(f)
print('CoreML export success, saved as %s' % f)
except Exception as e:
print('CoreML export failure: %s' % e)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
模型推理代码(video)
修改模型进行编译即可,模型文件放在项目main.cpp同一目录下。
#include <opencv2/opencv.hpp>
#include <torch/script.h>
#include <torch/torch.h>
#include <algorithm>
#include <iostream>
#include <time.h>
std::vector<torch::Tensor> non_max_suppression(torch::Tensor preds, float score_thresh = 0.01, float iou_thresh = 0.35)
{
std::vector<torch::Tensor> output;
for (size_t i = 0; i < preds.sizes()[0]; ++i)
{
torch::Tensor pred = preds.select(0, i);
//GPU推理结果为cuda数据类型,nms之前要转成cpu,否则会报错
pred = pred.to(at::kCPU); //增加到函数里pred = pred.to(at::kCPU); 注意preds的数据类型,转成cpu进行后处理。
// Filter by scores
torch::Tensor scores = pred.select(1, 4) * std::get<0>(torch::max(pred.slice(1, 5, pred.sizes()[1]), 1));
pred = torch::index_select(pred, 0, torch::nonzero(scores > score_thresh).select(1, 0));
if (pred.sizes()[0] == 0) continue;
// (center_x, center_y, w, h) to (left, top, right, bottom)
pred.select(1, 0) = pred.select(1, 0) - pred.select(1, 2) / 2;
pred.select(1, 1) = pred.select(1, 1) - pred.select(1, 3) / 2;
pred.select(1, 2) = pred.select(1, 0) + pred.select(1, 2);
pred.select(1, 3) = pred.select(1, 1) + pred.select(1, 3);
// Computing scores and classes
std::tuple<torch::Tensor, torch::Tensor> max_tuple = torch::max(pred.slice(1, 5, pred.sizes()[1]), 1);
pred.select(1, 4) = pred.select(1, 4) * std::get<0>(max_tuple);
pred.select(1, 5) = std::get<1>(max_tuple);
torch::Tensor dets = pred.slice(1, 0, 6);
torch::Tensor keep = torch::empty({ dets.sizes()[0] });
torch::Tensor areas = (dets.select(1, 3) - dets.select(1, 1)) * (dets.select(1, 2) - dets.select(1, 0));
std::tuple<torch::Tensor, torch::Tensor> indexes_tuple = torch::sort(dets.select(1, 4), 0, 1);
torch::Tensor v = std::get<0>(indexes_tuple);
torch::Tensor indexes = std::get<1>(indexes_tuple);
int count = 0;
while (indexes.sizes()[0] > 0)
{
keep[count] = (indexes[0].item().toInt());
count += 1;
// Computing overlaps
torch::Tensor lefts = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor tops = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor rights = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor bottoms = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor widths = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor heights = torch::empty(indexes.sizes()[0] - 1);
for (size_t i = 0; i < indexes.sizes()[0] - 1; ++i)
{
lefts[i] = std::max(dets[indexes[0]][0].item().toFloat(), dets[indexes[i + 1]][0].item().toFloat());
tops[i] = std::max(dets[indexes[0]][1].item().toFloat(), dets[indexes[i + 1]][1].item().toFloat());
rights[i] = std::min(dets[indexes[0]][2].item().toFloat(), dets[indexes[i + 1]][2].item().toFloat());
bottoms[i] = std::min(dets[indexes[0]][3].item().toFloat(), dets[indexes[i + 1]][3].item().toFloat());
widths[i] = std::max(float(0), rights[i].item().toFloat() - lefts[i].item().toFloat());
heights[i] = std::max(float(0), bottoms[i].item().toFloat() - tops[i].item().toFloat());
}
torch::Tensor overlaps = widths * heights;
// FIlter by IOUs
torch::Tensor ious = overlaps / (areas.select(0, indexes[0].item().toInt()) + torch::index_select(areas, 0, indexes.slice(0, 1, indexes.sizes()[0])) - overlaps);
indexes = torch::index_select(indexes, 0, torch::nonzero(ious <= iou_thresh).select(1, 0) + 1);
}
keep = keep.toType(torch::kInt64);
output.push_back(torch::index_select(dets, 0, keep.slice(0, 0, count)));
}
return output;
}
#include <torch/script.h>
#include <iostream>
#include <memory>
//int main(int argc, const char* argv[]) {
// std::cout << "cuda::is_available():" << torch::cuda::is_available() << std::endl;
// torch::DeviceType device_type = at::kCPU; // 定义设备类型
// if (torch::cuda::is_available())
// device_type = at::kCUDA;
//}
int main(int argc, char* argv[])
{
std::cout << "cuda::is_available():" << torch::cuda::is_available() << std::endl;
torch::DeviceType device_type = at::kCPU; // 定义设备类型
if (torch::cuda::is_available())
device_type = at::kCUDA;
// Loading Module
torch::jit::script::Module module = torch::jit::load("yolov5n.torchscript.pt");//best.torchscript3.pt//yolov5x.torchscript.pt
module.to(device_type); // 模型加载至GPU
std::vector<std::string> classnames;
std::ifstream f("class.names");
std::string name = "";
while (std::getline(f, name))
{
classnames.push_back(name);
}
std::string video = argv[1];
cv::VideoCapture cap = cv::VideoCapture(video);
// cap.set(cv::CAP_PROP_FRAME_WIDTH, 1920);
// cap.set(cv::CAP_PROP_FRAME_HEIGHT, 1080);
cv::Mat frame, img;
cap.read(frame);
int width = frame.size().width;
int height = frame.size().height;
int count = 0;
while (cap.isOpened())
{
count++;
clock_t start = clock();
cap.read(frame);
if (frame.empty())
{
std::cout << "Read frame failed!" << std::endl;
break;
}
// Preparing input tensor
cv::resize(frame, img, cv::Size(640, 640));
// cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
// torch::Tensor imgTensor = torch::from_blob(img.data, {img.rows, img.cols,3},torch::kByte);
// imgTensor = imgTensor.permute({2,0,1});
// imgTensor = imgTensor.toType(torch::kFloat);
// imgTensor = imgTensor.div(255);
// imgTensor = imgTensor.unsqueeze(0);
// imgTensor = imgTensor.to(device_type);
cv::cvtColor(img, img, cv::COLOR_BGR2RGB); // BGR -> RGB
img.convertTo(img, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
auto imgTensor = torch::from_blob(img.data, { 1, img.rows, img.cols, img.channels() }).to(device_type);
imgTensor = imgTensor.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(imgTensor);
// preds: [?, 15120, 9]
torch::jit::IValue output = module.forward(inputs);
auto preds = output.toTuple()->elements()[0].toTensor();
// torch::Tensor preds = module.forward({ imgTensor }).toTensor();
std::vector<torch::Tensor> dets = non_max_suppression(preds, 0.35, 0.5);
if (dets.size() > 0)
{
// Visualize result
for (size_t i = 0; i < dets[0].sizes()[0]; ++i)
{
float left = dets[0][i][0].item().toFloat() * frame.cols / 640;
float top = dets[0][i][1].item().toFloat() * frame.rows / 640;
float right = dets[0][i][2].item().toFloat() * frame.cols / 640;
float bottom = dets[0][i][3].item().toFloat() * frame.rows / 640;
float score = dets[0][i][4].item().toFloat();
int classID = dets[0][i][5].item().toInt();
cv::rectangle(frame, cv::Rect(left, top, (right - left), (bottom - top)), cv::Scalar(0, 255, 0), 2);
cv::putText(frame,
classnames[classID] + ": " + cv::format("%.2f", score),
cv::Point(left, top),
cv::FONT_HERSHEY_SIMPLEX, (right - left) / 200, cv::Scalar(0, 255, 0), 2);
}
}
// std::cout << "-[INFO] Frame:" << std::to_string(count) << " FPS: " + std::to_string(float(1e7 / (clock() - start))) << std::endl;
std::cout << "-[INFO] Frame:" << std::to_string(count) << std::endl;
// cv::putText(frame, "FPS: " + std::to_string(int(1e7 / (clock() - start))),
// cv::Point(50, 50),
// cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 255, 0), 2);
cv::imshow("", frame);
// cv::imwrite("../images/"+cv::format("%06d", count)+".jpg", frame);
cv::resize(frame, frame, cv::Size(width, height));
if (cv::waitKey(1) == 27) break;
}
cap.release();
return 0;
}
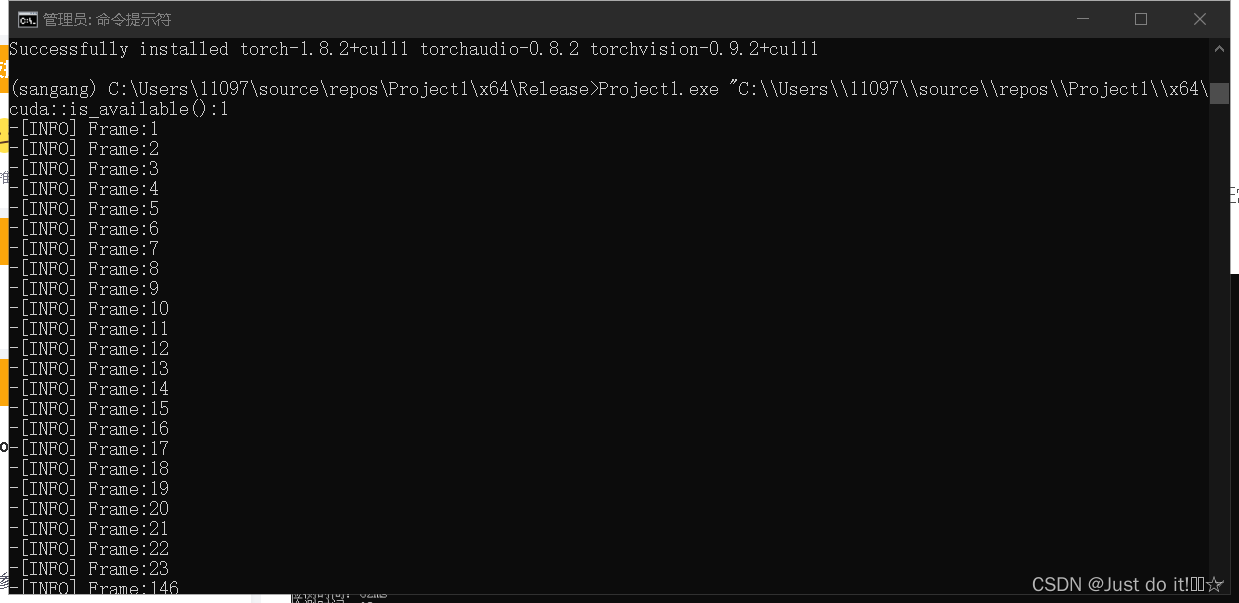
点击生成解决方案,会生成一个.exe文件,用cmd运行
运行指令:
Project1.exe "C:\\Users\\11097\\source\\repos\\Project1\\x64\\Release\\test.mp4"
总结
1。需要做到适配yolov5最新的模型版本,6.1版本